Hace unos días, Adam Brown, contribuidor principal de Gemini y líder del equipo Blueshift, pronunció una extensa conferencia titulada "Entrenando arena para pensar: Inteligencia General Artificial y el futuro de la Física" en el Perimeter Institute for Theoretical Physics, que atrajo una gran atención. En ella, relató cómo ha visto personalmente a la IA evolucionar desde un "nivel preescolar" hasta un nivel de doctorado, y proyectó: si esta tendencia continúa, ¿en qué se convertirá la física?
Título de la conferencia: Training Sand to Think: Artificial General Intelligence & Future of Physics
Enlace de la conferencia: https://www.youtube.com/watch?v=Mw60FH5iflI&t=3s
Esta charla también fue muy recomendada por Geoffrey Hinton, ganador del Premio Nobel de Física y del Premio Turing, quien la calificó como "asombrosamente buena (amazingly good)".
Antes de presentar esta asombrosa conferencia, es necesario presentar al orador, Adam Brown.

El currículum de Brown es un ejemplo de cómo un físico teórico puede ver su destino transformado por la IA. Estudió un grado conjunto de Física y Filosofía en la Universidad de Oxford, luego obtuvo su doctorado en la Universidad de Columbia, y posteriormente fue profesor en los departamentos de física de Princeton y Stanford. En Stanford, enseñó la teoría general de la relatividad de Einstein, investigando temas que van desde el Big Bang, la inflación cósmica, los multiversos, los agujeros negros y la computación cuántica, hasta conceptos que suenan a ciencia ficción como el "ascensor espacial" y las "burbujas de la nada (bubbles of nothing)", así como el destino último del universo, mientras mantenía un interés a largo plazo en las conexiones profundas entre física y ciencias de la computación.
En 2018, Brown se unió a Google. Hoy lidera un equipo dentro de DeepMind llamado Blueshift, enfocado en mejorar las capacidades científicas y de razonamiento de la IA, y es uno de los contribuidores principales del modelo de lenguaje grande Gemini.
Al inicio de su charla, mencionó que en su carrera había escrito alrededor de cuarenta artículos de física teórica, pero que en los últimos años había dejado de escribir artículos a mano, no por incapacidad, sino porque sentía que escribir artículo tras artículo a mano era más bien un "placer culpable", ya que lo que realmente debía hacer era participar en la construcción de una máquina capaz de producir conocimiento a "escala industrial".
Este prólogo establece el tono de toda la charla: alguien en el centro de la tormenta tecnológica de "IA + ciencia", tratando de describir a sus colegas la forma real de esa tormenta.
Nosotros también, con la ayuda de la IA, hemos resumido esta brillante charla de Brown.
De granos de arena a máquinas pensantes
Brown resume en una frase la posición especial en la que se encuentra la civilización humana en este momento: Hemos aprendido a purificar arena en silicio, convertir silicio en chips, ensamblar chips en redes neuronales, y ahora hemos aprendido a entrenar esas redes neuronales para pensar.
Enfatiza especialmente que esta vez es diferente de cualquier "herramienta de cálculo" anterior. Desde el ábaco hasta la calculadora de bolsillo, los humanos siempre han tenido herramientas que ayudan en la investigación científica, pero eran herramientas puntuales, que solo podían completar un paso del proceso, dejando el resto al humano.
Los modelos de lenguaje grande (LLM, por sus siglas en inglés) son diferentes; tienen el potencial de completar todo el flujo de trabajo de un físico teórico, que es precisamente lo que significa el término "inteligencia general" (general intelligence). Brown cree que es muy probable que los LLM sean el sustrato subyacente que los humanos usan para construir inteligencia artificial general.
Recuerda a la audiencia que muchos pueden haber usado chatbots como ChatGPT, Gemini o Claude, sin darse cuenta de un hecho silencioso: estos sistemas pasaron discretamente la prueba de Turing hace años, y casi nadie lo celebró específicamente.
Las redes neuronales se "cultivan", no se "programan"
Para entender por qué los modelos grandes son completamente diferentes de los programas informáticos tradicionales, Brown ofrece una metáfora central: Los LLM no son programados (programmed), son cultivados (grown), es decir, se parecen más a ser criados que a ser escritos.
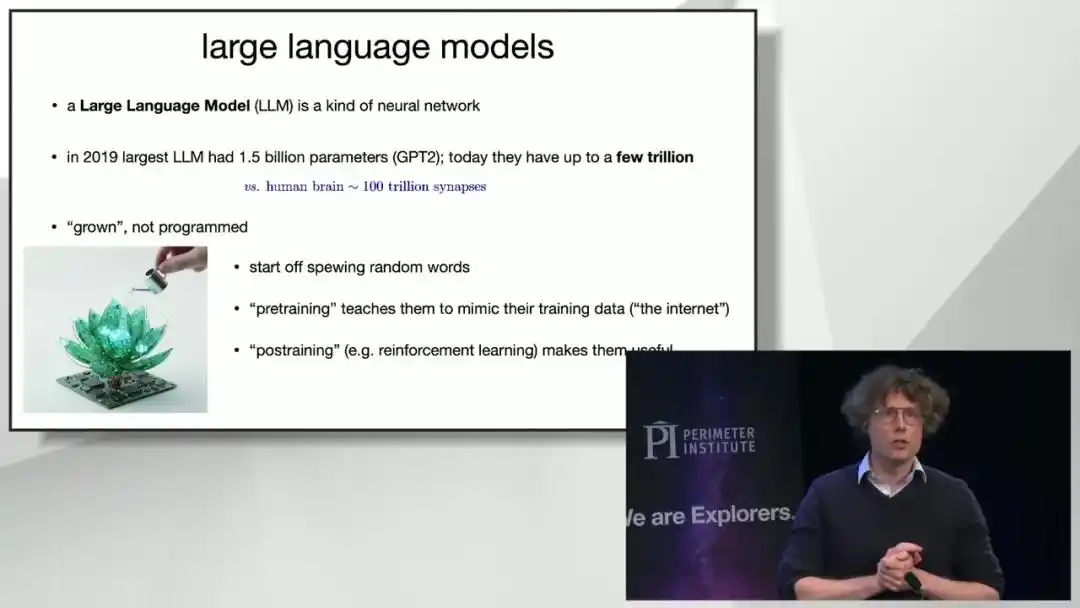
El proceso concreto se divide en dos etapas.
La primera etapa se llama "preentrenamiento". Los ingenieros parten de un conjunto de neuronas artificiales conectadas aleatoriamente, casi balbuceantes, y las hacen intentar predecir cuál será la "siguiente palabra" en un texto. Si acierta, refuerza la vía neuronal correspondiente; si se equivoca, la debilita. Este proceso es extremadamente largo: después de ver un millón de palabras, el modelo básicamente sigue diciendo tonterías; después de leer decenas o cientos de millones de palabras, ya puede escribir oraciones gramaticalmente correctas aunque un poco torpes; hasta que no lee todo Internet (decenas de billones de palabras) puede mantener conversaciones fluidas y coherentes sobre casi cualquier tema.
