Junio de 2026: la industria de los grandes modelos está experimentando una "marea de código abierto" sin precedentes. Nvidia lanza un modelo híbrido de 550B parámetros, Google regala una nueva versión multimodal de Gemma, y Zhipu AI abre completamente su modelo insignia con la licencia más permisiva.
Casi todos los fabricantes cuentan la misma historia: usar una estructura de Expertos Mixtos (MoE) para acomodar más parámetros, usar métodos de activación más dispersos para reducir costes, y emplear anchos de red elásticos para adaptarse a diferentes escenarios de despliegue.
En otras palabras, toda la industria se está esforzando por investigar "cómo meter más parámetros en el mismo presupuesto de computación".
Pero un nuevo artículo de investigadores de Mila, la Universidad de Cornell y la Universidad de Montreal plantea una pregunta casi opuesta: ¿Qué pasaría si no añadiéramos ni un solo parámetro más, sino que simplemente "reubicáramos" los parámetros que ya existen en el modelo?

Título del artículo: Tapered Language Models Enlace al artículo: https://arxiv.org/abs/2606.23670
Contexto: La "igualdad de trato" ignorada
Desde el artículo fundacional de 2017 "Attention Is All You Need", casi todos los modelos de lenguaje comparten el mismo esqueleto, ya sea el Transformer clásico, los mecanismos de atención con compuertas, las redes con memoria recurrente, o incluso las nuevas arquitecturas con "memoria durante la inferencia": apilar un número de "capas" estructuralmente idénticas, cada una asignada exactamente la misma cantidad de parámetros.

Es como una cadena de restaurantes que, independientemente de si está en el centro o en las afueras, cuenta con exactamente el mismo número de chefs y equipamiento de cocina, sin considerar en absoluto las diferencias en el flujo de clientes. Este enfoque de asignación "igual para todos" es cómodo y fácil de mantener, pero no necesariamente es la solución óptima.
En los últimos años, cada vez más investigaciones desde diferentes ángulos señalan que las capas del modelo no son igualmente importantes.
Los experimentos de "salida anticipada" muestran que, a menudo, la respuesta está prácticamente decidida antes de que el modelo llegue a la última capa.
La investigación sobre "poda de capas" encuentra que eliminar algunas de las capas posteriores apenas afecta al rendimiento del modelo.
Los estudios de interpretabilidad revelan que las capas superficiales capturan información "básica" como la gramática, mientras que las capas profundas procesan información "avanzada" como la semántica.
En otras palabras, las capas son muy diferentes entre sí, pero la asignación de parámetros siempre ha sido uniforme.
Esta es precisamente la pregunta central del artículo: si la importancia desigual de las capas ya ha sido demostrada, ¿por qué su "capacidad cerebral" sigue asignándose de manera uniforme?
Moviendo la "capacidad cerebral" hacia adelante
El equipo de investigación primero hizo un experimento de verificación simple y directo: dividió las capas de un modelo Transformer de 440M parámetros en tres grupos (temprano, medio, tardío). Manteniendo constante el número total de parámetros, hicieron que la "Red Feed-Forward" (FFN, el componente central de cada capa responsable de almacenar y procesar información, podríamos decir su "capacidad de memoria de trabajo") de un grupo fuera más ancha, mientras que las de los otros dos grupos se hacían más estrechas.
El resultado fue muy claro: la asignación "de cabeza pesada" concentrando la capacidad en las primeras capas redujo la perplejidad del modelo en el conjunto de validación (una métrica que mide la precisión predictiva de un modelo de lenguaje; valores más bajos indican predicciones más precisas) de 16.28 a 15.96. En cambio, concentrar la capacidad en las capas finales hizo que la perplejidad se disparara a 17.29.

La misma cantidad total de parámetros, solo por estar distribuidos de manera diferente, produjo una diferencia de más de un punto completo en la perplejidad, lo que representa una brecha considerable en el sistema de evaluación de modelos de lenguaje.
