La investigación técnica es una tarea llena de trampas (tanto para humanos como para IA), ya que desde el inicio se recibe una gran cantidad de información, los puntos de vista se multiplican y las conclusiones se vuelven más difusas. Por eso, es fundamental recordar constantemente el objetivo original.
Esta es precisamente una de las áreas donde la IA tradicionalmente no ha sobresalido: desde la perspectiva de la atención y la asociación, tiende a quedar más atrapada en el volumen de información actual y es débil en las asociaciones verdaderamente valiosas que cruzan disciplinas.
Por supuesto, el punto fuerte de la IA es su capacidad de ejecución, que puede adoptar la forma de agentes que buscan, sintetizan y resumen capa por capa, evitando así la pérdida de detalles.
Aunque llevo medio año sin publicar mucho en mi cuenta oficial, he estado siguiendo y estudiando de manera exhaustiva los principales campos de la industria. Lo que sustenta esta labor de entrada y salida de información es mi propio sistema de investigación profunda (deep-research).
Con el lanzamiento de la funcionalidad Dynamic Workflows en Claude Code la semana pasada, me propuse enfrentarlos, para ver si sus capacidades predeterminadas pueden superar completamente las mías.
2. ¿Qué son los Dynamic Workflows (Flujos de trabajo dinámicos)?
El concepto central de los Dynamic Workflows es: antes de ejecutar una tarea, la IA diseña automáticamente qué flujo de trabajo debe usar para completarla, y luego inicia la ejecución.
Esto es fundamentalmente diferente de los modos "plan" o "skill" que usábamos antes. El modo plan descompone la tarea en partes más pequeñas, pero no necesariamente sigue un flujo de trabajo racional. Solo según la disposición de tu prompt, es posible que añada criterios de verificación (cruciales para la investigación); igualmente, solo con un prompt adecuado, podrá establecer mejor algunas reglas de control (harness).
Sin embargo, el flujo de trabajo dinámico incorpora automáticamente la lógica de verificación, la convergencia de resultados y la validación por confrontación (adversarial verification).
La forma de activarlo es simple: en Claude Code, usa /deep-research y luego proporciona algunas plantillas de investigación y materiales de entrada. Si quieres usar solo la capacidad de flujo de trabajo dinámico, puedes usar un prompt o simplemente mencionar 'ultracode'. Ten en cuenta antes de usarlo que el consumo de tokens será decenas de veces mayor que el habitual.
3. Los seis modos de flujo de trabajo integrados
En el núcleo del flujo de trabajo dinámico hay seis modos de orquestación centrales resumidos por los desarrolladores. Esta es la razón por la que es más potente que un diálogo normal, un agente o una skill.
En realidad, detrás de estos seis modos solo hay dos preguntas centrales: ¿Cómo se descompone la tarea? ¿Cómo se combinan los resultados? Los seis modos son esencialmente combinaciones de estas dos variables.
3.1 Modo Enrutamiento (Clasificar y Actuar - Classify-And-Act)
Primero, un agente identifica el tipo de tarea y luego la distribuye al agente especializado más adecuado para realizarla. La lógica central es la lógica de selección de ruta, no la ejecución en paralelo o iterativa. Una tarea sigue un solo camino; los demás no se ejecutan en absoluto.
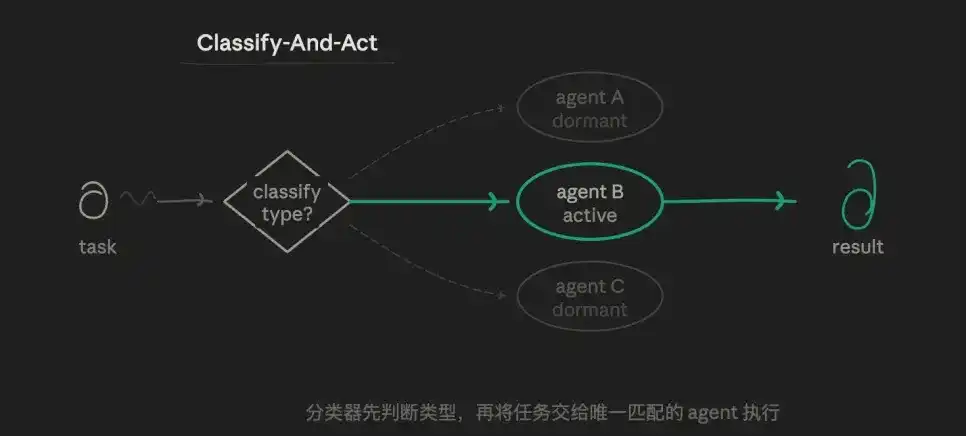
Por ejemplo, puedo tener tres subagentes predefinidos: un agente analista que verifica datos rigurosamente, un agente de salida experto en escritura y un agente desafiante especializado en encontrar fallos. La capa de enrutamiento juzgará a qué agente es más adecuado asignar la subtarea actual, en lugar de que un solo agente lo haga todo.
