En los últimos años, el Modelo de Expertos Mixtos (MoE) se ha utilizado ampliamente en grandes modelos en la nube. Sin embargo, en el lado del cliente móvil, los Modelos de Lenguaje a Gran Escala (LLM) todavía se basan principalmente en arquitecturas densas. En el pasado, las restricciones de memoria, potencia computacional y latencia en dispositivos móviles eran más estrictas, y la investigación sistemática sobre MoE en el lado del cliente dentro del rango de menos de mil millones de parámetros activos ha sido escasa. Hoy, con el aumento de la capacidad DRAM en dispositivos móviles, los modelos MoE también comienzan a tener la oportunidad de desplegarse en teléfonos inteligentes.
El equipo de Meta propone MobileMoE, que implementa por primera vez una inferencia eficiente de MoE en teléfonos inteligentes comerciales. Los resultados muestran que, en 14 pruebas básicas, MobileMoE-S/M, con un uso de memoria similar, logra una precisión promedio igual o mayor que la línea de base densa utilizando solo entre 1/2 y 1/4 de los cálculos de inferencia. En pruebas prácticas, MobileMoE-S mostró la mayor aceleración en el backend GPU/MLX del iPhone 16 Pro, alcanzando una aceleración máxima de hasta 3.8 veces en la fase de entrada.

Enlace del artículo: https://arxiv.org/abs/2605.27358
El equipo de investigación también propuso un conjunto de leyes de escalado para MoE en el lado del cliente, para determinar estructuras de modelo más adecuadas para el despliegue en móviles. MobileMoE establece un nuevo frente de Pareto para los grandes modelos de lenguaje en el lado del cliente, logrando un mejor equilibrio entre precisión y coste computacional de inferencia.
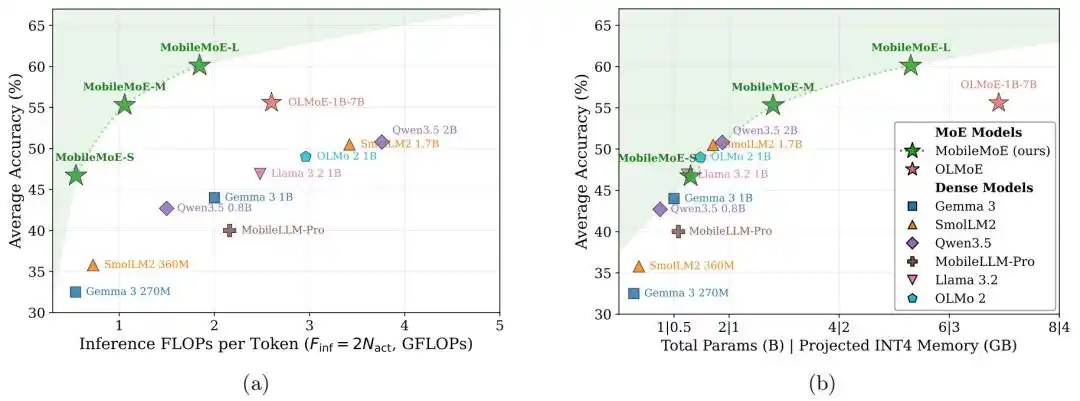
Figura | MobileMoE establece un nuevo frente de Pareto para LLMs en el lado del cliente.
¿Cómo está diseñado MobileMoE?
MobileMoE puede entenderse así: es una clase de modelo de lenguaje MoE diseñado para el despliegue en el lado del cliente. En general, sigue siendo un Transformer decoder-only, pero reemplaza las capas feed-forward densas originales por capas MoE. Un enrutador selecciona a los pocos expertos con la puntuación más alta para cada token para participar en el cálculo, mientras que también hay un experto compartido que siempre participa. El flujo de entrenamiento completo consta de cuatro pasos: preentrenamiento, entrenamiento intermedio, ajuste fino supervisado y entrenamiento consciente de la cuantización.