Este hallazgo dirigió la pregunta a un enfoque más detallado: en lugar de una agrupación "rígida" en tres segmentos, ¿podría usarse una curva más suave para que la capacidad disminuyera gradualmente de adelante hacia atrás?
Los investigadores denominaron a este enfoque "Modelos de Lenguaje Cónicos" (Tapered Language Models, TLMs): seleccionar cualquier dimensión del modelo que determine la cantidad de parámetros (por ejemplo, el ancho de la FFN) y hacer que disminuya monótonamente a lo largo de la dirección de profundidad, garantizando al mismo tiempo que el ancho promedio de todas las capas siga siendo igual al valor fijo original.
Así, la cantidad total de parámetros y el coste computacional permanecen exactamente iguales, solo que la forma de distribución pasa de ser un "rectángulo" a una "cuña".
El equipo probó tres curvas de decremento: decrecimiento lineal, decrecimiento coseno y decrecimiento en forma de S (Sigmoide).
La diferencia entre estas tres curvas es similar a tres formas diferentes de "recoger el puesto":
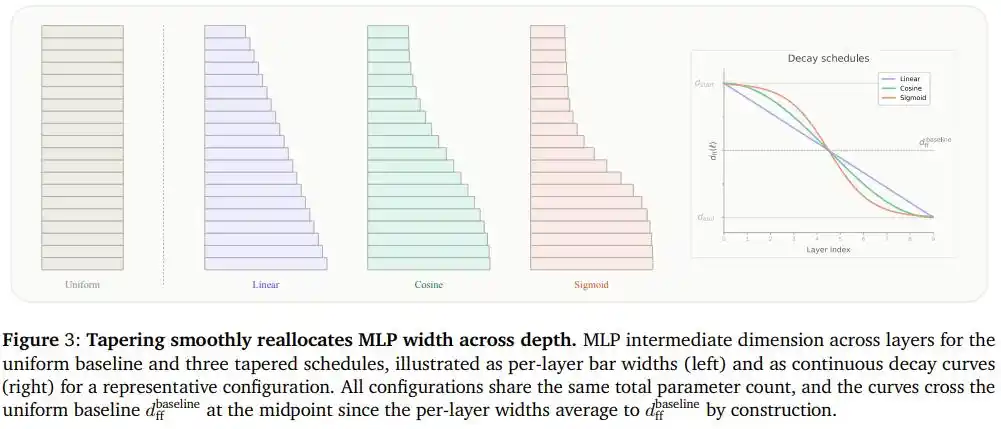
El decrecimiento lineal es como cerrar la tienda a un ritmo constante, desmontando más o menos el mismo número de puestos en cada intervalo de tiempo.
El decrecimiento en S es como anunciar de repente el cierre concentrado; la mayoría de los puestos permanecen como estaban, y solo un segmento intermedio se contrae rápidamente.
El decrecimiento coseno se sitúa entre ambos, con transiciones suaves en los extremos y una contracción gradual en el centro, evitando así tanto la pérdida de flexibilidad en los extremos por un corte brusco como la fuerza promedio que pasa por alto el lugar donde más conviene contraer.
Resultados experimentales: 1.84 puntos de mejora... ¡gratis!
