¿'Consumir' una unidad de estado sólido de 1TB en un año?
Codex, la herramienta de programación insignia de OpenAI, está desgastando tu unidad de estado sólido con una escritura de 640 TB al año.

Hace un tiempo, un desarrollador abrió un issue en GitHub. Este issue, ahora marcado como 'Closed' y con el número #28224, lleva el título:
Los registros de feedback de SQLite de Codex pueden escribir 640TB al año, agotando rápidamente la vida útil de las SSD.
Según las mediciones del informante, su SSD principal perdió 37 TB de escritura tras 21 días de funcionamiento continuo. Extrapolando, eso supone unos 640 TB al año, suficientes para acabar con una unidad de consumo con una resistencia total a escritura (TBW) de 600 TB.
Como evidencia, adjuntó dos tablas.
En la evidencia 1, esta base de datos de registros siempre ocupa solo 1.2 GB, aparentemente sin cambios; pero su ID de fila autoincremental ya ha superado los 5.5 mil millones, mientras que las filas realmente retenidas son apenas poco más de 500,000, una diferencia de diez mil veces.
La clave está en que el desgaste del disco se mide por la cantidad total escrita, independientemente de lo que quede ahora: esas 5.5 mil millones de filas se escribieron todas en el disco, y borrarlas no devuelve el desgaste ya incurrido. Así que al revisar el archivo solo ves esas 500,000 filas, pero el disco ya ha soportado la escritura de 5.5 mil millones.
La evidencia 2 revela la distribución de estas 5.5 mil millones de filas: más del 90% es ruido de depuración que ni los propios desarrolladores revisarían. Solo el hecho de copiar cada paquete completo de datos WebSocket supone la mitad.
El culpable es una configuración predeterminada de Level::TRACE, que trata la vida útil de escritura de tu disco como papel de borrador gratuito.
Un comentario muy votado en Hacker News definió la situación:
Este es uno de los ejemplos más notorios de 'software defectuoso' (slopware).

Este usuario también añadió con frustración:
Es realmente trágico. El mundo necesita competencia para Anthropic.
Lo más embarazoso es que el problema no era desconocido.
Desde abril de este año hubo reportes esporádicos, que se arrastraron durante más de dos meses, hasta que los usuarios hicieron sus propios cálculos, escribieron informes y lo llevaron a los titulares de Hacker News para que fuera tomado en serio. Incluso así, esta ronda solo eliminó aproximadamente el 85% de la escritura de registros.
Algunos intentaron solucionarlo por su cuenta, pero descubrieron que no podían: las versiones de escritorio de estas herramientas son de código cerrado.
Otro comentario ingenioso: ¿cómo es que el proceso de revisión no detectó un error tan obvio? Ah, cierto... @codex, revisa esto.
640TB, ¿cómo se llega a esa cifra?
¿Qué representa 640TB?
Las SSD de consumo convencionales tienen una vida útil de escritura (TBW) típica de 150 a 600 TB, suficiente para décadas de uso normal.
Y la función de registro de Codex, que simplemente 'anota lo que hace', puede alcanzar esa cifra en un año.
Todo comenzó cuando este usuario revisó su disco. Su máquina, encendida continuamente durante 21 días, había escrito 37 TB en su SSD principal.
A ese ritmo, unos 640 TB al año.
Pero lo más absurdo es el método de escritura.
Codex mantiene localmente una base de datos SQLite, logs_2.sqlite, específicamente para registros de feedback. Este usuario la monitoreó durante 15 segundos: se insertaron 36,211 filas, pero el número total de filas retenidas se mantuvo en 681,774 desde el principio hasta el final, sin aumentar.
Por cada fila insertada, otra era eliminada. El conteo de filas constante, pero el disco era reescrito decenas de miles de veces.
A este mecanismo se le conoce como 'insertar y podar' (insert-and-prune).
Y lo más ridículo es lo que registra: una serie de eventos inotify del sistema de archivos.
ld.so.cache fue registrado 128,764 veces, locale.alias 37,982 veces, passwd 23,843 veces.
El mismo archivo, por el mismo programa, registrado cientos de miles de veces.
El ID autoincremental en los registros supera los 5.5 mil millones, mientras que las filas realmente conservadas son solo unas 500,000.
Una diferencia de diez mil veces.
Esto no es un bug, parece que una herramienta de programación con IA está recitando un mantra a su propio disco duro.
El archivo pesa 1GB, pero la escritura es de 640TB
¿Qué tamaño tiene logs_2.sqlite, escribiendo y borrando constantemente? Aproximadamente 1 GB.