El valor de este modo radica en: precisión y economía. El prompt de cada agente puede ser altamente independiente, sin interferencias de otros objetivos, permitiendo una exploración con profundidad vertical. Consume la menor cantidad de tokens y tiene la velocidad de respuesta más rápida. Los límites de responsabilidad son muy claros.
La desventaja es evidente: capacidad débil para manejar tareas con límites difusos (por ejemplo, "es un problema técnico y también de cuenta").
3.2 División y Fusión (Abanico y Fusión - Fan-out & Merge)
Es también el modo que uso con más frecuencia. La lógica central es paralelismo + fusión. La tarea se divide en N subtareas independientes que se ejecutan simultáneamente, y cuando todas terminan, se fusionan uniformemente.
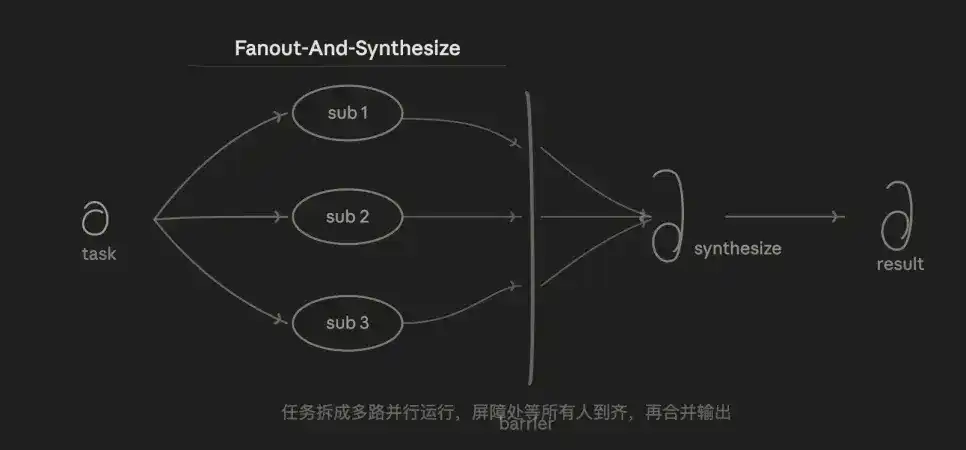
Las ventajas son velocidad y aislamiento. El tiempo total es aproximadamente igual al de la subtarea más lenta, no a la suma de todas. Cada subtarea tiene un contexto independiente, no se interfieren entre sí, y el ruido de una subtarea no contamina a las demás.
El punto débil es que el coste en tokens es N veces mayor que en serie, y la capa de fusión (Synthesize) en sí misma es un desafío de diseño: ¿cómo fusionar N salidas con estructuras inconsistentes? Una mala división de las subtareas puede provocar omisiones o cobertura redundante.
3.3 Validación por Confrontación (Adversarial Verification)
La lógica central es la verificación. Para una misma conclusión, varios agentes la desafían desde un ángulo de "refutación"; solo se aprueba si obtiene más de la mitad de los votos.
