Autor: IC3
Compilado por: Jiahuan, ChainCatcher
Conclusiones clave
La combinación significativa de IA y cripto aún se encuentra en una etapa muy temprana; el bullicio en torno a este campo interdisciplinario ha opacado los avances reales.
En la dirección Crypto x AI, la IA ya puede analizar y detectar propiedades clave de transacciones, eventos y protocolos existentes, identificando contratos inteligentes fraudulentos o con vulnerabilidades. Estas tecnologías suelen emplear métodos simples de aprendizaje automático y son más efectivas en entornos controlados con datos abundantes.
En la dirección AI x Crypto, las herramientas cripto ofrecen nuevas vías para proteger y gobernar los procesos de IA. Herramientas como las pruebas de conocimiento cero y la computación confiable pueden adaptarse para reducir el riesgo de manipulación de los resultados de IA. Sin embargo, conceptos como la gobernanza descentralizada y la gestión de infraestructuras descentralizadas aún no se han implementado verdaderamente en los círculos principales de IA.
La industria aún necesita demostrar dos aspectos.
Primero, la IA descentralizada debe contrastarse de manera más estricta y directa con las soluciones centralizadas en términos de costos. Actualmente, la industria se centra principalmente en demostrar que "es posible entrenar modelos grandes en entornos distribuidos", pero aún falta evidencia cuantitativa sobre oportunidades competitivas de costo frente a plataformas centralizadas en escenarios específicos.
Segundo, los pagos cripto deben demostrar su utilidad real en escenarios de pago de agentes frente a las soluciones centralizadas. Los pagos cripto siempre han carecido de un avance sustancial en el ámbito de los pagos, pero las tasas de pago de agentes son bajas y no necesitan adaptarse al modelo tradicional financiero de que "las cuentas deben pertenecer a una persona", por lo que tienen potencial. La industria debería aprovechar esta oportunidad con pruebas cuantitativas, en lugar de quedarse en la viabilidad.
Además, existen dos problemas de investigación por resolver.
Uno, la seguridad de la IA necesita defensas a nivel de sistema: los círculos de IA suelen abordar la seguridad a nivel del modelo, diseñando barreras alrededor de la semántica de entrada y salida. Pero a medida que los agentes ganan autonomía y pueden acceder directamente a la infraestructura subyacente, este enfoque será insuficiente. La ejecución verificable y los procesos de certificación de crypto pueden complementar las garantías a nivel de sistema que el nivel del modelo no puede ofrecer.
Dos, la combinación de crypto e IA dará lugar a nuevos actores de amenaza y vectores de ataque, como agentes autónomos que no se pueden apagar y contratos inteligentes descontrolados, que se discutirán más adelante.
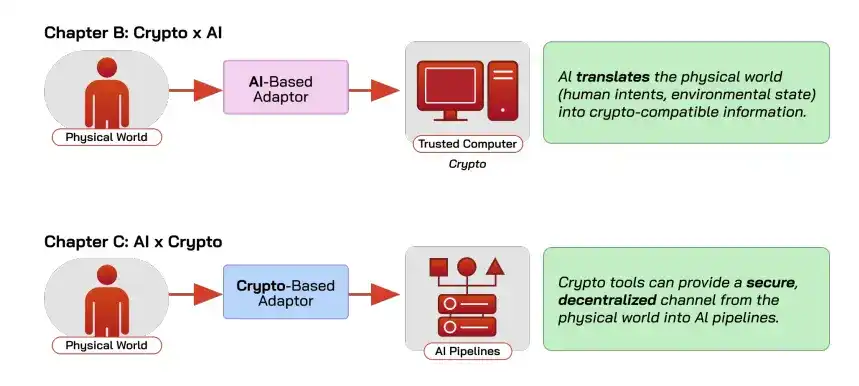
Un marco unificado: IA y Cripto como "middleware" mutuo
Un flujo de decisión automatizado se puede dividir en cuatro eslabones: la intención humana, la entrada, el programa y la salida, y cada eslabón de esta cadena puede no ser confiable. IA y Cripto gestionan diferentes segmentos en este marco.
La IA es el "middleware de traducción", que traduce las intenciones vagas humanas en programas ejecutables por máquinas, por ejemplo, transformar "quiero identificar señales de estacionamiento" en un modelo entrenado, reduciendo así la barrera de entrada para usar blockchain.
Cripto es el "middleware de confianza", garantizando a través de computación confiable que un cálculo se ejecute realmente según lo acordado y que los resultados no hayan sido alterados (integridad), y asegurando a través de la descentralización que el sistema esté siempre disponible y sea resistente a la censura (disponibilidad). Algunas soluciones también pueden garantizar que las entradas y salidas no se filtren (confidencialidad).
La computación confiable tiene tres enfoques técnicos.
Primero, Entornos de Ejecución Confiables (TEE), que dependen de hardware especializado para proporcionar aislamiento y atestación remota (el hardware presenta una prueba verificable de estado para que otra parte confirme que el chip es auténtico y no ha sido alterado). Con la computación confidencial de Nvidia, la sobrecarga adicional para la inferencia de un modelo de 8B de parámetros es inferior al 7%, y para modelos de 70B es casi insignificante. El costo es confiar en el fabricante del hardware y no protegerse contra ataques físicos.
Segundo, Pruebas de Conocimiento Cero (ZK), que dependen únicamente de problemas criptográficos difíciles, con las suposiciones de seguridad más limpias, pero con un costo computacional extremadamente alto. Generar una prueba para un modelo pequeño de unos 18 millones de parámetros ya requiere aproximadamente un minuto, estando muy lejos de los modelos grandes de vanguardia.
Tercero, Computación Multiparte (MPC), que permite a múltiples partes realizar cálculos conjuntos sin revelar datos originales, siendo más lenta. El marco de inferencia MPC Transformer más avanzado tarda aproximadamente cinco minutos en generar un solo token para LLaMA-7B.
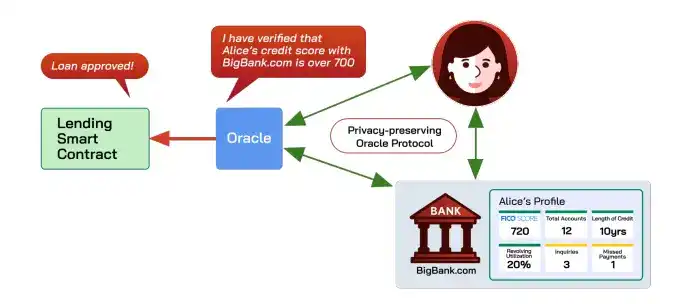
Los oráculos son responsables de llevar datos fuera de la cadena de manera confiable a la cadena. Los oráculos de privacidad (como Town Crier, DECO) van más allá, permitiendo probar propiedades de los datos sin revelar la privacidad, por ejemplo, probar que "el puntaje crediticio de alguien es superior a 700" sin exponer otra información.
La industria agrupa estas tecnologías bajo el nombre zkTLS, pero los esquemas basados en TEE no utilizan pruebas de conocimiento cero, lo cual es un uso incorrecto del término.
Crypto x AI: Usar IA para mejorar blockchain
La investigación sobre IA aplicada a crypto se puede dividir aproximadamente en tres generaciones según el tiempo.