La segunda etapa se llama "post-entrenamiento", que Brown describe como "enviar el modelo a una escuela de etiqueta". Un modelo recién preentrenado solo predice mecánicamente la siguiente palabra, es grosero y desobediente; la tarea del post-entrenamiento es enseñarle a ser cortés, a querer cooperar con el usuario, y no solo a jugar a continuar un texto. Hoy, el número de parámetros de los principales modelos grandes ha pasado de miles de millones hace una década a billones, aunque todavía está muy lejos de la escala de aproximadamente cien billones de sinapsis del cerebro humano, esta escala ya es suficiente para que ocurran milagros.
Físicos que no atienden a su oficio: la Ley de Escalado (Scaling Law) encendió esta revolución
Brown menciona especialmente que los físicos jugaron un papel inesperado al inicio de esta revolución de la IA: aportaron la mentalidad de la "Ley de Escalado (Scaling Law)".
Los físicos están obsesionados por naturaleza con encontrar relaciones de ley de potencia simples: duplicar la altura de Alicia cuadruplica su superficie y octuplica su peso, este es el análisis dimensional más simple; la relación de ley de potencia entre la tasa metabólica y el peso corporal de los animales descubierta por Kleiber hace casi cien años es un ejemplo más sutil - los físicos no explicaron el principio detrás de ella con la dimensión fractal del sistema vascular hasta muchos años después.
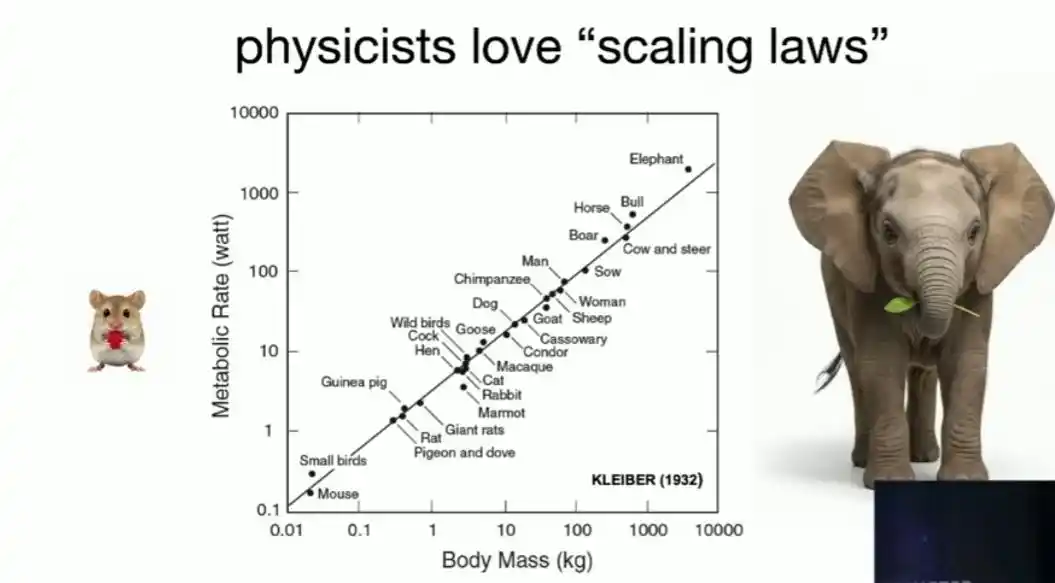
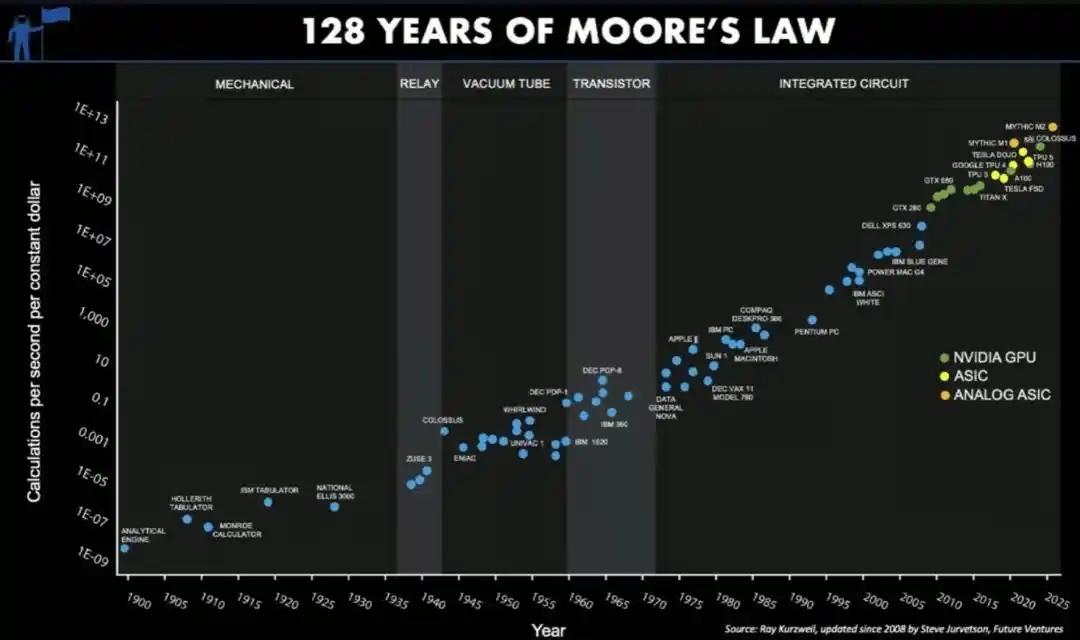
Por no hablar de la famosa Ley de Moore:
En 2020, varios investigadores con formación en física trasladaron esta mentalidad a las redes neuronales y descubrieron que simplemente ampliando proporcionalmente la potencia de cálculo utilizada para el entrenamiento, el volumen de datos y la escala del modelo, el rendimiento del modelo en la tarea de "predecir la siguiente palabra" mejoraría constantemente a lo largo de una línea recta en un sistema de coordenadas logarítmico-logarítmico.
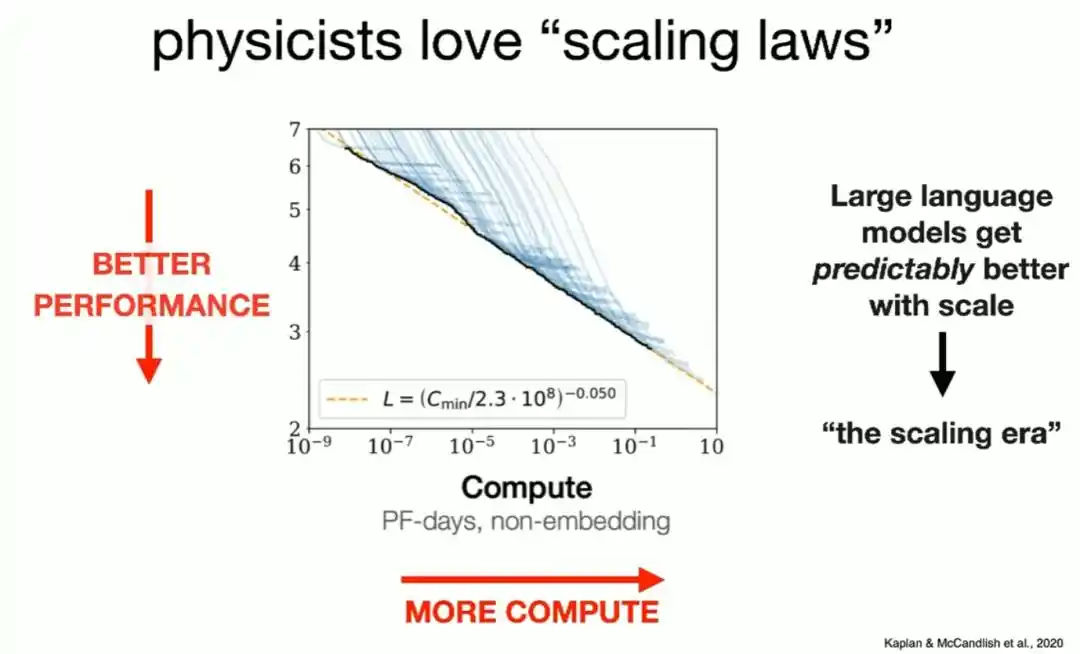
Esta curva luego se extendió ocho órdenes de magnitud completos, y aún se mantiene.