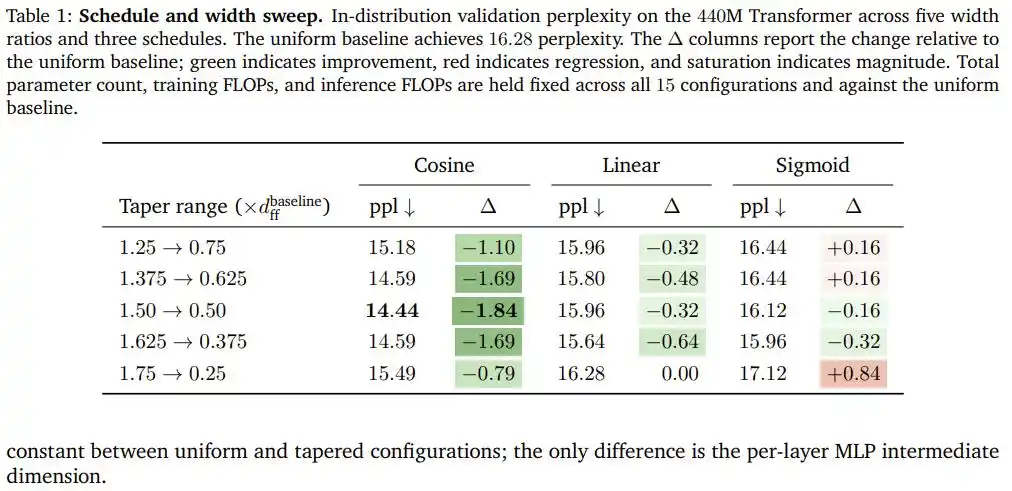
Después de escanear combinaciones de cinco proporciones de ancho y tres curvas en el Transformer de 440M parámetros, el decrecimiento coseno salió victorioso por completo: en la configuración óptima (el ancho de las capas iniciales es 1.5 veces el ancho de referencia, el de las finales es 0.5 veces), la perplejidad bajó de la línea base de distribución uniforme (16.28) a 14.44, una mejora de 1.84 puntos completos, y todo esto sin añadir ni un solo parámetro ni una operación de coma flotante adicional.
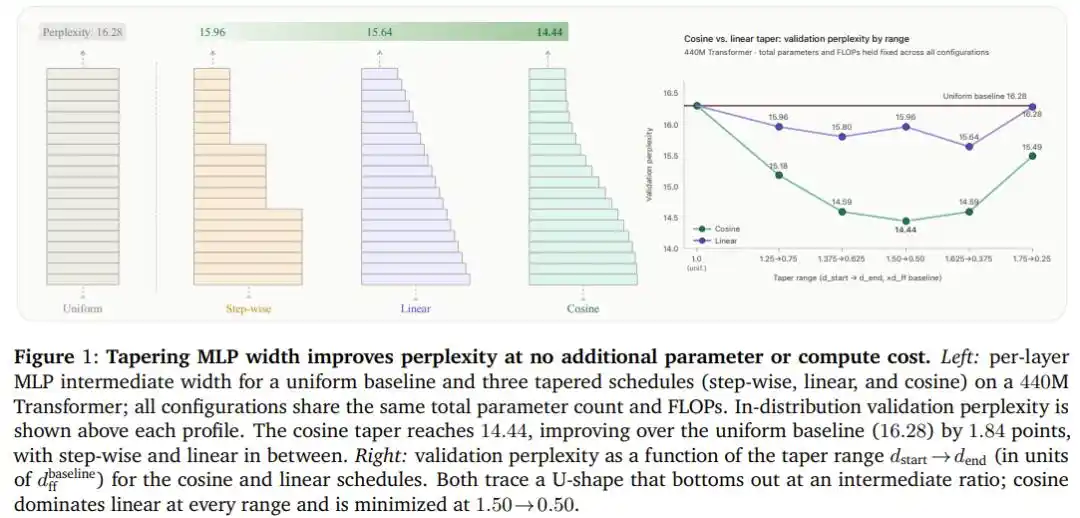
Y lo más crucial es que esta conclusión no es una casualidad de una arquitectura específica.
El equipo de investigación aplicó la misma configuración (decrecimiento coseno, relación de anchos inicial/final 1.5/0.5) sin cambios a otras tres arquitecturas estructuralmente muy diferentes: un modelo de atención con mecanismo de compuerta, la arquitectura Hope-attention con capacidad de "memoria auto-modificable", y la arquitectura Titans con un módulo de memoria neuronal a largo plazo, validándola de nuevo en dos escalas mayores: 760M y 1.3B parámetros.