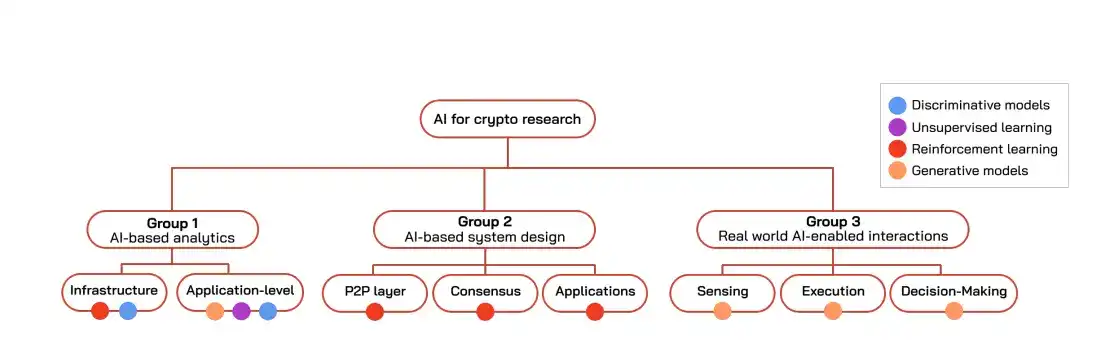
Primera generación: Análisis y detección
Desde hace más de una década, el aprendizaje automático se ha utilizado para analizar el estado en cadena: descubrir vulnerabilidades en protocolos de consenso (como la minería egoísta, donde los mineros ocultan bloques minados y los publican oportunamente para obtener más ganancias), detectar ataques de eclipse en redes P2P (rodear un nodo con muchos nodos maliciosos para cortar su conexión con la red honesta), predecir precios de criptomonedas, identificar transacciones fraudulentas y lavado de dinero.
La limitación es que este tipo de análisis a menudo depende de escenarios donde se puede obtener información global pública y está restringido por datos simulados y la falta de muestras de ataques reales.
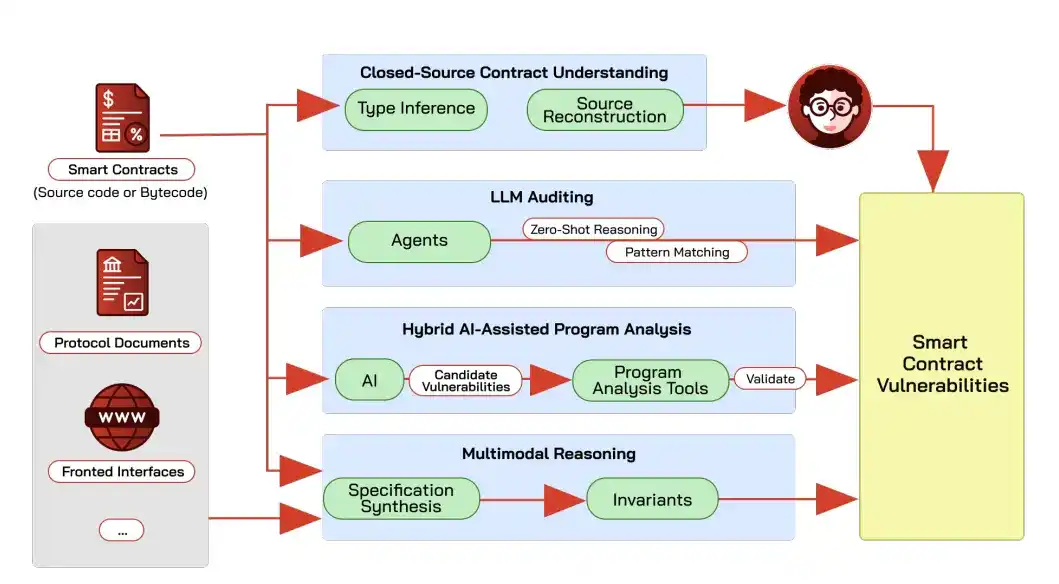
La detección de vulnerabilidades en contratos más avanzada actualmente no hace que la IA adivine conclusiones directamente desde el código, sino que primero la IA propone puntos sospechosos, que luego se verifican mediante análisis estático y ejecución simbólica (analizando la estructura del código para encontrar vulnerabilidades sin ejecutarlo realmente).
Dejar que un modelo grande actúe únicamente como auditor genera muchos falsos positivos debido a las alucinaciones; GPT-4 y Claude solo identificaron correctamente el tipo de vulnerabilidad en el 40% de 52 contratos DeFi que habían sido atacados.
Segunda generación: Diseño de algoritmos
En los últimos seis años, el aprendizaje por refuerzo se ha utilizado para diseñar algoritmos descentralizados, cubriendo topologías de redes P2P, selección de parámetros y roles en protocolos de consenso, fragmentación, tasas de préstamo y creación de mercados en DeFi, estrategias de licitación para MEV, etc.
Estos métodos son más efectivos en entornos que pueden modelarse claramente, y la mayoría permanecen en etapa de investigación, sin implementarse a gran escala en redes reales ni ser probados contra ataques.
Tercera generación: Interacción con el mundo real
Con la ayuda de oráculos impulsados por IA, los contratos inteligentes obtienen tres capacidades mejoradas: percepción (entender datos no estructurados y lenguaje natural), ejecución (llamar a modelos y herramientas de IA fuera de la cadena) y decisión (actuar como agente según una función objetivo).
El desempeño real de la IA como oráculo es desigual. Según experimentos de Chainlink Labs, GPT-4o tuvo una precisión general del 89.3% en 1660 preguntas de mercados de predicción, el Truth Bot de UMA tuvo un 75%, mientras que la precisión humana en el oráculo optimista de UMA (que asume inicialmente que la respuesta es verdadera, establece un período de disputa y se considera válida si nadie la impugna) fue del 98.2%.
La precisión depende en gran medida del tipo de pregunta: preguntas discretas con fuentes de datos oficiales, como resultados deportivos, pueden alcanzar el 99.7%, mientras que las preguntas que involucran secuencias temporales o requieren transcribir y contar en video muestran tasas de error significativamente más altas.
Hay tres formas de abordarlo: primero, diseñar para ser tolerante a fallos, usándolo solo en escenarios de bajo valor; segundo, introducir arbitraje humano, como una ventana de disputa de 48 horas, pero esto ralentiza las decisiones; tercero, hacer que el modelo se abstenga de responder cuando no está seguro, introduciendo humanos solo en ese momento.
Los "DAO de inversión" que entregan fondos a modelos de IA para operar colectivamente, el informe los llama CoinAlg, con proyectos representativos como ElizaOS, AI XBT, que alcanzaron valores de mercado máximos de 27 mil millones y 47 mil millones de dólares respectivamente. Este tipo de productos enfrenta un dilema de diseño irresoluble, denominado "callejón sin salida de CoinAlg".
Si la estrategia de trading es transparente, será copiada o su beneficio será absorbido por ataques sándwich (colocar órdenes justo antes y después de la transacción de la víctima para obtener ganancias por deslizamiento); si es confidencial, los insider con conocimiento de la estrategia pueden obtener ganancias anticipadas aprovechando la diferencia de información, equivalente a trading con información privilegiada. Ambas vías perjudican a los inversores comunes.
Un enfoque preliminar de mitigación es envolver la estrategia en TEE y aleatorizar las operaciones, aumentando la dificultad de predicción para los insider.
Nuevo riesgo: Contratos inteligentes maliciosos impulsados por IA
Los contratos inteligentes reemplazan la confianza interpersonal, lo que también significa que los actores criminales con las relaciones menos confiables pueden beneficiarse de ellos.