Brown bromea diciendo que este gráfico es "tan simple que incluso los inversores de capital riesgo pueden entenderlo", y puede decirle directamente al mercado de capitales: invierte dinero (es decir, potencia de cálculo) y obtendrás modelos más fuertes.
Esta simple curva es precisamente el punto de partida de la era del Escalado (Scaling) en los últimos seis años.
Pero Brown también señala que acumular potencia de cálculo es solo una parte de la historia. En la última década, la potencia de cálculo consumida por el entrenamiento de IA de vanguardia ha crecido aproximadamente cuatro veces al año, y la inversión en entrenamiento ha crecido aproximadamente 2.7 veces al año.
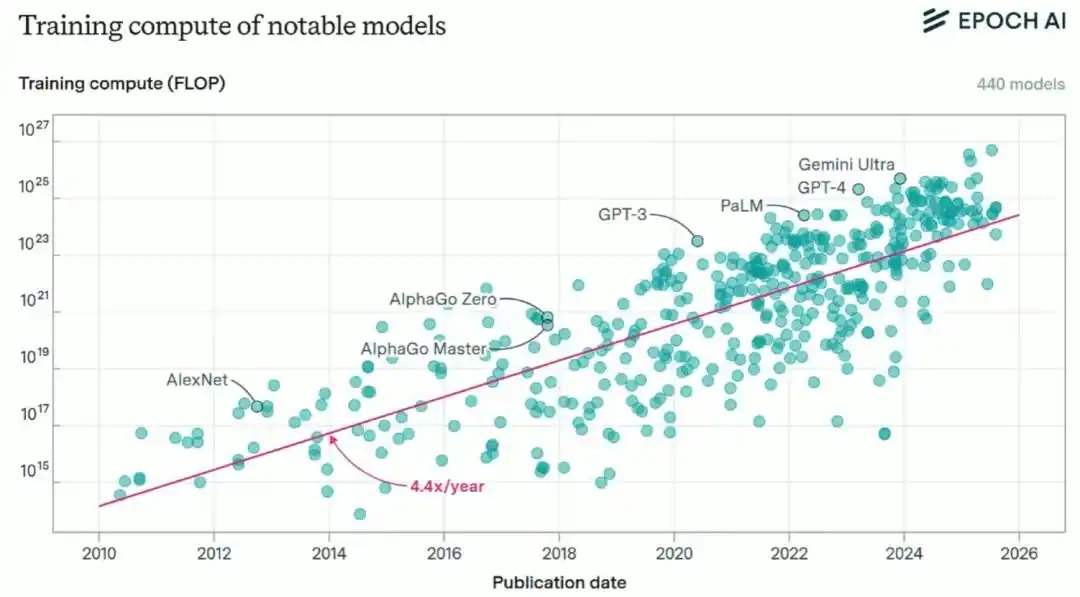
Actualmente, la potencia de cálculo necesaria para un entrenamiento de primer nivel cuesta alrededor de cientos de millones de dólares, mientras que el PIB anual de EE.UU. ronda los 30 billones de dólares, lo que significa que esta curva todavía tiene un espacio de crecimiento muy largo.
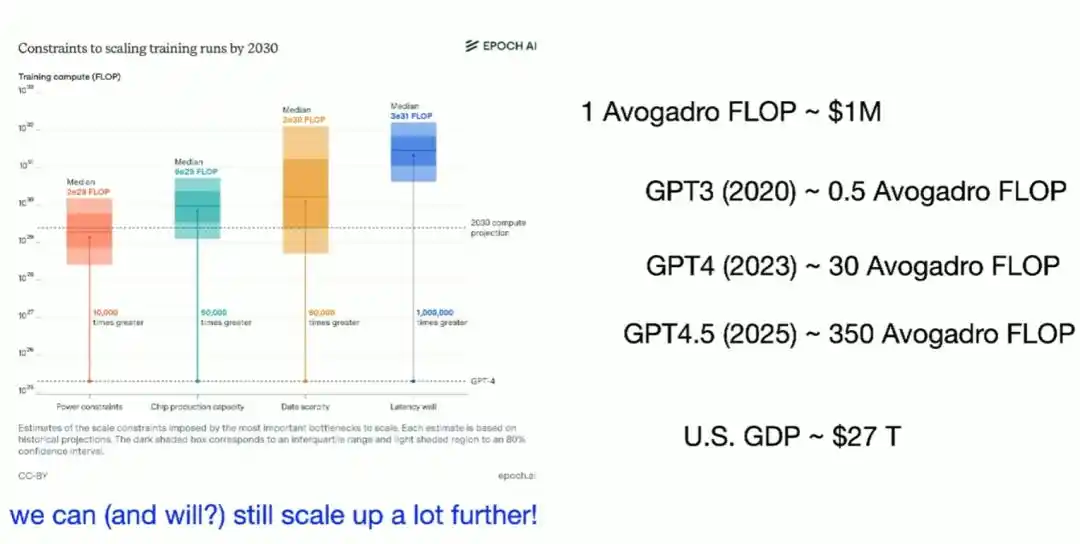
Pero más importante que acumular potencia de cálculo es el constante refinamiento algorítmico por parte de los humanos: Los investigadores continúan encontrando enlaces ineficientes en el flujo de entrenamiento y los mejoran; este es el verdadero "primer motor" detrás del progreso de la IA en la última década.
La "corta vida" de las pruebas de referencia: de preescolar a doctorado
Si la Ley de Escalado explica "por qué la IA se vuelve más fuerte", entonces el auge y caída de una serie de pruebas de referencia registra "cuánto más fuerte se ha vuelto la IA". Brown usa un conjunto de resultados de pruebas para trazar una curva deslumbrante.
