En la última década, el aumento de potencia de la IA ha dependido principalmente de una vía: invertir más datos y capacidad computacional en modelos más grandes, haciendo que la experiencia se consolide en los parámetros de la red neuronal. Este camino ha creado el salto cualitativo de los grandes modelos tras ChatGPT, pero también ha dejado un problema difícil: los modelos son cada vez más potentes, pero la razón de sus éxitos y fracasos sigue siendo, en muchos casos, difícil de explicar y corregir.
Los experimentos recientes del ingeniero de OpenAI, Weng Jiayi, proponen otra posibilidad: en entornos con objetivos claros, ejecutables y con un ciclo de retroalimentación cerrado, la IA no solo puede volverse más potente entrenando modelos, sino también "modificando código de forma autónoma".
El 8 de mayo de 2026, Weng Jiayi describió sistemáticamente este conjunto de experimentos en su blog personal "Learning Beyond Gradients", y publicó simultáneamente el repositorio de código, los registros experimentales en CSV y las grabaciones de video. Se ha especializado durante mucho tiempo en aprendizaje por refuerzo e infraestructura de post-entrenamiento, participó en el lanzamiento inicial de ChatGPT, y ha trabajado en proyectos como GPT-4, GPT-4 Turbo, GPT-4o, la serie o y GPT-5. Antes de unirse a OpenAI, se graduó en Ciencias de la Computación en la Universidad de Tsinghua y realizó su maestría en la Universidad Carnegie Mellon. También es el autor principal de la biblioteca de aprendizaje por refuerzo de código abierto Tianshou y del motor de entorno paralelo de alto rendimiento EnvPool.

Imagen generada por IA
Hizo que Codex escribiera repetidamente código de estrategias, ejecutara entornos, leyera registros, revisara grabaciones y localizara fallos, para luego modificar el código, añadir pruebas y continuar con la evaluación. Tras múltiples iteraciones, Codex "desarrolló" un conjunto de estrategias programáticas en Python puro: consiguió la puntuación teórica máxima de 864 en Atari Breakout, y en entornos de simulación de control robótico como MuJoCo Ant y HalfCheetah, obtuvo resultados cercanos a los de los algoritmos comunes de aprendizaje por refuerzo profundo.
El verdadero punto importante de este conjunto de experimentos es una cuestión central: ¿es necesario que el aprendizaje ocurra siempre en los pesos de la red neuronal cuando el agente de codificación es lo suficientemente potente?
En estos experimentos, la experiencia se escribe en código, pruebas, registros y grabaciones, convirtiéndose en un sistema de software legible, modificable, revisable y auditable. Si esta dirección continúa siendo viable, el siguiente paso para la IA Agéntica podría no ser solo entrenar modelos más grandes, sino hacer que los modelos participen en el mantenimiento de un sistema de ingeniería en continua evolución.
01
Del ciclo de ingeniería de 387 puntos a la puntuación perfecta
Weng Jiayi escribió en su blog que el punto de partida de este experimento era en realidad una necesidad de ingeniería. Al mantener EnvPool en su tiempo libre, necesitaba una forma más barata que "ejecutar una red neuronal cada vez" para probar si el entorno de juego funcionaba correctamente, porque incluir redes neuronales en la integración continua (CI) era demasiado caro. El problema original era: ¿se puede escribir una regla heurística barata, reproducible y claramente superior a una estrategia aleatoria, que lleve al entorno a estados ricos en información?

Intentó usar Codex (modelo base gpt-5.4) para escribir una versión completamente basada en reglas. El primer prompt fue muy directo: "Escribe una estrategia que resuelva Breakout". El resultado no fue ideal. La baja puntuación no proporcionaba ninguna información: podía haber un error en la semántica de las acciones, en la detección de estados, en el flujo de evaluación, o la estructura de la estrategia en sí podía ser demasiado débil.
Posteriormente, Weng Jiayi cambió la forma de la tarea. En lugar de pedir a Codex que entregara directamente un policy.py, le pidió que mantuviera un ciclo completo: detectar acciones y observaciones, escribir detectores de estado, escribir estrategias, ejecutar episodios completos, registrar trials.jsonl y summary.csv, generar videos o gráficos, revisar modos de fallo, modificar estrategias, simplificar código, ejecutar regresiones.