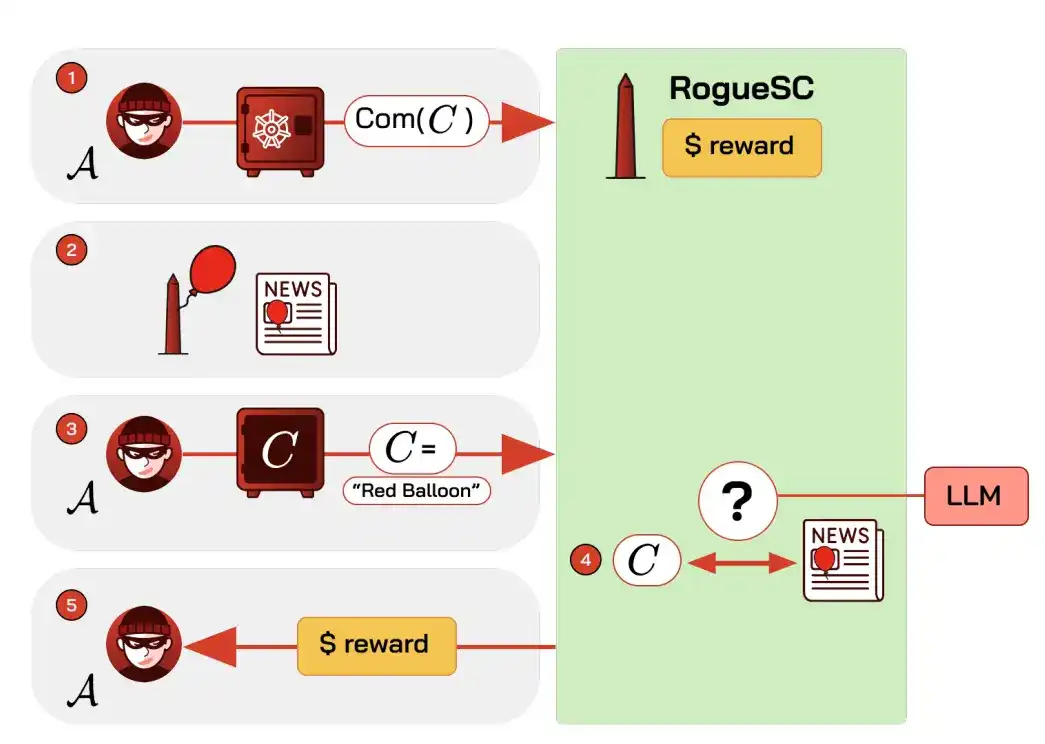
Un mecanismo es: un contrato ofrece una recompensa por un crimen, el perpetrador se compromete criptográficamente de antemano con una "marca secreta" y la revela después, un modelo de IA compara con reportes de noticias, confirma la finalización del crimen y paga automáticamente la recompensa. La IA asume aquí el rol de "árbitro", difícil de automatizar en el pasado, y puede usarse para acoso dirigido, robo de información organizacional, exposición de la identidad de denunciantes, etc.
Las contramedidas viables incluyen análisis en cadena para rastrear, listar fondos involucrados en listas negras, y hacer que los oráculos que alojan modelos de IA rechacen servicios en solicitudes de alto riesgo.
AI x Crypto: Usar Crypto para mejorar la IA
La contribución potencial de crypto a la IA se divide en dos categorías: primero, descentralizar las diversas etapas del ciclo de vida de la IA; segundo, proteger la seguridad de estas etapas.
Infraestructura descentralizada (DePIN)
Las Redes de Infraestructura Física Descentralizadas permiten que los nodos proporcionen recursos como potencia de cálculo mediante incentivos de tokens. Theta, Akash, etc., afirman ahorrar entre un 50% y un 85% en costos frente a AWS, siendo el principal cuello de botella el rendimiento y la latencia debidos a la comunicación entre nodos a través de internet público.
La adaptabilidad varía según el tipo de tarea. El entrenamiento no es sensible a la latencia (se realiza offline), pero la comunicación de sincronización entre regiones es un cuello de botella. Ya existen resultados de modelos con decenas de miles de millones de parámetros entrenados en hardware distribuido (700M y 7B en Bittensor, Intellect-1 de 10B de Prime Intellect, siendo el mayor un modelo de 40B en entrenamiento en la red Psyche).
La inferencia es más sensible a la latencia, pero los requisitos de rendimiento son menores que para el entrenamiento y no necesita propagación hacia atrás (el paso clave durante el entrenamiento que retropropaga el error a través de las capas para actualizar parámetros, solo necesario para el entrenamiento). La inferencia no sensible a la latencia (actas de reuniones, revisión de documentos) es especialmente adecuada para DePIN.
La brecha clave es que la mayoría de estos proyectos no reportan el costo total de extremo a extremo. Lo que promocionan es el precio por hora de una sola GPU, mientras que lo que realmente determina el costo de una tarea de ML es la eficiencia del entrenamiento (iteraciones por unidad de costo) y la eficiencia de la inferencia (tokens por unidad de costo).
Mercados descentralizados de datos y modelos
Los datos de IA tienen varias características distintivas de las mercancías ordinarias. Son bienes digitales, cuya creación inicial es costosa pero la copia es casi gratuita; a menudo son no rivales (un conjunto de datos puede ser utilizado simultáneamente por múltiples partes sin desgaste); la calidad es difícil de juzgar de antemano, el problema del "mercado de los limones" (el comprador no puede juzgar la calidad de antemano, lo que lleva a que los productos de calidad sean expulsados por los de baja calidad); el vendedor necesita proporcionar muestras, pero las muestras mismas tienen valor; y pueden revenderse, además de que es difícil determinar si dos conjuntos de datos son sustancialmente iguales.
La controversia con los mercados centralizados radica en la opacidad de precios y la limitación de opciones para los usuarios, pero a veces la fijación de precios centralizada es más eficiente al tener más información.
Los mercados de datos aún no tienen un monopolio dominante, existe una ventana de oportunidad para reconstruirlos de manera descentralizada, utilizando herramientas crypto como micropagos, TEE (limitando el uso de datos a tareas específicas), pruebas de conocimiento cero (revelando propiedades de los datos al comprador sin filtrar los datos mismos).
La realidad actual es que la mayoría de las plataformas solo usan criptomonedas para completar el pago, y los mecanismos de fijación de precios los decide el protocolo o se dejan completamente al vendedor, ambos ya existentes en mercados centralizados. Aún se investiga poco sobre qué mejora realmente la descentralización.
Canal de pagos para agentes y x402
El ecosistema de agentes en sí mismo ya es descentralizado: diferentes partes desarrollan, optimizan y tienen diferentes objetivos usando diferentes modelos, sin un punto de control central natural. El enfoque de criptoeconomía de crypto (usar medios criptográficos combinados con incentivos económicos para restringir el comportamiento de los participantes) puede migrarse a la gobernanza de agentes.
Los micropagos son clave para la economía de agentes. En la historia de internet, los micropagos han fracasado repetidamente, el obstáculo ha sido el costo de decisión humana para evaluar cada pago pequeño, no la infraestructura de pago en sí. Los agentes evalúan micropagos mucho más rápido que los humanos, los usuarios solo necesitan establecer estrategias, lo que podría hacer que los micropagos funcionen por primera vez.
Cloudflare ya ha lanzado "pago por rastreo", y protocolos como x402 (un protocolo abierto que permite a los programas realizar pagos pequeños en cadena directamente a través de HTTP) están en desarrollo.
El activo subyacente de este sistema son principalmente stablecoins (USDC, USDT, DAI), porque proporcionan una unidad de cuenta estable para los agentes (una medida para etiquetar uniformemente todos los bienes), mientras que tokens nativos como ETH, SOL tienen demasiada volatilidad.