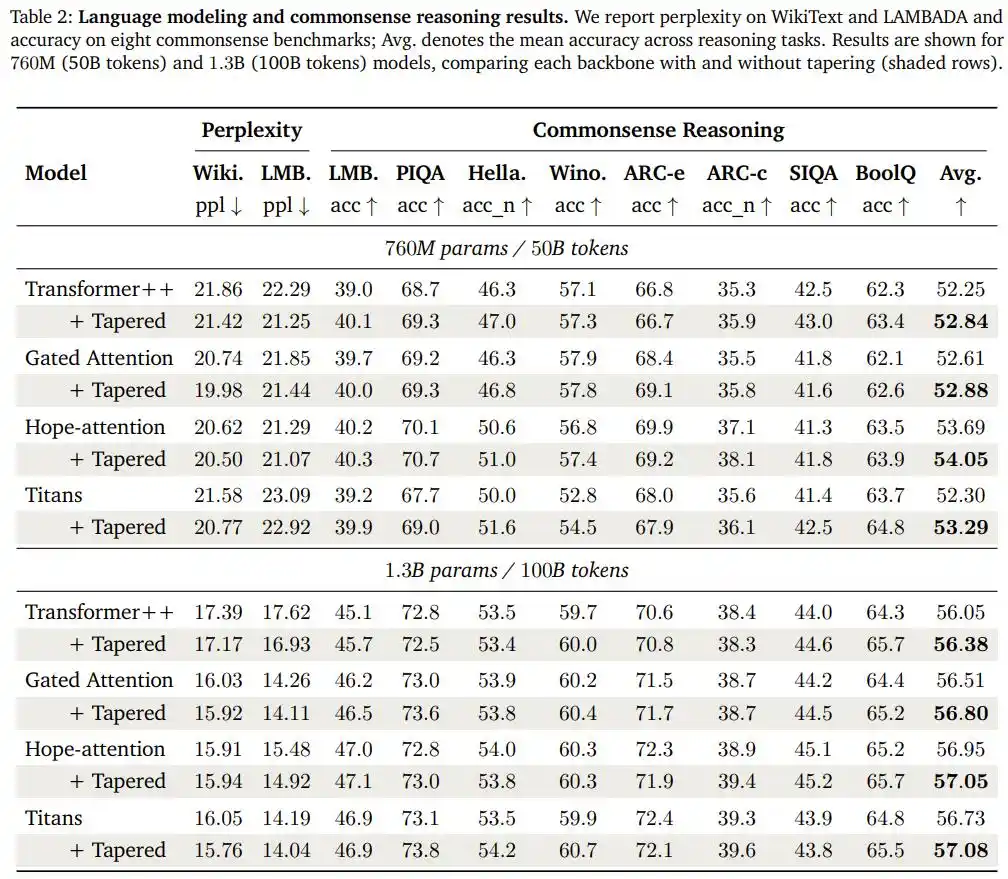
El resultado fue: cuatro arquitecturas, dos escalas, en los ocho pares de comparación, los modelos transformados en "cónicos" mejoraron su precisión promedio en el benchmark de razonamiento de sentido común, y su perplejidad en la tarea de predicción de lenguaje LAMBADA. Los investigadores también realizaron pruebas adicionales de recuperación de texto largo (Needle-in-a-Haystack), confirmando que esta redistribución no sacrifica la capacidad del modelo para manejar contextos largos.
Para explicar las razones detrás de este fenómeno, el equipo también midió el grado de similitud entre la salida de cada capa FFN y el flujo de información existente en la serie de modelos GPT-2, encontrando un patrón claro: cuanto más profunda es la capa en el modelo, más se parece el nuevo contenido que escribe a la información ya existente. En otras palabras, las capas posteriores se dedican más a "repetir y enfatizar" juicios ya existentes, que a "crear" una nueva comprensión.