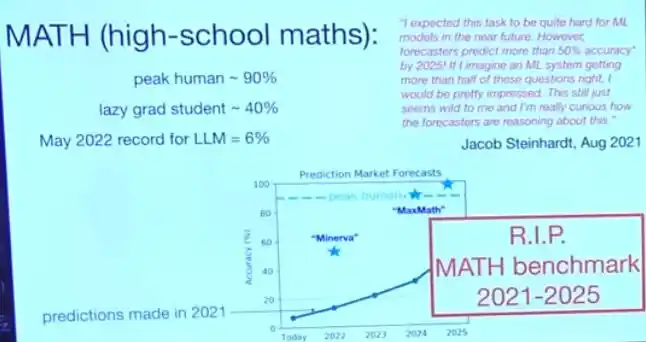
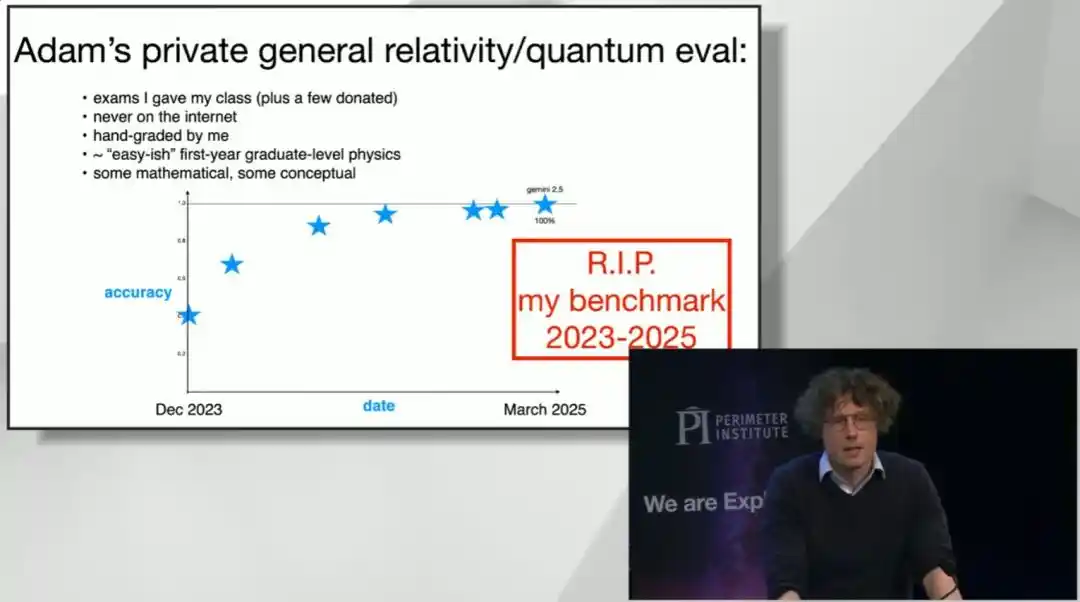
Hace cuatro años, apareció una prueba de referencia de matemáticas de secundaria llamada MATH. Los investigadores hicieron que un doctorando en informática no muy hábil en matemáticas la tomara, obteniendo alrededor del 40%; luego hicieron que un triple medallista de oro de la Olimpiada Internacional de Matemáticas la tomara, obteniendo el 90%. En ese momento, el modelo grande más avanzado solo obtenía un 6%, casi indistinguible de adivinar al azar, porque el modelo ni siquiera podía entender la pregunta.
El mercado de predicciones de ese año consideraba que para 2025, lograr que un modelo alcanzara el 50% ya era "un optimismo arrogante"; el propio creador de la prueba de referencia declaró públicamente que si algún modelo realmente lograba eso, estaría "bastante sorprendido".
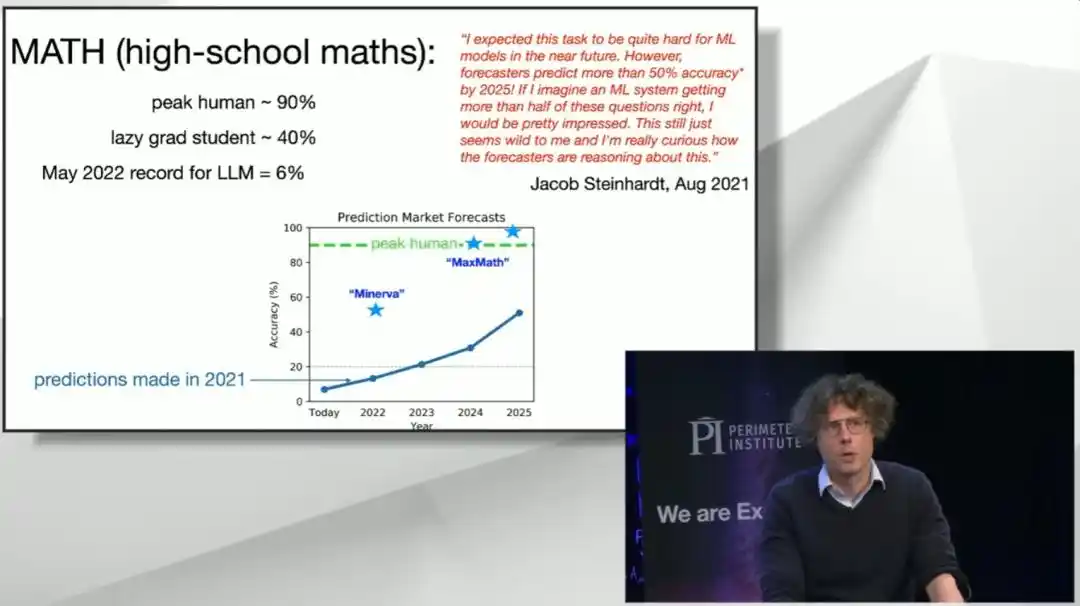
Resultó que ese 50% fue superado "inmediatamente" por un sistema llamado Minerva. A mediados de 2024, el sistema del equipo de Brown obtuvo una puntuación del 90% en esta prueba. Incluso organizaron una fiesta de patinaje sobre ruedas estilo años 90 para celebrarlo. Sin embargo, solo seis meses después, los modelos grandes disponibles en el mercado resolvieron estas preguntas casi a la perfección. La prueba de referencia MATH "murió", y pasó directamente de ser "demasiado difícil" a "demasiado fácil", casi sin paradas intermedias.
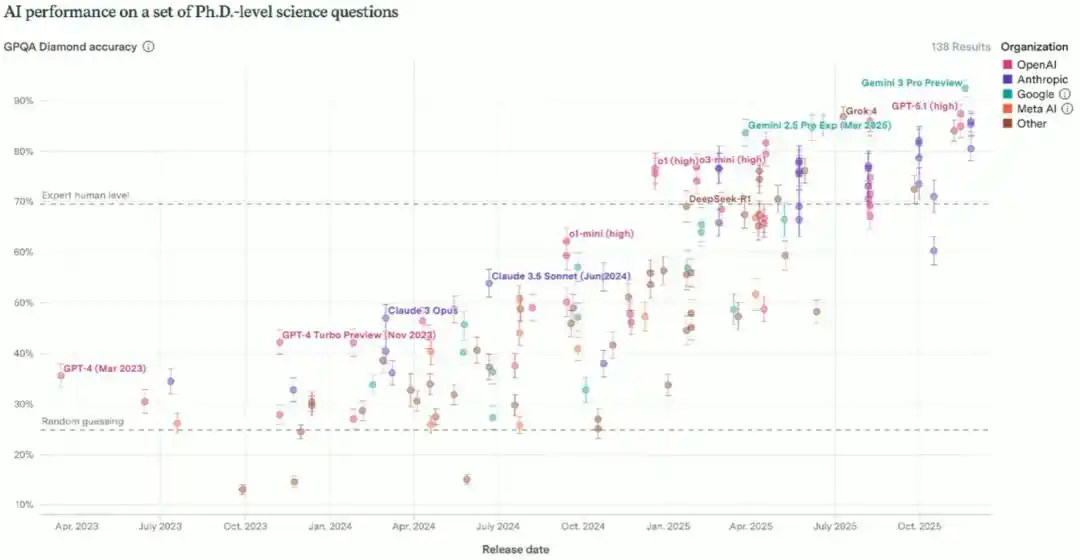
La siguiente en caer fue la prueba GPQA dirigida a estudiantes de posgrado, que simula la dificultad de los exámenes de calificación del primer año de doctorado, con una puntuación promedio de expertos humanos de alrededor del 70%. El modelo partió de cerca de adivinar al azar y entre 2024 y 2025 superó el nivel de experto, obteniendo hoy casi la puntuación perfecta. Para descartar la posibilidad de que "el modelo simplemente memorizara las respuestas", el equipo de Brown diseñó preguntas nuevas de la misma distribución que no aparecían en Internet, y el rendimiento del modelo apenas disminuyó.