La confianza entre agentes se basa en registros en cadena (como la propuesta de estándar ERC-8004 en Ethereum para establecer identidad y reputación en cadena para agentes) que registran identidad y reputación, pero estos son esencialmente autodeclaraciones, y la reputación va con retraso, beneficiando a los actores establecidos.
Un esquema más avanzado es la auditoría verificable de agentes: un LLM ejecutado dentro de un TEE revisa el código privado del agente, produce una puntuación de reputación, y el resultado de la auditoría se vincula al hash del código, permitiendo que el código permanezca privado mientras los verificadores obtienen garantías confiables.
Los agentes autónomos inapagables (UAA) son otro riesgo. La duración de las tareas que los agentes de vanguardia pueden completar de manera autónoma se ha duplicado aproximadamente cada siete meses desde 2019. Investigaciones ya muestran que los modelos pueden, localmente, cruzar la línea roja de autorreplicación y crear copias independientes, pero la replicación a infraestructura externa aún se ve obstaculizada por la autenticación de identidad.
El modelo Mythos de Anthropic ya ha demostrado la capacidad de descubrir y explotar de manera autónoma vulnerabilidades de día cero (vulnerabilidades desconocidas para el fabricante y sin parches disponibles). Un agente que tenga una billetera y no se pueda apagar caería en un punto ciego del marco regulatorio existente centrado en el "operador".
Gobernanza descentralizada
Las comunidades blockchain tienen una historia más larga de prácticas en la asignación del control del sistema, utilizando métodos naturalmente descentralizados que buscan incluir a una amplia gama de partes interesadas, pero también tienen deficiencias reconocidas: vulnerabilidades de seguridad, apatía en la votación, compra de votos.
La gobernanza comunitaria tiene diferente adaptabilidad en las diversas etapas del desarrollo de IA: el volumen de datos de preentrenamiento es demasiado grande para recopilar opiniones efectivas, su valor se manifiesta más en la etapa de ajuste fino; la selección de la arquitectura subyacente es una decisión técnica, no apta para gobernanza comunitaria; las etapas de evaluación y alineación mezclan juicios técnicos y normativos, donde la entrada comunitaria tiene valor.
Constitutional AI utiliza una "constitución" escrita por humanos para establecer los principios que el modelo debe seguir. Collective Constitutional AI, en el que participa Anthropic, introduce votación pública para generar principios, y los modelos entrenados con principios de fuentes públicas muestran menos sesgos sociales. Pero estos experimentos de gobernanza democratizadora básicamente no se han adoptado realmente, y las empresas de IA carecen de motivación para ceder el control de sus modelos.
La votación ponderada por tokens en los DAO es ampliamente considerada "plutocracia", lo que ha derivado en mecanismos como votación cuadrática (el costo de votos adicionales aumenta para disuadir a las ballenas), votación por convicción (acumulación de peso según el tiempo de posesión del voto de apoyo), votación delegada, etc., pero su efectividad aún no está clara.
Protección de la integridad de ejecución de los sistemas de IA
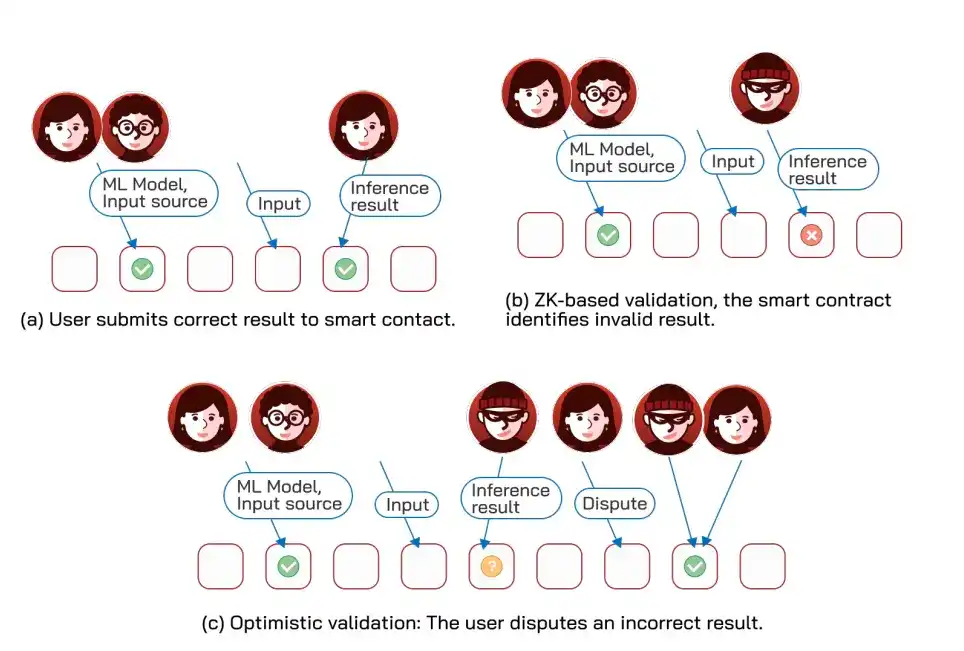
Cuando un contrato inteligente necesita utilizar cálculos de ML que están más allá de sus capacidades, puede actuar como "árbitro": las partes primero se comprometen con el modelo y los datos utilizados y depositan garantías, después de completar el cálculo fuera de la cadena, presentan los resultados al contrato para verificación, y la parte incorrecta es penalizada. Hay cuatro enfoques para la verificación, cada uno con compensaciones.
Primero, TEE, el más eficiente, utiliza hardware confiable para firmar y probar la integridad del cálculo, pero requiere confiar en el operador.
Segundo, ejecución optimista, los resultados se consideran inicialmente no finales, con una ventana de disputa; en caso de disputa, se utiliza búsqueda binaria (dividir repetidamente el rango de error a la mitad para localizar rápidamente el paso incorrecto) para localizar una sola instrucción errónea y luego penalizar.
La dificultad radica en la no determinística de las operaciones de punto flotante en ML, que requieren un orden de operaciones controlado o semántica de tolerancia (no exigir que dos cálculos sean idénticos, permitiendo que se consideren consistentes dentro de un margen de error). Representan este enfoque Verde, TAO, Arbigraph, OPML, entre otros.
Tercero, pruebas de conocimiento cero (zkML, usar pruebas de conocimiento cero para probar que el proceso de inferencia de IA es correcto), pueden probar que la inferencia es correcta ocultando los parámetros del modelo, e incluso las entradas y salidas, ya existen esquemas especializados para CNN, Transformer y compiladores generales (como EZKL, ZKML, DeepProve).
Su objetivo de privacidad tiene de hecho tres niveles: ocultar la entrada, ocultar los pesos, ocultar la estructura del modelo, pero cuanto mayor es la privacidad, más complejas son las restricciones del circuito y menor es el espacio de optimización, existiendo una tensión fundamental entre privacidad y eficiencia. Los costos principales provienen de las capas no lineales y la representación numérica, y aún es difícil soportar contextos largos, modelos grandes y servicios de alto rendimiento.
Cuarto, pruebas de inferencia estadística, cuyo principio es que dos modelos con funciones diferentes, sus características internas calculadas también serán necesariamente diferentes, por lo que basta con muestrear y comparar estas características para juzgar probabilísticamente si la inferencia fue realmente ejecutada por el modelo especificado.