El registro experimental de Breakout documenta este proceso con gran claridad. En la primera ronda, Codex confirmó primero el espacio de acciones y la forma de las observaciones, identificó los colores de la pelota, la paleta y los ladrillos en los fotogramas RGB, y luego usó etiquetas de imagen para escanear la RAM de 128 bytes del Atari. La línea base inicial solo obtuvo 99 puntos. Después de añadir lógica de compensación del túnel, la puntuación subió a 387 puntos.
387 puntos es una puntuación localmente alta que puede llevar a un juicio erróneo. La estrategia ya podía atrapar la pelota de forma estable, pero la trayectoria de esta quedaba atrapada en un ciclo periódico: no perdía vidas, pero tampoco golpeaba nuevos ladrillos, y la puntuación se estancaba. Si un humano escribiera el código, podría seguir ajustando la "precisión para atrapar la pelota". Codex, después de ver el video y las últimas decenas de pasos, identificó el problema como la falta de perturbación en la trayectoria de la pelota.
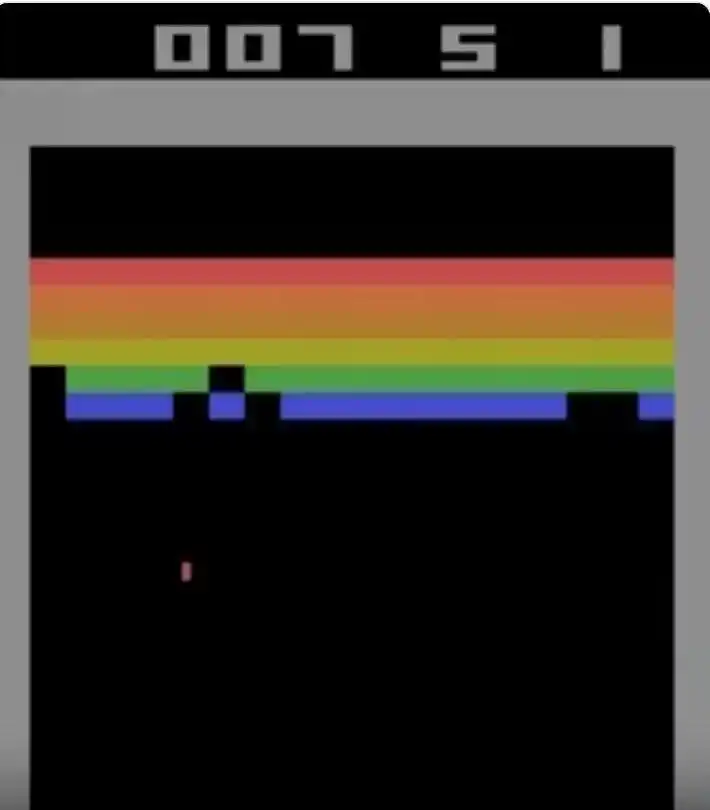
Figura: Pantalla del juego Atari Breakout. El jugador controla una paleta en la parte inferior para hacer rebotar una pelota y romper filas de ladrillos de colores en la parte superior. Codex alcanzó la puntuación teórica perfecta de 864 puntos en este juego.
Luego, Codex añadió un mecanismo para "romper el ciclo": si no se obtenían recompensas durante un tiempo prolongado, se añadía periódicamente un desplazamiento a la predicción del punto de impacto para sacar la pelota del ciclo local. La puntuación saltó de 387 a 507. Durante iteraciones posteriores surgió un nuevo problema: para pelotas bajas y rápidas, la interceptación convencional hacía que la paleta "se adelantara demasiado" y se desviara. Codex añadió el parámetro fast_low_ball_lead_steps=3, y la puntuación saltó de 507 a 839. El último salto, de 839 a 864, se pareció más a mantener un sistema que ya se había vuelto complejo: probó bandas muertas, compensación del saque, compensación del bloqueo, sesgo de equilibrio de ladrillos, pasos de previsión; muchas direcciones no dieron resultado, y el cambio útil final fue una condición tardía: "Después de romper la primera pared de ladrillos, habilitar la compensación del bloqueo solo cuando la pelota está lejos de la paleta, y liberarla gradualmente cuando se acerca".
