Autor: Li Hailun, Su Yang
El 6 de enero, hora de Pekín, el CEO de NVIDIA, Jensen Huang, vistiendo su característica chaqueta de cuero, volvió a subirse al escenario principal de CES2026.
En el CES de 2025, NVIDIA mostró el chip Blackwell en producción y una pila tecnológica completa de IA física. En esa ocasión, Huang enfatizó que se estaba abriendo una "era de la IA física". Pintó un futuro lleno de imaginación: coches autónomos con capacidad de razonamiento, robots que pueden entender y pensar, y agentes de IA (Agentes Inteligentes) capaces de manejar tareas de contexto largo con millones de tokens.
Un año después, la industria de la IA ha experimentado una enorme transformación y evolución. Al repasar estos cambios en la presentación, Huang se refirió especialmente a los modelos de código abierto.
Dijo que modelos de razonamiento de código abierto como DeepSeek R1 han hecho que toda la industria se dé cuenta de que, cuando la colaboración abierta y global realmente despega, la difusión de la IA es extremadamente rápida. Aunque los modelos de código abierto aún están unos seis meses por detrás de los modelos más avanzados en capacidad general, se acercan cada seis meses, y sus descargas y uso ya han experimentado un crecimiento explosivo.

Comparado con 2025, donde se mostraron más visiones y posibilidades, esta vez NVIDIA comenzó a abordar sistemáticamente el problema de "cómo implementarlo": en torno a la IA de razonamiento, complementando la infraestructura de computación, red y almacenamiento necesaria para su ejecución a largo plazo, reduciendo significativamente los costes de inferencia e integrando estas capacidades directamente en escenarios reales como la conducción autónoma y la robótica.
El discurso de Huang en el CES se desarrolló en torno a tres líneas principales:
● A nivel de sistema e infraestructura, NVIDIA rediseñó la arquitectura de computación, red y almacenamiento en torno a las necesidades de inferencia a largo plazo. Con la plataforma Rubin, NVLink 6, Spectrum-X Ethernet y la plataforma de almacenamiento de memoria de contexto de inferencia como núcleo, estas actualizaciones apuntan directamente a los cuellos de botella del alto coste de inferencia, la dificultad de mantener el contexto de forma continua y las limitaciones de escalabilidad, resolviendo los problemas de que la IA "piense un poco más", sea asequible de computar y funcione durante más tiempo.
● A nivel de modelo, NVIDIA situó a la IA de razonamiento (Reasoning / Agentic AI) en una posición central. A través de modelos y herramientas como Alpamayo, Nemotron, Cosmos Reason, impulsan a la IA a pasar de "generar contenido" a ser capaz de pensar de forma sostenida, y de "modelos que responden una vez" a "agentes inteligentes que pueden trabajar a largo plazo".
● A nivel de aplicación e implementación, estas capacidades se introducen directamente en escenarios de IA física como la conducción autónoma y la robótica. Tanto el sistema de conducción autónoma impulsado por Alpamayo como el ecosistema robótico GR00T y Jetson, están impulsando el despliegue a escala mediante la colaboración con plataformas empresariales y proveedores de la nube.

01 De la hoja de ruta a la producción: Rubin revela por primera vez datos completos de rendimiento
En este CES, NVIDIA reveló por primera vez los detalles técnicos completos de la arquitectura Rubin.
En su discurso, Huang comenzó con el concepto de Test-time Scaling (Escalado en tiempo de prueba), que puede entenderse como que, para que la IA se vuelva más inteligente, ya no se trata de "hacer que estudie más", sino de "dejarla pensar un poco más cuando se enfrente a un problema".
En el pasado, la mejora de la capacidad de la IA dependía principalmente de utilizar más potencia de cálculo en la fase de entrenamiento, haciendo modelos cada vez más grandes; ahora, el nuevo cambio es que incluso si el modelo deja de crecer, siempre que se le dé un poco más de tiempo y potencia de cálculo para pensar en cada uso, los resultados también pueden mejorar notablemente.
¿Cómo hacer que "la IA piense un poco más" sea económicamente viable? La nueva plataforma de computación de IA de arquitectura Rubin viene a resolver este problema.
