Una línea de import, el ajuste fino de modelos grandes MoE se acelera 3.7 veces.
La última investigación de NVIDIA ya es de código abierto: NeMo AutoModel, diseñado específicamente para construir y ajustar modelos de IA generativa a gran escala.
Basándose en Hugging Face Transformers v5, NeMo AutoModel puede lograr un ajuste fino más rápido para modelos MoE sin modificar el código de la API, simplemente añadiendo una línea de import.

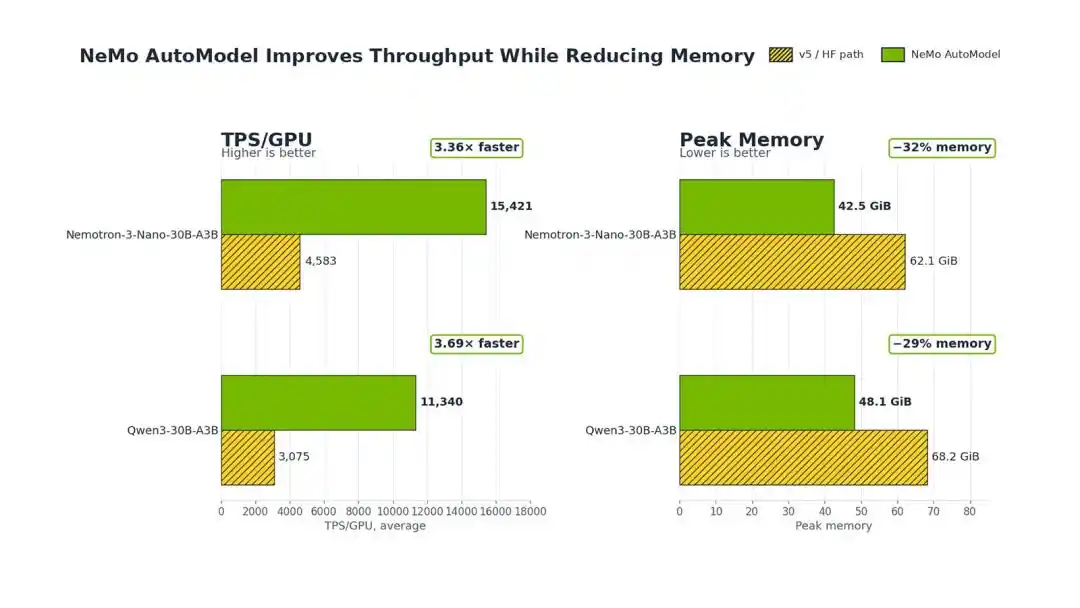
Los experimentos muestran que, en comparación con la versión original de Transformers v5 de Hugging Face, el NeMo AutoModel de NVIDIA puede lograr un aumento de 3.4 a 3.7 veces en el rendimiento de entrenamiento durante el ajuste fino de MoE, y reducir el uso de memoria GPU entre un 29% y un 32%.
En un solo nodo con 8 GPUs H100 de 80 GB, tomando como ejemplo el Qwen3-30B-A3B, NeMo AutoModel elevó directamente el TPS/GPU (rendimiento por GPU por segundo) de 3075 a 11340, un aumento de 3.69 veces.
Análisis de la tecnología central
MoE se ha convertido en la arquitectura principal de los modelos de vanguardia actuales, pero MoE también plantea nuevos desafíos para el entrenamiento eficiente:
Paralelismo de expertos, fusión de comunicaciones, optimización de kernels... Estas complejas ingenierías requieren infraestructuras complementarias para su soporte.
Transformers v5 de HuggingFace es actualmente la "base universal" de entrenamiento MoE más utilizada. La versión v5 mejoró el soporte nativo para MoE, introduciendo capacidades básicas como backends de expertos, carga dinámica de pesos, ejecución distribuida, etc.