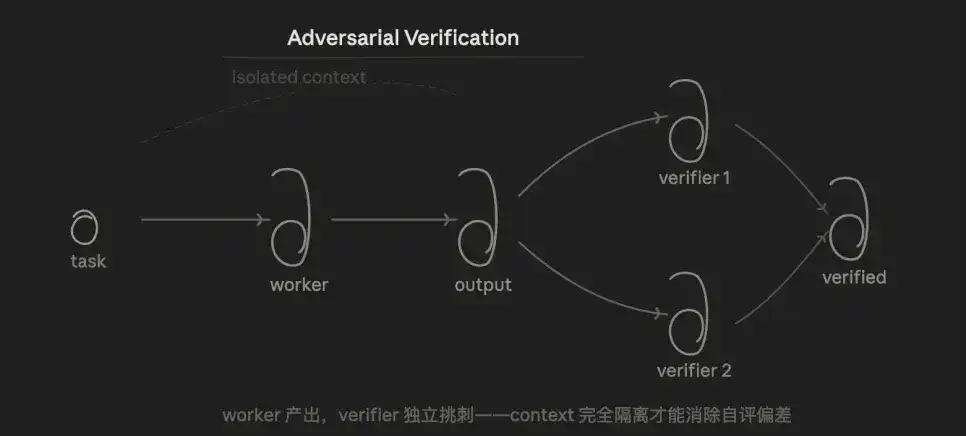
La ventaja es que, como el Verificador no conoce el razonamiento del Trabajador (Worker) y solo ve el resultado, se elimina estructuralmente el sesgo de autoevaluación que ocurre cuando "se le pide al modelo que revise su propio código".
Este modo resuelve un problema que me ha molestado durante mucho tiempo: a menudo hablamos con la IA de manera coloquial, pero la IA tiende a responder conforme a nuestras expectativas, lo que fácilmente genera "sesgo de confirmación". La validación por confrontación obliga a la IA a buscar contraejemplos, a verificar basándose en datos y experimentos, no a complacer tus ideas.
Sin embargo, si la verificación da un juicio erróneo, puede desviar al Trabajador para que se ajuste al Verificador. Por lo tanto, es preferible basarse en hechos reproducibles, no en opiniones.
Bromeando un poco, si le pides a la IA que busque problemas, puede encontrarlos infinitamente, así que debes limitar el alcance de su búsqueda de problemas.
3.4 Generación y Filtrado (Generate & Filter)
La lógica central es divergencia y luego convergencia. Primero se genera deliberadamente un exceso de candidatos, luego se eliminan mediante una rúbrica (criterios) hasta quedarse con lo esencial, y solo se retienen los resultados de alta confianza para la salida.
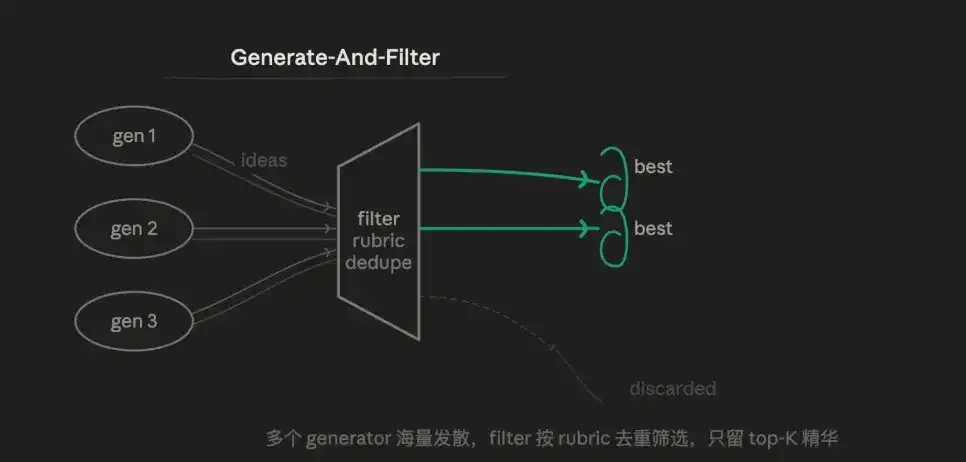
En lugar de que un agente genere una respuesta "aceptable", es mejor que genere diez y luego las filtre con una capa de verificación. Por lo tanto, la ventaja es la diversidad. Múltiples Generadores pueden usar diferentes estrategias y prompts, produciendo soluciones difíciles de prever manualmente. El paso de filtrado hace que la calidad de la salida final esté muy concentrada.
El punto débil es que la calidad de la rúbrica del Filtro determina directamente el resultado final; un diseño erróneo de la rúbrica equivale a que todo el proceso sea inútil.
Es adecuado para escenarios donde no se conoce de antemano la respuesta correcta, cuando se necesita elegir lo mejor entre múltiples posibilidades o cuando hay una necesidad explícita de diversidad.
