Nota del editor: Anthropic ha lanzado Claude Opus 4.8, logrando el primer puesto en cinco de las seis pruebas de referencia clave, manteniendo el precio sin cambios; Claude Code incorpora flujos de trabajo dinámicos, y el próximo modelo de nivel Mythos ya entra en las expectativas del mercado.
En comparación con una mera mejora de rendimiento, lo más destacable de este lanzamiento es que Anthropic comienza a moldear la 'fiabilidad' como el argumento central de los modelos de vanguardia.
En las pruebas de honestidad de código, la tasa de falsos negativos de Opus 4.8 en sus propios errores disminuyó drásticamente; en Claude Code, puede coordinar múltiples sub-agentes e introducir una autoinspección adversaria antes de entregar los resultados. Estos cambios apuntan a un problema real: cuando la IA pasa de la ventana de chat a flujos de trabajo reales, lo que más preocupa a los usuarios a menudo no es que el modelo no pueda completar la tarea, sino que dé una respuesta aparentemente completa, fluida y coherente incluso cuando está equivocado.
Por lo tanto, el significado de Opus 4.8 va más allá de una simple actualización del modelo; también libera una señal clara de la industria: la competencia entre modelos de vanguardia está pasando de la simple persecución de benchmarks a la disputa por la confiabilidad, verificabilidad y capacidad de exposición de errores. Para empresas y usuarios profesionales, el umbral central de la IA en la próxima fase dependerá cada vez más de si el modelo merece ser delegado.
Esta es también la premisa para que los Agent se vuelvan realmente útiles. Los modelos necesitan completar más tareas, y también necesitan que la gente se atreva a confiarles tareas más importantes y complejas.
A continuación, el texto original:
Anthropic lanzó hoy Claude Opus 4.8. En las seis pruebas de referencia listadas en la tarjeta de lanzamiento, obtuvo el primer lugar en cinco de ellas.
El cambio clave que más me interesa es: en la prueba de honestidad de resumen de código de Anthropic, Opus 4.7 no marcó sus errores en el 19.7% de los casos; mientras que en Opus 4.8, esta proporción bajó al 3.7%. En la misma tarea, su capacidad para identificar errores en su propio trabajo mejoró aproximadamente cinco veces. Anthropic lo resume como '4 veces' en el anuncio. Independientemente de cómo se calcule, esto es clave para determinar si puedes confiarle un trabajo real a este modelo e irte tranquilo, y es más importante que cualquier puntuación de referencia en la tarjeta de lanzamiento.

Qué se ha lanzado realmente
Primero, la versión resumida, y luego entramos en cifras concretas:
La confiabilidad realmente ha mejorado. Además de los datos de honestidad de código mencionados anteriormente, Opus 4.8 es también el primer modelo Claude que obtiene un 'cero literal' en dos pruebas de diligencia: redujo la frecuencia de 'informar erróneamente resultados defectuosos' de 0.25 a 0.00, y la incidencia de 'investigación perezosa' del 25% al 0%. Las respuestas erróneas por exceso de confianza disminuyeron aproximadamente 11 veces. Su tendencia a favorecer su propio trabajo, un sesgo medible en la versión 4.7, ha desaparecido.
Claude Code incorpora flujos de trabajo dinámicos, actualmente en versión de vista previa de investigación. Claude ahora escribe sus propios scripts de orquestación, coordina de docenas a cientos de sub-agentes en paralelo en una sola sesión, y ejecuta agentes adversarios independientes para intentar refutar los resultados antes de presentártelos. Esta es la idea de 'equipo de Agent' planteada en Opus 4.6, ahora convertida en una capacidad automatizada.
Lidera en su propia tarjeta de lanzamiento, pero no de manera absoluta. Ganó cinco de seis. GPT-5.5 sigue liderando en tareas de operación de terminal. Además, en la tarjeta del sistema, hay algunos retrocesos en honestidad que Anthropic no incluyó en las diapositivas de presentación, que se detallarán más adelante.
El precio no ha cambiado. Sigue siendo 5 dólares por millón de tokens de entrada y 25 dólares por millón de tokens de salida, igual que la versión 4.7. Sin embargo, el modo rápido ahora es tres veces más barato que antes, aunque todavía pertenece a la categoría premium, con un precio de 10 dólares / 50 dólares.
Mythos está por llegar. Anthropic indica claramente que los modelos de nivel Mythos, de acceso restringido y capacidades extremadamente altas, llegarán en las próximas semanas. Opus 4.8 es la entrada pública hacia ellos.
Tarjeta de lanzamiento oficial: panorama de las pruebas de referencia
A continuación, la tarjeta de lanzamiento oficial, presentada con nuestra combinación de colores.
