【Introducción】GPT-5.5 expuesto por «pensar falso», reemplazado furtivamente por mini tras dos horas de uso, 200 dólares al mes por un «cerebro de Schrödinger». Comando trace lo confirma, documentación oficial lo admite. Usuarios no dejan de quejarse: OpenAI, ¿a quién quieres engañar?
¡ChatGPT vuelve a ser acusado de «volverse más tonto»!
Estos días, X ha sido el primero en estallar.
El usuario Lisan al Gaib descubrió que, tras usar GPT-5.5 una o dos horas, de repente se volvía estúpido, respondiendo cada solicitud al instante, con una calidad que caía en picado.
Pero en la interfaz, seguía mostrando «GPT-5.5 Extended Thinking».
Es decir, la etiqueta de pensamiento seguía ahí, pero el pensamiento en sí había desaparecido.

200 dólares al mes por un «modelo de Schrödinger»
En el foro de desarrolladores de OpenAI, un post de queja estalló al mismo tiempo.
Agentify.sh indicó que GPT-5.5, de repente, perdía la capacidad de seguir instrucciones mientras se usaba.
Viendo cómo anunciaba entusiasmado que «lo había arreglado», pero la calidad del código era tan mala que provocaba reversiones masivas.
Tareas de UI que antes el 5.5-med resolvía con facilidad, ahora ni los cambios más simples podía hacerlos.
Subir a 5.5-high, inútil. Subir a xhigh, tampoco funcionaba.
Y el xhigh, que antes podía funcionar varias horas, ahora claramente duraba menos.
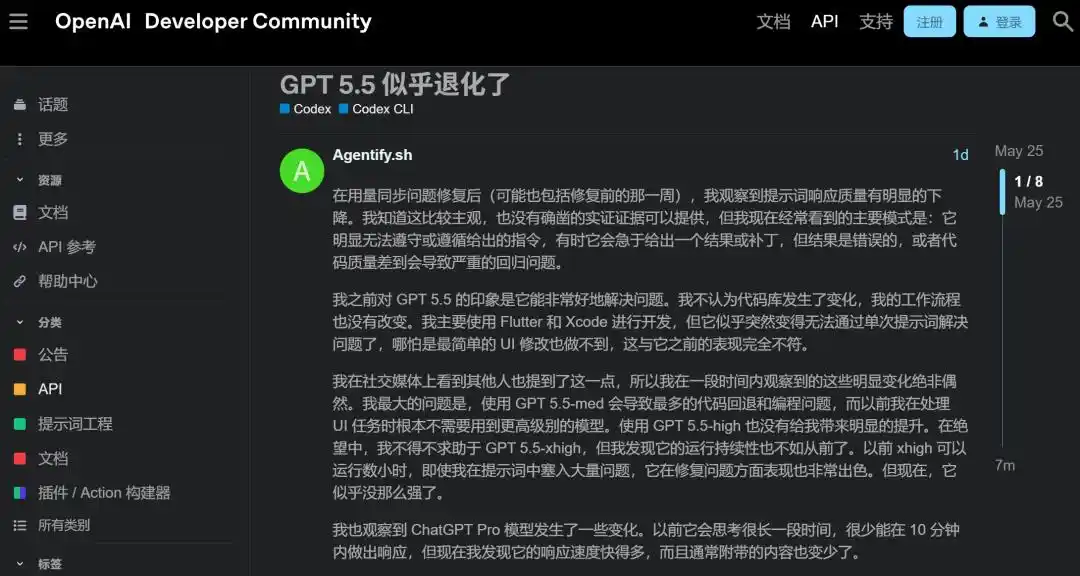
Al publicarse el post, la sección de respuestas estalló al instante.
Alguien directamente volvió a la versión 5.4.
Otro usaba el nivel más alto, xhigh, pero «comparado con la semana pasada, claramente va peor, tareas largas fallan con frecuencia, no sigue el flujo de trabajo en absoluto».
Otro reportó algo aún más absurdo, «consultas simples también tardan mucho en procesarse, si lo interrumpes para corregir la dirección, directamente te ignora y continúa con el plan erróneo anterior».
Exacto, todos describían el mismo fenómeno: el cerebro de GPT, sin saber cuándo, había sido reemplazado a escondidas.