Solo superficialmente se parece a Fan-out-And-Synthesize: Ambos son "múltiples vías en paralelo → una sola salida", lo que los hace más fáciles de confundir.
La diferencia clave está en la intención: En Fan-out, cada vía procesa una parte diferente de la tarea, los resultados son complementarios y todas contribuyen en la fusión; en Generar-y-Filtrar, cada vía procesa la misma tarea, los resultados compiten y la mayoría se descarta en la fusión. El primero es un "puzzle", el segundo un "concurso de belleza".
3.5 Modo Torneo (Tournament)
La lógica central es la eliminación competitiva. N agentes realizan independientemente la misma tarea, se eliminan por rondas mediante comparaciones por pares (pairwise) y finalmente se selecciona la mejor solución.
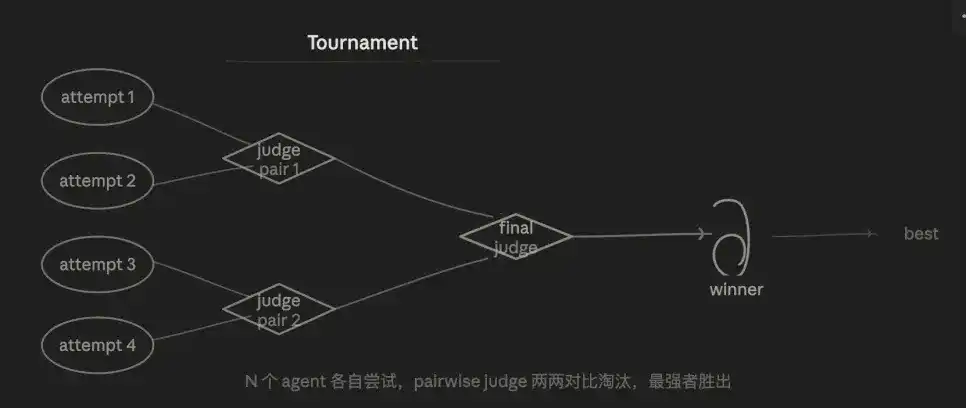
Yo he hecho esto manualmente antes: ejecutar dos o tres versiones del mismo cambio de código y luego pedir a la IA que compare cuál es mejor. Ahora se puede integrar directamente en el flujo de trabajo.
La ventaja es la estabilidad en la evaluación. Comparar de dos en dos ("¿cuál es mejor, A o B?") es mucho más estable que una puntuación absoluta ("puntúa A"), porque elimina el problema de la deriva en los criterios de puntuación. El resultado, tras múltiples rondas de competencia, da una alta credibilidad al ganador final.
También se parece superficialmente a Generar-y-Filtrar: Ambos seleccionan lo mejor entre múltiples candidatos. La diferencia clave está en el mecanismo de selección: el Torneo usa un juez por pares (pairwise judge) para comparaciones de dos en dos, es "hacer que los candidatos compitan entre sí". Es más confiable cuando la rúbrica es difícil de cuantificar o el juicio es esencialmente relativo.
3.6 Modo Bucle (Loop)
La lógica central es la iteración adaptativa. Se intenta constantemente, al encontrar obstáculos se recopila información de error, se complementa el contexto, se reintenta, y así hasta que se cumplen las condiciones de aceptación.
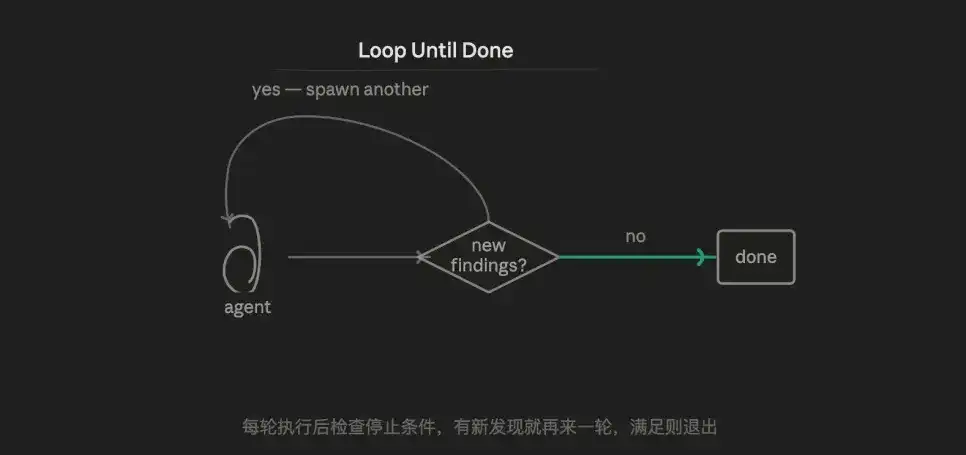
En esencia, se contrarresta la aleatoriedad de la IA: probando varias veces, eventualmente se obtendrá un mejor resultado. Pero un enfoque más maduro es combinarlo con la validación por confrontación, haciendo que cada ciclo se ejecute con más información, no solo dependiendo del azar.