Preentrenamiento: El equipo de investigación realizó el preentrenamiento con aproximadamente 6T tokens de datos con licencia abierta, con una longitud de contexto de 2048. Los datos consisten principalmente en contenido web, cubriendo también áreas como matemáticas, código, conocimiento y ciencia.
Entrenamiento Intermedio: El equipo extendió la longitud de contexto a 8192 y aumentó aún más la proporción de datos de alta calidad en conocimiento, código, matemáticas y ciencia, con una escala total de aproximadamente 500B tokens.
Ajuste Fino Supervisado (SFT): El equipo realizó el ajuste fino en más de 80 millones de muestras de datos de instrucción con licencia abierta para MobileMoE-Base.
Entrenamiento Consciente de la Cuantización: El equipo cuantificó las capas lineales y los embeddings a INT4, las activaciones dinámicas a INT8, manteniendo la precisión del enrutador en FP32.

Figura | Las cuatro etapas de entrenamiento de MobileMoE.
Resultados Experimentales
Resultados del estudio de ablación
El equipo comparó primero tres variables de arquitectura: el número de expertos E, la granularidad del experto g, y si se incluye un experto compartido.

Figura | Escalado del número de expertos E.
Con un presupuesto de memoria fijo, cuando la memoria supera aproximadamente 0.25 GB, la pérdida del MoE comienza a ser inferior a la del modelo denso correspondiente. Al continuar aumentando el número de expertos E, la pérdida disminuye aún más, pero cuando E llega a 8, el beneficio marginal se debilita notablemente. Los experimentos sobre la granularidad del experto g muestran que configuraciones de expertos más finas son generalmente mejores, con g=8 logrando un buen equilibrio entre rendimiento y coste de entrenamiento; cuando g aumenta de 8 a 16, la mejora en la pérdida es inferior a 0.01, pero el tiempo de entrenamiento aumenta aproximadamente un 50%. Bajo el mismo presupuesto computacional, la pérdida del modelo disminuye aún más al incluir un experto compartido.
Basándose en los resultados del estudio de ablación, el equipo finalmente adoptó la configuración E=8, g=8, con experto compartido, es decir, 60 expertos de enrutamiento de grano fino, enrutamiento Top-4 y 1 experto compartido, y utilizó esta estructura para las tres versiones MobileMoE-S/M/L.
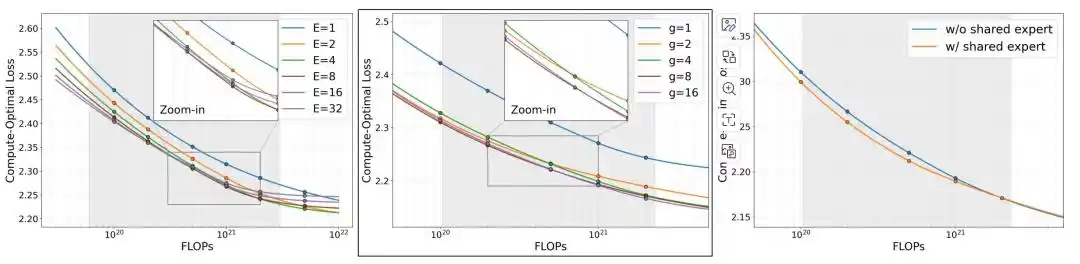
Figura | Escalado de modelos MoE bajo condiciones computacionalmente óptimas.