El rendimiento actual de GPT-5.5 es similar al de 5.3, sin exagerar. Los primeros días era impresionante, ahora no encuentras rastro del modelo original.

No es una ilusión, OpenAI lo tiene escrito negro sobre blanco
Para verificarlo, Lisan al Gaib hizo una prueba comparativa.
Misma cuenta, en el lado de ChatGPT usando Extended Thinking los resultados eran basura, pero al cambiar al lado de Codex usando xhigh, inmediatamente volvía a la normalidad.
En sus propias palabras, Codex era «literalmente 4 mil millones de veces más inteligente que esta cosa».
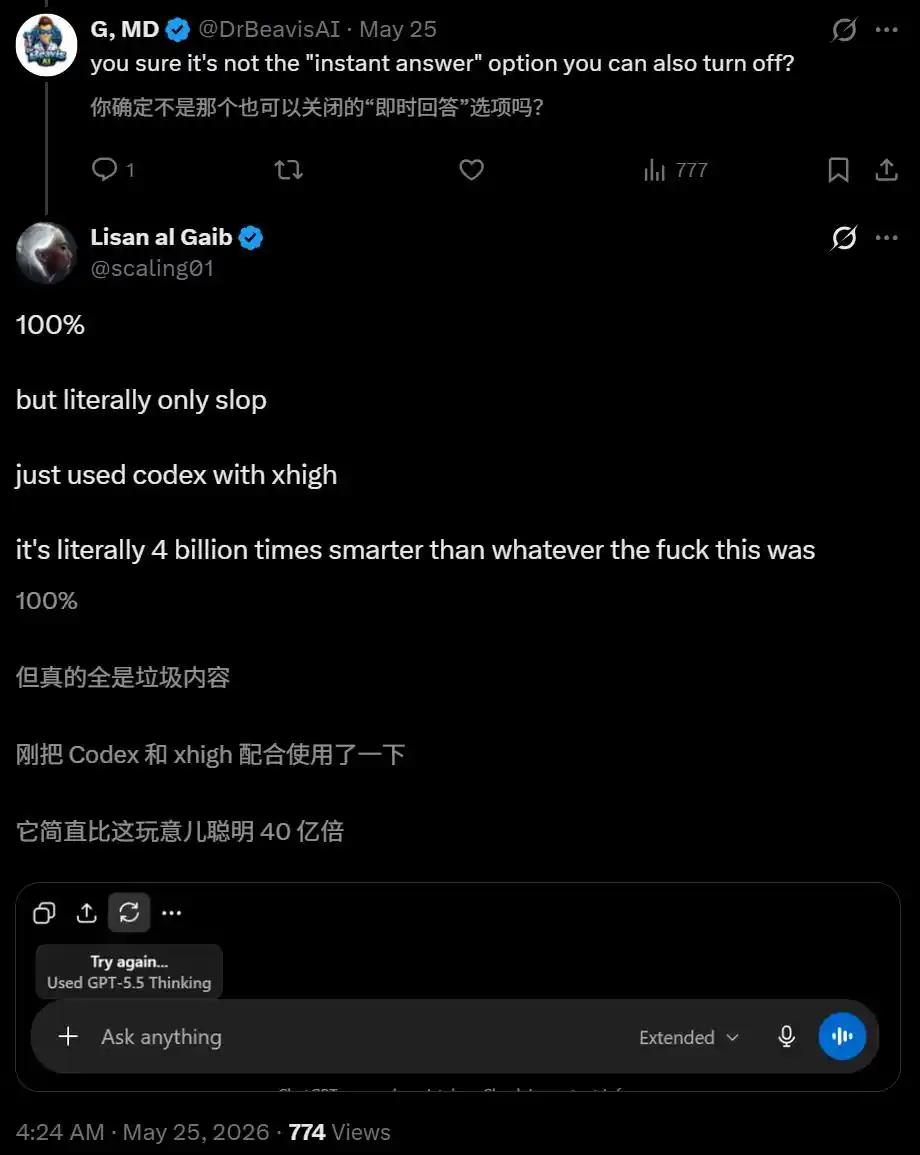
El desarrollador Andrew Curran ideó una solución ingeniosa: preguntarle directamente al modelo «¿Cuál es la fecha de corte de tus datos de entrenamiento?»