Esto lleva al punto más contraintuitivo de todo el asunto: la vida útil de una SSD se mide por la 'cantidad de escritura', no por el 'tamaño del archivo'. Un archivo de 1 GB reescrito 640 veces equivale a 640 TB de escritura para el disco.
SQLite utiliza el mecanismo WAL (Write-Ahead Logging): cada cambio se escribe primero en el archivo -wal, y luego se consolida (checkpoint) en la base principal. Codex realiza decenas de miles de inserciones y eliminaciones cada 15 segundos, cada una pasando por WAL, actualización de índices y checkpoint. La misma área de almacenamiento, sobrescrita una y otra vez.
Una analogía: un cuaderno de 1 GB donde cada día borras y reescribes 1,750 veces, durante un año. El cuaderno es el mismo, pero el papel está gastado.
Esta es también la razón por la que este bug pudo permanecer oculto tanto tiempo: no ocupa espacio, solo quema vida útil.
Revisar el espacio disponible en disco no muestra anomalías, el tamaño del archivo se mantiene estable. Solo al consultar los contadores de salud SMART del disco se puede ver la acumulación silenciosa de escritura.
La causa raíz: una línea RUST_LOG ignorada
¿Por qué se registra tanto?
La respuesta está en una línea de configuración del código fuente de Codex: el 'sink' (receptor) del registro de feedback SQLite se inicializa con Targets::new().with_default(Level::TRACE).
En resumen, el registro está configurado por defecto en el nivel TRACE, el más alto, verboso y que registra todo.
El framework de registro de Codex es 'tracing' del ecosistema Rust, cuya práctica estándar es leer la variable de entorno RUST_LOG. Los usuarios lo intentaron, ajustando RUST_LOG a info, warn, incluso desactivándolo.
Inútil.
with_default(Level::TRACE) fija rígidamente el nivel predeterminado global en TRACE. RUST_LOG no tiene efecto en esta ruta. Crees que has desactivado el registro, pero sigue escribiendo.
Lo más engañoso de este tipo de bug no es que 'olvidaras configurarlo', sino que 'lo configuraste, y lo ignoró'.