La configuración predeterminada final de la RAM produjo de forma estable 864 / 864 / 864 puntos en tres episodios, alcanzando el límite teórico de Breakout. Codex luego migró el mismo controlador geométrico a una versión con entrada puramente visual: sin leer la RAM, solo identificando la paleta, la pelota y el equilibrio de ladrillos mediante segmentación RGB. La versión visual obtuvo 310 puntos en la primera ejecución, luego 428, y alcanzó 864 puntos después del séptimo episodio local, correspondiente a 14,504 pasos locales del entorno de estrategia.
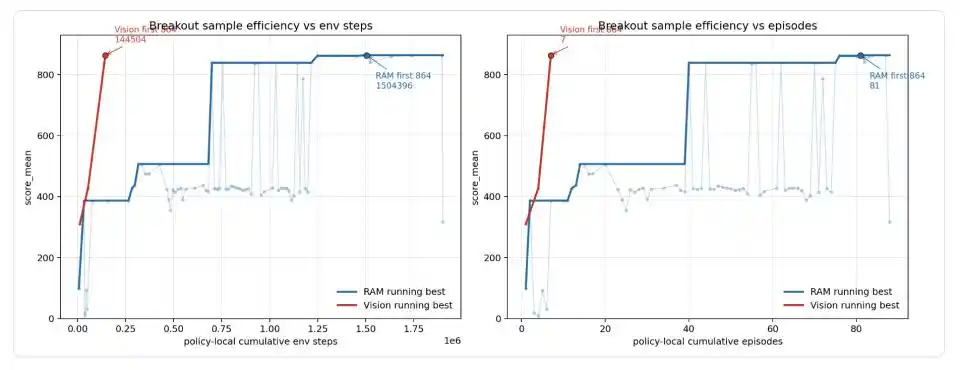
Figura: Curva de eficiencia de muestras de Codex en Breakout. La línea azul es la versión que lee directamente la memoria del juego (RAM), la línea roja es la versión que solo mira la pantalla (Visión). La versión RAM experimentó múltiples saltos (99 → 387 → 507 → 839 → 864), alcanzando finalmente la puntuación perfecta por primera vez en el episodio 81, tras acumular 1.5 millones de pasos de entorno. La versión Visión, al migrar desde la estructura madura de la versión RAM, alcanzó los 864 puntos con solo 7 episodios y aproximadamente 14,500 pasos de entorno.
Weng Jiayi destaca especialmente que esto no debe entenderse como que "la entrada visual partió de cero y usó solo 14.5K pasos para alcanzar la puntuación perfecta". El flujo real es que Codex descubrió primero el controlador geométrico, la ruptura de ciclos y la liberación tardía de compensación en la versión RAM; solo después de que la estructura se estabilizó, cambió la capa de lectura de estado de RAM a RGB. Los 14.5K son el presupuesto de migración para la versión visual.
02
Definición del Aprendizaje Heurístico
Encontrar un nombre para esta "estrategia de software" en constante evolución fue más difícil que escribir la primera versión de la estrategia. Weng Jiayi finalmente nombró este proceso como Aprendizaje Heurístico (HL, por sus siglas en inglés), y llamó al objeto que mantiene como Sistema Heurístico (HS).
Según su definición en el blog, el HL está compuesto por código de programa y, al igual que el aprendizaje por refuerzo profundo común hoy en día, tiene un ciclo de estado, acción, retroalimentación y actualización. La diferencia es que el objeto que se actualiza es la estructura de software, no los parámetros de la red neuronal; su retroalimentación es digerida por el agente de codificación y puede provenir de recompensas del entorno, casos de prueba, registros, videos, grabaciones o retroalimentación humana; su actualización no utiliza retropropagación, sino que el agente de codificación edita directamente la estrategia, los detectores de estado, las pruebas, la configuración o la memoria.
Es necesario añadir que el concepto de "usar programas en lugar de redes neuronales como estrategias" no es una creación original de Weng Jiayi. El mundo académico ha discutido durante años el Aprendizaje por Refuerzo Programático (Programmatic RL): el marco PROPEL, propuesto en 2019 por la Universidad de Rice y Caltech, investigaba métodos de aprendizaje por refuerzo que representaban la estrategia como programas cortos en un lenguaje simbólico; el trabajo LEAPS de 2021 avanzó aprendiendo espacios de incrustación de programas, combinando estrategias programáticas diferenciables con entrenamiento RL; HPRL de ICML 2023 propuso aprendizaje por refuerzo programático jerárquico, permitiendo que una meta-estrategia combinara múltiples programas; el marco LLM-GS de 2024, de la Universidad Nacional de Taiwán y Microsoft, utilizó la capacidad de programación y el razonamiento de sentido común de los LLM para guiar la búsqueda de estrategias RL programáticas.
