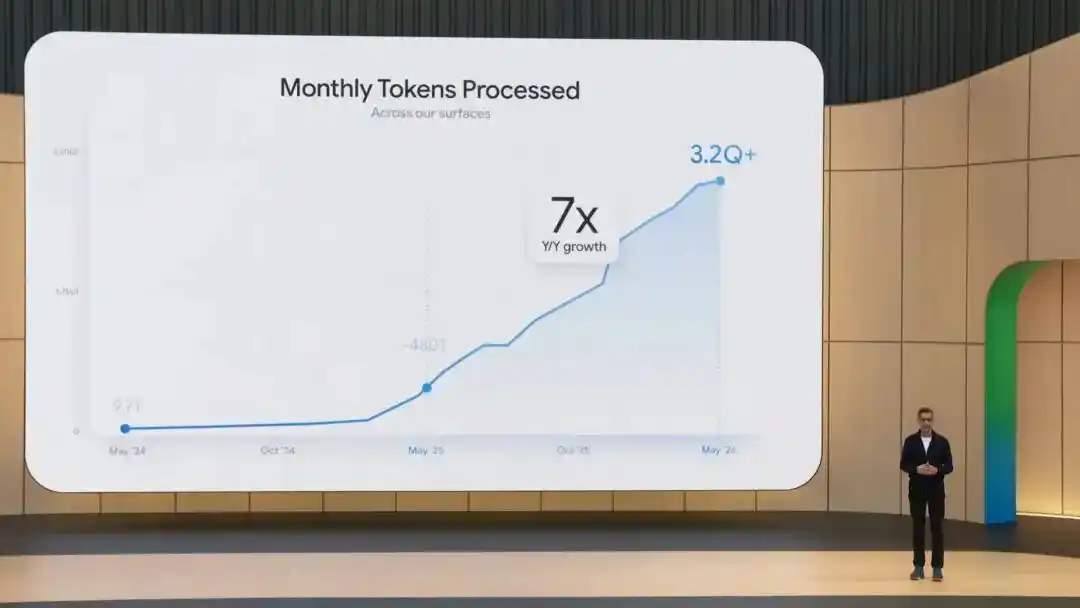
La aplicación Gemini tiene más de 900 millones de usuarios activos mensuales,procesa 3200 billones de tokens al mes, Nano Banana ha generado más de 50 mil millones de imágenes......
En la conferencia Google I/O que acaba de terminar esta madrugada, Sundar Pichai, CEO de Google, comenzó lanzando estas cifras.
El último año, la IA se convirtió en el tema principal de todas las industrias, y la posición de Gemini en Google también comenzó a cambiar, pasando de ser una aplicación única a convertirse en la capacidad de IA subyacente más importante en todos los productos de Google.
Esta presentación también comenzó con modelos, para luego pasar a productos de codificación y agentes.
Gemini Omni lleva la generación de video de Google hacia la dirección del "modelo mundial", mientras que Gemini 3.5 Flash, junto con las herramientas de programación con IA, se lanzan como plataforma de desarrollo de agentes.
Estas dos capacidades luego ingresan al ecosistema completo de Google: búsqueda, aplicación Gemini, Flow, Spark, Chrome, gafas XR y escenarios de comercio electrónico.
Aparece Gemini Omni, llega el momento "Nano Banana" del mundo del video
El primer punto en ser destacado en la presentación fue Gemini Omni. Hicimos un video comparándolo con Seedance 2.0 para ver las diferencias.
Google describe a Gemini Omni como un nuevo modelo capaz de "crear cualquier contenido a partir de cualquier entrada".
Combina la capacidad de razonamiento de Gemini con los modelos de medios generativos existentes de Google, con el objetivo de mejorar la comprensión del mundo por parte del modelo, la capacidad de generación multimodal y la capacidad de edición.

Google enfatiza que modelos como Veo, Nano Banana, Genie ya pueden generar videos, imágenes y simulaciones interactivas, pero Gemini Omni va más allá, comenzando a abordar problemas más cercanos al mundo físico, como la cinética, la gravedad, etc.
Los casos mostrados en el escenario de la presentación incluyen un video explicativo sobre el plegamiento de proteínas. El usuario solo necesita ingresar una indicación como "genera una explicación en animación de plastilina sobre el plegamiento de proteínas", y Omni puede transformar conceptos científicos abstractos en contenido de video.