Esta vez, el enfoque de NVIDIA es apoyarse en los hombros de sus predecesores, manteniendo compatibilidad con la API de HuggingFace Transformers, permitiendo que todos puedan obtener un mayor rendimiento de entrenamiento y un menor uso de memoria durante el ajuste fino de MoE sin realizar grandes cambios en el código.
Concretamente, NeMo AutoModel añade, sobre la base de Transformers v5, Paralelismo de Expertos (EP), DeepEP y TransformerEngine.
Paralelismo de Expertos (Expert Parallelism)
La tecnología de paralelismo de expertos se utiliza principalmente para reducir la presión sobre la memoria.
EP distribuye los pesos de los expertos entre múltiples GPUs, de modo que cada GPU ya no contiene todos los parámetros de los expertos, sino solo una parte de ellos.
Por ejemplo, en 8 GPUs con ep_size=8, los pesos de los expertos se distribuyen entre las 8 GPUs, y el uso de memoria MoE en cada GPU puede reducirse a 1/8 del original.
Según los resultados experimentales, para Qwen3, esta tecnología puede reducir la memoria máxima de 68.2 GiB a 48.1 GiB, una disminución del 29%.
Para el modelo Nemotron Nanomo, el uso de memoria se redujo de 62.1 GiB a 42.5 GiB, una disminución del 32%.
El espacio liberado puede usarse para admitir lotes más grandes o secuencias más largas.
DeepEP
DeepEP logra la fusión de cálculo y comunicación.
En el método tradicional, existe un coste de comunicación evidente entre la distribución de tokens y el cálculo de expertos. DeepEP integra las operaciones de distribución y combinación de tokens en kernels GPU optimizados, logrando la superposición del proceso de comunicación con el cálculo de expertos.
TransformerEngine
El kernel TransformerEngine proporciona aceleración para diversas operaciones centrales.
Esta tecnología proporciona implementaciones fusionadas para mecanismos de atención, capas lineales, RMSNorm, etc., acelerando no solo las capas MoE, sino también las capas Transformer ordinarias.
Una línea de import, mejora de velocidad 3 veces
En resumen, para aquellos que ya usaban Transformers v5, NVIDIA NeMo AutoModel ofrece una solución de actualización sin dolor:
Solo hay que añadir una línea de código de import para obtener una mejora de velocidad de 3 veces en el ajuste fino de MoE.

En Qwen3-30B-A3B y Nemotron 3 Nano 30B-A3B, en comparación con Transformers v5, esta solución puede lograr un aumento de 3.4 a 3.7 veces en el rendimiento de entrenamiento, mientras reduce el consumo de memoria entre un 29% y un 32%.
NVIDIA también mostró resultados de ajuste fino completo de parámetros para Nemotron 3 Ultra 550B A55B en 16 nodos H100 con 128 GPUs.
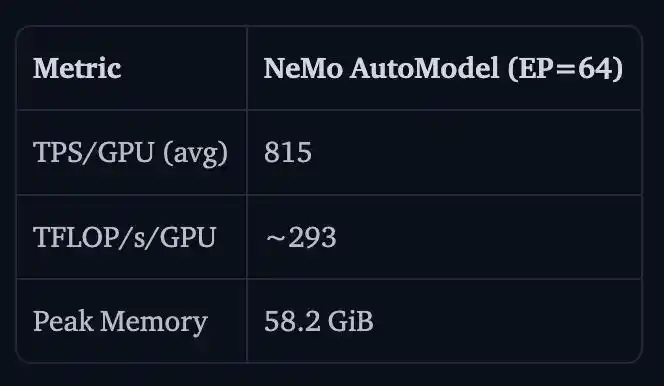
El TPS/GPU fue de 815, el TFLOP/s/GPU fue de aproximadamente 293, y la memoria máxima fue de 58.2 GiB.
La razón por la que no se comparó con v5 aquí es que Transformers v5 directamente saturaría la memoria a esta escala ̄_(ツ)_/ ̄
Si estás interesado, NVIDIA ya ha subido el código, configuraciones y scripts de pruebas de referencia a GitHub: https://github.com/NVIDIA-NeMo/Automodel/tree/blog/transformers-v5-automodel/blog_experiments
La guía de uso específica está aquí: https://docs.nvidia.com/nemo/automodel/latest/get-started/hf-compatibility
Este artículo proviene del WeChat público "Qubit", autor: Yu Yang