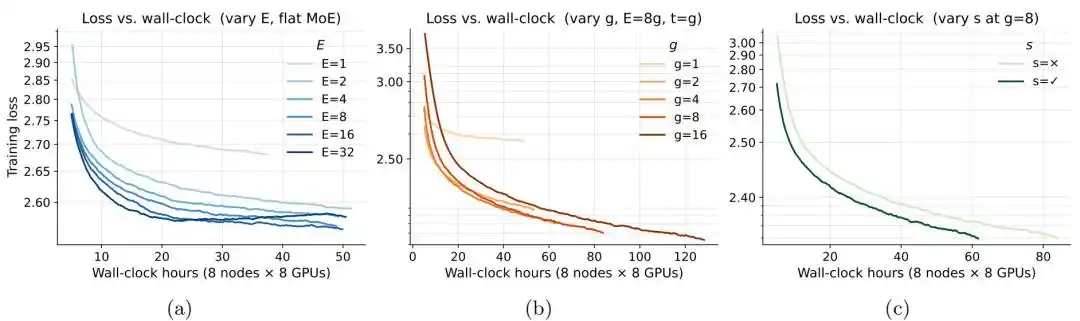
Figura | Eficiencia de entrenamiento de la arquitectura MoE.
14 evaluaciones básicas: estableciendo un nuevo frente de Pareto en el lado del cliente
El equipo evaluó MobileMoE junto con modelos como Gemma 3, SmolLM2, Qwen3.5, OLMo 2, OLMoE-1B-7B bajo una configuración unificada en 14 evaluaciones básicas divididas en cinco categorías: razonamiento de sentido común, conocimiento, ciencia, lectura comprensiva y razonamiento.
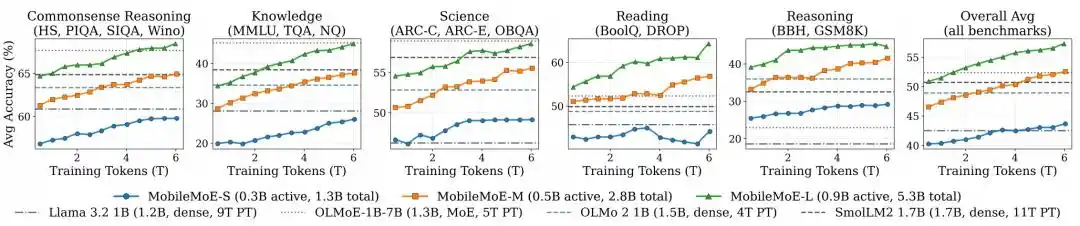
Figura | Trayectoria de preentrenamiento de MobileMoE.
Los resultados de comparación de los modelos Base muestran que la puntuación promedio de MobileMoE-M es mayor que la de Qwen3.5 2B, y la de MobileMoE-L es mayor que la de OLMoE-1B-7B, requiriendo además un tamaño de modelo más pequeño; el equipo también mencionó que la versión Base de MobileMoE-L ya tiene una puntuación promedio mayor que la versión Instruct de OLMoE-1B-7B. En cuanto a la escala de entrenamiento, MobileMoE utiliza aproximadamente 6T tokens de preentrenamiento, menos que los 9T de Llama 3.2 1B y los 11T de SmolLM2 1.7B. En la comparación general de modelos ajustados por instrucciones, la precisión promedio de MobileMoE-M ya se acerca a la de OLMoE-1B-7B, pero con aproximadamente un 60% menos de parámetros activos y totales.

Figura | Comparación de modelos MobileMoE-Base.
Evaluaciones avanzadas: ventaja más notable en tareas de código y matemáticas
En evaluaciones avanzadas tras el ajuste fino por instrucciones, MobileMoE se desempeña mejor en tareas de código y matemáticas. Tomando MobileMoE-L como ejemplo, sus puntuaciones promedio en las evaluaciones de código y matemáticas son más altas que las de Qwen3.5 2B y OLMoE-1B-7B. Sin embargo, el equipo también señala que Qwen3.5 2B sigue siendo más fuerte en seguimiento de instrucciones y razonamiento basado en conocimiento.