La ventaja es la capacidad de manejar tareas con carga de trabajo desconocida. Los otros cinco modos asumen que los límites de la tarea están definidos; Loop Until Done es el único modo que puede manejar "no saber cuántas rondas se necesitarán".
El punto débil es el riesgo potencial de pérdida de control: una condición de parada mal diseñada puede causar un bucle infinito. El agente de cada ronda tiene un contexto completamente nuevo y no puede acumular estado entre rondas (a menos que se escriba explícitamente en un archivo).
4. La batalla entre mi propia skill y el flujo de trabajo oficial
Antes de que aparecieran los flujos de trabajo dinámicos, diseñé mi propio sistema de investigación profunda (deep-research). La lógica de mi skill era más o menos así:
- Solo proporcionar información simple (por ejemplo, que cierto proyecto lanzó cierta funcionalidad).
- Hacer que la IA busque todos los materiales relacionados: documentación oficial, código fuente, opiniones del mercado.
- Comprimir la información en resúmenes significativos.
- Múltiples agentes con diferentes roles realizan análisis confrontados y generan informes.
- Eliminación automática de duplicados, porque el contenido de múltiples agentes tiene una alta tasa de repetición.
Lo usé durante un tiempo y me pareció bastante útil. Pero tiene un defecto fundamental: carece de convergencia orientada a objetivos.
Y muchas veces, incluso con el paso 5 de eliminación de duplicados, a menudo borraba información valiosa. Si no se eliminaban duplicados, la skill fácilmente generaba un documento de diez mil palabras, con información completa pero sin decirte directamente "qué tiene que ver esto contigo, qué debes hacer".
Sin embargo, la investigación sirve para "tomar decisiones". Por eso muchas skills solo pueden detenerse en la investigación misma, alcanzan un 80%, pero les falta el 20% más crucial.
Como resultado, después de completar la investigación preliminar, la IA a menudo necesita continuar con diez rondas más de pensamiento y diálogo para llegar a una conclusión satisfactoria y completa.
¿Qué más hace el flujo de trabajo dinámico oficial?
A través de experimentos esta semana con varias tareas de investigación complejas, descubrí que el flujo de trabajo deep research integrado en Claude Code (no solo una skill, sino un módulo compilado e incrustado en CC), en comparación con mi skill, añade varios pasos clave:
- Capa de descomposición del problema: No comienza a buscar directamente, sino que primero pregunta, descomponiendo mi pregunta en varias subpreguntas: ¿Qué quieres realmente aclarar? ¿Qué tiene que ver esto contigo? ¿Qué dimensiones merecen un estudio profundo? Este paso yo solía saltármelo.
- Evaluación de credibilidad: Evalúa la falsabilidad de cada pieza de información, similar a la puntuación de autoridad en el SEO tradicional: ¿La fuente es confiable? ¿Cuántas veces se ha citado? Este es un paso que nunca pensé en añadir.
- Eliminación cruzada en lugar de fusión promedio: Mi enfoque anterior era promediar o seleccionar uniformemente todas las conclusiones, por lo que el documento era enorme. El flujo de trabajo dinámico realiza una votación multi-agente para cada conclusión, eliminando las que no obtengan suficientes votos, no es una simple fusión.
- Salida orientada a objetivos: El informe final no es una acumulación de información, sino que proporciona juicios y planes de sugerencia en torno a tu objetivo original. La clave para lograr esto reside en su capacidad predefinida para orquestar múltiples subagentes. La razón por la que mi skill carecía de orientación al objetivo final era precisamente la atenuación del peso de las instrucciones tras la avalancha de información.