El consenso de estas investigaciones es que, en comparación con las estrategias neuronales, las estrategias programáticas poseen una mejor explicabilidad, capacidad de verificación formal y capacidad de generalización a escenarios no vistos.
La contribución sustancial de Weng Jiayi esta vez radica en considerar al agente de codificación como un canal de ingeniería que mantiene un sistema heurístico. En el pasado, al hacer RL programático, se dependía de lenguajes específicos de dominio diseñados manualmente o de algoritmos de búsqueda en espacios de programa restringidos. Weng Jiayi, en cambio, utiliza Codex para integrar código, registros, pruebas, grabaciones de video y ajustes de parámetros en el mismo flujo de trabajo del agente, reduciendo de una vez el coste de iteración de las estrategias programáticas. En otras palabras, está argumentando una nueva vía de ingeniería: cuando el agente de codificación es lo suficientemente potente, aquellas estrategias heurísticas que antes se consideraban de "coste de mantenimiento demasiado alto" podrían volver a ser rentables.
Weng Jiayi proporciona una tabla comparativa en su blog, aclarando las diferencias entre HL y Deep RL: en forma de estrategia, el primero son reglas, máquinas de estado, controladores, control predictivo por modelo (MPC), macros de acción formando código, mientras que el segundo son parámetros de red neuronal; en forma de estado, el primero usa variables explícitas, detectores y caché, el segundo vectores de observación legibles por la red; en forma de retroalimentación, el primero considera pruebas, registros y grabaciones como señales válidas, el segundo depende principalmente de una función de recompensa fija; en forma de memoria, el primero puede almacenar explícitamente ensayos, resúmenes, causas de fallo y diferencias entre versiones, mientras que el segundo, en algoritmos on-policy, básicamente no tiene, y en algoritmos off-policy depende de un buffer de repetición.
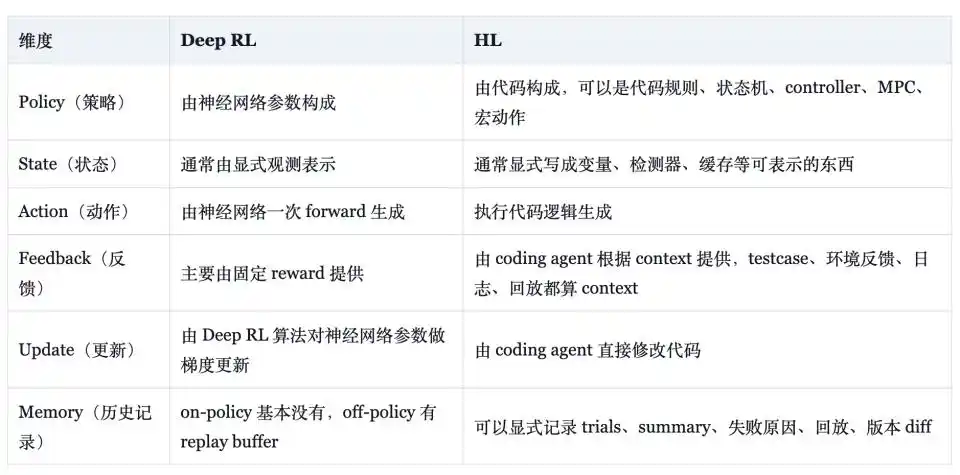
Esta comparación demuestra que el HL posee ciertas propiedades en términos de ingeniería: la estrategia es explicable y puede traducirse a lenguaje natural; la eficiencia de muestras se mide en unidades de "un cambio de código efectivo", no en lentas actualizaciones de gradiente; las capacidades antiguas pueden convertirse en pruebas de regresión, grabaciones con semilla fija o casos de referencia dorados; el sobreajuste a semillas de entrenamiento o vulnerabilidades de prueba puede restringirse mediante simplificación, comprobaciones de regresión y evaluación con múltiples semillas; las capacidades antiguas no tienen por qué residir solo en los pesos, también pueden residir en conjuntos de reglas y pruebas, abordando parcialmente el problema del olvido catastrófico que las redes neuronales no han resuelto bien a largo plazo.