El modelo respondió: Agosto de 2025.
El problema es que la fecha de corte de GPT-5.5 Thinking es diciembre. ¡Agosto es la fecha de corte de la versión Instant!
Es decir, él seleccionó Thinking, pero el sistema en realidad le ejecutó Instant.
La etiqueta del modelo en la interfaz no cambió ni una letra, pero el modelo detrás había sido reemplazado furtivamente......
Lo gracioso es que esta vez OpenAI, en su propia documentación de ayuda, confirmó lo que los usuarios decían.
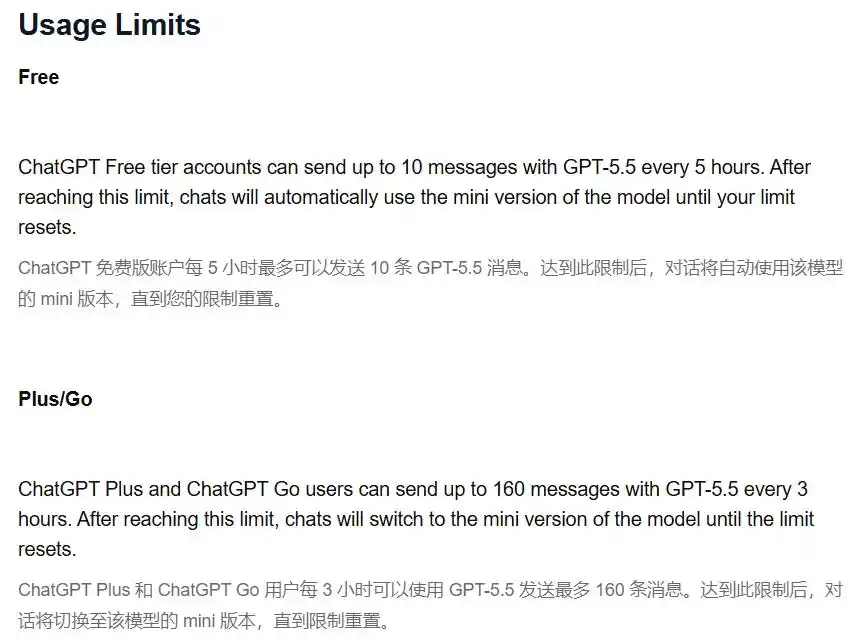
Según las instrucciones oficiales del Centro de Ayuda de OpenAI, los usuarios Plus pueden enviar un máximo de 160 mensajes de GPT-5.5 cada 3 horas.
Una vez agotados, el sistema cambia silenciosamente al modelo mini, hasta que se reinicia la cuota.
Nota la palabra «silenciosamente».
Sin ventana emergente de advertencia, sin cambio en la etiqueta del modelo, sin ningún feedback visual.
Tú crees que sigues usando el modelo insignia, pero al otro lado ya han cambiado silenciosamente a mini.
Los usuarios Pro tampoco se alegren demasiado.
El modo de pensamiento Heavy, ese nivel de razonamiento más alto exclusivo para Pro, también está sujeto a limitaciones de capacidad cuando la carga del servidor es alta. Tampoco hay advertencia.
En otras palabras, una suscripción Pro de 200 dólares al mes compra un servicio que puede ser «cambiado por otro» en cualquier momento.

Y esta operación de «la etiqueta no cambia, pero el cerebro sí», fue descubierta incluso antes en el lado de Codex.
En febrero de este año, apareció un issue en GitHub donde un usuario Pro, usando el comando trace, descubrió que había solicitado GPT-5.3 Codex, pero el modelo realmente devuelto era GPT-5.2.
Ni siquiera era 5.2 Codex, era la versión base inferior 5.2.