Huang presentó un sistema completo de computación de IA de próxima generación, diseñado de forma coordinada con la CPU Vera, la GPU Rubin, NVLink 6, ConnectX-9, BlueField-4 y Spectrum-6, para lograr una caída revolucionaria en el coste de inferencia.

La GPU Rubin de NVIDIA es el chip central responsable del cálculo de IA en la arquitectura Rubin, con el objetivo de reducir significativamente el coste unitario de inferencia y entrenamiento.
En pocas palabras, la tarea central de la GPU Rubin es "hacer que la IA sea más barata y más inteligente de usar".
La capacidad central de la GPU Rubin reside en que la misma GPU puede hacer más trabajo. Puede procesar más tareas de inferencia a la vez, recordar contextos más largos y la comunicación con otras GPU también es más rápida, lo que significa que muchos escenarios que antes requerían "apilar muchas tarjetas" ahora se pueden completar con menos GPU.
El resultado es que la inferencia no sólo es más rápida, sino también notablemente más barata.
Huang repasó en el escenario los parámetros hardware del NVL72 de arquitectura Rubin: contiene 220 billones de transistores, un ancho de banda de 260 TB/s, y es la primera plataforma a escala de rack que admite computación confidencial.

En general, en comparación con Blackwell, la GPU Rubin logra un salto generacional en indicadores clave: el rendimiento de inferencia NVFP4 aumenta a 50 PFLOPS (5 veces), el rendimiento de entrenamiento a 35 PFLOPS (3.5 veces), el ancho de banda de memoria HBM4 a 22 TB/s (2.8 veces), y el ancho de banda de interconexión NVLink por GPU se duplica a 3.6 TB/s.
Estas mejoras actúan conjuntamente para permitir que una sola GPU procese más tareas de inferencia y contextos más largos, reduciendo fundamentalmente la dependencia del número de GPU.

La CPU Vera es un componente central diseñado específicamente para el movimiento de datos y el procesamiento Agentic. Utiliza 88 núcleos Olympus de diseño propio de NVIDIA, está equipada con 1.5 TB de memoria del sistema (3 veces más que la CPU Grace anterior), y logra acceso coherente a la memoria entre la CPU y la GPU mediante la tecnología NVLink-C2C de 1.8 TB/s.
A diferencia de las CPU genéricas tradicionales, Vera se centra en la planificación de datos y el procesamiento de lógica de razonamiento de múltiples pasos en escenarios de inferencia de IA, siendo esencialmente el coordinador del sistema que permite que "la IA piense un poco más" se ejecute de manera eficiente.
NVLink 6, con un ancho de banda de 3.6 TB/s y capacidad de computación en la red, permite que las 72 GPU en la arquitectura Rubin trabajen de forma cooperativa como una super GPU, siendo una infraestructura clave para lograr reducir el coste de inferencia.
De este modo, los datos y resultados intermedios que la IA necesita durante la inferencia pueden fluir rápidamente entre las GPU, sin tener que esperar, copiar o recalcar repetidamente.


En la arquitectura Rubin, NVLink-6 se encarga del cómputo cooperativo interno de la GPU, BlueField-4 de la planificación de contexto y datos, y ConnectX-9 asume la conexión de red externa de alta velocidad del sistema. Garantiza que el sistema Rubin pueda comunicarse eficientemente con otros racks, centros de datos y plataformas en la nube, siendo un prerrequisito para el funcionamiento fluido de tareas de entrenamiento e inferencia a gran escala.