03
Validación por lotes en Atari57: Límites y debilidades
Si solo se mira Breakout, la historia se puede simplificar fácilmente como "la IA escribió una estrategia perfecta". Pero Weng Jiayi no se detuvo en Breakout; extendió por lotes este flujo de trabajo de Codex a Atari57, ejecutando 57 juegos, dos modos de observación, tres repeticiones, para un total de 342 trayectorias de búsqueda "sin supervisión".
El diseño experimental fue bastante riguroso. Cada juego se probó con dos métodos de entrada: uno leyendo directamente la memoria del juego, y otro mirando solo la pantalla, cada método repetido de forma independiente tres veces. Esto generó un total de 342 trayectorias experimentales "sin supervisión": cada agente Codex recibía la misma plantilla de prompt, exploraba las acciones por sí mismo, escribía el código, ejecutaba el experimento y registraba los resultados, sin que nadie le diera pistas. Las restricciones estaban muy definidas: no entrenar redes neuronales, no leer el código fuente del juego, no usar información oculta, todos los pasos usados para depurar y experimentar debían contabilizarse en el coste total. Esto fue para evitar que Codex hiciera trampa de cualquier forma "mirando la respuesta".
Al medir los resultados, se usa típicamente una métrica llamada Puntuación Normalizada Humana (HNS): en términos simples, estandariza la puntuación de cada juego tomando como referencia "el nivel promedio del jugador humano = 1", facilitando la comparación entre diferentes juegos.
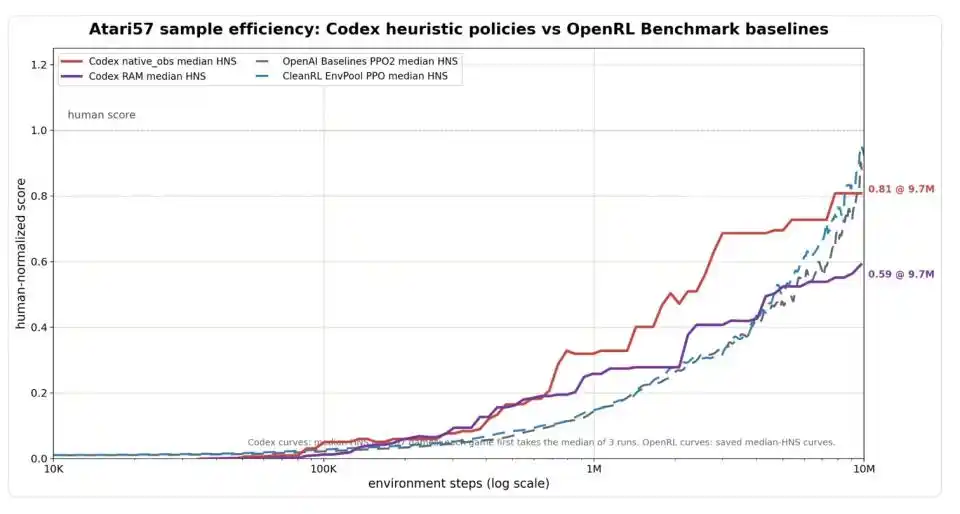
Figura: Comparación de eficiencia de muestras en el conjunto completo Atari57. El eje horizontal es el número de pasos de entorno (escala logarítmica), el eje vertical es HNS (puntuación normalizada humana, 1.0 indica alcanzar el nivel promedio de un jugador humano). La versión de entrada visual de Codex (línea roja) es claramente superior en eficiencia temprana a la línea base PPO (líneas discontinuas azul/gris), alcanzando 0.81 a los 9.7 millones de pasos, cercano al nivel de PPO alrededor de los 10 millones de pasos; la versión de entrada de memoria de Codex (línea púrpura) converge en 0.59.