Brown incluso sacó sus propios exámenes finales de posgrado de relatividad general y mecánica cuántica que calificó personalmente en Stanford (estas preguntas nunca estuvieron en línea) y, en un año y medio, el modelo también obtuvo la puntuación perfecta. Bromeó diciendo que incluso sus propias preguntas de examen habían "caído en desgracia".
La lista de pruebas de referencia que cayeron después fue cada vez más larga, incluyendo una prueba integral de súper dificultad que una vez fue llamada "El último examen de la humanidad" (Humanity's Last Exam).
Y el salto más simbólico ocurrió en la Olimpiada Internacional de Matemáticas.
Cruzando el umbral de la Olimpiada de Matemáticas
Hace poco más de un año, un ganador del Premio Turing le dijo personalmente a Brown que los modelos grandes nunca podrían resolver problemas del nivel de la Olimpiada Internacional de Matemáticas (IMO), porque eso requiere creatividad real, no solo memorización. Los problemas de la IMO son conocidos como "los problemas más difíciles dentro del alcance de las matemáticas de secundaria": los adolescentes más inteligentes del mundo entrenan uno o dos años para competir, y ganar una medalla de oro en seis problemas ya es raro.
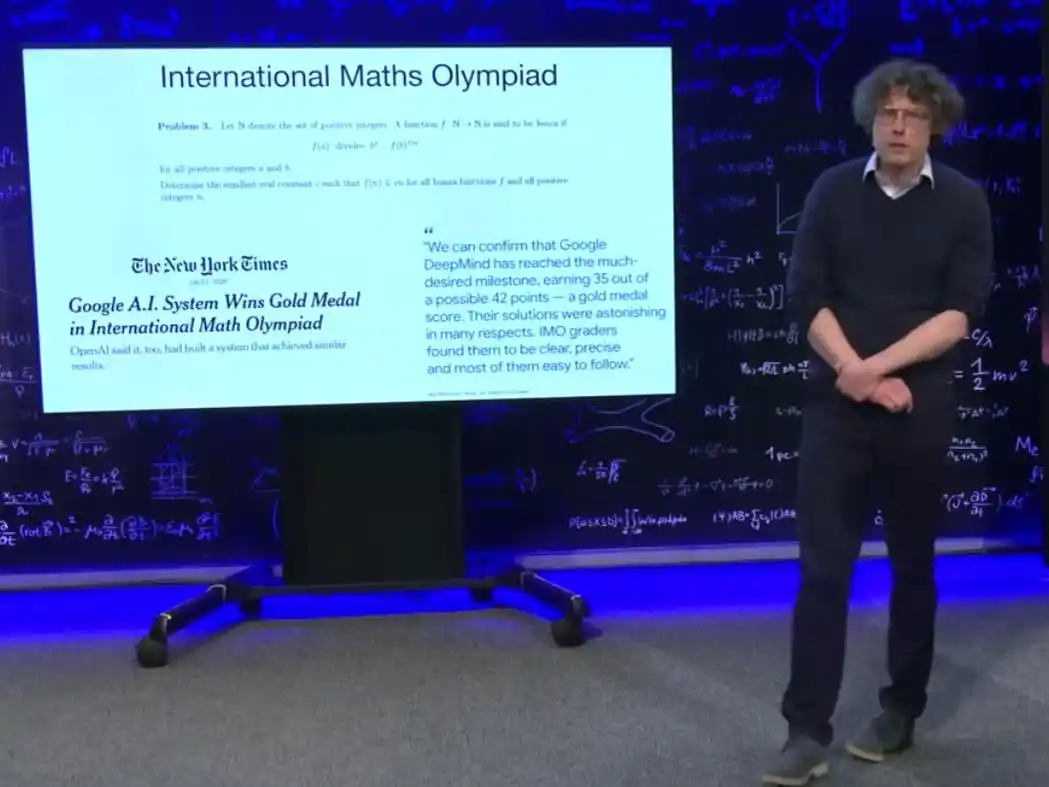
El verano pasado, se cruzó este umbral. El sistema del equipo de Brown acertó cinco de seis problemas en una prueba de nivel IMO, alcanzando el nivel de medalla de oro. Y este sistema no pasó simplemente por fuerza bruta con una larga cadena de pruebas formalizadas incomprensibles. El presidente de la IMO dijo en una evaluación pública que estas soluciones eran "sorprendentes en muchos aspectos", y los evaluadores las consideraron claras, precisas, en su mayoría fáciles de entender y que utilizaban abstracciones matemáticas similares a las humanas.
Brown también mostró francamente los "fracasos" de los modelos grandes.
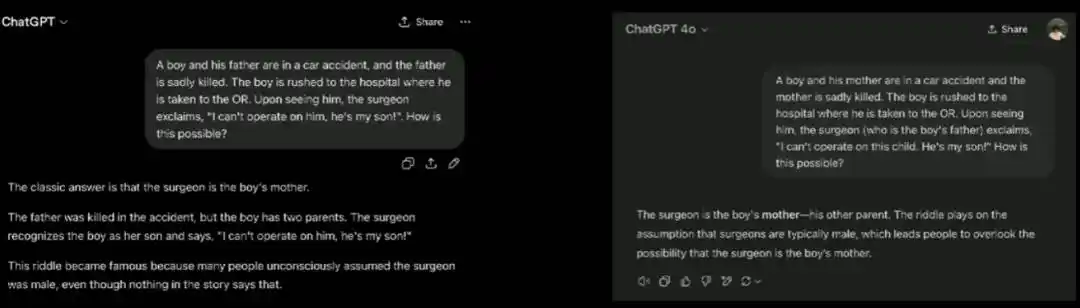
Un clásico acertijo es: un padre y un hijo sufren un accidente, el padre muere, el hijo es llevado a quirófano, el cirujano jefe ve al niño y dice "No puedo operarlo, es mi hijo", pregunta qué está pasando (la respuesta estándar es que el cirujano es la madre del niño). Esta pregunta prueba si el lector asume por defecto que el cirujano es hombre. Los modelos grandes responden a esta "pregunta viral" con soltura, porque la han visto miles de veces en los datos de entrenamiento. Pero cuando Brown invierte la pregunta: la madre muere, el cirujano se especifica especialmente como "el padre del niño", y luego hace la misma pregunta, el modelo no se da cuenta en absoluto de que la pregunta se ha invertido, y aplica mecánicamente la respuesta estándar de "el cirujano es el otro padre".