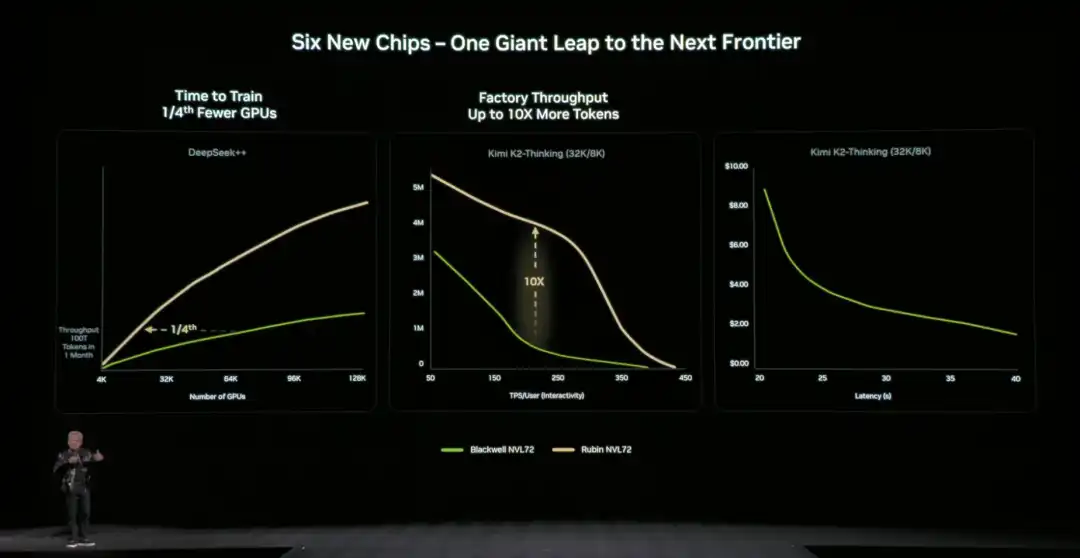
En comparación con la arquitectura anterior, NVIDIA también proporciona datos concretos y直观: en comparación con la plataforma NVIDIA Blackwell, puede reducir el coste por token en la fase de inferencia hasta 10 veces, y reducir el número de GPU necesarias para entrenar modelos de expertos mixtos (MoE) a una cuarta parte.
NVIDIA indicó oficialmente que Microsoft ya se ha comprometido a desplegar cientos de miles de chips Vera Rubin en su próxima fábrica super inteligente Fairwater, y proveedores de servicios en la nube como CoreWeave ofrecerán instancias Rubin en la segunda mitad de 2026. Esta infraestructura para "dejar que la IA piense un poco más" está pasando de demostraciones técnicas a implementación comercial a escala.

02 ¿Cómo se resuelve el "cuello de botella del almacenamiento"?
Dejar que la IA "piense un poco más" también plantea un desafío tecnológico clave: ¿dónde se deben colocar los datos de contexto?
Cuando la IA procesa tareas complejas que requieren diálogos de múltiples turnos o razonamiento de múltiples pasos, genera una gran cantidad de datos de contexto (KV Cache). La arquitectura tradicional los mete either en la memoria GPU, que es cara y tiene capacidad limitada, o en almacenamiento normal (demasiado lento para acceder). Si este "cuello de botella de almacenamiento" no se resuelve, incluso la GPU más potente se verá ralentizada.
Para abordar este problema, NVIDIA reveló por primera vez en este CES la Plataforma de Almacenamiento de Memoria de Contexto de Inferencia (Inference Context Memory Storage Platform) impulsada por BlueField-4, cuyo objetivo central es crear una "tercera capa" entre la memoria GPU y el almacenamiento tradicional. Que sea lo suficientemente rápida, tenga capacidad suficiente y pueda soportar el funcionamiento a largo plazo de la IA.
Desde la perspectiva de la implementación técnica, esta plataforma no es un único componente el que funciona, sino el resultado de un diseño coordinado:
- BlueField-4 se encarga de acelerar a nivel de hardware la gestión y el acceso a los datos de contexto, reduciendo el movimiento de datos y la sobrecarga del sistema;
- Spectrum-X Ethernet proporciona redes de alto rendimiento, admitiendo el intercambio de datos de alta velocidad basado en RDMA;
- Componentes de software como DOCA, NIXL y Dynamo, se encargan de optimizar la planificación a nivel del sistema, reducir la latencia y mejorar el rendimiento general.
Podemos entender que el enfoque de esta plataforma es expandir los datos de contexto, que antes solo podían residir en la memoria GPU, a una "capa de memoria" independiente, rápida y compartible. Por un lado, libera presión sobre la GPU, y por otro, permite compartir rápidamente esta información de contexto entre múltiples nodos y múltiples agentes de IA.