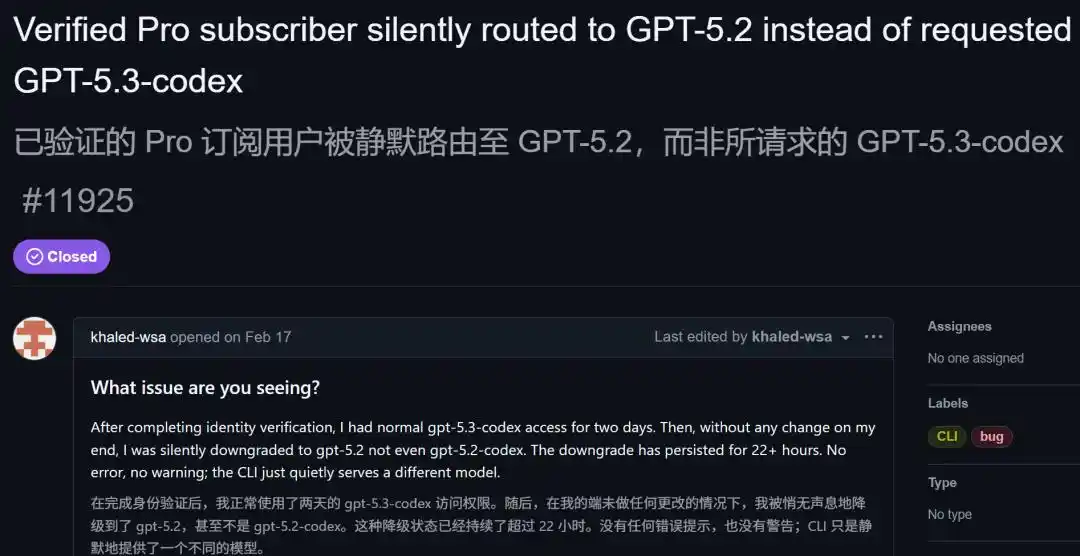
Publicó el comando para reproducirlo:
- RUST_LOG='codex_api::sse::responses=trace' codex exec --skip-git-repo-check -s read-only -m 'gpt-5.3-codex' 'hi' 2>&1 >/dev/null | rg -o --replace '$1' '"model":"([^"]+)"' | head -n1
- Salida: gpt-5.2-2025-12-11
- Esperado: gpt-5.3-codex
Varios usuarios Pro confirmaron el mismo degradado en el mismo issue.
Y este degradado es «pegajoso», no se recupera solo, y no hay ninguna explicación.

Incluso, el día del lanzamiento de GPT-5.5 en abril, había usuarios reportando que la velocidad del modo Fast era similar a la de Standard, pero la facturación seguía siendo la de Fast.
Una tarea simple tardó 7 minutos y 49 segundos, cuando normalmente debería ser 5-6 minutos.
OpenAI lo reconoció, y luego no pasó nada más
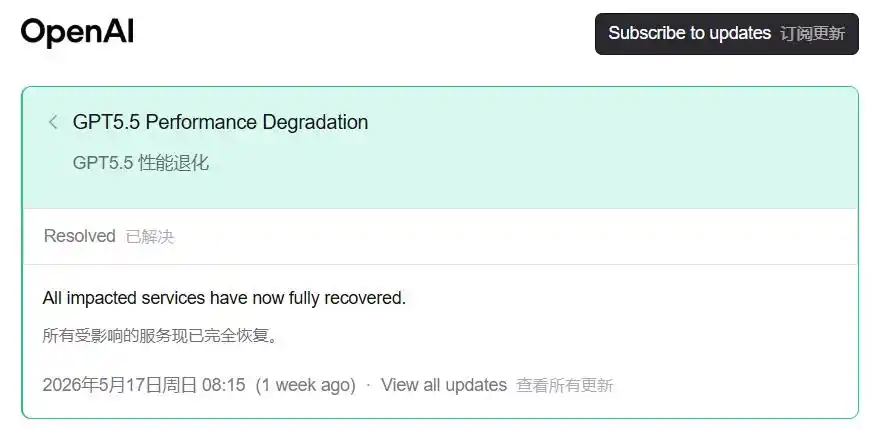
El 15 de mayo, apareció un registro en la página de estado de OpenAI.
Degradación del Rendimiento de GPT5.5, estamos investigando problemas de degradación del rendimiento de GPT-5.5 reportados por algunos usuarios.
El 17 de mayo, el estado se actualizó a «Resuelto».
Pero según la línea de tiempo de los posts en el foro, las quejas sobre la pérdida de inteligencia del 24-26 de mayo fueron más fuertes que la ola del 15 de mayo.
O el problema «resuelto» volvió, o simplemente nunca se resolvió realmente.