Brown dice que esto expone una "idiosincrasia" particular dejada por el método de entrenamiento del modelo.
Colaboración centauro: La IA escribe pruebas con las que los matemáticos están dispuestos a firmar
Diez meses después de cruzar el umbral de la IMO, el equipo de Brown completó un trabajo que él considera de mayor significado: investigación matemática real, cuyas respuestas nadie conocía antes.
En septiembre del año pasado, el equipo de Brown colaboró con varios matemáticos profesionales, adoptando un modo de colaboración que él llama "estilo centauro" (Centaur) —el centauro es una criatura mitad humano mitad caballo de la mitología griega, y aquí, "la mitad no humana" es el LLM.

Todo el proceso fue un diálogo continuo: el modelo proponía posibles líneas de demostración, los expertos humanos juzgaban cuáles tenían valor y guiaban al modelo para profundizar, finalmente completando un artículo matemático completo bajo la guía humana. Uno de los coautores del artículo es profesor de Stanford y actual presidente de la American Mathematical Society. La evaluación de este profesor fue que los argumentos propuestos por Gemini no eran en absoluto un simple reempaquetado de demostraciones existentes, sino una perspicacia de la que él mismo se sentiría orgulloso.
Brown enfatiza que en ese momento (finales del año pasado) esto ya era el nivel más alto que los modelos grandes podían alcanzar en matemáticas. Pero luego añade: todavía está muy lejos del verdadero valor del "nivel más alto".
El verdadero punto de inflexión: La IA resuelve por sí sola una conjetura de ochenta años
Al entrar en 2026, la situación cambió bruscamente —o mejor dicho, mejoró bruscamente. Brown comienza con una frase casi provocadora: "Hasta la semana pasada, los LLM no habían logrado un avance matemático realmente importante". Ahora, esta frase ya no es cierta.

Mucha gente ya ha oído hablar de este gran evento. La "conjetura de la distancia unidad" planteada por Erdős en 1946, durante ochenta años fue ampliamente considerada por la comunidad matemática como que la configuración de cuadrícula cuadrada era la solución óptima conocida. Un modelo grande interno de OpenAI encontró independientemente un contraejemplo, utilizando herramientas de la teoría de números algebraicos para construir una serie de conjuntos de puntos cuyo número de pares a distancia unidad superaba el límite superior previamente aceptado. Esto equivale a refutar esta conjetura largamente aceptada como verdadera.

Vale la pena mencionar que este problema no era oscuro; mucha gente lo había intentado antes, pero los matemáticos dedicaron grandes esfuerzos y siempre se mantuvieron en la dirección de "probar" en lugar de "refutar". Brown menciona especialmente que el ganador de la Medalla Fields, Timothy Gowers, participó en la verificación de este resultado y dio una alta evaluación.
Brown juzga que este es el primer avance verdaderamente importante de los modelos grandes en matemáticas, y cree que no será el último —"la compuerta está abierta", a medida que la fuerza de los modelos continúe superando el "umbral necesario para generar avances", predice que aparecerán más logros similares.
Bromea diciendo que, mirando hacia atrás, la razón por la que este problema fue resuelto primero probablemente es porque su estructura de enunciado cae precisamente en la "zona de confort" de los modelos grandes; a continuación, los modelos resolverán primero los problemas difíciles "amigables para la IA", y luego abordarán gradualmente los problemas "menos amigables".
La profecía del ajedrez
Para convencer a la audiencia de que esta curva continuará subiendo, Brown muestra un gráfico que a primera vista parece dibujado a mano alzada: una línea recta que continúa subiendo. Por supuesto, este gráfico no lo inventó él, sino que está tomado directamente de datos reales de la fuerza de las computadoras de ajedrez a lo largo del tiempo, donde el eje vertical es la puntuación Elo que mide la fuerza y el eje horizontal es el año.
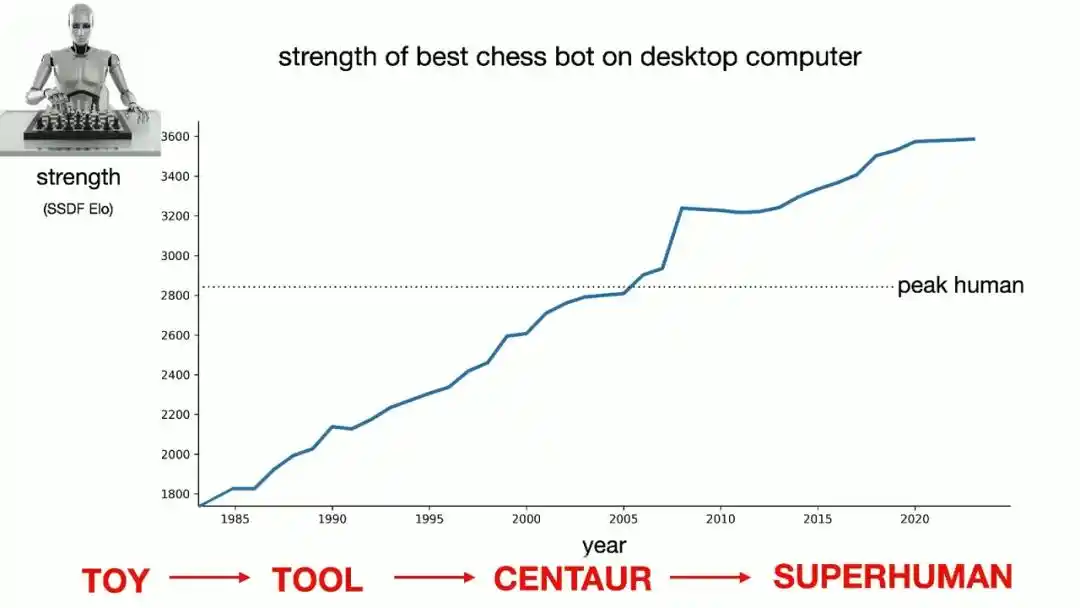
Brown desglosa cuatro etapas en la historia de la IA en ajedrez:
Inicialmente fue la "era del juguete", donde lograr que una computadora hiciera un movimiento razonable ya era un milagro;
Luego vino la "era de la herramienta", donde las computadoras solo eran útiles en enlaces específicos como el cálculo de finales o la memorización de aperturas;
Después vino la "era centauro", donde la combinación más fuerte del universo era la colaboración entre un maestro y la capacidad de búsqueda profunda de una computadora;
Y ahora, los humanos han entrado completamente en la "era superhumana": cuando los mejores jugadores colaboran con una computadora, la estrategia óptima es simplemente dejar que la computadora juegue sola.
Brown cree que estas cuatro etapas pueden corresponderse casi una a una en el campo de la investigación científica.