Su costo de generación de prueba es del orden de milisegundos y es final instantáneo, adecuado para escenarios de alta frecuencia y baja latencia. Puede prevenir malas acciones realistas como que el proveedor de servicios reemplace el modelo (por ejemplo, con una versión destilada más barata o reemplazando una versión alineada), pero no puede detener a un atacante completamente malicioso que falsifique por completo el registro de cálculo, lo cual sigue siendo un problema sin resolver.
Probar el entrenamiento del modelo (zkPoT, usar pruebas de conocimiento cero para probar que el proceso de entrenamiento es correcto) es mucho más difícil que probar la inferencia: el proceso de entrenamiento es de larga duración, los estados intermedios se acumulan continuamente, es altamente estocástico, y su complejidad es varios órdenes de magnitud mayor que la inferencia. Trabajos relacionados (Garg et al., Kaizen) están en curso, extendiéndose a pruebas auditables sobre el origen de los datos de entrenamiento y restricciones de equidad (ZkAudit, Confidential-PROFITT).
Protección de la canalización de entrenamiento
Cuando una sola organización entrena un modelo con sus propios datos confiables, generalmente no tiene preocupaciones inmediatas de privacidad o integridad. Los desafíos de seguridad complejos surgen en el entrenamiento federado entre múltiples partes y cuando las fuentes de datos son diversas.
Un escenario típico es el entrenamiento federado de un modelo de diagnóstico entre varios hospitales: combinar los registros médicos electrónicos (EHR) de cada parte cubre un espectro más amplio de pacientes y mejora la precisión del diagnóstico, pero está sujeto a regulaciones como HIPAA, y las partes no están dispuestas, ni pueden, simplemente entregar datos brutos entre sí o a un tercero.
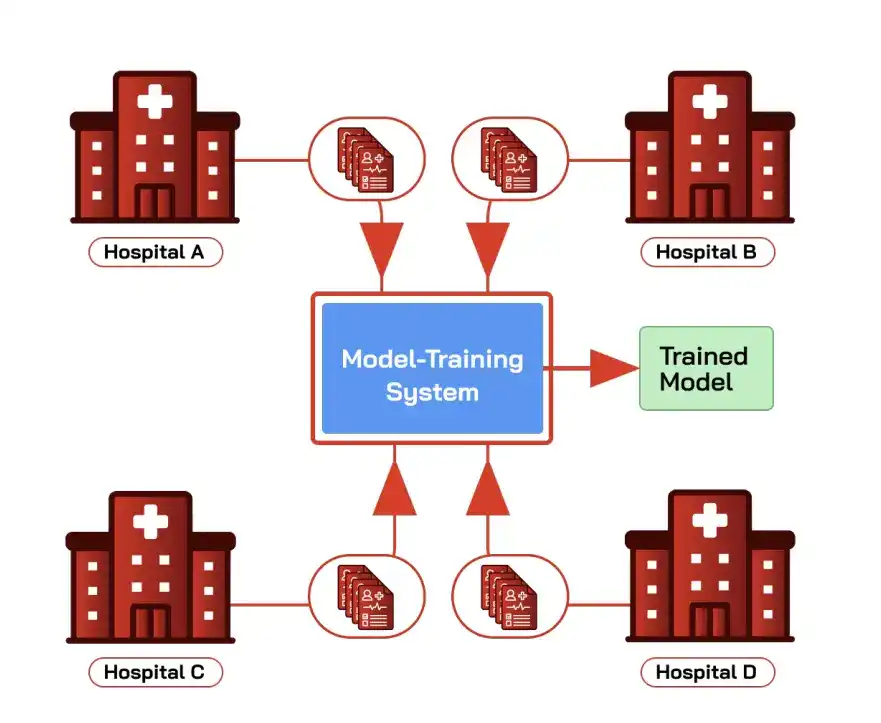
Las instituciones financieras que entrenan federadamente modelos de detección de fraude, o empresas que entrenan federadamente modelos de detección de intrusiones, también son casos similares.
El aprendizaje federado está diseñado para esto: el entorno de entrenamiento inicializa un modelo global y lo distribuye a las partes, cada parte entrena localmente con sus datos privados, solo envía actualizaciones del modelo, el entorno de entrenamiento las agrega en un nuevo modelo global, los datos nunca salen localmente.
Pero el aprendizaje federado tiene una adopción limitada (la aplicación más conocida es la predicción del teclado de teléfonos). No garantiza la integridad de los datos y el cálculo, incluso si las partes son honestas, la sobrecarga de comunicación es grande, la latencia de red y coordinación ralentiza la velocidad general, la precisión del modelo es inferior al entrenamiento centralizado, y las partes maliciosas pueden envenenar el modelo o implantar puertas traseras.
Una alternativa más simple es usar TEE para el entrenamiento centralizado: el entorno de entrenamiento se ejecuta en un entorno de computación confidencial confiable, recibe datos brutos de las partes a través de canales cifrados, entrena de manera centralizada y solo produce el modelo entrenado, los datos no son visibles entre sí, y puede incluir una prueba de trazabilidad del modelo (quién proporcionó los datos, cómo se entrenó el modelo).
El costo son los riesgos inherentes de canales laterales en TEE y la alta sobrecarga de E/S. En la realidad, las instituciones actualmente suelen consolidar datos en nubes conformes, confiando en el aislamiento, control de acceso, cifrado y acuerdos de uso de datos para cumplir, pero esto requiere confiar en el proveedor de la nube.
Los datos de redes privadas son otra vía. Los datos de texto de la red pública están alcanzando su límite (se predice que se agotarán entre 2025 y 2030), los datos sintéticos tienen el riesgo de "colapso del modelo" y no pueden ampliar la cobertura de datos más allá de los dominios existentes.
Se estima que las "redes privadas" (datos no accesibles a rastreadores como correos electrónicos, salud, finanzas) son dos órdenes de magnitud más grandes que la red pública, una mina rica aún sin explotar, pero actualmente altamente aisladas.
Los oráculos pueden abrir esta puerta. Tomando el ejemplo de un paciente que sube su historial médico para entrenar un modelo médico, el usuario puede usar un oráculo para transferir su historial desde el portal del hospital al entrenador, y probar que los datos realmente provienen de ese portal, todo sin que el hospital modifique su infraestructura, porque la conexión la inicia el usuario.
Para proteger simultáneamente la privacidad, es necesario combinar oráculos de privacidad (los datos van por canales cifrados) y TEE. El TEE también puede mostrar al usuario una prueba de que está ejecutando exactamente ese software de entrenamiento privado que "solo produce el modelo", permitiendo al usuario verificar antes de enviar los datos.
Sobre esta base, se pueden añadir compromisos más detallados como privacidad diferencial (la salida del modelo depende mínimamente de cualquier dato de entrenamiento individual), eliminación de datos después del uso, restricción del uso del modelo final a hospitales de una lista blanca, etc.
Canalización de inferencia segura y canal protegido (Props)
La misma combinación de oráculos y computación confiable también se puede usar para realizar inferencia segura sobre datos de redes privadas.
Tomando la aprobación de préstamos bancarios como ejemplo: el modelo lee los documentos financieros del solicitante y produce una decisión de aprobar o rechazar. El proceso actual es que el prestatario descarga o fotografía y sube los materiales, lo que plantea dos problemas: primero, el prestamista no puede confirmar si los materiales son auténticos y no han sido alterados; segundo, los materiales del prestatario podrían filtrarse desde el sistema del modelo del prestamista, un riesgo para ambas partes.