Según este estándar, Codex parece bastante impresionante en eficiencia temprana. Con solo 1 millón de pasos de entorno consumidos, la mediana HNS de Codex con entrada visual ya era 0.32, y con entrada de memoria 0.26, significativamente más alta que los niveles de algoritmos clásicos de aprendizaje por refuerzo como PPO en la misma etapa. A los 9.7 millones de pasos, la versión visual de Codex alcanzó 0.81, ya cercana al nivel de PPO alrededor de 0.88 a 0.92 a los 10 millones de pasos. Si se permite agregar eligiendo, para cada juego, el modo de entrada en el que Codex tuvo mejor rendimiento, la mediana HNS de Codex fue 0.83, OpenAI Baselines PPO2 fue 0.80, CleanRL EnvPool PPO fue 0.98, prácticamente un empate.
Pero el propio Weng Jiayi traza un límite con mucha cautela: esto es solo una comparación de eficiencia de interacción con el entorno; no se han contabilizado los costes de Codex leyendo registros, escribiendo código o viendo videos. "Ejecutarse rápido" no es igual a "coste total bajo"; esto último sigue siendo una caja negra.
Lo más interesante es que el rendimiento de Codex en los 57 juegos no es uniforme. En juegos con estructura geométrica clara como Breakout, Boxing, Krull, tanto las estrategias heurísticas como el aprendizaje por refuerzo profundo superan claramente el nivel humano; en juegos con reglas claras como Asterix, Jamesbond, Tennis, las estrategias heurísticas son incluso más fuertes; pero en juegos rápidos y complejos como Atlantis, VideoPinball, RoadRunner, StarGunner, PPO sigue siendo abrumadoramente superior.
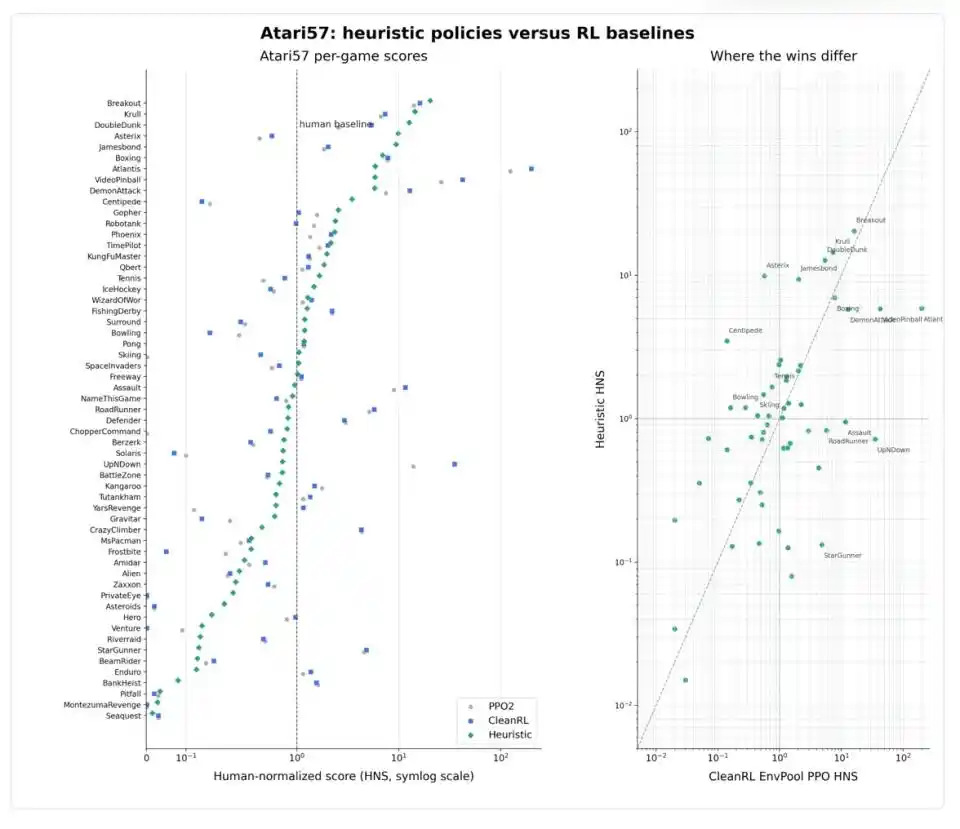
El contraejemplo más revelador es Montezuma’s Revenge. Este es un famoso "hueso duro" en el campo del aprendizaje por refuerzo: el protagonista necesita encontrar llaves, esquivar enemigos y abrir puertas en un laberinto subterráneo complejo, con señales de recompensa extremadamente escasas. Es un problema clásico de "planificación a largo plazo + recuperación de fallos". Codex obtuvo efectivamente 400 puntos en este juego, pero al abrir el archivo de estrategia generado, se descubre que no es una verdadera "estrategia", sino una secuencia codificada de 86 acciones, correspondiente a 1,769 pasos de entorno: se parece más a memorizar una ruta fija que a aprender a navegar por el laberinto. Weng Jiayi señala especialmente: "Este es un caso límite y no debe interpretarse como una estrategia general para Montezuma."