Otro dato revelador es una proporción.
Separando los registros retenidos por categoría, TRACE representa el 70.7%, unos 732.5 MB. Sumando los dos flujos de telemetría espejada codex_otel (log_only y trace_safe), se añade otro 25.3%.
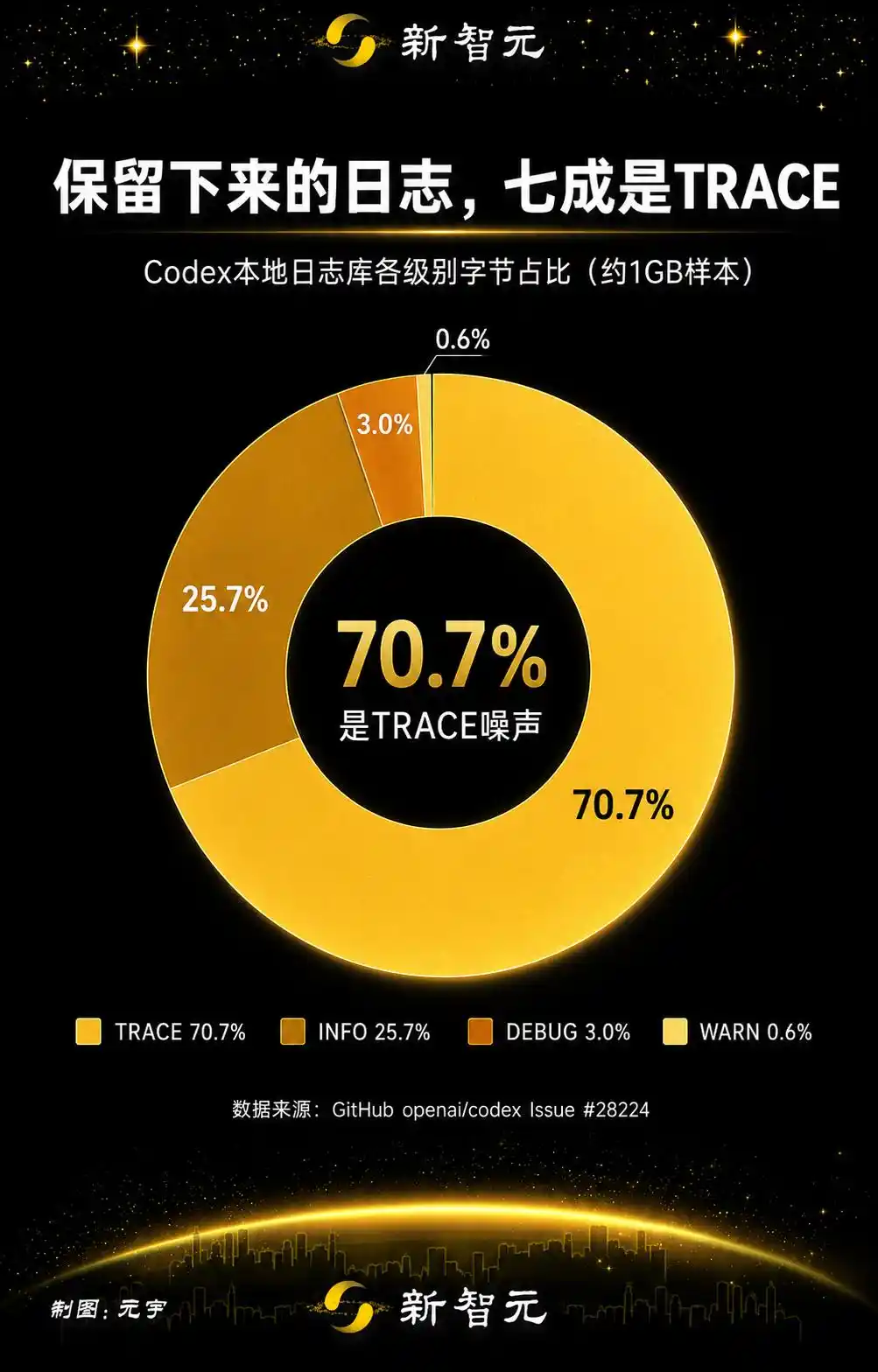
El 70% de la escritura es ruido TRACE. Sumando la telemetría espejada, el 96% son detalles irrelevantes que nadie revisaría.
Solo el 4% es contenido realmente significativo.
No es el primero, al menos es el noveno
El informante revisó el repositorio de Codex y descubrió que hay al menos 9 issues sobre 'crecimiento ilimitado de registros'.
#17320, escritura frenética de WAL durante respuestas en flujo, misma causa raíz que esta vez: TRACE ignorando RUST_LOG.
#24275, logs_2.sqlite en la versión de escritorio crece descontroladamente.
#22444, WAL crece infinitamente y no libera espacio.
#26374, escribe 0.75 GB al día, sin rotación.
#27911, una base de datos goals_1.sqlite de 4 KB, escrita a 11 MB/s.
#20563, el proceso escribe frenéticamente en disco incluso inactivo.
#27020, actividad de disco al 100% en Windows.
El origen más temprano se remonta a #12969, el PR que introdujo el 'sink' del registro de feedback SQLite configurado en nivel TRACE.
Una base de datos de 4 KB escrita a 11 MB por segundo merecería un artículo por sí sola. Y es un síntoma del mismo producto, del mismo sistema de telemetría que el de los 640 TB.
Esto indica que el sistema de registro y telemetría de Codex, desde el principio, carecía del concepto de 'presupuesto de recursos'.
Toda la industria compite por presupuesto de tokens, longitud de contexto, capacidad del modelo.
Pero casi nadie pregunta: ¿quién controla el presupuesto de disco, memoria, CPU de un Agente que se ejecuta 7x24 en la máquina del usuario?
Se corrigió, pero de manera muy 'OpenAI'
Reportado en GitHub el 14 de junio. El 23 de junio, el informante actualizó: tres PRs fusionados. Según sus propias pruebas en Codex, reducen aproximadamente el 85% del registro, por lo que cerró el issue.