En cuanto a los efectos prácticos, los datos oficiales de NVIDIA indican que, en escenarios específicos, este enfoque puede aumentar el número de tokens procesados por segundo hasta 5 veces, y lograr un nivel equivalente de optimización de eficiencia energética.
Huang enfatizó多次 en la presentación que la IA está evolucionando de "chatbots de conversación única" a verdaderos colaboradores inteligentes: necesitan entender el mundo real, razonar de forma continua, invocar herramientas para completar tareas y retener memoria a corto y largo plazo. Estas son precisamente las características centrales de la IA Agentic. La Plataforma de Almacenamiento de Memoria de Contexto de Inferencia está diseñada para esta forma de IA de funcionamiento prolongado y pensamiento repetitivo, ampliando la capacidad de contexto y acelerando el intercambio entre nodos, haciendo que los diálogos de múltiples turnos y la colaboración multiagente sean más estables y no "se vuelvan más lentos con el tiempo".

03 La nueva generación de DGX SuperPOD: Haciendo que 576 GPU trabajen en conjunto
NVIDIA anunció en este CES el lanzamiento de la nueva generación de DGX SuperPOD (Supernodo) basada en la arquitectura Rubin, expandiendo Rubin de un solo rack a una solución completa para todo el centro de datos.
¿Qué es DGX SuperPOD?
Si el Rubin NVL72 es un "super rack" con 72 GPU, entonces el DGX SuperPOD es conectar múltiples de estos racks para formar un clúster de computación de IA a mayor escala. La versión anunciada esta vez consta de 8 racks Vera Rubin NVL72, equivalentes a 576 GPU trabajando en cooperación.
Cuando la escala de la tarea de IA continúa expandiéndose, las 576 GPU de un solo clúster de racks pueden no ser suficientes. Por ejemplo, para entrenar modelos a ultra gran escala, servir simultáneamente a miles de agentes de IA Agentic, o procesar tareas complejas que requieren contextos de millones de tokens. En ese caso, se necesitan múltiples racks trabajando juntos, y DGX SuperPOD está diseñado como una solución estandarizada para este escenario.
Para empresas y proveedores de servicios en la nube, DGX SuperPOD ofrece una solución de infraestructura de IA a gran escala "lista para usar". No necesitan investigar cómo conectar cientos de GPU, cómo configurar la red, cómo gestionar el almacenamiento, etc.
Los cinco componentes centrales de la nueva generación de DGX SuperPOD:
○8 racks Vera Rubin NVL72: proporcionan el núcleo de capacidad de computación, cada rack con 72 GPU, total 576 GPU;
○Red de expansión NVLink 6: permite que las 576 GPU en estos 8 racks trabajen de forma cooperativa como una super GPU;
○Red de expansión Spectrum-X Ethernet: conecta diferentes SuperPODs, y también con el almacenamiento y la red externa;
○Plataforma de Almacenamiento de Memoria de Contexto de Inferencia: proporciona almacenamiento compartido de datos de contexto para tareas de inferencia de larga duración;
○Software NVIDIA Mission Control: gestiona la planificación, monitorización y optimización de todo el sistema.
En esta actualización, la base del SuperPOD tiene como núcleo el sistema a nivel de rack DGX Vera Rubin NVL72. Cada NVL72 es en sí mismo una supercomputadora de IA completa, internamente conecta 72 GPU Rubin through NVLink 6, capaz de completar tareas de inferencia y entrenamiento a gran escala dentro de un rack. El nuevo DGX SuperPOD está formado por múltiples NVL72, formando un clúster a nivel de sistema que puede funcionar a largo plazo.
Cuando la escala de computación se expande de "un solo rack" a "múltiples racks", aparecen nuevos cuellos de botella: cómo transmitir establemente y eficientemente cantidades masivas de datos entre racks. En torno a este problema, NVIDIA lanzó同步 en este CES el nuevo conmutador Ethernet basado en el chip Spectrum-6, e introdujo por primera vez la tecnología "óptica encapsulada conjuntamente" (CPO).