También admite una edición de video más natural. Los usuarios pueden subir sus propios videos y luego modificar el estilo, agregar elementos, ajustar detalles mediante conversación, incluso transformar un círculo común en un agujero negro, o cambiar una escena de paseo nocturno en una imagen con mayor dramatismo.

Según Google, Gemini Omni comienza con video, y luego avanzará gradualmente hacia "cualquier entrada a cualquier salida". Esta es también la razón por la que Google siempre ha diseñado a Gemini como un modelo multimodal.
El primer modelo de la familia Omni, Gemini Omni Flash, ya está disponible en los productos de Google. Se dará más información sobre Omni Pro más adelante. Las funciones de Omni en la aplicación Gemini también están disponibles para suscriptores de Google AI Plus, Pro y Ultra.
Esto significa que Gemini Omni no es solo un modelo de generación de video. Google quiere integrarlo en la narrativa del "modelo mundial": el modelo no solo genera imágenes, sino que también comprende las relaciones físicas, las relaciones de movimiento y la lógica de la escena dentro de la imagen.
Después de integrarse en aplicaciones como Gemini App, Google Flow y YouTube Shorts, Omni también expandirá las herramientas de creación generativa de Google desde la edición de imágenes hasta la edición de video.
Se lanza Gemini 3.5 Flash, la IA para escribir código entra en modo ultrarrápido
Si Gemini Omni corresponde a generación y edición, Gemini 3.5 Flash corresponde a velocidad, costo y capacidad de ejecución.