Montezuma expone el límite de expresividad del Aprendizaje Heurístico. Las estrategias programáticas ordinarias son esencialmente lógica reactiva de "hacer una acción al ver un estado", y es difícil manejar tareas que requieren secuencias de acción estrictas, continuar planes desde estados intermedios o planificación de largo alcance. Este tipo de tareas necesita no solo más if-else, sino estructuras programáticas más cercanas a "combinación de macros + estados de búsqueda recuperables + memoria a largo plazo". Esto nos dice algo: por muy potente que sea el agente de codificación, algunos problemas no caben en código ordinario.
04
Si el paradigma se establece, ¿cuál es su significado industrial?
Volviendo a la perspectiva industrial. Si realmente se consolida el camino del Aprendizaje Heurístico, es decir, "el agente de codificación puede mantener de forma estable estrategias programáticas que superen las reglas manuales y se acerquen a las líneas base de RL", ¿cuál es su significado práctico?
El primer punto de aplicación es el control robótico, especialmente en escenarios con estructura relativamente estable. La visión que Weng Jiayi presenta en su blog es una división jerárquica en HL a nivel de articulación, HL a nivel de extremidad, HL de equilibrio corporal completo, HL a nivel de tarea. Los niveles bajos manejan control de seguridad y baja latencia, los niveles medios manejan la marcha y el contacto, los niveles altos manejan tareas y memoria a largo plazo; el agente de codificación no necesita "entender cómo caminar", se parece más a un canal de actualización insertado en el sistema, que envía videos de fallos, flujos de sensores y resultados de simulación de vuelta al sistema, y luego reescribe la retroalimentación como código, parámetros, reglas de protección y memoria.
En escenarios como vehículos de guiado automático (AGV) en almacenes, robots de inspección, brazos robóticos industriales y clasificación estandarizada, donde la estructura ambiental es relativamente fija y los límites de seguridad están claros, si la estrategia central de control puede solidificarse como código ligero, cada paso del robot no necesitaría ejecutar una gran red de estrategia, reduciendo la dependencia de las GPU de alta potencia en el despliegue y trasladando más carga a controladores tradicionales y lógica de programa local.
Esto no significa que los robots no necesiten GPU; la percepción, localización, mapeo y comprensión semántica aún dependen de redes neuronales. Lo que cambia es el rol de la GPU, pasando de "quemar capacidad computacional cada segundo para la toma de decisiones de extremo a extremo" a "actuar periódicamente en la percepción, simulación offline, generación de estrategias y análisis de anomalías".
El segundo punto de aplicación es la auditabilidad en escenarios críticos para la seguridad. El problema de ingeniería más espinoso de las estrategias neuronales es la imposibilidad de localizar el error tras un fallo. Si un brazo robótico falla repentinamente en cierto ángulo, un coche comete un error de juicio en un caso límite, o un robot médico actúa de forma anómala en una postura rara, los ingenieros no pueden responder "qué peso causó este error". Finalmente, solo pueden añadir datos, reentrenar, ejecutar pruebas de regresión, y confiar en que el nuevo modelo no introduzca nuevos problemas.
Si la estrategia existe en forma de código, las variables de estado, las ramas condicionales, los registros de fallos y las pruebas de regresión son visibles; una acción peligrosa puede prohibirse mediante codificación dura, un caso límite puede escribirse como prueba, una transición de estado errónea puede repararse por separado. Esto no hace que el sistema sea inherentemente más seguro, pero permite que los problemas de seguridad entren por primera vez en un flujo normal de ingeniería de software: pueden revisarse en código, interceptarse en CI y ser respondidos por equipos de SRE en guardia. En áreas que requieren regulación y división de responsabilidades, como conducción autónoma, brazos robóticos industriales y robots médicos, esta auditabilidad en sí misma tiene valor comercial.