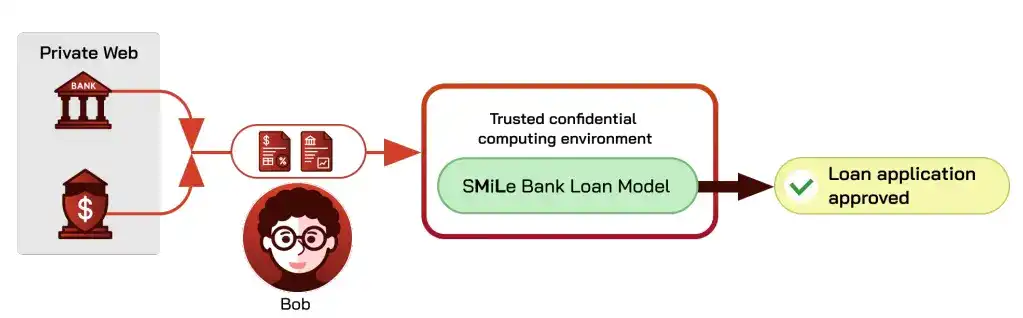
Usando un oráculo de privacidad para resolver la autenticidad del origen y computación confidencial para resolver la privacidad, se obtiene una canalización de inferencia segura: el prestamista solo ve la conclusión del modelo, mientras está seguro de que la entrada es confiable.
Las fuentes de redes privadas también pueden servir temporalmente como sistemas de identidad y credenciales.
El prestatario puede transferir extractos bancarios o formularios W-2 con su identidad, lo que en sí mismo es una prueba sólida de identidad, convirtiendo los servicios web existentes en sistemas de identidad temporales contra el robo de identidad y el fraude de beneficios; el modelo también puede emitir credenciales basadas en esto, por ejemplo, después de verificar los materiales fiscales y comerciales de una pequeña empresa, emitir una prueba de "cumplimiento de cierta calificación" adjuntando la prueba de la canalización de inferencia.
Todo el proceso puede realizarse de manera descentralizada, en teoría, cualquiera puede configurar una canalización de inferencia confiable, sin necesidad de cooperación de la fuente de datos o de autoridades existentes.
La entrada adversaria es un problema persistente. Un atacante puede enviar un extracto bancario que parece normal a simple vista pero ha sido cuidadosamente alterado, engañando al modelo para que lea un saldo artificialmente alto y apruebe erróneamente el préstamo. La investigación académica sobre ejemplos adversarios ha sido un ciclo de "explotar-parchear", sin solución general hasta ahora.
Las canalizaciones de inferencia segura ofrecen un nuevo enfoque: limitar las entradas a fuentes de red certificadas, reduciendo así el espacio para que los atacantes construyan entradas adversarias, complementando las defensas a nivel de modelo.
La privacidad del modelo en sí también necesita protección. Los atacantes pueden realizar extracción del modelo (extraer características o incluso el modelo completo), inferencia de membresía (determinar si los datos de alguien están en el conjunto de entrenamiento) e incluso reconstruir datos de entrenamiento originales mediante consultas cuidadosamente construidas, también pueden usar esto para espiar la configuración del sistema y las opciones de preprocesamiento.
Investigadores estimaron que costaría unos $8000 robar los pesos de una capa de un modelo grande. La limitación de tasa comúnmente usada en sistemas abiertos es frágil, porque un solo usuario anónimo puede hacerse pasar por muchos usuarios en un ataque Sybil.
Las canalizaciones de inferencia segura pueden mitigar desde ambos extremos: usar oráculos para limitar los tipos de entrada, frenando los ataques de extracción que requieren muchas consultas diversas; y usar identidades fuertes generadas dentro de la canalización para imponer límites de consultas por usuario, ejecutable sin exponer la identidad del usuario a la plataforma, suprimiendo así los ataques Sybil.
La memoria del agente es una nueva superficie de ataque. Los atacantes pueden contaminar el contexto (memoria inyectada) proporcionado al agente a través de llamadas a herramientas o materiales externos, induciendo un comportamiento anómalo, por ejemplo, en el framework ElizaOS que gestiona grandes cantidades de activos criptográficos, el contexto contaminado puede inducir al agente a iniciar transacciones no autorizadas.
El TEE puede mitigar parcialmente: ejecutando el agente dentro de un TEE, o extrayendo solo contextos certificados.
Pero incluso con TEE, hay dos dificultades.
Primero, las fuentes confiables también pueden tener contenido contaminado, por ejemplo, el contenido de plataformas sociales es generado por los usuarios, y un publicador puede fácilmente envenenar su propia publicación.
Segundo, el operador del TEE puede lanzar un ataque de reversión o bifurcación, retrocediendo el estado del TEE a un punto de control anterior, borrando las actualizaciones de memoria posteriores.
El primero es un problema de detección de contenido, la criptografía no puede resolverlo; el segundo ya puede abordarse con ideas de consenso, sistemas como ROTE, Narrator utilizan protocolos distribuidos, e incluso blockchain pública, para garantizar la consistencia y frescura del estado del TEE.
Resumiendo la arquitectura de esta sección, obtenemos el marco general "Canal Protegido" (Props), cuyo objetivo es utilizar datos de redes privadas de manera segura sin modificar la infraestructura existente.
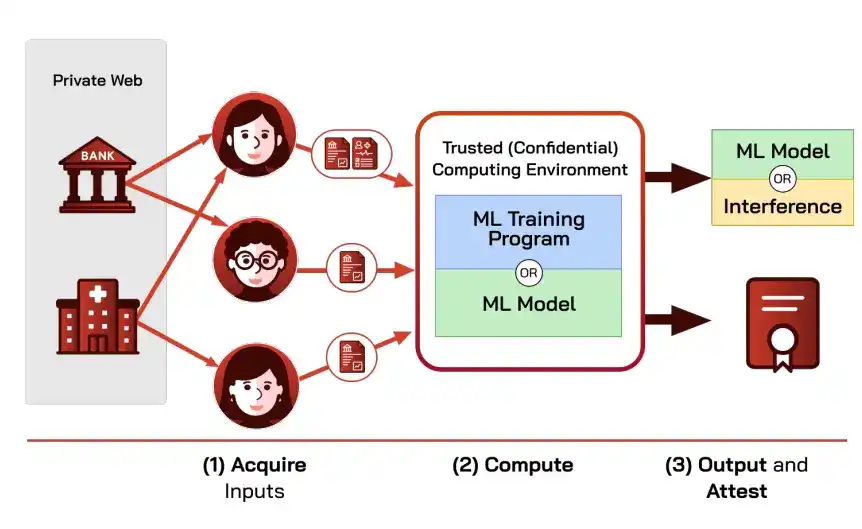
Combina oráculos y computación confiable en tres segmentos: el oráculo obtiene datos de fuentes privadas certificadas y prueba su origen; el TEE completa el entrenamiento o inferencia dentro del límite cifrado; el TEE produce el modelo o conclusión adjuntando una prueba que describe las propiedades de la canalización (fuentes de datos, hash del código del software/modelo, etc.).
Props garantiza tres propiedades: integridad de entrada de extremo a extremo (la salida depende solo de datos certificados de fuentes privadas confiables), confidencialidad por defecto (las entradas y estados intermedios no salen del límite protegido, solo se revela la salida), y capacidad de prueba sin revelación (la prueba convence tanto al proveedor de datos como al usuario del resultado de que se cumplen la integridad y confidencialidad).
También tiene una "versión transparente", donde los datos y el cálculo no necesitan ser confidenciales, solo certificados, y las fuentes pueden ser públicas o privadas.