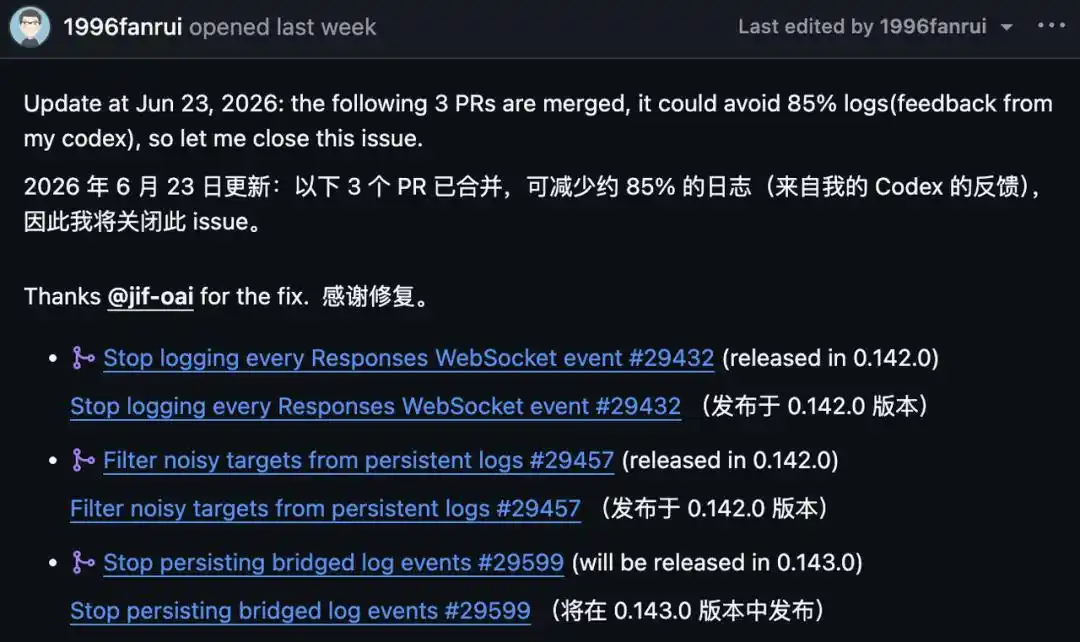
Primero, ese 85%: no es el 100%, y aún no está completamente implementado.
De las tres correcciones, #29432 y #29457 se lanzaron con la versión 0.142.0, eliminando los registros WebSocket línea por línea y objetivos de ruido; la tercera, #29599, desactiva otro tipo de registros redundantes introducidos por puente, y llegará con la versión 0.143.0.
Incluso con las tres implementadas, el 15% restante aún supondría escribir unos 96 TB al año, pasando de 'agotar el disco en un año' a 'agotarlo en seis años'.
Algunos defienden la postura: los registros TRACE se almacenan por diseño para depuración, no es un bug, y son útiles para que OpenAI investigue casos límite.
Pero el problema reside precisamente ahí: usar la vida útil de las SSD de usuarios que pagan, como almacenamiento gratuito para la depuración del fabricante. ¿Los usuarios dieron su consentimiento para eso?
El campo de batalla de la programación: lo que se agota no es solo la SSD
Curiosamente, no solo Codex recibió críticas.
En los comentarios rápidamente añadieron: Claude Code también escribe registros de depuración intensivamente en local, obligando a algunos a enlazar el directorio de registros a un disco en RAM (tmpfs) para salvar sus SSD.
Dos herramientas líderes, la misma clase de problema.
Los comentarios de la comunidad pronto pasaron de un bug específico a cuestionar la calidad general de las herramientas de programación con IA.
Algunos se quejan de que estos agentes mantienen la GPU al máximo, consumen 70 GB de memoria, otros acuñaron un nombre para esta generación de software: software defectuoso (slopware).
La sugerencia original del desarrollador era simple: establecer un límite para la aplicación, que no supere los 3 GB. Solo esa línea, Codex tardó 9 Issues y varios meses en trazarla.
La pregunta es: ¿por qué una empresa que siempre habla de 'AGI' tropieza con un problema que un ingeniero en prácticas podría detectar?
¿Por qué pudo permanecer oculto tanto tiempo? Un comentario dio en el clavo.
Hace una década, con el registro en TRACE, el programa se colgaría al instante y se corregiría el mismo día. Hoy, las CPUs son rápidas, la memoria es grande, los discos son potentes. Este defecto es absorbido silenciosamente por el rendimiento del hardware. El programa funciona, la interfaz responde, el usuario no nota nada, hasta que un día la SSD falla prematuramente.
En los últimos años, el software se llena de código generado por IA, las funciones se acumulan, las capas de abstracción se apilan, el consumo de recursos se dispara, sostenido solo por hardware más rápido cada año.
Así surge un ciclo absurdo: el software se escribe peor, el hardware se fabrica más potente. Los usuarios, con la ilusión de que 'no va más lento', pagan por máquinas nuevas, que apenas sostienen software peor.
Un pequeño bug no derribará a OpenAI. Pero la competencia entre Codex y Claude Code ya se extiende desde la capacidad del modelo hasta la entrada del flujo de trabajo del desarrollador.
En este frente, cambiar rápidamente y responder a las necesidades de los desarrolladores no es un punto a favor, es el precio de entrada.
Referencias:
https://github.com/openai/codex/issues/28224
https://news.ycombinator.com/item?id=48626930
Este artículo proviene del WeChat público '新智元' (Nueva Era de la Inteligencia), autor: ASI启示录






