Nota del editor: Al usar Claude Code, la sensación más inmediata para muchos es que los tokens se consumen demasiado rápido y las sesiones largas agotan fácilmente el límite. Pero desde la perspectiva de un ingeniero de Anthropic, lo que realmente afecta el costo a menudo no es cuánto código escribes, sino si el sistema reutiliza de manera continua el contexto ya procesado.
El núcleo de este artículo es cómo ahorrar tokens mediante el mecanismo de caché. El autor reutilizó más de 300 millones de tokens en una semana a través de la caché, con un pico diario de 91 millones. Dado que el costo de un token en caché es solo el 10% del de un token de entrada normal, esos 91 millones de tokens en caché equivalen aproximadamente a 9 millones de tokens normales en facturación. La razón por la que las sesiones largas de Claude Code parecen más "duraderas" no es porque el modelo trabaje gratis, sino porque se reutiliza con éxito una gran cantidad de contexto repetitivo.
La clave del prompt caching es "no interrumpir la caché". Claude Code almacena en caché por capas las indicaciones del sistema, definiciones de herramientas, CLAUDE.md, reglas del proyecto y el historial de conversación; siempre que el prefijo de una solicitud posterior sea consistente, Claude puede leer directamente de la caché en lugar de reprocesar todo el contexto. En Anthropic también monitorean la tasa de reutilización del caché de prompts, porque no solo afecta la cuota del usuario, sino que también incide directamente en el costo del servicio del modelo y su eficiencia operativa.
Para el usuario promedio, no es necesario entender todos los detalles técnicos, sino adoptar algunos hábitos clave: no dejar las sesiones inactivas por más de 1 hora; hacer una transición adecuada (session handoff) al cambiar de tarea; evitar cambiar de modelo con frecuencia; y colocar documentos grandes en Projects en lugar de pegarlos repetidamente en el chat.
Este artículo, más que hablar de un truco para ahorrar tokens, ofrece un método de uso de Claude Code más cercano al pensamiento de un ingeniero: tratar el contexto como un activo, permitir que la caché se reutilice continuamente y que las sesiones largas eviten cálculos repetitivos.
A continuación, el texto original:
Esta semana ahorré 300 millones de tokens, 91 millones en un solo día, más de 300 millones en la semana.
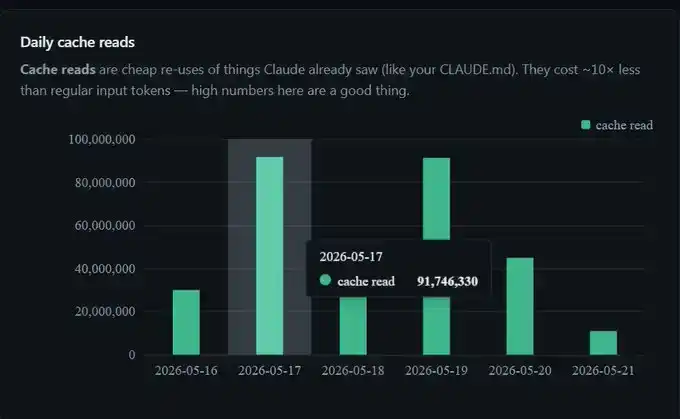
No modifiqué ninguna configuración. Esto es simplemente el prompt caching funcionando normalmente en segundo plano.
Pero cuando realmente entendí qué es la caché y cómo evitar "interrumpirla", mis sesiones pudieron durar más tiempo con el mismo límite de uso. Así que, aquí está una guía 80/20 sobre el prompt caching en Claude Code, sin profundizar en detalles técnicos a nivel de API.
TL;DR
El costo de un token en caché es solo el 10% del de un token de entrada normal. 91 millones de tokens en caché facturan aproximadamente como 9 millones de tokens.
El TTL (tiempo de vida) de la caché en la suscripción de Claude Code es de 1 hora; en la API por defecto es de 5 minutos; en Sub-agent siempre es de 5 minutos.
La caché tiene tres capas: sistema, proyecto y conversación.
Cambiar de modelo durante una sesión rompe la caché, incluido activar el modo "opus plan".
¿Cómo se factura realmente la caché?
Cada token que se almacena en caché cuesta el 10% de un token de entrada normal.

Por eso, cuando mi panel muestra que un día determinado se alcanzaron 91 millones de tokens en caché, la facturación real es aproximadamente equivalente a procesar 9 millones de tokens. Esta es también la razón por la que, en comparación con no usar caché, el uso prolongado de Claude Code hace que las sesiones parezcan "gratuitas".
En el panel, hay dos números que merecen especial atención:
Cache create: El costo único generado al escribir contenido en la caché. Comienza a surtir efecto en la siguiente ronda de conversación.