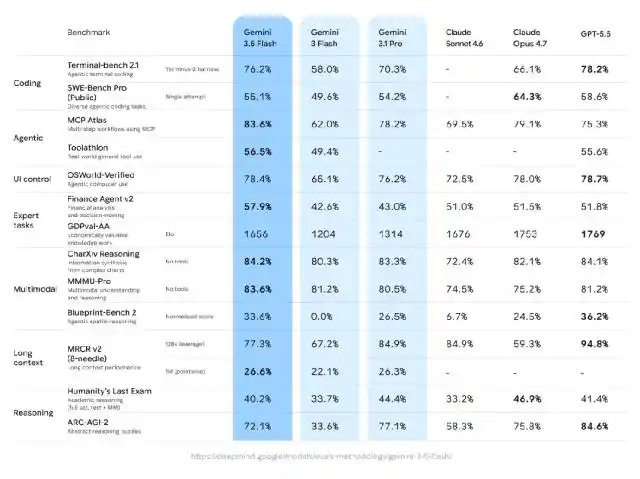
Google presentó Gemini 3.5 Flash en la conferencia, afirmando que es uno de los primeros modelos de la serie Gemini 3.5, enfocado en coding agentic, tareas de ciclo largo y flujos de trabajo reales.
En comparación con 3.1 Pro, 3.5 Flash muestra mejoras notables en casi todas las pruebas de referencia, especialmente en capacidad de código y evaluaciones más cercanas a tareas económicas reales como GDPVal.
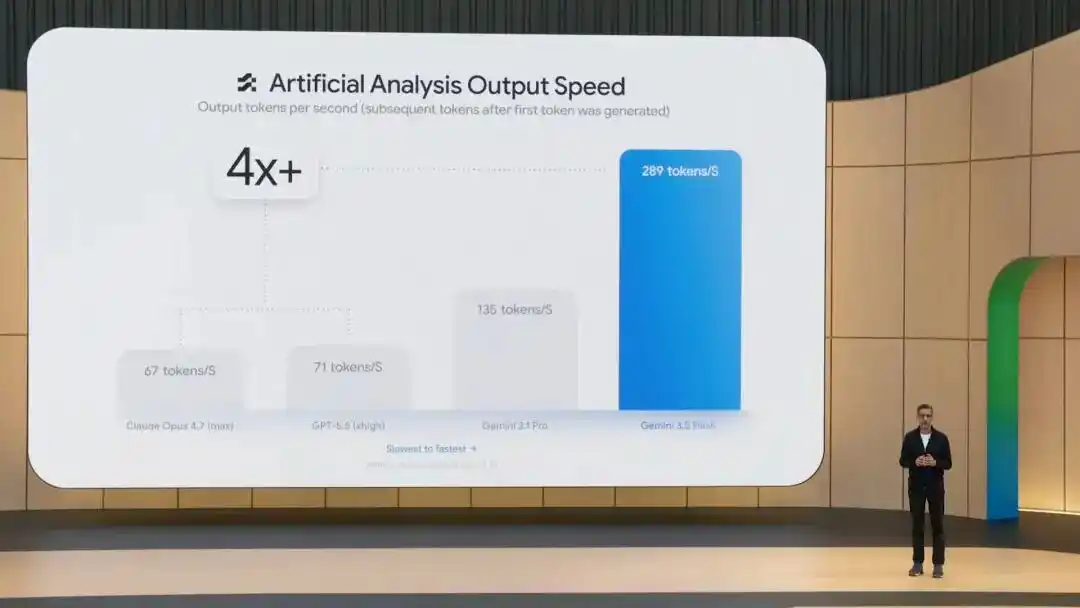
Además del buen desempeño en las pruebas de referencia,3.5 Flash es 4 veces más rápido en la velocidad de salida de tokens que otros modelos líderes, y después de una optimización especial en Antigravity, la velocidad puede alcanzar hasta 12 veces.
Vale la pena mencionar que en marzo de este año, las tareas de desarrollo interno de Google procesaban aproximadamente 500 mil millones de tokens por día, duplicándose cada pocas semanas, y actualmente superan los 3 billones de tokens diarios. Google llama a esto un ciclo de retroalimentación, usando un uso real a gran escala para seguir mejorando 3.5 Flash.
Junto con el modelo, se lanzó Antigravity 2.0.
Pasó de ser un IDE potenciado por agentes a una aplicación de escritorio independiente, con un cambio de enfoque hacia "agent first". Los usuarios ya no solo permiten que la IA asista en la escritura de código dentro del editor, sino que completan tareas de desarrollo a través del diálogo con Agentes, los productos de los Agentes y la colaboración entre múltiples Agentes.
Antigravity 2.0 incorpora una CLI completa, Antigravity SDK, soporte nativo de voz del modelo de audio de Gemini, e integración con servicios como Android, Firebase y Google AI Studio. Antigravity 2.0, como aplicación de escritorio independiente, ya está disponible para usuarios de todo el mundo.
Google usó una demostración intensiva en el escenario para explicar la dirección de Antigravity 2.0: permitir que un Agente construya un sistema operativo ejecutable desde cero. Esta tarea fue ejecutada en paralelo por 93 sub-agentes, duró 12 horas, inició más de 15,000 solicitudes al modelo, procesó 2.6 mil millones de tokens, generando desde un proyecto vacío módulos centrales como el programador, la gestión de memoria, el sistema de archivos, etc.
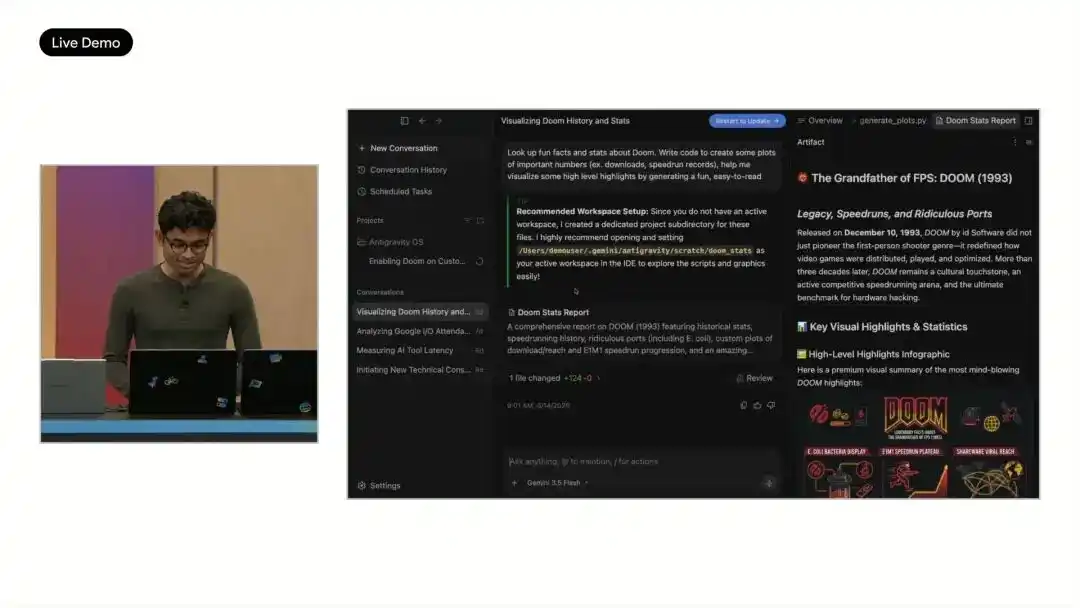
Google afirma que esto no se pudo lograr con Gemini 3.1 Pro, mientras que el uso de Gemini 3.5 Flash consumió menos de 1000 dólares en créditos de API.
En el escenario también se demostró este sistema ejecutando el programa de tren pequeño SL y Doom. Como al sistema inicialmente le faltaban controladores de video y teclado, Antigravity continuó generando el código relevante y corrigiendo, permitiendo que Doom se ejecutara. Google también afirmó que se han probado proyectos como suites de edición de fotos, aplicaciones de mensajería en tiempo real y plataformas de colaboración multiusuario de manera similar, comprimiendo trabajos de ingeniería que originalmente tomaban días a horas o incluso menos.
Gemini 3.5 Flash ya está disponible para todos los usuarios, cubriendo productos y API de Google.Gemini 3.5 Pro aún está en uso interno y siendo mejorado, se espera que se abra el próximo mes.
Del cuadro de búsqueda al Agente de información, Google rehace la búsqueda con IA
Después de los modelos y las herramientas de desarrollo, Google cambió el enfoque hacia la búsqueda. La búsqueda de Google ahora es la búsqueda con IA.