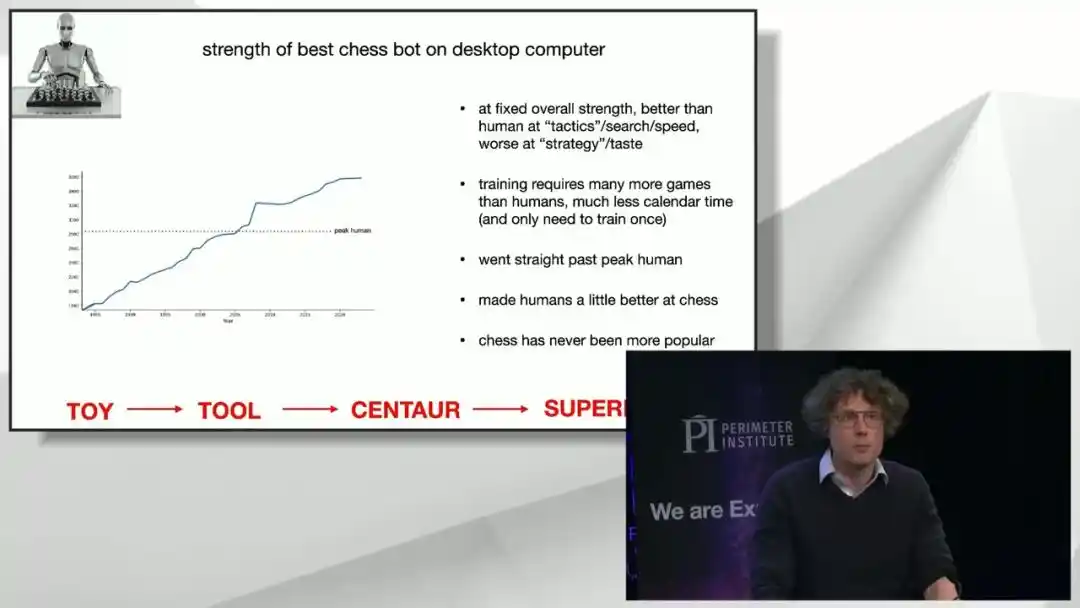
La primera regla es: con la misma fuerza integral, las computadoras superan a los humanos en táctica y velocidad de búsqueda, pero siguen siendo más débiles en juicio estratégico y "gusto". Esta es precisamente la característica que los modelos grandes actuales muestran en la investigación matemática y física: son buenos aplicando lemas y técnicas existentes, pero no tan buenos juzgando "hacia dónde debe ir la dirección general", aunque esta debilidad se está reduciendo rápidamente.
La segunda regla es: el número de partidas que la IA necesita "experimentar" para entrenarse en ajedrez es mucho mayor que el número total de partidas que un humano puede jugar en su vida, pero como la máquina puede jugar contra sí misma incansablemente a alta velocidad, el "tiempo calendario" real requerido es mucho más corto que entrenar a un jugador humano.
La tercera regla es: una vez que la fuerza de la computadora supera el nivel máximo humano, nunca se detiene, después de todo, no hay ninguna razón física o lógica para que se detenga justo cerca del nivel humano.
El cuarto hecho reconfortante es: el auge de la IA en ajedrez en realidad elevó el nivel general de los jugadores humanos; los jugadores humanos más fuertes de hoy son más fuertes que en cualquier época histórica, en parte gracias a aprender de IA súper fuertes; y el ajedrez en sí nunca ha sido tan popular como hoy.
La insinuación de Brown es clara: si la investigación científica repite esta trayectoria, es probable que los humanos primero reciban "científicos de IA" completamente autónomos, luego algún tipo de "Einstein de IA"... Lo que sucederá después, admite, está más allá de lo que puede predecir.
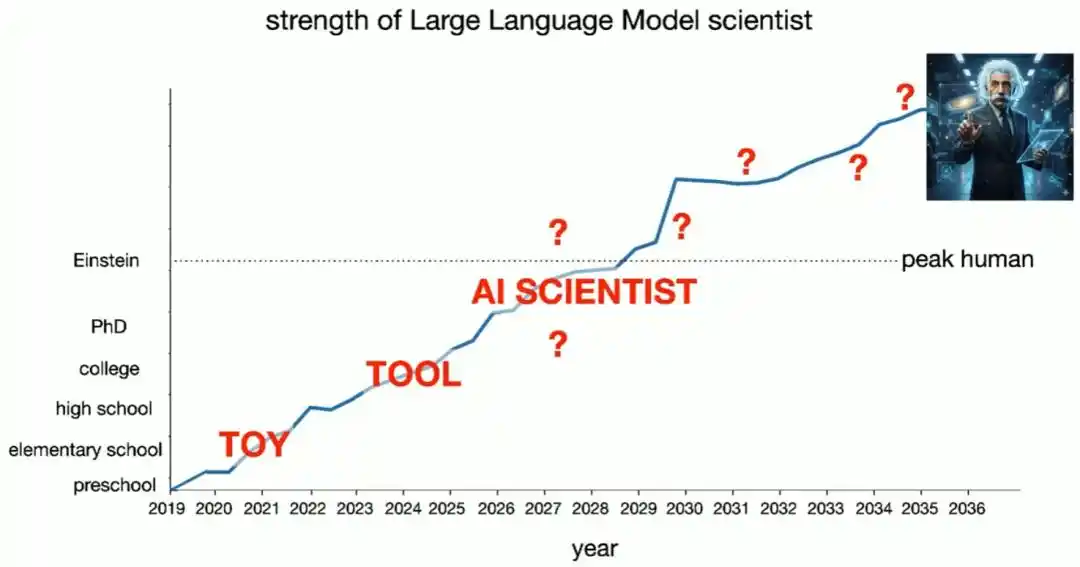
Incluso si el progreso se detuviera aquí, la física ya ha sido remodelada
Brown también plantea una "hipótesis pesimista" que merece atención: ¿qué pasaría si las capacidades de los modelos grandes se estancaran completamente a partir de hoy?

Dice francamente que el uso que realmente "no funciona" actualmente es pedirle directamente al modelo "Por favor, invéntame una nueva teoría de gravedad cuántica", la respuesta probablemente sea un "disparate de IA" sin valor y aburrido.
En términos más generales, los modelos grandes actuales todavía tienen cuatro debilidades evidentes: baja autonomía, lenta velocidad de aprendizaje, pobre capacidad de planificación y débil capacidad de corrección de errores.

Brown admite que estas cuatro debilidades han mejorado significativamente en el último año, pero ninguna se ha resuelto por completo, y por eso un sistema que puede obtener puntuaciones perfectas en los exámenes de posgrado de cada disciplina, aún no ha producido resultados que puedan llamarse "avances importantes".
Al preparar esta charla, incluso dibujó específicamente esto como una "curva plana" con un signo de interrogación, admitiendo burlonamente que este es quizás el único gráfico en toda la charla que "no sube constantemente". Pero añade que, antes de que termine 2026, probablemente empezarán a debatir cómo definir exactamente la palabra "avance importante". La realidad demostró que este día llegó más rápido de lo que él mismo esperaba.
Sin embargo, incluso si el progreso realmente se detuviera en este momento, Brown cree que los modelos grandes ya son suficientes para cambiar completamente la apariencia de la investigación en física.
Enumera varios usos ya maduros y que siguen mejorando:
Como un "tutor personal sin juicios", puede responder en cualquier momento a las 3 a.m. a las lagunas de conocimiento que incluso los físicos no pueden aclarar, sin tener que despertar a un experto de clase mundial;
Como asistente de programación, ahora es tan fuerte que "llamarlo asistente de programación parece casi un insulto", muchos problemas físicos que antes se consideraban "no problemas de programación" ahora pueden reformularse como problemas de código para resolver;
Como herramienta de búsqueda bibliográfica, puede leer toda la base de artículos de un campo y decirte directamente si una idea ya ha sido explorada; además, puede actuar como compañero de lluvia de ideas.