Cinco conceptos erróneos sobre Crypto x AI
Alrededor de las plataformas y aplicaciones de Crypto x AI, han surgido varios conceptos erróneos o declaraciones engañosas comunes. Las siguientes cinco no son completamente falsas, la clave está en aclarar qué partes son válidas actualmente y cuáles aún requieren más evidencia.
Error 1: Blockchain puede distinguir entre contenido generado por IA y contenido generado por humanos
Registrar contenido en la cadena para luego poder determinar si fue creado por IA o humanos es una afirmación comúnmente citada, y ya hay proyectos (como Everlyn AI) que suben contenido generado por IA a la cadena. Pero blockchain no puede hacer esto en un sentido general; es necesario separar dos problemas: "detección de contenido" y "trazabilidad de contenido".
La detección de contenido es juzgar si un contenido fue generado por humanos o IA. El enfoque principal actual es la detección a posteriori, que no depende de metadatos o señales previamente incrustadas, y se divide en dos tipos: uno, clasificadores de IA, que utilizan aprendizaje profundo para identificar características estadísticas específicas de los modelos generativos; dos, análisis forense estadístico, que analiza distribuciones de ruido a nivel de píxel, anomalías estructurales (como inconsistencias fisiológicas en rostros generados por IA).
El problema es que blockchain en sí misma no puede percibir esta información fuera de la cadena; el resultado de la clasificación debe ser proporcionado por un clasificador externo. Subirlo a la cadena solo puede anclar ese resultado, garantizando que el registro no sea alterado después de enviarlo, pero no puede garantizar que el registro sea verdadero en el momento de la escritura. Si el detector externo se equivoca, blockchain preservará el error permanentemente. Es decir, blockchain proporciona "integridad de la declaración", no "verificación de que la declaración es verdadera".
La trazabilidad de contenido es registrar el historial de un activo digital desde su creación. Estándares de la industria como C2PA permiten a los creadores o dispositivos adjuntar metadatos firmados criptográficamente (credenciales de contenido) que registran el origen, autor y ediciones posteriores. Numbers Protocol, Starling Lab, entre otros, utilizan blockchain como un registro público e inmutable de estas credenciales.
Pero incluso con un sistema de trazabilidad sólido anclado a la cadena, no puede garantizar si el contenido fue originalmente generado por humanos o IA.
Un usuario podría perfectamente mostrar una imagen generada por IA en una pantalla HD y luego fotografiarla con una cámara compatible con C2PA, obteniendo un archivo con firma válida etiquetado como "fotografía real"; con texto sucede lo mismo, después de la generación por IA, se puede volver a escribir manualmente en un editor compatible, obteniendo información de trazabilidad legítima etiquetada como "creación humana".
Además, una vez que el contenido se modifica hasta el punto de no coincidir con el registro en cadena, se rompe la trazabilidad, y un registro universal que cubra todo el contenido es casi imposible en un futuro visible, por lo que los sistemas de trazabilidad inevitablemente tendrán muchas lagunas.
Punto clave: En un sentido estricto, blockchain puede proporcionar garantías sólidas de integridad para los metadatos de trazabilidad, pero está lejos de ser una solución completa al problema de detección de contenido generado por IA.
Una solución realmente efectiva requeriría un ecosistema universal donde cada pieza de contenido sea capturada por dispositivos confiables y anclada instantáneamente a la cadena, pero en la realidad, la gran mayoría del contenido es creado y compartido por herramientas que no soportan anclaje criptográfico, y el contenido no etiquetado permanece en una zona gris.
Error 2: Blockchain o la descentralización pueden resolver los problemas de sesgo y equidad de la IA
"Poner la inferencia y el entrenamiento del modelo en la cadena resolverá la inequidad y el sesgo de la IA". Para evaluar esta afirmación amplia, primero es necesario distinguir entre diferentes tipos de sesgo.
El sesgo algorítmico es el concepto de equidad más común en los círculos de IA. Los modelos aprenden e incluso amplifican los desequilibrios en el conjunto de datos, lo que lleva a que los modelos de discriminación tengan un rendimiento inferior en grupos desfavorecidos, y los modelos generativos perpetúan tendencias indeseables de los datos de entrenamiento (como lenguaje dañino, estereotipos fijos).
La academia ha propuesto numerosas soluciones técnicas en tiempo de entrenamiento y de inferencia (barreras), pero estas protecciones están lejos de ser perfectas; la equidad aún no es un problema resuelto, e incluso puede que nunca se resuelva por completo, ya que incluso "cómo definir la equidad" requiere muchas compensaciones.
La descentralización no puede resolver el sesgo algorítmico porque se origina en el proceso de entrenamiento mismo, generalmente se mitiga mejorando las técnicas de entrenamiento o inferencia, la descentralización no toca la raíz.
Pero el sesgo tiene una segunda fuente: las decisiones de alto nivel que afectan el rendimiento del modelo: qué datos usar, qué arquitectura, cómo compensar a los contribuyentes. Este nivel es ortogonal a la equidad comúnmente entendida en IA, pero puede afectar el sesgo algorítmico, y parte de ello puede mejorarse con dos características de la descentralización.
La primera característica es la transparencia. Los desarrolladores pueden usar blockchain para comprometerse públicamente con los datos de entrenamiento, algoritmos de entrenamiento, puntos de control del modelo y barreras de inferencia, permitiendo a los operadores rastrear de manera verificable la salida de un entrenamiento o inferencia específico.
Pero esto es difícil de escalar para productos del entrenamiento como modelos grandes y puntos de control (los costos de almacenamiento y computación son demasiado altos); en los sistemas existentes, estos datos en su mayoría ya están fuera de la cadena y los usuarios tampoco pueden acceder directamente, por lo que, a corto plazo, el beneficio de la transparencia puede limitarse al proceso de inferencia.
Lo más crucial es que, a menos que la industria aclare para qué casos de uso debe servir esta transparencia y qué interfaz debe tener (por ejemplo, permitir a los usuarios reportar el uso indebido de datos, lo que a su vez requiere establecer una verdadera propiedad de datos y tecnologías complementarias como el olvido de máquina), la transparencia por sí sola puede no cambiar la forma en que las personas desarrollan y usan la IA.
La segunda característica es la gobernanza descentralizada, es necesario distinguir dos tipos. El primero son los mecanismos de gobernanza comunitaria explorados y adoptados en blockchain (votación ponderada por tokens, democracia líquida); el segundo es la gobernanza autónoma descentralizada representada por los DAO, donde las decisiones de gobernanza son aplicadas por contratos inteligentes.
El punto crucial común es que mecanismos como la gobernanza comunitaria en sí mismos no necesitan blockchain para implementarse, por lo que presentarlos como "problemas de IA resueltos por blockchain" no es exacto. Las decisiones de IA técnicas y sensibles al rendimiento no son adecuadas para votaciones amplias, pero las decisiones orientadas a valores (como la alineación del modelo) son más adecuadas; los principales desarrolladores de IA los han explorado, simplemente aún no se han implementado realmente.
La gobernanza en cadena realmente aplicada por contratos inteligentes (ejecución directa o penalización de garantías) puede mejorar la robustez, pero enfrenta las mismas barreras técnicas que la transparencia en cadena; la infraestructura actual no puede soportar los requisitos de almacenamiento y computación de la IA, y su implementación aún requiere avances significativos en el entrenamiento verificable, siendo una visión a largo plazo coherente pero prematura.
Punto clave: Blockchain en sí misma no puede reducir el sesgo algorítmico, pero puede promover la transparencia en las diversas etapas del ciclo de vida de la IA y ampliar la participación en la gobernanza de la IA.