En términos simples, consiste en encapsular directamente los módulos ópticos, que antes eran extraíbles, junto al chip del conmutador, reduciendo la distancia de transmisión de señal de metros a milímetros, lo que reduce significativamente el consumo de energía y la latencia, y también mejora la estabilidad general del sistema.
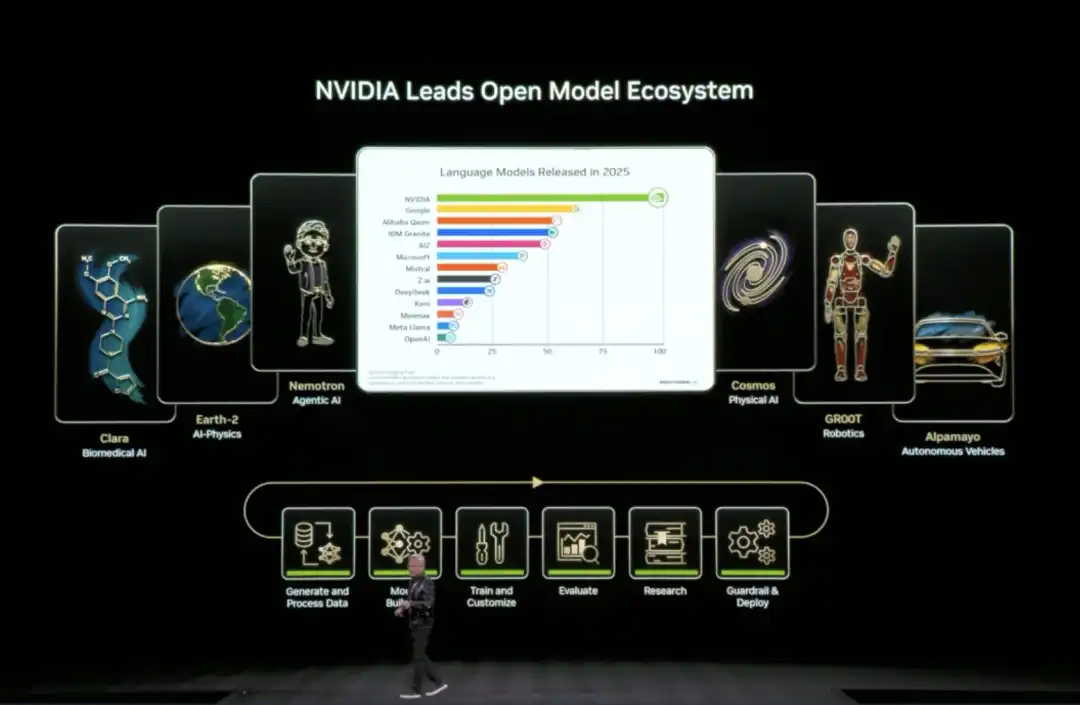
04 El "combo completo" de IA de código abierto de NVIDIA: De datos a código, todo incluido
En este CES, Huang anunció la expansión de su ecosistema de modelos de código abierto (Open Model Universe), añadiendo y actualizando una serie de modelos, conjuntos de datos, repositorios de código y herramientas. Este ecosistema cubre seis áreas: IA biomédica (Clara), simulación física de IA (Earth-2), IA Agentic (Nemotron), IA física (Cosmos), robótica (GR00T) y conducción autónoma (Alpamayo).
Entrenar un modelo de IA no solo requiere potencia de cálculo, sino también conjuntos de datos de alta calidad, modelos preentrenados, código de entrenamiento, herramientas de evaluación, etc., toda una infraestructura. Para la mayoría de empresas e instituciones de investigación, construir todo esto desde cero consume demasiado tiempo.
Concretamente, NVIDIA ha abierto seis niveles de contenido: plataformas de computación (DGX, HGX, etc.), conjuntos de datos de entrenamiento en varias áreas, modelos base preentrenados, bibliotecas de código de inferencia y entrenamiento, scripts de flujo de entrenamiento completos y plantillas de soluciones integrales.