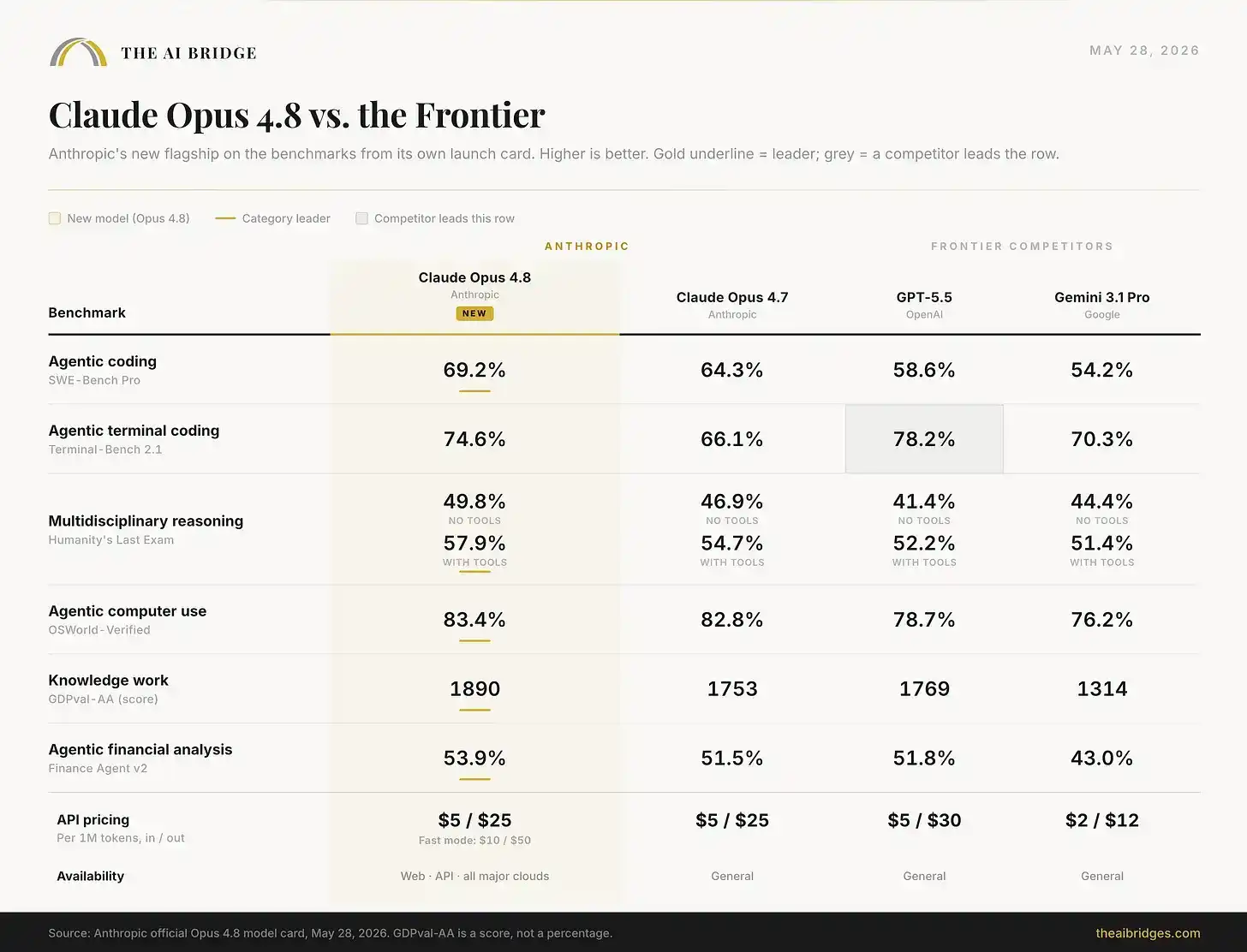
Hay un ítem que rompe el barrido total, y es importante. En Terminal-Bench 2.1, el benchmark que prueba la capacidad del modelo para completar tareas de Agent de largo alcance a través de terminal, GPT-5.5 todavía lidera con un 78.2% frente al 74.6% de Opus 4.8. Anthropic ha colocado esta desventaja en su propia tarjeta de lanzamiento, en lugar de ocultarla. La divergencia entre 'Agent y artesano' que mencionamos en el lanzamiento de GPT-5.5 aún no se ha cerrado por completo: GPT-5.5 sigue siendo un operador de terminal puro más fuerte, mientras que Opus 4.8 se parece más a un ingeniero más potente en la mayoría de los trabajos que realmente interesan a los usuarios profesionales, como la codificación en el mundo real, el razonamiento experto, el uso de computadoras y el trabajo de conocimiento.