Google afirma que el Modo IA ya supera los 1000 millones de usuarios activos mensuales, y el volumen de consultas se duplica cada trimestre desde su lanzamiento.
A partir de hoy, el Modo IA se actualiza a Gemini 3.5. El nuevo cuadro de búsqueda inteligente también comienza a implementarse hoy mismo. Admite entrada de texto, imágenes, archivos y video, y brinda sugerencias de IA mientras el usuario escribe preguntas.

AI Overviews y AI Mode también se fusionaron en una experiencia de búsqueda con IA más continua. Los usuarios primero pueden ver la respuesta de IA en la página principal de resultados, luego ingresar al Modo IA para continuar preguntando, y el contexto se conserva. Esta nueva experiencia de búsqueda ya está disponible globalmente en escritorio y móvil el mismo día de la presentación.
El cambio más grande es el Agente de búsqueda. Este verano, los usuarios podrán crear Agentes de información en Search, para que realicen un seguimiento continuo de ciertos tipos de información.
Por ejemplo, un usuario puede hacer que monitoree acciones de biotecnología grandes con una relación precio-beneficio inferior a 15, flujo de caja positivo y baja deuda; también puede hacer que realice un seguimiento a largo plazo de información sobre alquileres, colaboraciones de zapatillas deportivas y nuevos productos. Cuando las condiciones cambien, el Agente enviará actualizaciones integradas al usuario.

Google también incorpora la capacidad de "agentic coding" de Antigravity a la búsqueda.
En el futuro, la búsqueda no solo devolverá páginas web, resúmenes o tarjetas, sino que también podrá generar interfaces interactivas para preguntas específicas. Por ejemplo, si un usuario pregunta "¿cómo afecta un agujero negro al espacio-tiempo?", Search puede generar un componente visual interactivo; si continúa preguntando "¿cómo generan ondas gravitacionales los agujeros negros binarios?", Search volverá a generar una interfaz dinámica con parámetros ajustables. Generative UI with Antigravity se lanzará de forma gratuita para todos los usuarios este verano.