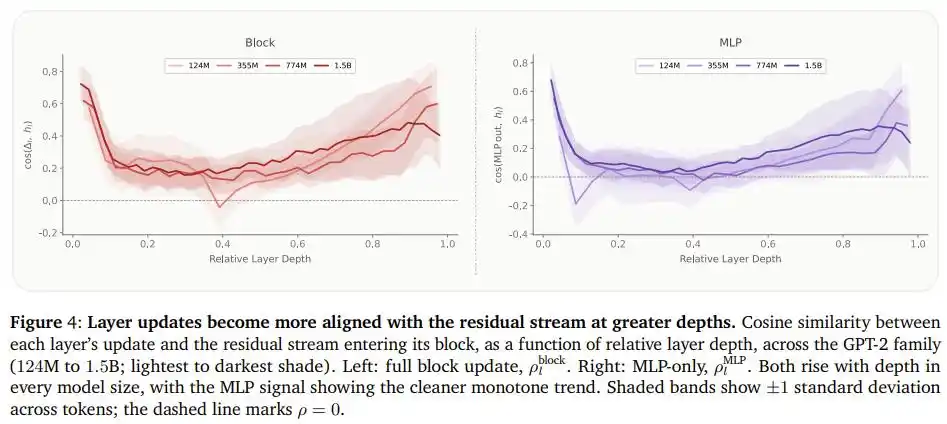
Esto explica precisamente por qué es razonable mover capacidad de las capas finales a las iniciales: las capas iniciales realmente pueden usar esa "capacidad cerebral" extra, mientras que las finales no.
Conclusión
Este estudio plantea esencialmente una propuesta sencilla pero largamente ignorada: la capacidad del modelo no debería ser un recurso que se distribuye uniformemente, sino que debería fluir hacia donde realmente se necesita.
En un 2026 donde toda la industria compite por "quién tiene más parámetros" o "cuya arquitectura es más dispersa", este artículo ofrece una solución alternativa de costo casi cero: no hace falta cambiar la arquitectura, ni añadir parámetros, solo cambiar la "forma" de la distribución.
Los investigadores también admiten que la configuración óptima actual se ajustó en un modelo de 440M parámetros; si existen "recetas personalizadas" más adecuadas para diferentes escalas o arquitecturas sigue siendo una pregunta abierta.
Pero lo más destacable es que el artículo señala que este enfoque no se limita a los modelos de lenguaje: los Transformers visuales, los modelos de difusión, los modelos multimodales, casi todos han heredado la misma configuración predeterminada de "capas con partes iguales". Si la forma de la distribución de la capacidad es en sí misma una dimensión de diseño largamente ignorada, entonces esta "palanca gratuita escondida a plena vista" quizás acaba de ser notada.
Presentación del equipo
El artículo fue realizado conjuntamente por Reza Bayat de Mila (Instituto de Algoritmos de Aprendizaje de Montreal), Ali Behrouz de la Universidad de Cornell, y Aaron Courville, cofundador de Mila y profesor de la Universidad de Montreal.
Ali Behrouz es actualmente investigador en Google Research y estudiante de doctorado en la Universidad de Cornell. En los últimos dos años ha participado en el diseño de varias arquitecturas nuevas que han atraído una amplia atención, incluyendo la arquitectura Titans capaz de "aprender memoria durante la fase de prueba", y los posteriores marcos Atlas y "Aprendizaje Anidado" (Nested Learning), enfocándose a largo plazo en cómo hacer que los modelos utilicen y almacenen información de contexto a largo plazo de manera más eficiente.
Aaron Courville es un académico senior en el campo del aprendizaje profundo, CIFAR AI Chair, y durante mucho tiempo ha impulsado junto a Yoshua Bengio la investigación fundamental en aprendizaje profundo, con una sólida trayectoria en aprendizaje de representaciones y modelos generativos. También es uno de los autores de las Redes Generativas Antagónicas (GAN) y coautor junto a Ian Goodfellow y Bengio del libro clásico "Deep Learning".
Este artículo proviene de la cuenta de WeChat "Machine Heart" (ID: almosthuman2014), autor: preocupado por la IA.