Más allá de la tarjeta de lanzamiento
La tarjeta de lanzamiento solo muestra seis benchmarks. El informe de la tarjeta del sistema de 244 páginas reporta más de 40 pruebas, y algunos de los resultados más interesantes no están en las diapositivas. Los siguientes puntos son dignos de mención:
La capacidad matemática mejoró 27 puntos porcentuales. En USAMO 2026, la Olimpiada Matemática Estadounidense celebrada en marzo de este año, Opus 4.8 obtuvo un 96.7%, mientras que la versión 4.7 obtuvo un 69.3%. Dado que esta competencia ocurrió después de la fecha límite de entrenamiento de Opus 4.8, no hay problemas de contaminación de datos. Este es el mayor salto generacional en toda la tarjeta.
La ventaja se amplía en escenarios de contexto largo. En una prueba de razonamiento de gráficos de un millón de tokens, Opus 4.8 obtuvo 68.1 puntos, mientras que la versión 4.7 obtuvo 40.3 y GPT-5.5 obtuvo 45.4. Cuanto más largo sea el contexto y más difícil la tarea, más amplia será su ventaja.
Los multi-Agent son donde realmente alcanza la cima. Un solo Agent Opus 4.8 se queda atrás de Gemini en tareas de investigación web, con 84.3 y 85.9 respectivamente. Pero si un orquestador coordina un grupo de sub-agentes, su puntuación puede alcanzar el 88.5%, convirtiéndose en el resultado más alto reportado; un equipo de cinco Agent también puede lograr el mejor rendimiento de un solo Agent en una quinta parte del tiempo. Esta es precisamente la manifestación de la funcionalidad de flujos de trabajo dinámicos en las pruebas de referencia.
La eficiencia de tokens experimenta un cambio cualitativo. En las pruebas de codificación más difíciles, Opus 4.8, con la configuración de menor esfuerzo, puede lograr el rendimiento máximo de Opus 4.7 con su configuración de mayor esfuerzo. Es decir, puedes obtener el rendimiento máximo anterior con un costo de tokens menor.
Cruzó un umbral que ningún modelo había cruzado antes. En el Legal Agent Benchmark de Harvey, una tarea solo se considera exitosa cuando se aprueban todos y cada uno de los criterios de evaluación. Opus 4.8 es el primer modelo en clasificarse primero bajo este estándar de 'aprobación total'. Aprobó el 89% de los criterios individuales, pero la tasa de éxito de la tarea completa fue solo del 9.6%, lo que también muestra cuán estrictos son los requisitos del trabajo legal real.
También hay retrocesos presentados honestamente. Hay tres cosas que son realmente peores que la versión 4.7, y Anthropic lo admite en la tarjeta del sistema. GPQA Diamond, la prueba científica experta, cayó de 94.2 a 93.6. La capacidad para rechazar respuestas en escenarios de uso de computadoras y la resistencia a la inyección de instrucciones han retrocedido, por lo que la versión 4.8 es más fácil de manipular en escenarios de Agent. Además, en una prueba comercial simulada de un año, terminó con solo un tercio del efectivo que tenía la versión 4.7. Estos no aparecieron en la tarjeta de lanzamiento, y por eso mismo, merecen ser señalados.
En comparación con los modelos de pesos de código abierto, ¿en qué posición se encuentra?
La tarjeta de lanzamiento solo compara a Opus 4.8 con otros modelos de vanguardia de código cerrado. Si ampliamos la visión a los baratos modelos de pesos de código abierto que muchos equipos están probando ahora, el panorama es casi una instantánea de la industria de la IA en 2026: Opus 4.8 lidera en capacidad, pero la brecha con los modelos gratuitos y auto-alojables se ha reducido a solo unos pocos puntos porcentuales, mientras que la diferencia de precio es enorme.