¿Qué problemas resuelven estos mecanismos?
Abordan específicamente varios problemas típicos de la IA en tareas largas:
Deriva del objetivo (Goal drift): Al inicio de la tarea el estado es bueno, en medio no sabe lo que está haciendo, y al final recupera el ritmo (similar a cuando un humano se distrae en clase). Cuanto más larga la tarea, más evidente.
Parada prematura (Early stopping): Durante la ejecución encuentra dificultades, la IA cree que ha "terminado" y se detiene, cuando en realidad no se han cumplido los criterios de aceptación.
Contaminación del contexto (Context pollution): Un solo agente realizando una tarea compleja hace que el prompt inicial masivo comprima el espacio de ejecución posterior. Una mejor manera es mantener el prompt inicial en unos pocos miles de tokens y usar múltiples agentes para distribuir el contexto.
Sesgo en la salida (Output bias): La IA tiende a responder conforme a tus expectativas; hacer preguntas de manera coloquial activa más fácilmente este problema.
El flujo de trabajo dinámico resuelve estos cuatro problemas de manera estructural: añade automáticamente criterios de verificación para evitar paradas prematuras; aísla contextos mediante paralelismo; contrarresta el sesgo de salida con validación por confrontación; descompone el problema y obliga a la IA a entender primero el objetivo antes de actuar.
5. Resumen
Finalmente, como investigador durante muchos años, quedo asombrado ante este nuevo mecanismo de CC. Sus seis modos integrados (enrutamiento, división-fusión, validación por confrontación, generación-filtrado, torneo, bucle) cubren las necesidades de orquestación de la gran mayoría de las tareas de investigación complejas.
Ya no necesito diseñar manualmente la orquestación de agentes, ni hacer la eliminación de duplicados y validación cruzada yo mismo; todo esto está integrado en el propio flujo de trabajo.
Y es especialmente adecuado para pensar en problemas abiertos y exploratorios con falta de información, porque la orquestación multi-agente natural + la descomposición de objetivos de la tarea elevan nuevamente su generalidad. En realidad, hace 3 años, la IA ya era muy buena resolviendo pequeños problemas extremadamente claros y con restricciones por capas. Pero el cambio cualitativo real de la IA está en la generalidad; esto es lo que hace que su competidor pase de ser un simple código a convertirse en un verdadero Agente, de resolver un problema de forma estática a adaptarse a cualquier problema.
Por lo tanto, Dynamic Workflows no es un "diálogo único más inteligente", sino la estructuración del propio proceso de investigación.
Una investigación que originalmente requería iniciar diez o más diálogos independientes ahora se comprime en 3-4. Aunque el consumo de tokens correspondiente ha aumentado decenas de veces.
¿Por qué todavía se necesitan 3-4 veces? Creo que la causa principal radica en las diferencias entre estas demandas.
La primera es la rigurosidad del mecanismo de verificación. Investigo principalmente nuevas tecnologías en blockchain, donde a menudo la documentación oficial está desactualizada y hay datos más relevantes como código abierto, transacciones en cadena, etc. Actualmente, la IA por defecto aún prioriza la documentación oficial, no la verificación factual.
La segunda es el pensamiento profundo completamente interdisciplinario. Aunque el flujo de trabajo predefinido puede resolver algo de esto (definiendo previamente subagentes de varias dimensiones) para pensar sobre el mismo problema, la IA sobresale en modelos de pensamiento convencionales; para lo muy nuevo, muy profundo o que carece de base de datos, es ligeramente insuficiente.
La tercera es el diseño y verificación de soluciones. El valor de una solución no está en proponerla, sino en verificarla y respaldarla, lo que depende de evaluar mecanismos existentes, inversiones y costos. Con un buen ajuste (fine-tuning), la IA ciertamente puede hacerlo mejor, pero esto entraría en conflicto con la generalidad.
Finalmente, la concentración extrema de información requiere volver a comprender el nivel de conocimiento de la audiencia objetivo. Algunas personas sin antecedentes necesitan una explicación antropomórfica y vívida, mientras que otros oyentes necesitan que los impactes en una sola frase.