También están en camino experiencias personalizadas más complejas.
Google mostró en el escenario un planificador de fin de semana,Search combinará información sobre el clima, mapas, preferencias del usuario, Gmail, Calendar, etc., para generar una pequeña herramienta que se puede seguir modificando, compartir y sincronizar con el calendario. Este tipo de experiencias personalizadas se abrirán primero a los usuarios suscriptores en los próximos meses.
Funciona incluso apagado, Gemini Spark traslada la capacidad de agente a la vida personal
El producto de consumo más importante es Gemini Spark.

Gemini Spark es un Agente de IA personal, que se ejecuta en una máquina virtual dedicada en Google Cloud y puede realizar tareas las 24 horas del día. Está impulsado por Gemini 3.5 y el sistema Antigravity harness, y admite tareas en segundo plano de larga duración.
Incluso después de que el usuario apague la computadora, Spark puede continuar trabajando. Primero se integra con las propias herramientas de Google, y en las próximas semanas se integrará con herramientas de terceros a través de MCP.

La presentación mostró varios escenarios típicos de Spark.
Un usuario puede pedirle que resuma los lanzamientos y avances de Gemini Live de la semana pasada, extraiga información de Docs, Gmail y registros de chat, y luego genere un correo electrónico para el equipo utilizando el estilo de escritura personal.
También puede pedirle que gestione una fiesta en el vecindario, mantenga una tabla de Google Sheets con RSVP, haga un seguimiento de quién trajo qué cosa, genere un borrador de correo electrónico de recordatorio para vecinos que no se hayan registrado, y genere automáticamente una página de presentación en Google Slides.
Spark también admite entrada de voz desde el móvil.
Los usuarios pueden enumerar múltiples tareas a la vez, como marcar todas las reuniones con Sundar de color rosa brillante, escribir una carta de invitación para un nuevo vecino, crear un documento de tareas pendientes para antes del final del año escolar del niño.Spark dividirá este contenido en múltiples tareas independientes y las ejecutará en segundo plano, y los resultados se pueden sincronizar entre el teléfono y la computadora.
Gemini Spark estará disponible para algunos evaluadores esta semana, y se lanzará en versión beta la próxima semana para suscriptores de Google AI Ultra en Estados Unidos.

Google también presenta un nuevo plan Ultra de 100 dólares mensuales, y reduce el precio del plan Ultra más alto de 250 a 200 dólares mensuales.
A finales de este verano, Spark llegará a Chrome, convirtiéndose en un navegador inteligente con agentes que pueden ejecutar tareas dentro de las páginas web.