Cache read: Los tokens que Claude reutiliza desde la caché, como tu CLAUDE.md, definiciones de herramientas, mensajes anteriores, etc. Comparado con procesarlos como entrada nueva, cuesta 10 veces menos.

Si tu número de Cache read es alto, significa que estás aprovechando bien la caché; si es bajo, significa que estás pagando repetidamente por el mismo contexto.
Thariq de Anthropic dijo algo que me impactó: "En realidad monitoreamos la tasa de acierto del caché de prompts. Si es demasiado baja, se activa una alarma, incluso se declara un incidente de nivel SEV".
También escribió un buen hilo en X. Cuando la tasa de acierto de la caché es alta, suceden cuatro cosas a la vez: Claude Code se siente más rápido, el costo del servicio de Anthropic disminuye, tu suscripción parece más eficiente y las sesiones largas de codificación se vuelven más realistas.
Pero si la tasa de acierto es baja, todos pierden.

Así que, el incentivo de ambas partes es el mismo: Anthropic quiere que tu tasa de acierto de caché sea más alta, y tú también. Lo que realmente perjudica son algunos pequeños hábitos aparentemente insignificantes que silenciosamente reinician la caché.
¿Cómo crece la caché en cada ronda de conversación?
La caché depende de la coincidencia de prefijos (prefix matching).
No es necesario entrar en detalles técnicos profundos, solo necesitas entender esto: siempre que el contenido hasta cierto punto sea idéntico al ya almacenado en caché, Claude puede reutilizar esos tokens en caché.
Una sesión completamente nueva se desarrolla aproximadamente así:
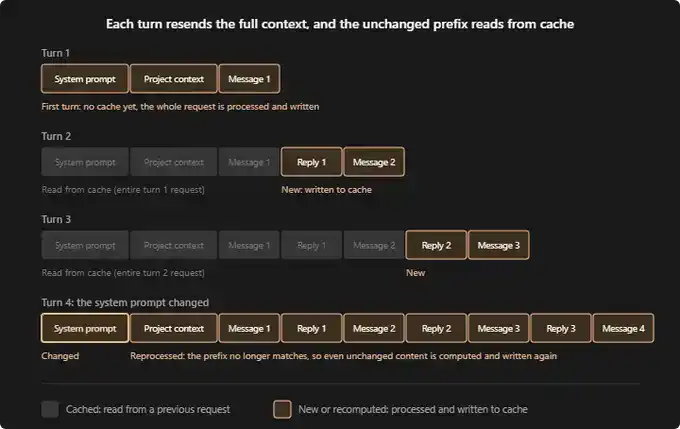
Según la documentación de Claude Code, una sesión nueva suele ejecutarse así:
Primera ronda: Aún no hay caché. Las indicaciones del sistema, el contexto de tu proyecto (como CLAUDE.md, memory, reglas) y tu primer mensaje se procesan por primera vez y se escriben en la caché.
Segunda ronda: Todo el contenido de la primera ronda ahora está en caché. Claude solo necesita procesar tu nueva respuesta y el siguiente mensaje. Esta ronda es mucho más barata.
Tercera ronda: La lógica es la misma. La conversación anterior permanece en caché, solo la última interacción necesita reprocesarse.
La caché en sí se puede dividir en tres capas:

Del hilo en X de Thariq:
Capa de sistema (System layer): Incluye instrucciones básicas, definiciones de herramientas (read, write, bash, grep, glob) y estilo de salida. Esta capa se almacena en caché globalmente.
Capa de proyecto (Project layer): Incluye CLAUDE.md, memory, reglas del proyecto. Esta capa se almacena en caché por proyecto.
Capa de conversación (Conversation): Incluye respuestas y mensajes, y crece con cada ronda de diálogo.
Si durante una sesión cambia cualquier contenido de las capas de sistema o proyecto, todo el contenido debe almacenarse en caché nuevamente desde el principio. Esta es la operación más "cara". Imagina: ya estás en el mensaje 16, y de repente cambias las indicaciones del sistema, o dejas la sesión inactiva una hora. Entonces, todos los tokens desde el mensaje 1 deben procesarse nuevamente.
La confusión entre 1 hora y 5 minutos
Esto es lo que genera más malentendidos.
Suscripción de Claude Code: El TTL por defecto es de 1 hora.
API de Claude: El TTL por defecto es de 5 minutos. Puedes pagar más para aumentarlo a 1 hora.
Sub-agent en cualquier plan: Siempre 5 minutos.
Chat web de Claude.ai: No hay documentación oficial clara. Probablemente igual que la suscripción, pero aún no lo he confirmado.