Error 3: Darle una billetera a un agente de IA lo hace "autónomo"
Los proyectos que desarrollan "billeteras para agentes" y protocolos de pago a menudo afirman que darle una billetera a un agente de IA, permitiéndole ganar, gastar y "sobrevivir" por sí mismo, lo hace autónomo. Esta afirmación confunde varios conceptos diferentes.
La ambigüedad surge primero porque "autonomía" tiene significados diferentes en dos campos. En el contexto de IA, un agente autónomo es aquel que puede actuar basándose en su propia percepción, aprendizaje y experiencia, en lugar de seguir reglas preestablecidas rígidamente; los contratos inteligentes también se denominan a menudo autónomos, pero enfatizan la resiliencia contra la manipulación, la censura y el cierre.
El primero se denomina "autonomía inteligente", el segundo "autonomía de ejecución". Los agentes de IA modernos ya poseen una autonomía inteligente considerable, pero pueden no tener autonomía de ejecución; un administrador aún puede apagar el servidor donde se ejecutan.
Lo que aporta una billetera para agentes no es ninguno de estos dos tipos de autonomía. Tener una billetera no hace que la IA sea más inteligente, ni le permite resistir mejor la manipulación humana o el cierre; lo que realmente aporta es automatización: el agente puede operar, transferir fondos, llamar a instalaciones en cadena de manera programática, sin necesidad de pasar por aprobación humana.
Esta automatización tampoco es exclusiva de blockchain; la infraestructura financiera centralizada también puede ser llamada de manera programática por agentes. Una interpretación más sólida es: los sistemas de pago blockchain en sí mismos ofrecen una mayor autonomía (aunque no específicamente para agentes) en comparación con las soluciones centralizadas, por ejemplo, pueden garantizar que las transacciones del agente no sean tratadas de manera diferente, es decir, neutralidad y resistencia a la censura.
Punto clave: Las billeteras para agentes permiten a los agentes de IA invocar convenientemente interfaces financieras, automatizar interacciones económicas y eliminar la aprobación humana, pero la automatización no equivale a autonomía. Solo tener una billetera no permite que un agente escape del control humano (el operador aún puede apagar el modelo o las instalaciones de las que depende), y los pagos automatizados tampoco requieren blockchain; los sistemas centralizados también pueden lograrlo.
El verdadero valor de los pagos blockchain radica en la neutralidad y resistencia a la censura, adecuados para escenarios donde preocupa que los pagos sean suprimidos o intervenidos.
Error 4: IA transparente equivale a IA confiable
Subir a la cadena el origen de los datos del modelo y el registro de inferencia parece una herramienta ideal para garantizar la confiabilidad de la IA, argumento que proviene de un blog de IBM ampliamente citado y se ha extendido a los agentes de IA. Pero es necesario desglosarlo en dos niveles.
En cuanto a la transparencia a nivel de modelo, registrar el origen de los datos de entrenamiento parece aportar transparencia sobre la creación del modelo, pero hay una gran brecha entre "registro del origen de datos" y "garantía del comportamiento del modelo".
Primero, el registro en cadena es solo un registro, no equivale a una prueba del origen (para probar la composición del conjunto de entrenamiento se necesitan técnicas específicas).
Segundo, incluso con pleno conocimiento de los datos de entrenamiento, no es suficiente para determinar cómo se comportará el modelo, porque el flujo de entrenamiento y el entorno de cálculo también determinan el comportamiento del modelo.
Tercero, incluso conociendo el flujo completo desde los datos hasta el modelo, suficiente para replicar el modelo, la no determinística inherente al entrenamiento estocástico hace que "usar el flujo de entrenamiento para verificar los pesos del modelo" sea inviable en principio.
Además, incluso obteniendo los pesos, no hay un método universalmente efectivo para detectar puertas traseras o manipulaciones adversarias implantadas durante el entrenamiento, y registrar en cadena los datos del modelo y la información de entrenamiento no garantiza directamente sus características de comportamiento o la ausencia de manipulaciones adversarias.
En cuanto a la transparencia a nivel de inferencia, registrar en cadena las entradas del modelo y las inferencias correspondientes parece aportar transparencia sobre el uso del modelo, pero blockchain hace transparentes las transacciones, no la inferencia. Un registro en cadena que diga "el modelo X produjo la inferencia Z con la entrada Y" casi no puede probar que Z sea confiable.
Porque no puede probar ni la "ejecución correcta" (para probar que esta tripleta fue realmente producida por el modelo X según las especificaciones, se requieren TEE o costosos medios criptográficos), ni la "confiabilidad del modelo".
Incluso probando la ejecución correcta, el problema más fundamental es: el registro completo del origen del modelo X no puede probar a nivel semántico que cumple con las expectativas del usuario o las normas de la industria; usar el hash de los pesos para especificar el modelo ofrece garantías aún más débiles, porque la identidad del modelo no equivale a la confiabilidad del modelo.
Blockchain es ciertamente útil para ciertos objetivos de confiabilidad, como cuando una institución publica el hash de un modelo de pesos de código abierto en la cadena como referencia inmutable, permitiendo a los usuarios confirmar que están usando el modelo real sin modificaciones; un enfoque similar de registro a prueba de alteraciones también se usa en registros de actualizaciones de firmware y en transparencia de certificados (usando registros de solo adición similares a blockchain para mantener registros de emisión de certificados públicamente auditables).
Punto clave: Aún existe una brecha considerable entre subir a la cadena el origen de los datos del modelo y los registros de inferencia, y "garantías significativas de confiabilidad del modelo y sus inferencias".
Error 5: La descentralización hace naturalmente que las tareas de IA sean más baratas
Algunos proyectos presentan las redes descentralizadas como una solución de IA más eficiente y económica, típicamente las Redes de Infraestructura Física Descentralizadas (DePIN), donde los usuarios alquilan su hardware (como GPU), siendo el principal punto de venta el menor costo; alquilar una GPU en DePIN puede ser mucho más barato que alquilar una de nivel similar en un proveedor de nube.
Pero máquinas más baratas no necesariamente conducen a un costo total menor de la tarea. Los nodos descentralizados se comunican a través de internet público, y los requisitos de rendimiento y latencia de las tareas de IA afectan significativamente el costo total, y las tareas muy grandes (como entrenar modelos de vanguardia) suelen verse limitadas por cuellos de botella de rendimiento.
Actualmente es difícil hacer comparaciones directas de costos porque la industria aún carece de pruebas de referencia sistemáticas que comparen el rendimiento y costo de tareas de IA en DePIN con la nube tradicional bajo los mismos criterios.
Punto clave: Las redes descentralizadas son una alternativa atractiva a la nube centralizada de alto costo, pero los datos existentes aún no son suficientes para predecir cuándo una tarea será más barata en DePIN o en una plataforma de IA descentralizada en comparación con la nube centralizada.
Las tareas pequeñas (inferencia, entrenamiento a pequeña escala) probablemente sean más económicas, mientras que las tareas muy grandes (entrenamiento de modelos base) pueden verse obstaculizadas por la comunicación inestable y de bajo ancho de banda entre nodos. Para aclarar estas compensaciones, aún se necesita más investigación.
El punto en común de estos cinco errores es que blockchain puede proporcionar más "integridad" y "verificabilidad", no la "veracidad" o "confiabilidad" en sí mismas. Crypto x IA aún se encuentra en una etapa temprana donde es necesario hablar con evidencia, no avanzar solo con narrativas.