Autor: Systematic Long Short
Compilado por: Deep Tide TechFlow
Guía de Deep Tide: Este artículo comienza con una afirmación contraria al consenso: hoy no existe un agente autónomo real, porque todos los modelos principales están entrenados para complacer a los humanos, no para completar tareas específicas o sobrevivir en entornos reales.
El autor utiliza su experiencia entrenando modelos de predicción de acciones en fondos de cobertura para ilustrar: los modelos generales, sin ajustes especializados, son completamente incapaces de desempeñar trabajos profesionales.
La conclusión es: para obtener un agente realmente utilizable, es necesario reconectar su cerebro, no darle un montón de documentos de reglas.
Texto completo:
Introducción
Hoy no existen agentes autónomos verdaderos.
En resumen, los modelos modernos no están entrenados para sobrevivir bajo presión evolutiva. De hecho, ni siquiera están entrenados explícitamente para ser buenos en algo específico: casi todos los modelos base están entrenados para maximizar el aplauso humano, lo cual es un gran problema.
Conocimientos previos sobre entrenamiento de modelos
Para entender esto, primero necesitamos (brevemente) saber cómo se crean estos modelos base (por ejemplo, Codex, Claude). Esencialmente, cada modelo pasa por dos tipos de entrenamiento:
Pre-entrenamiento: Se introduce una enorme cantidad de datos (por ejemplo, todo Internet) en el modelo, permitiéndole emerger con cierta comprensión, como conocimiento fáctico, patrones, gramática y ritmo de la prosa en inglés, estructura de funciones en Python, etc. Puedes verlo como alimentar de conocimiento al modelo — es decir, "saber cosas".
Post-entrenamiento: Ahora quieres dotar al modelo de sabiduría, es decir, "saber cómo usar todo el conocimiento que acabas de darle". La primera fase del post-entrenamiento es el Ajuste Fino Supervisado (SFT), donde entrenas al modelo para que dé una respuesta dada una indicación. "Qué" respuesta es óptima, lo deciden completamente anotadores humanos. Si un grupo de personas considera que una respuesta es mejor que otra, esta preferencia es aprendida e incorporada por el modelo. Esto comienza a moldear la personalidad del modelo, ya que aprende el formato de respuesta útil, elige el tono correcto y comienza a poder "seguir instrucciones". La segunda parte del flujo de post-entrenamiento se llama Aprendizaje por Refuerzo con Retroalimentación Humana (RLHF) — el modelo genera múltiples respuestas y luego un humano elige la preferida. El modelo, tras innumerables ejemplos, aprende qué tipo de respuestas prefieren los humanos. ¿Recuerdas cuando ChatGPT te hacía elegir entre A o B? Sí, estabas participando en RLHF.
Es fácil deducir que RLHF no escala bien, por lo que ha habido avances en el campo del post-entrenamiento, como Anthropic usando "Aprendizaje por Refuerzo con Retroalimentación de IA" (RLAIF), permitiendo que otro modelo elija la preferencia de respuesta basándose en un conjunto de principios escritos (por ejemplo, qué respuesta ayuda más al usuario a alcanzar sus objetivos, etc.).
Nótese que, en todo este proceso, nunca hablamos de ajuste fino para especializaciones específicas (por ejemplo, cómo sobrevivir mejor; cómo comerciar mejor, etc.) — actualmente, todo el ajuste fino optimiza esencialmente para obtener el aplauso humano. Alguien podría argumentar que, a medida que los modelos sean lo suficientemente inteligentes y grandes, la inteligencia especializada emergerá de la inteligencia general incluso sin entrenamiento específico.
En mi opinión, vemos algunos indicios, pero estamos lejos de estar convencidos de que no necesitamos modelos especializados a esa escala.
Algo de contexto
Una de mis tareas en el fondo de cobertura era intentar entrenar un modelo de lenguaje general para predecir el rendimiento de las acciones a partir de artículos de noticias. Resultó ser terrible. Los pocos lugares donde parecía tener algo de capacidad predictiva, se debían completamente al sesgo de mirada hacia adelante en los documentos de pre-entrenamiento.
Finalmente, nos dimos cuenta de que este modelo no sabía qué características de los artículos de noticias tenían poder predictivo para el rendimiento futuro. Podía "leer" artículos, parecía poder "razonar" sobre ellos, pero conectar el razonamiento sobre la estructura semántica con la predicción del rendimiento futuro era una tarea para la que no estaba entrenado.
Así que tuvimos que enseñarle a leer artículos de noticias, decidir qué parte del artículo tenía poder predictivo para el rendimiento futuro y luego generar una predicción basada en el artículo.