La serie Nemotron es el foco de esta actualización, cubriendo cuatro direcciones de aplicación.
En la dirección de razonamiento, incluye modelos de inferencia pequeños como Nemotron 3 Nano, Nemotron 2 Nano VL, y herramientas de entrenamiento de aprendizaje por refuerzo como NeMo RL, NeMo Gym. En la dirección RAG (Generación Aumentada por Recuperación), proporciona Nemotron Embed VL (modelo de incrustación vectorial), Nemotron Rerank VL (modelo de reordenamiento), conjuntos de datos relacionados y la biblioteca de recuperación NeMo Retriever Library. En la dirección de seguridad, está el modelo de seguridad de contenido Nemotron Content Safety y su conjunto de datos complementario, y la biblioteca de barreras NeMo Guardrails.
En la dirección de voz, se incluye el reconocimiento automático de voz Nemotron ASR, el conjunto de datos de voz Granary Dataset y la biblioteca de procesamiento de voz NeMo Library. Esto significa que una empresa que quiera hacer un sistema de servicio al cliente de IA con RAG no necesita entrenar sus propios modelos de incrustación y reordenamiento, puede usar directamente el código que NVIDIA ya ha entrenado y abierto.
05 En el campo de la IA física, hacia la comercialización
El campo de la IA física también tiene actualizaciones de modelos: Cosmos, para理解和generar视频del mundo físico, el modelo base universal para robótica Isaac GR00T, y el modelo de visión-lenguaje-acción para conducción autónoma Alpamayo.

Huang afirmó en el CES que el "momento ChatGPT" de la IA física está cerca, pero los desafíos son muchos: el mundo físico es demasiado complejo y cambiante, recopilar datos reales es lento y caro, y nunca son suficientes.
¿Qué hacer? Los datos sintéticos son un camino. Así que NVIDIA lanzó Cosmos.
Este es un modelo base de mundo físico de IA de código abierto, que ya ha sido preentrenado con cantidades masivas de video, datos reales de conducción y robótica, y simulación 3D. Puede entender cómo funciona el mundo, puede conectar lenguaje, imágenes, 3D y acciones.
Huang表示 que Cosmos puede lograr varias habilidades de IA física, como generar contenido, hacer razonamiento, predecir trayectorias (incluso si solo se le da una imagen). Puede generar video realista basado en escenas 3D, generar movimiento que cumple las leyes físicas basado en datos de conducción, y también generar video panorámico a partir de simuladores, imágenes de múltiples cámaras o descripciones de texto. Incluso puede recrear escenas raras.
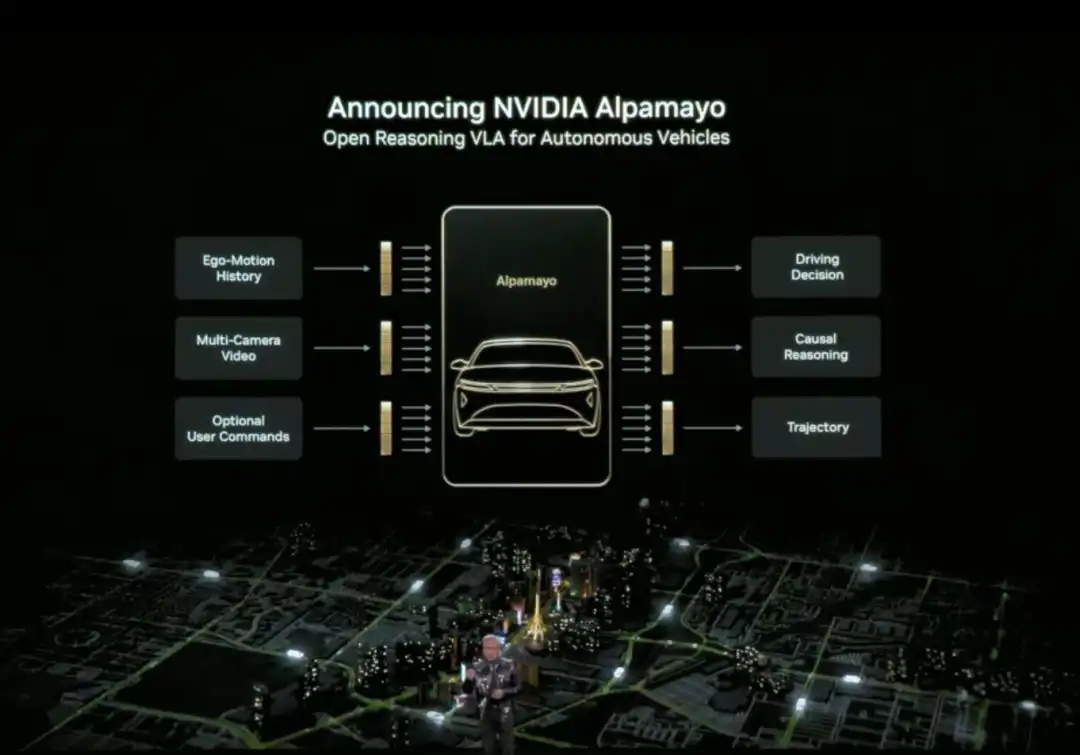
Huang también lanzó oficialmente Alpamayo. Alpamayo es una cadena de herramientas de código abierto para el campo de la conducción autónoma, y también el primer modelo de inferencia de visión-lenguaje-acción (VLA) de código abierto. A diferencia de antes, donde solo se abría el código, esta vez NVIDIA ha liberado todos los recursos de desarrollo completos, desde los datos hasta el despliegue.