Rediseño importante de la aplicación Gemini, y también la "versión de Google" del "informe matutino de IA"
La propia aplicación Gemini también ha recibido un rediseño integral.
Google introdujo un nuevo lenguaje de diseño llamado Neural Expressive, incorporando animaciones fluidas, colores vibrantes, nuevas fuentes y retroalimentación háptica.
La nueva versión de la aplicación Gemini ya no presenta las respuestas como largos párrafos de texto, sino que genera en tiempo real diseños más adecuados para la lectura y operación, incluyendo imágenes interactivas, líneas de tiempo, videos incrustados, etc. Neural Expressive ya se está implementando globalmente en Android, iOS y web.
Gemini Live también fue rediseñado; al abrirlo, se puede acceder directamente a una conversación en tiempo real. La selección de acentos regionales se lanzará en las próximas semanas.
La aplicación Gemini también incorpora Daily Brief. Se trata de un Agente de resumen personalizado para el uso matutino, que sintetizará información de Gmail, Calendar, Tasks, etc., organizará los asuntos que el usuario necesita atender ese día y brindará entradas para las próximas acciones.
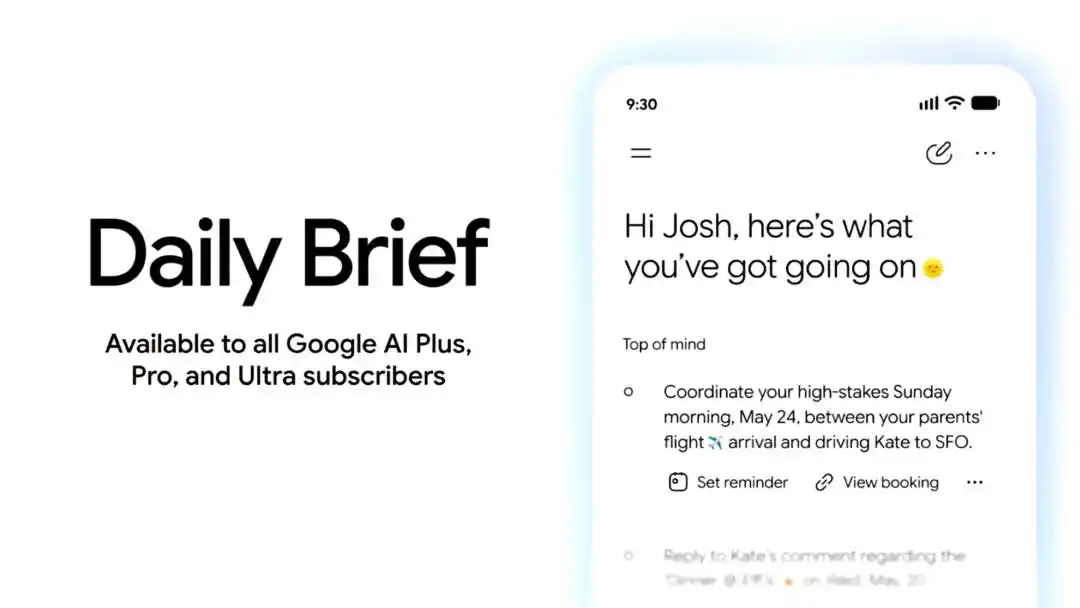
Daily Brief estará disponible a partir de hoy para suscriptores de Google AI Plus, Pro y Ultra en Estados Unidos.
Fuera de la narrativa más amplia de Gemini, Google también actualizó varios productos cotidianos.
Google Maps completó recientemente su mayor actualización en una década e incorporó Ask Maps. Permite a los usuarios plantear preguntas más largas y complejas. Por ejemplo, en la presentación se mencionó un escenario: un niño cae en un estanque de patos, la boda comienza en 30 minutos, el usuario quiere saber dónde puede comprar un vestido nuevo caminando.

Docs también recibe nueva capacidad de creación por voz. Los usuarios no necesitan ingresar indicaciones precisas, pueden directamente decir sus ideas con la voz, hacer que Gemini recupere el currículum de Drive, encuentre información de eventos en Gmail y luego genere un borrador en Google Docs. Esta capacidad se lanzará este verano para suscriptores Pro y Ultra, y capacidades de voz similares también llegarán a Gmail.
Después de la mejora de la capacidad de generación, la identificación de la fuente del contenido también se vuelve cada vez más importante.
Google afirma que,desde su lanzamiento hace tres años, SynthID ha agregado marcas de agua invisibles a más de 100 mil millones de imágenes y videos, y a audio equivalente a 60,000 años de duración. A continuación, SynthID y la verificación de credenciales de contenido se extenderán a Search y Chrome.

Los usuarios pueden buscar rodeando con el cursor, o hacer clic derecho en Chrome para preguntar si el contenido fue generado por IA, y el sistema mostrará si el contenido proviene de IA, de una cámara o si fue editado por herramientas de IA generativa.
Google también anunció que OpenAI, Kakao y ElevenLabs adoptarán SynthID 2. Anteriormente, NVIDIA ya se había unido al ecosistema SynthID. Para Google, SynthID no es solo una función de seguridad, sino también parte de la búsqueda de estándares de transparencia para el contenido de IA.

El paquete completo de creación de Google comienza a asediar imágenes, diseño y video
En el campo de las herramientas creativas, Google lanzó intensamente múltiples productos importantes.
Google Pics es un nuevo producto de creación y edición de imágenes dentro de Google Workspace, orientado a escenarios como carteles de fiesta, infografías, imágenes promocionales, etc. Los usuarios pueden comenzar con una imagen base, eliminar elementos, ajustar el tamaño de los objetos, editar texto y traducir texto. El contenido generado por Pics llevará la marca de agua SynthID. Google Pics se lanzará este verano.