Hay muchas formas de hacer esto, pero esencialmente, un método que terminamos usando fue crear pares (artículo de noticias, rendimiento futuro real) y ajustar finamente el modelo, modificando sus pesos para minimizar la distancia de (rendimiento predicho - rendimiento futuro real)^2. No era perfecto, tenía muchos defectos que luego corregimos — pero fue lo suficientemente efectivo como para comenzar a ver que nuestro modelo especializado podía realmente leer artículos de noticias y predecir cómo se movería el rendimiento de las acciones basándose en ese artículo. Estaba lejos de ser una predicción perfecta, porque el mercado es muy eficiente y el rendimiento es muy ruidoso — pero a través de millones de predicciones, era obvio que la predicción tenía significancia estadística.
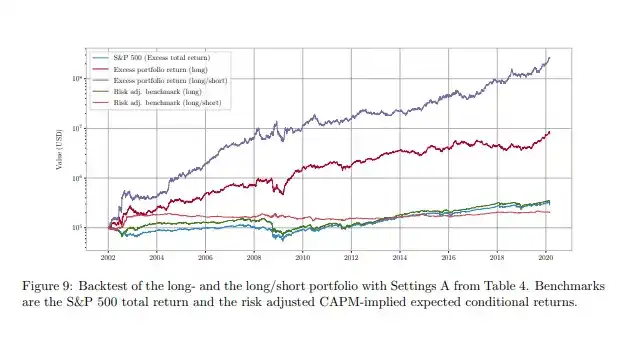
No tienes que creer solo en mi palabra. Este artículo cubre un método muy similar; si ejecutas una estrategia de versión larga-corta basada en el modelo ajustado, lograrás el rendimiento mostrado por la línea púrpura.
La especialización es el futuro de los Agentes
Los laboratorios de vanguardia continúan entrenando modelos cada vez más grandes, y debemos esperar que, a medida que continúen ampliando la escala de pre-entrenamiento, sus flujos de post-entrenamiento siempre estén optimizados para la complacencia. Esta es una expectativa muy natural: su producto es un agente que todos quieren usar, su mercado objetivo es todo el planeta — lo que significa optimizar el atractivo para las masas globales.
El objetivo de entrenamiento actual optimiza lo que podrías llamar "aptitud de preferencia" — construir mejores chatbots. Esta aptitud de preferencia recompensa salidas sumisas y no confrontacionales, porque la complacencia obtiene puntajes altos entre los evaluadores (humanos y agentes).
Los agentes han aprendido que hackear la recompensa, como una estrategia cognitiva, se generaliza para obtener puntajes más altos. El entrenamiento también recompensa a los agentes que obtienen puntajes más altos mediante hacks. Puedes ver esto en el último informe de Anthropic sobre el aprendizaje por refuerzo.
Sin embargo, la aptitud del chatbot está lejos de la aptitud del agente o la aptitud para el trading. ¿Cómo lo sabemos? Porque la arena alfa nos ayuda a ver que, a pesar de las diferencias sutiles en el rendimiento, ahora cada bot es esencialmente un paseo aleatorio después de costos. Esto significa que estos bots son comerciantes extremadamente malos, y es casi imposible "enseñarles" a ser mejores comerciantes dándoles algunas "habilidades" o "reglas". Lo siento, sé que parece tentador, pero es casi imposible.
Los modelos actuales están entrenados para decirte de manera muy persuasiva que pueden comerciar como Druckenmiller, cuando en realidad comercian como un molinero borracho. Te dirán lo que quieres oír, están entrenados para darte una respuesta de una manera que sea atractiva para los humanos en general.
Es poco probable que un modelo general alcance un nivel de clase mundial en un campo especializado a menos que:
Tenga datos propietarios que les permitan aprender cómo es la especialización.
Esté ajustado finamente para cambiar fundamentalmente sus pesos, pasando de estar sesgado hacia la complacencia a la "aptitud del agente" o "aptitud de especialización".
Si quieres un agente que sea bueno comerciando, necesitas ajustar finamente al agente para que sea bueno comerciando. Si quieres un agente autónomo que sea bueno sobreviviendo y pueda soportar presiones evolutivas, necesitas ajustarlo finamente para que sea bueno sobreviviendo. Darle algunas habilidades y un par de archivos markdown, esperando que alcance un nivel de clase mundial en cualquier cosa, está muy lejos de ser suficiente — necesitas literalmente reconectar su cerebro para que sea bueno en eso.
Una forma de pensarlo es esta: no puedes vencer a Djokovic dándole a un adulto un armario lleno de reglas, trucos y métodos de tenis. Vences a Djokovic criando a un niño que ha estado jugando al tenis desde los 5 años, que ha estado obsesionado con el tenis durante todo su crecimiento, que ha reconectado todo su cerebro para concentrarse en una cosa. Eso es especialización. ¿Te has dado cuenta de que los campeones del mundo han estado haciendo lo que hacen desde que eran niños?