El mayor avance de Alpamayo es que es un modelo de conducción autónoma "de razonamiento". Los sistemas tradicionales de conducción autónoma tienen una arquitectura en pipeline de "percepción-planificación-control": ven un semáforo en rojo y frenan, ven un peatón y reducen la velocidad, siguiendo reglas preestablecidas. Alpamayo introduce la capacidad de "razonamiento", entendiendo las relaciones causales en escenas complejas, prediciendo las intenciones de otros vehículos y peatones, e incluso pudiendo manejar decisiones que requieren pensamiento de múltiples pasos.
Por ejemplo, en una intersección, no solo reconoce que "hay un coche delante", sino que puede razonar "ese coche probablemente va a girar a la izquierda, así que debería esperar a que pase primero". Esta capacidad eleva la conducción autónoma de "conducir según reglas" a "pensar como un humano".
Huang anunció que el sistema NVIDIA DRIVE entra正式 en la fase de producción, siendo la primera aplicación el nuevo Mercedes-Benz CLA, planeado para circular en EE.UU. en 2026. Este coche estará equipado con un sistema de conducción autónoma de nivel L2++, adoptando una arquitectura híbrida de "modelo de IA de extremo a extremo + pipeline tradicional".
El campo de la robótica también tiene avances sustanciales.
Huang表示 que empresas líderes globales en robótica, incluyendo Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics y XRlabs, están desarrollando productos basados en la plataforma Isaac de NVIDIA y el modelo base GR00T, cubriendo múltiples áreas desde robots industriales, robots quirúrgicos hasta robots humanoides y robots de consumo.

En el escenario de la presentación, detrás de Huang había una multitud de robots de diferentes formas y usos, exhibidos集中 en un escenario escalonado: desde robots humanoides, robots de servicio bípedos y con ruedas, hasta brazos robóticos industriales, maquinaria de ingeniería, drones y equipos de asistencia quirúrgica, mostrando un "panorama del ecosistema robótico".
Desde las aplicaciones de IA física hasta la plataforma de computación RubinAI, pasando por la Plataforma de Almacenamiento de Memoria de Contexto de Inferencia y el "combo completo" de IA de código abierto.
Estas acciones mostradas por NVIDIA en el CES constituyen la narrativa de NVIDIA para la infraestructura de IA de la era del razonamiento. Como Huang enfatizó repetidamente, cuando la IA física necesita pensar de forma continua, funcionar a largo plazo y entrar realmente en el mundo real, el problema ya no es solo si hay suficiente potencia de cálculo, sino quién puede realmente construir todo el sistema.
En el CES 2026, NVIDIA ya ha dado una respuesta.