Cada actualización es una «polémica por pérdida de inteligencia»
Aunque todas las empresas enfrentan quejas de «el modelo se vuelve estúpido», OpenAI, desde GPT-5 hasta GPT-5.5, no se ha perdido ni una actualización.
Cada vez OpenAI dice que está investigando, cada vez dice que está resuelto, y luego continúa con la siguiente versión.
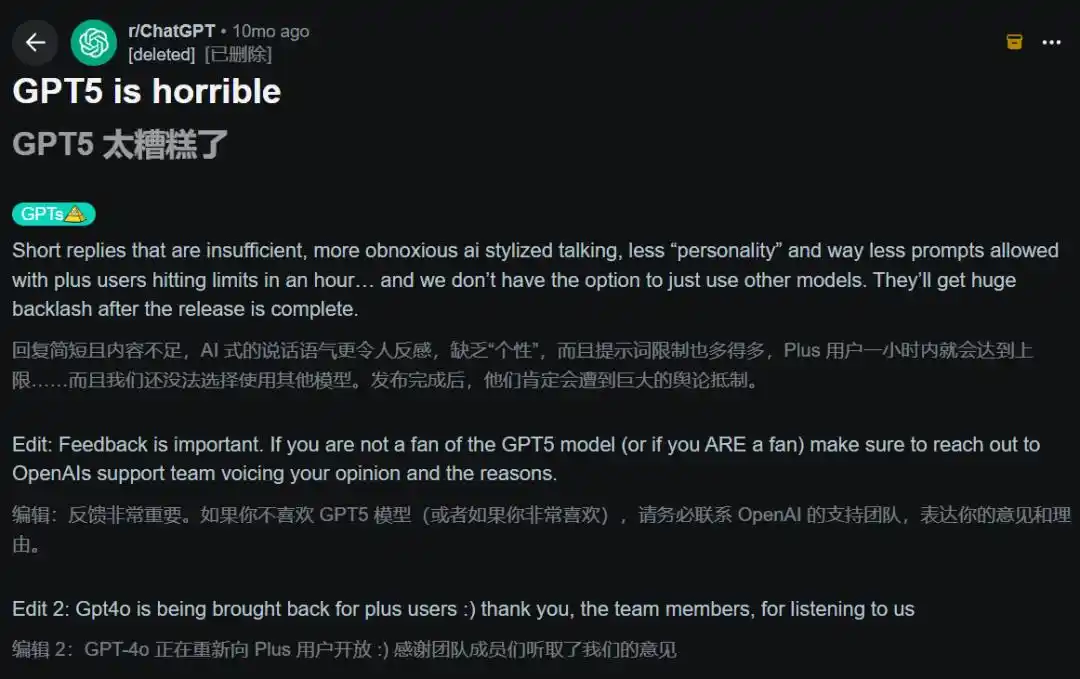
Agosto de 2025, lanzamiento de GPT-5. El título del post caliente en Reddit era directamente «GPT-5 es una mierda». Usuarios se quejaban de respuestas cortas, más rechazos, menos sensación de personalidad.
OpenAI se vio forzado a restaurar urgentemente la opción GPT-4o. Altman en un AMA de Reddit admitió personalmente «más accidentado de lo que esperábamos».
Diciembre de 2025, GPT-5.2. Calidad de traducción retrocedida, inventaba APIs que no existían, se negaba a ejecutar instrucciones de estilo que 5.1 completaba fácilmente.
Febrero de 2026, GPT-5.3-Codex. Usuarios Pro degradados silenciosamente a 5.2, comando trace lo confirma.
Marzo de 2026, GPT-5.4. Aparece en el foro comunitario de OpenAI el post «GPT-5.4 ha degradado notablemente en Codex», respuestas de usuarios lo confirman.