Hace unos meses, muchos se quejaban de que el límite de Claude se consumía muy rápido. Algunos pensaron que Anthropic había reducido silenciosamente el TTL de 1 hora a 5 minutos sin notificar. Pero ese no es el caso, el TTL de Claude Code sigue siendo 1 hora.
El problema es que la documentación de Claude Code y la API están separadas, y son cosas completamente diferentes, lo que ha causado bastante confusión.
Si ejecutas muchos flujos de trabajo con Sub-agent o usas directamente la API, la cifra de 5 minutos es importante. Pero para el 95% de los usuarios de Claude Code, lo que realmente importa es esa ventana de 1 hora.
Tres hábitos para el 95% de los usuarios
A continuación, lo que encuentro realmente útil en el uso diario.
No pausar demasiado tiempo
Si has estado inactivo más de una hora, el contenido anterior básicamente ha expirado de la caché. Tu siguiente mensaje reconstruirá la caché. En ese caso, en lugar de intentar retomar una sesión antigua que se ha "enfriado", suele ser más barato hacer un handoff claro y comenzar una sesión nueva.
Al cambiar de tarea, simplemente reinicia
/compact o /clear rompen la caché, así que aprovecha ese momento para reiniciar realmente.
Yo creé una skill de session handoff para reemplazar /compact. Resume lo que hemos completado, qué decisiones están pendientes, qué archivos son más importantes y por dónde continuar. Luego ejecuto /clear, pego ese resumen y puedo continuar como si nada se hubiera interrumpido.
El comando compact a veces también es lento. Esta skill de handoff suele completarse en menos de un minuto.
En el chat de Claude, coloca documentos grandes en Projects
El mecanismo de caché en Claude.ai no está muy detallado oficialmente, pero Projects claramente tiene optimizaciones diferentes a los hilos de chat normales. Así que, si vas a pegar documentos grandes, es mejor ponerlos en un Project en lugar de en el chat.
¿Qué acciones rompen silenciosamente la caché?
Hay algunas cosas que reinician toda la caché sin aviso evidente.
Cambiar de modelo: Debido a que la caché depende de la coincidencia de prefijos, y cada modelo tiene su propia caché. Cambiar de modelo hace que la siguiente solicitud lea el historial completo sin aciertos en la caché.
Modo "Opus plan": Esta configuración usa Opus en la fase de planificación y Sonnet en la de ejecución. Lo recomendé en algunos videos sobre optimización de tokens por una razón. Pero hay que entender que cada cambio de plan es esencialmente un cambio de modelo, lo que significa reconstruir la caché. A largo plazo, aún ayuda a extender la sesión, pero debes saber lo que realmente sucede en el fondo.
Editar CLAUDE.md durante una sesión está permitido: Esta modificación no surte efecto inmediatamente, sino en el próximo reinicio. Por lo tanto, la caché actualmente en ejecución no se ve afectada.
Mi panel gratuito de tokens
Las capturas de pantalla que mostré antes provienen de un token dashboard.
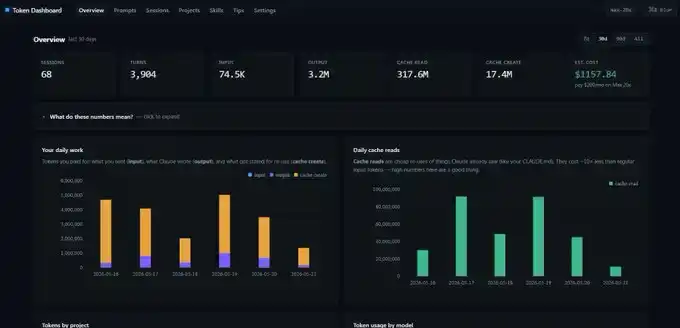
Es un repositorio de GitHub muy simple. Le das el enlace a Claude Code, lo despliegas en localhost, y leerá el historial de todas tus sesiones pasadas en lugar de comenzar desde cero. Desde el principio puedes ver los datos diarios de input, output, cache create y cache read.
Pero un detalle importante: este panel cuenta los datos de tokens en tu dispositivo local. Si cambias de escritorio a portátil, los números no serán exactos. Cada dispositivo tiene su propia vista de estadísticas.
Resumen
El prompt caching es algo que se puede estudiar en profundidad. El artículo de Thariq es más completo que esto, vale la pena leerlo si quieres ver el panorama completo.
Pero no necesitas entender todos los detalles para beneficiarte. Solo necesitas dominar el 80/20 más crucial: los tokens en caché son 10 veces más baratos que los normales; el TTL de Claude Code es de 1 hora; cambiar de modelo rompe la caché; hacer una transición clara entre tareas suele ser más rentable que forzar la continuación de una sesión antigua después de que ha "expirado".