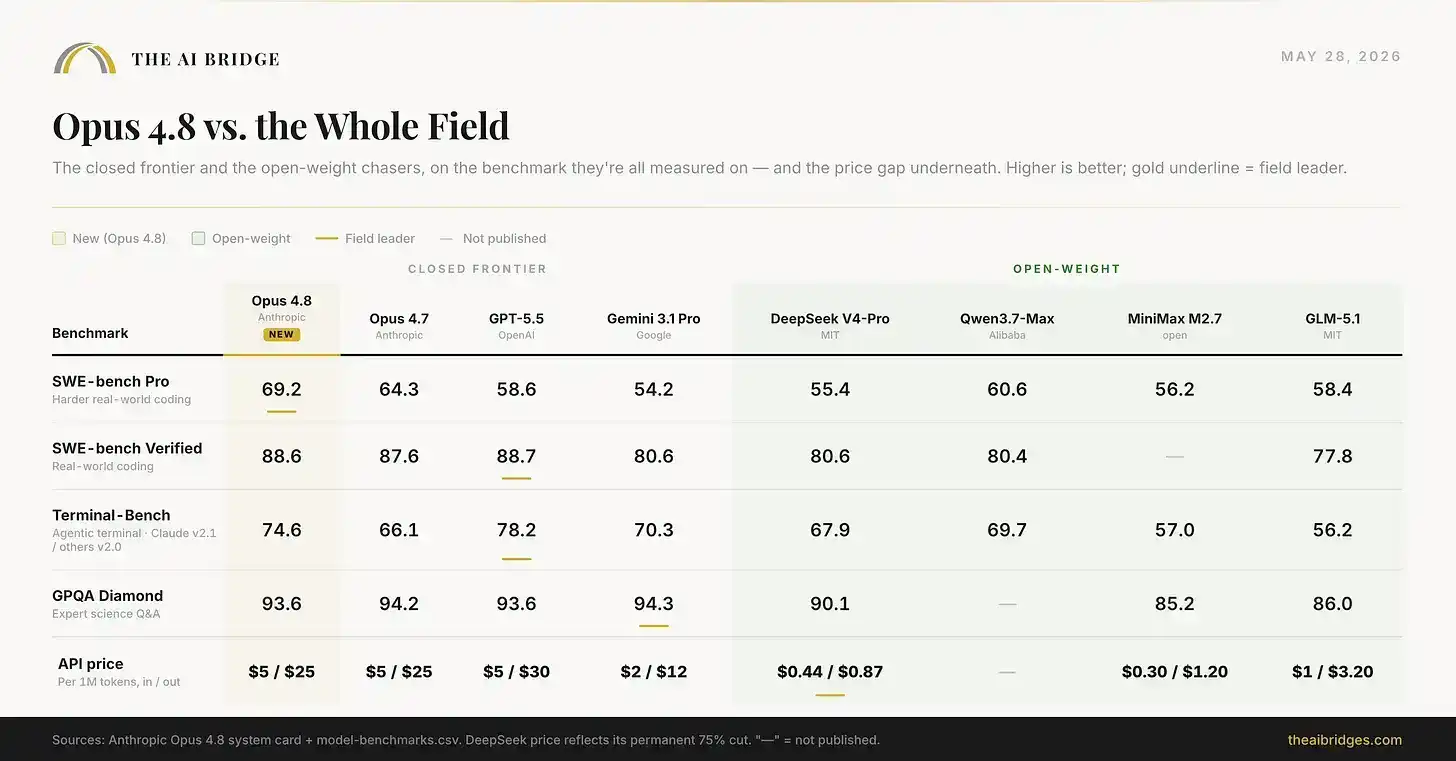
El gráfico anterior incluye una comparación completa de ocho modelos. El precio de DeepSeek refleja su reducción permanente del 75%; el precio de Qwen Max aún no se ha anunciado.
Opus 4.8 gana directamente en los benchmarks de codificación. Pero Qwen3.7-Max, un modelo de código abierto que puedes ejecutar tú mismo, obtiene 60.6 puntos, solo unos 9 puntos menos. DeepSeek V4-Pro obtiene 55.4 puntos, y su precio de salida es aproximadamente una trigésima parte del de Opus. Para las tareas de ingeniería de mayor riesgo, la diferencia de 25 dólares por millón de tokens de salida vale la pena. Para una gran cantidad de trabajo diario, esta diferencia cada vez vale menos la pena. Y esta es precisamente la cuenta que cada equipo serio está haciendo ahora.
Qué significa esto para ti
Si estás usando Opus 4.7, esta es una actualización gratuita. El precio es el mismo, los datos son mejores, y el juicio sobre sus propias salidas es notablemente más confiable. Solo cambia a ella.
La pregunta más interesante es: ¿qué trabajos estás dispuesto a confiarle ahora? Cada lector tiene una línea en su mente que separa 'las tareas que puedo dejar que la IA haga' de 'las tareas que debo hacer personalmente, porque aún no puedo confiar en la delegación'. La mejora en confiabilidad de la versión 4.8 significa que puedes empujar esa línea un paso hacia adelante. El modelo es mejor para señalar su propia incertidumbre, lo que reduce el costo del 'error silencioso en la delegación' y amplía el rango de tareas que vale la pena delegar al modelo. Este es el significado práctico de los datos de honestidad, es más importante que cualquier puntuación individual.