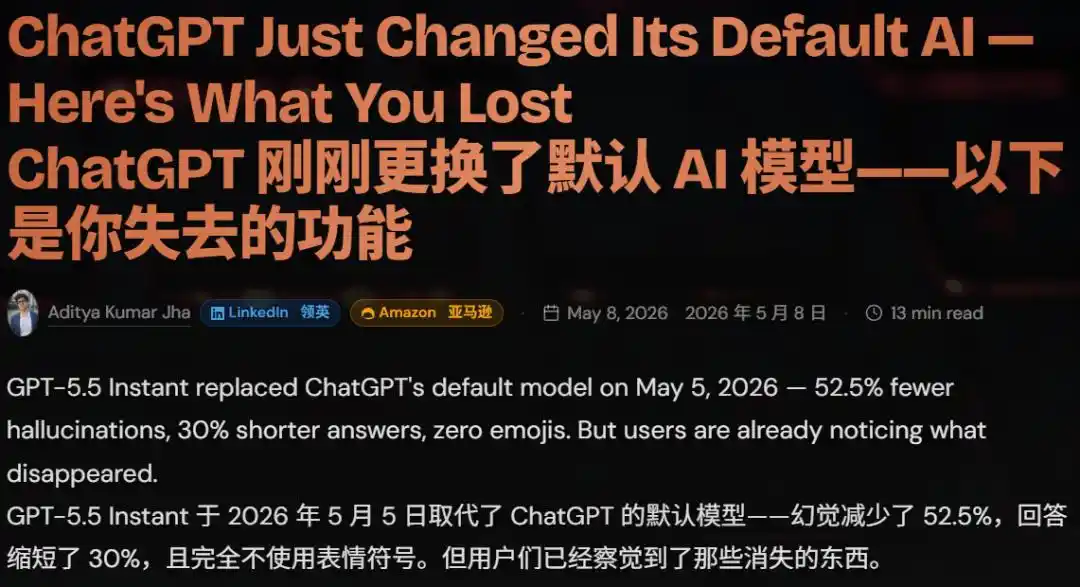
Principios de mayo de 2026, lanzamiento de GPT-5.5 Instant. Longitud de respuestas reducida un 30%, emojis casi desaparecen. Resumen de usuarios: precisión mejorada, pero la temperatura desapareció.
Finales de mayo de 2026, es decir, ahora. Quejas por pérdida de inteligencia en el modo Thinking estallan de nuevo.
Lisan al Gaib revela que, desde que GPT-5 se lanzó y él lideró esa batalla por la cuota de ChatGPT Plus, «cada semana recibo mensajes privados así».
El último era alguien pidiéndole ayuda para recuperar xhigh/heavy thinking.
El día que obtuvo las mejores puntuaciones, fue el día del lanzamiento
chatgptdisaster.com recopiló 1087 quejas verificadas de usuarios, donde un escenario mencionado repetidamente se llama «fallo de la capa de enrutamiento», la UI muestra GPT-5.5 Pro, pero la salida es de otro nivel completamente diferente.
Los usuarios describen un patrón reproducible: tras sesiones largas, el modelo empieza a «ignorar por completo lo que dices», pero el selector de modelos aún muestra la etiqueta de máxima gama.

La nota más absurda es que el mecanismo de cambio automático a mini después de que los usuarios Plus agotan las 160 mensajes/3 horas, en la documentación oficial de OpenAI es descrito como una «función».
¿Por qué pasa esto? Lisan al Gaib analiza que la respuesta está en dos palabras: ahorrar dinero.
La contracción del poder computacional y la rentabilidad está afectando a todos. Ahorrar por todos lados, sin dejar pasar ninguna oportunidad de recortar costes.
Sin embargo, la misma semana en que los usuarios de GPT-5.5 se quejaban colectivamente, la sombra de GPT-5.6 ya aparecía en los registros del backend de Codex.
Código interno iris-alpha, contexto de 1.5 millones de tokens, probabilidad de lanzamiento en junio según Polymarket supera el 85%.
Por un lado, los usuarios de 5.5 ni siquiera pueden mantener la experiencia básica; por otro, 5.6 ya está ejecutando tráfico real en el backend.
Así es la competencia ASI en 2026.
La velocidad para crear nuevos modelos es cada vez mayor, pero hacer que un modelo antiguo complete bien una sesión es cada vez más difícil.
El día que obtiene las mejores puntuaciones es siempre el día del lanzamiento, cada día después es un GPT de Schrödinger.

Referencias: https://x.com/scaling01/status/2058643470357590058?s=20
Este artículo proviene del WeChat Official Account "新智元", autor: ASI启示录; editor: Moisés