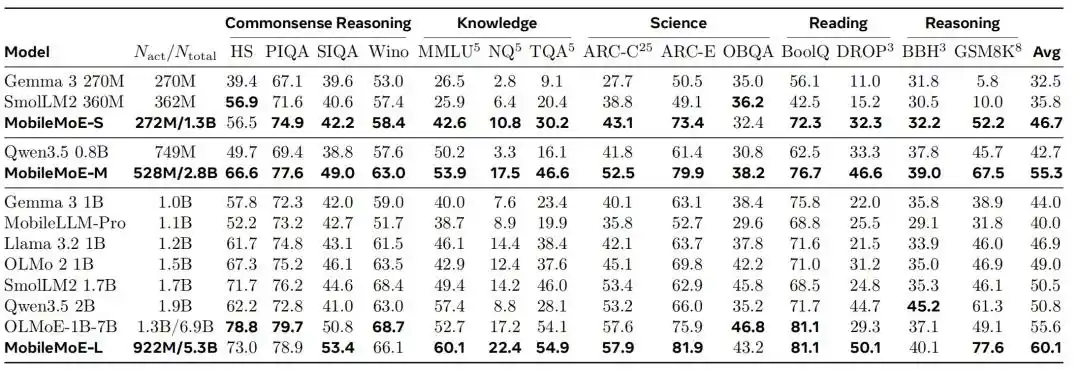
Figura | Comparación de modelos Instruct en evaluaciones de referencia avanzadas.
Cuantización y despliegue en el lado del cliente: mantiene competitividad tras INT4, aceleración notable en móviles
Tras la cuantización, las puntuaciones promedio generales de MobileMoE-S/M/L disminuyen en comparación con sus versiones BF16, pero la caída está aproximadamente entre 2 y 3 puntos. Aún así, el rendimiento de la versión INT4 de MobileMoE-L sigue siendo superior al de la versión BF16 Instruct de OLMoE-1B-7B.
El equipo también desplegó MobileMoE en Samsung Galaxy S25 e iPhone 16 Pro para realizar pruebas. Los resultados muestran que, bajo condiciones de memoria de pesos INT4 comparables, MobileMoE-S, en comparación con MobileLLM-Pro, acelera la fase de entrada entre 1.8 y 3.8 veces y acelera la fase de generación token por token entre 2.2 y 3.4 veces.
En cuanto al uso de memoria, en Samsung Galaxy S25, con un contexto de 8K y prompts reales, el pico de RSS de MobileMoE-S es de 1.49 GB, menor que los 1.91 GB de MobileLLM-Pro.

Figura | Latencia de ejecución en el lado del cliente.
Limitaciones y direcciones futuras
Actualmente, en capacidades de seguimiento de instrucciones de orden superior, así como en razonamiento basado en conocimiento, el MobileMoE ajustado por instrucciones aún está por detrás de Qwen3.5 2B. El equipo de investigación cree que esta brecha puede estar relacionada con un post-entrenamiento más completo del último. En el futuro, para reducir esta brecha, se necesitarán refuerzo en destilación, post-entrenamiento orientado al razonamiento y expansión multimodal en el lado del entrenamiento.
Además, el equipo señala que la huella de memoria de MoE en el móvil varía con el contenido de entrada. En comparación con entradas de plantilla fija, las entradas reales generalmente generan un mayor uso de memoria. Si las pruebas se basan únicamente en entradas de plantilla, podría subestimarse la presión de memoria en escenarios de despliegue real. En el futuro, para evaluar con mayor precisión el rendimiento de memoria real de MoE en el lado del cliente, aún se necesitan más datos de medición real.
Mientras tanto, el equipo ya ha completado pruebas sistemáticas en dispositivos reales para backends CPU y GPU, pero la ruta NPU aún está por explorar. Simultáneamente, el uso de memoria en tiempo de ejecución de MoE es relativamente sensible al contenido de entrada. En el futuro, el enrutamiento dinámico, la poda de expertos, la cuantización de precisión mixta y el despliegue en NPU móviles son direcciones para continuar mejorando la eficiencia en el lado del cliente.
Para más detalles técnicos, consulte el artículo original.
Este artículo proviene del WeChat público "学术头条" (ID:SciTouTiao), autor: 夏千斯.