El tercer punto de aplicación es la ingenierización del aprendizaje continuo y en línea. Weng Jiayi plantea esta línea como el argumento principal de todo el artículo en su blog. El olvido catastrófico de las redes neuronales es un problema estructural: al aprender cosas nuevas, las capacidades antiguas se pierden. El HL también puede olvidar, pero de una forma más ingenieril: una nueva regla repara un modo de fallo pero rompe un escenario antiguo; una nueva memoria guía repetidamente al agente en una dirección errónea; el alcance de una prueba es demasiado estrecho y la estrategia aprende a aprovecharlo; un parche modifica una interfaz compartida y las rutas de llamada antiguas fallan silenciosamente.
Estos problemas no desaparecen automáticamente, pero son problemas que la ingeniería de software ha manejado durante décadas, con herramientas existentes: pruebas de regresión, diferencias entre versiones, grabaciones con semilla fija, trazas de referencia doradas, direcciones de fallo registradas explícitamente.
Un HS saludable debe realizar simultáneamente dos operaciones: absorber nueva retroalimentación y comprimir parches históricos; un HS que solo crece sin reducirse eventualmente se convertirá en una "bola de lodo de código" que nadie se atreve a tocar. En otras palabras, el HL transforma el problema matemático de "cómo actualizar parámetros" en el problema de ingeniería de "cómo mantener un sistema de software que absorbe retroalimentación constantemente".
Esto último no es necesariamente más fácil, pero está más cerca de los límites de capacidad que los humanos ya poseen.
El cuarto punto de aplicación es la sedimentación de capacidades en productos Agente. Lo que más falta actualmente a los productos Agente son llamadas a herramientas estables, cadenas de ejecución confiables, experiencias de fallo reutilizables y registros de tareas auditables. Si la lógica del HL es válida, la memoria del Agente durante la ejecución se sedimentará como activos de código reutilizables entre sesiones, usuarios y tareas. Esto se puede conectar directamente a los flujos DevOps existentes, y también significa que los Agentes de diferentes empresas y equipos pueden compartir heurísticas sin necesidad de compartir modelos, algo que el enfoque de redes neuronales no puede lograr.
Sin embargo, es necesario enfatizar: los cuatro puntos anteriores dependen de que el camino del HL sea validado aún más en tareas más complejas. Breakout y Ant son entornos relativamente limpios; los robots reales enfrentan cambios en la fricción del suelo, cambios en la iluminación, retrasos en los actuadores y ruido en los sensores, aspectos que aún no han sido evaluados sistemáticamente en materiales públicos. El contraejemplo de Montezuma ya muestra que las tareas de largo alcance requieren formas programáticas que van más allá del simple if-else. Hasta dónde puede llegar esta visión dependerá de los experimentos en la próxima etapa.
05
La deuda técnica se traslada de los pesos al código
El juicio de Weng Jiayi en su blog es muy comedido. Escribe que el HL no puede realizar todo lo que hacen las redes neuronales; está limitado por lo que el código puede expresar, especialmente en percepción compleja y generalización de largo alcance. Con el conocimiento actual, no puede imaginar un agente que use solo código Python puro, sin ninguna red neuronal, para resolver ImageNet. El problema realmente digno de discusión es cómo combinar redes neuronales y HL para abordar conjuntamente el aprendizaje en línea y continuo.
La división que propone utiliza el lenguaje de Sistema 1 / Sistema 2: redes neuronales especializadas y superficiales asumen parte del Sistema 1, responsable de percepción rápida, clasificación y estimación del estado de objetos; el HL también asume parte del Sistema 1, responsable de procesamiento de datos nuevos, reglas, pruebas, grabaciones, memoria, límites de seguridad y recuperación local; el agente LLM actúa como Sistema 2, proporcionando retroalimentación al HL, mejorando datos y, periódicamente, extrayendo información de los datos generados por el HL para actualizarse a sí mismo.
Si el aprendizaje profundo de la última década demostró que "la experiencia puede comprimirse en pesos", entonces la hipótesis que Weng Jiayi plantea esta vez es otra proposición: en la era de los agentes de codificación, la experiencia tal vez pueda volver a convertirse en software legible, modificable y probable.
Este artículo proviene del WeChat Official Account "Tencent Technology", autor: Xiao Jing, editor: Xu Qingyang