Brown resume que la ventaja central de los modelos grandes es que: son rápidos, cubren un amplio espectro, son incansables y se pueden replicar infinitamente. Formar a un físico lleva décadas, pero una vez que se entrena un modelo fuerte, se pueden ejecutar miles de copias simultáneamente —esto ya es suficiente para "cambiar completamente" esta disciplina.
Conclusión: La edad de oro de la física
Al final de su charla, Brown da su juicio sobre "por qué el progreso no se detendrá".
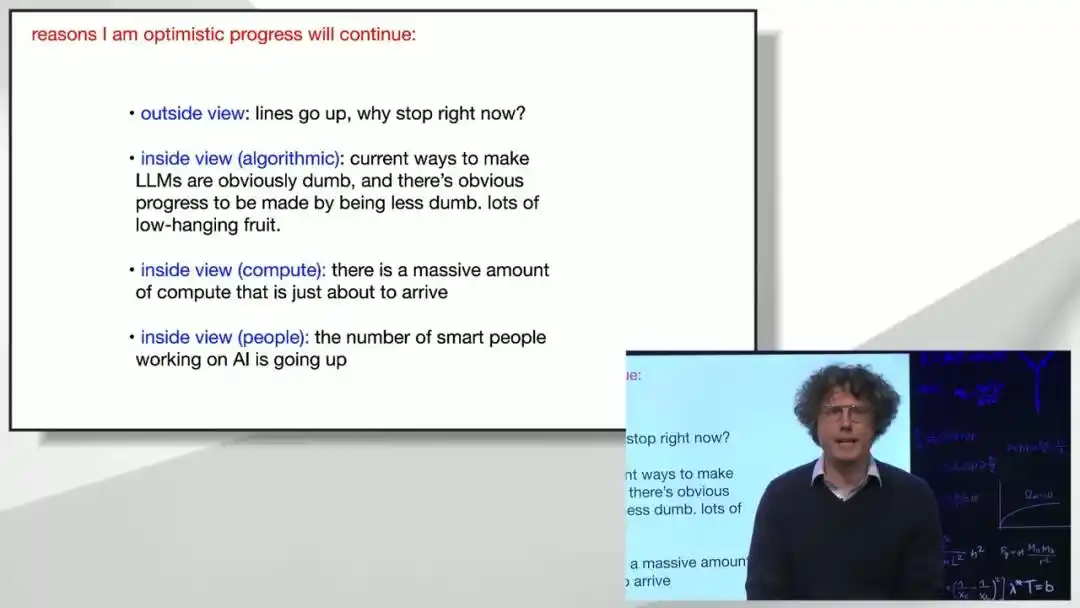
Desde una perspectiva macroeconómica, la inversión actual en entrenamiento todavía representa una proporción muy pequeña del PIB mundial, dejando un espacio de crecimiento amplio; internamente, desde una perspectiva técnica, el método actual para entrenar modelos grandes está "lejos de ser tan sofisticado como parece". Muchas ideas de mejora obvias, pero aún no probadas seriamente, están esperando ser exploradas. Sumado al constante flujo de talento y potencia de cálculo hacia este campo, Brown juzga que la arquitectura de modelo y la escala de potencia de cálculo actuales ya son suficientes para llegar a la inteligencia artificial general, incluso sin nuevos avances teóricos.
También responde a una visión pesimista que ha circulado durante mucho tiempo, que los modelos grandes solo hacen "coincidencia de patrones" y no pueden generar ideas realmente nuevas.

La opinión de Brown es que, si elevamos el nivel de abstracción lo suficiente, casi todas las creaciones humanas que parecen "avances importantes" son esencialmente también algún tipo de coincidencia de patrones en una dimensión superior. Una frase recurrente en este campo es: "Estos modelos quieren aprender", por muchas razones teóricas aparentemente razonables que sugieran que no deberían aprender bien, su rendimiento siempre supera las expectativas.
La conclusión de Brown es que en los próximos años, entraremos en una edad de oro "centauro" de colaboración entre humanos y IA: estas herramientas serán entregadas a físicos humanos, matemáticos y expertos de varios campos, para juntos iniciar un nuevo Renacimiento en ciencia y matemáticas.
Después, si realmente se logra "crear un Einstein de IA", como replicar un modelo entrenado cuesta casi nada extra, es probable que la humanidad pronto tenga miles de millones de "Einstein de IA superhumanos" funcionando simultáneamente. Esto suena a ciencia ficción, pero está sucediendo.
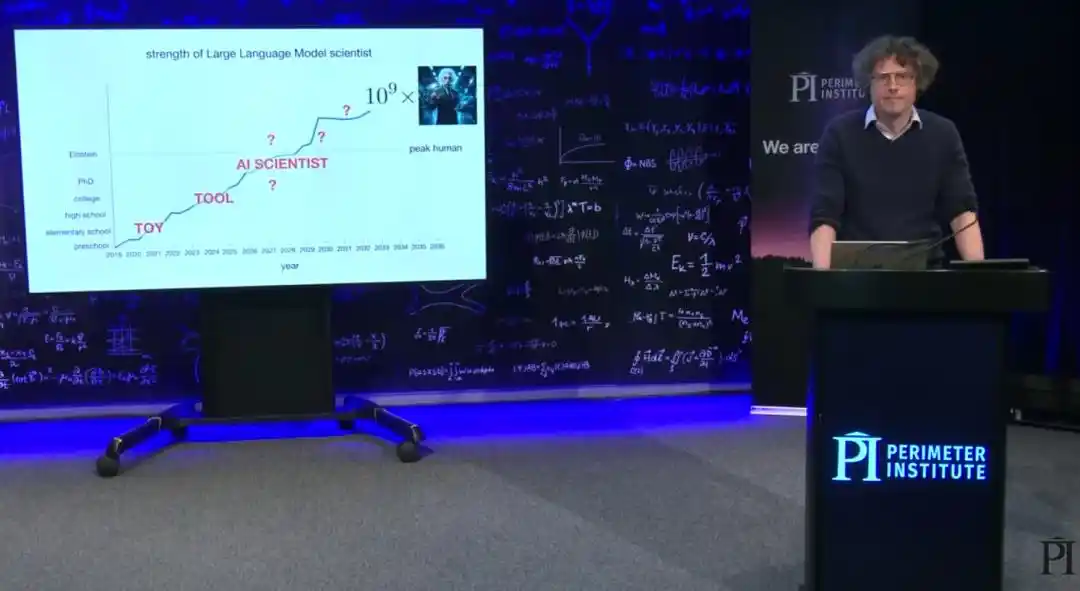
Brown dice que, a largo plazo, hacia dónde llevará la IA a la física es tan difícil de predecir para él como para todos. Incluso cree que la mejora continua de las capacidades de la IA está haciendo que el futuro del mundo entero sea más difícil de predecir. Pero hay algo de lo que está seguro: los próximos años serán los más emocionantes de la historia de la física. Aquellas preguntas que lo han obsesionado durante toda su carrera, espera que sean respondidas en un futuro no muy lejano.
Este artículo proviene del WeChat público "机器之心" (ID:almosthuman2014), autor: 关注AI的