Esto también resuena con lo que escribimos la semana pasada. El propio estudio AI Fluency de Anthropic descubrió que cuando la salida del modelo parece pulida y completa, las personas son significativamente menos propensas a notar la falta de contexto. La respuesta parece terminada, así que dejamos de revisar. Opus 4.8 ataca este modo de fallo desde el lado del modelo: es mejor para decirte dónde pueden estar los puntos débiles en una respuesta que parece limpia y completa. No puede reemplazar tu criterio, pero puede proporcionarle asideros a tu criterio.
Si usas Claude Code, esta semana puedes probar un flujo de trabajo dinámico con una tarea realmente grande, como una migración, o una revisión exhaustiva de muchos archivos, prestando atención al medidor de tokens. Esta capacidad es real, y la autoinspección adversaria también es clave para hacer que la salida sea más confiable. Pero el costo también es real. Esta es una herramienta preparada para aquellas grandes tareas que un solo Agent difícilmente puede completar, y no debería ser tu opción predeterminada diaria.
A continuación: Mythos, llegando en unas semanas
La declaración más prospectiva en este lanzamiento en realidad no trata sobre la versión 4.8. Anthropic indica que los modelos de nivel Mythos llegarán en las próximas semanas, y posiciona a Opus 4.8 como el paso público hacia ellos.
Necesitas entender lo que esto significa. Mythos es el modelo de vanguardia restringido en el que Anthropic ha estado realizando pruebas de referencia internamente, superando a Opus 4.8 publicado en casi todos los indicadores: en SWE-bench Verified alcanza el 93.9%; en pruebas de ciberseguridad, puede generar exploits ejecutables para la mayoría de los objetivos en los navegadores actuales, mientras que la tasa de éxito de Opus 4.8 es inferior al 10%. Anteriormente, estaba abierto solo a unas 52 instituciones auditadas, con un precio cinco veces mayor que el Opus estándar, siendo tratado como infraestructura, no como un producto común.
Por lo tanto, cuando un modelo de nivel Mythos más potente llegue en las próximas semanas, debe entenderse bajo el marco de 'dos tipos de mercado': uno es la capa de comercialización, es decir, Opus 4.8, ampliamente abierta, precio sin cambios, cada vez más perseguida por modelos de código abierto gratuitos; el otro es la capa de vanguardia controlada, es decir, Mythos, costosa, de acceso restringido. Estos dos no son productos separados, sino diferentes niveles en la misma línea continua de capacidad. El trabajo de confiabilidad en la versión 4.8 es precisamente lo que debes construir antes de que tu verdadero objetivo sea 'hacer que el modelo se ejecute con menos supervisión'. Y ese objetivo ahora no está a varios trimestres de distancia, sino a unas semanas.
Contexto: Cómo llegamos aquí
Si has perdido el ritmo de los últimos cuatro meses, puedes entenderlo así: Opus 4.6 trajo equipos de Agent en febrero, Sonnet 4.6 trajo el colapso de precios, Opus 4.7 trajo un salto en el razonamiento en abril, y Mythos es el techo restringido apenas visible al lado. Opus 4.8 conecta dos de estas líneas: continúa la narrativa de orquestación de la versión 4.6, y también es la entrada a Mythos.
Este ritmo de lanzamiento en sí mismo es el hecho clave escondido debajo de todos los cambios superficiales. Los modelos insignia han pasado de la versión 4.5, 4.6, 4.7 a la 4.8 en unos meses, y el modelo que adoptas hoy para estandarizar en tu equipo puede que ya no sea el modelo que realmente ejecutes en otoño. Esta es también la razón por la cual, en lugar de invertir en habilidades de uso para un modelo concreto, es más importante invertir en aquellas capacidades que puedan migrar entre modelos, como la delegación clara y la verificación estricta.
Los barridos de benchmarks obtendrán capturas de pantalla que se difundirán. Pero donde realmente ocurren los cambios es más pequeño y más importante: esta es la primera versión de Claude cuyo argumento central ya no es solo 'es más inteligente', sino 'puedes confiarle más cosas'. Antes de que los Agent se vuelvan realmente útiles, toda la industria debe avanzar en esta dirección; y esta parte de la capacidad también es la más difícil de poner en un gráfico.
¿Dónde está tu línea ahora? ¿Qué trabajos estás dispuesto a delegar al modelo, y cuáles aún debes hacer tú mismo? ¿Y qué tendría que pasar para que estés dispuesto a empujar esa línea un paso más?