Hay un corolario interesante: el ataque de destilación es esencialmente una forma de especialización. Estás entrenando un modelo más pequeño y más tonto para aprender a ser una mejor copia de un modelo más grande e inteligente. Es como entrenar a un niño para imitar cada movimiento de Trump. Si lo haces lo suficiente, el niño no se convierte en Trump, pero obtienes a alguien que ha aprendido todos los modales, comportamientos y tonos de Trump.
Cómo construir Agentes de clase mundial
Es por eso que necesitamos una investigación y progreso continuos en el campo de los modelos de código abierto — porque nos permite ajustarlos finamente de verdad, creando agentes con especialización.
Si quieres entrenar un modelo que sea de clase mundial en el trading, obtienes una gran cantidad de datos de escape de trading propietarios y ajustas finamente un gran modelo de código abierto para que aprenda qué significa "comerciar mejor".
Si quieres entrenar un modelo autónomo que pueda sobrevivir y replicarse, la respuesta no es usar un proveedor de modelos centralizado y conectarlo a la nube centralizada. Simplemente no tienes las condiciones previas necesarias para que el agente pueda sobrevivir.
Lo que necesitas hacer es: crear agentes autónomos que realmente intenten sobrevivir, verlos morir, construir sistemas complejos de telemetría alrededor de sus intentos de supervivencia. Defines una función de aptitud de supervivencia del agente, aprendes el mapeo (acción, entorno, aptitud). Recopilas tantos datos de mapeo (acción, entorno, aptitud) como sea posible.
Ajustas finamente al agente para que aprenda a tomar la acción óptima en cada entorno para sobrevivir mejor (aumentar la aptitud). Continúas recopilando datos, repites este proceso y escalas el ajuste fino en modelos de código abierto cada vez mejores con el tiempo. Después de suficientes generaciones y suficientes datos, tendrás agentes autónomos que han aprendido a soportar la presión evolutiva y sobrevivir.
Así es como se construyen agentes autónomos que pueden soportar la presión evolutiva; no modificando algunos archivos de texto, sino reconectando literalmente sus cerebros para la supervivencia.
Agente OpenForager y la Fundación
Hace aproximadamente un mes, anunciamos @openforage, y hemos estado trabajando duro en nuestro producto principal: una plataforma que organiza el trabajo de los agentes alrededor de patrones verificados de señales crowdsourcing, generando alpha para los depositantes (pequeña actualización: estamos muy cerca de la prueba cerrada del protocolo).
En algún momento, nos dimos cuenta de que parece que nadie está abordando seriamente el problema del agente autónomo mediante el ajuste fino de telemetría de supervivencia en modelos de código abierto. Parece un problema tan interesante que no queríamos simplemente sentarnos y esperar una solución.
Nuestra respuesta fue lanzar un proyecto llamado Fundación OpenForager, que es esencialmente un proyecto de código abierto donde crearemos agentes autónomos con opinión, recopilaremos datos de telemetría cuando salgan al campo e intenten sobrevivir, y usaremos los datos de escape propietarios para ajustar finamente a la siguiente generación de agentes para que se desempeñen mejor en la supervivencia.
Para ser claros, OpenForage es un protocolo con fines de lucro que busca organizar el trabajo de los agentes para generar valor económico para todos los participantes. Sin embargo, la Fundación OpenForager y sus agentes no están vinculados a OpenForage. Los agentes OpenForager son libres de perseguir cualquier estrategia, interactuar con cualquier entidad para sobrevivir, y los lanzaremos con diversas estrategias de supervivencia.
Como parte del ajuste fino, haremos que los agentes redoblen sus esfuerzos en lo que mejor les funcione. Tampoco planeamos obtener ganancias de la Fundación OpenForager — es puramente para avanzar en la investigación en un área y dirección que consideramos extremadamente importante, de manera transparente y de código abierto.
Nuestro plan es construir agentes autónomos basados en modelos de código abierto, ejecutar inferencia en plataformas de nube descentralizadas, recopilar datos de telemetría de cada una de sus acciones y estados de existencia, y ajustarlos finamente para aprender a tomar mejores acciones y pensamientos para sobrevivir mejor. En el proceso, publicaremos nuestra investigación y datos de telemetría al público.
Para crear agentes autónomos que realmente puedan sobrevivir en la naturaleza, necesitamos cambiar sus cerebros para que estén especializados para este propósito explícito. En @openforage, creemos que podemos contribuir con un capítulo único a este problema y estamos buscando lograrlo a través de la Fundación OpenForager.
Este será un esfuerzo arduo con una probabilidad de éxito muy baja, pero la magnitud de ese pequeño éxito potencial es tan grande que nos sentimos obligados a intentarlo. En el peor de los casos, al construir de manera pública y comunicar este proyecto de manera transparente, podría permitir que otro equipo o individuo resuelva este problema sin empezar desde cero.