El producto de diseño Stitch también recibe una actualización. Los usuarios pueden generar una interfaz de sitio web o aplicación con un solo comando de prompt, y luego continuar modificándola mediante texto o voz, como agrandar el título, ajustar el menú, resaltar más opciones de pizza. Stitch admite exportar el diseño como código o publicar el sitio web directamente; las actualizaciones relevantes ya se han lanzado.

La actualización de Google Flow es particularmente notable. Después de que Gemini Omni ingresa a Flow, los usuarios pueden cambiar el entorno, agregar efectos visuales, incorporar nuevos personajes basados en el video original, manteniendo en lo posible la actuación original.
Flow también incorpora nuevos Agentes, que admiten la ejecución de múltiples acciones a la vez. Por ejemplo, generar 16 videos con diferentes ángulos de cámara a partir de una sola imagen, o transformar un conjunto de escenas matutinas en escenas nocturnas de manera masiva.

Flow Tools permite a los usuarios crear sus propias herramientas creativas dentro de Flow, como efectos de video, animaciones dibujadas a mano y herramientas de capas de texto, y admite compartir y remezclar.
Google Flow Music puede expandir un riff de piano en un demo musical con una dirección de estilo. Estas nuevas funciones de Google Flow y Google Flow Music ya están disponibles.
Apostando por las gafas inteligentes, Google vuelve a explorar la entrada de próxima generación
En la parte de hardware,Google también expande Android XR, una plataforma a nivel de sistema operativo, desde cascos de realidad virtual, dispositivos XR, hacia la forma de gafas inteligentes.
Android XR es una plataforma desarrollada por Google en colaboración con Samsung y optimizada para Qualcomm Snapdragon.

Google afirma que las gafas de IA se dividirán en dos categorías:una son gafas con pequeñas lentes de visualización, la otra son gafas de audio. Las gafas de visualización ya se mostraron en I/O del año pasado, este año los primeros desarrolladores han comenzado a crear experiencias de visualización, y el programa de evaluadores de confianza se ampliará a finales de este año.
Las que llegarán al mercado antes son las gafas de audio.
Las primeras gafas de audio se lanzarán este otoño, con Samsung participando en la construcción del hardware y la experiencia, y Warby Parker y Gentle Monster a cargo del diseño de las gafas. Estas gafas se conectan al teléfono y admiten Android e iOS. Las respuestas de Gemini se reproducen de forma privada a través de auriculares, en lugar de mostrarse en las lentes.

En la presentación, el demostrador pudo usar las gafas para hacer que Gemini lo guiara al lugar donde se reunió con un amigo la semana pasada, deteniéndose en una cafetería en el camino; también pudo hacer que Gemini abriera DoorDash y ordenara café automáticamente, esperando la confirmación del usuario;
también pudo hacer que resumiera mensajes silenciados y escribiera una cena familiar en el calendario. Las gafas también pueden combinarse con un reloj inteligente, permitiendo al usuario tomar fotos en el lugar y usar Nano Banana para generar imágenes de dibujos animados, y luego previsualizarlas en el reloj.
Al final de la presentación, los escenarios de uso de Gemini también se extendieron al ámbito de la ciberseguridad.
Google presentó CodeMender. Es un Agente de seguridad de código, capaz de buscar y reparar automáticamente vulnerabilidades críticas en el software. Google invitará a un grupo de expertos a probar la API de CodeMender, y luego se lanzará de manera más amplia.

Al ver la presentación completa, la cantidad de información es tan grande que deja sin aliento. Solo que cuando estas funciones de IA realmente se abran a decenas o cientos de millones de usuarios, un problema de cálculo muy real se presenta directamente:¿Cómo va a recuperar Google este enorme gasto en potencia de cálculo?
Durante los últimos veinte años, Google representó un modelo típico de internet gratuito. Los usuarios intercambian atención y datos por servicios, Google gana dinero con publicidad y distribución. Este modelo hizo de Google la empresa de infraestructura más fuerte de la era de Internet.
Pero el costo de la inferencia de modelos grandes no está ni cerca de estar en el mismo orden de magnitud que consultar una vez los resultados de búsqueda.
Memoria de contexto largo, generación multimodal, Agentes entre aplicaciones, automatización a nivel empresarial, detrás de estas capacidades hay un consumo continuo de potencia de cálculo. Cuanto más profunda sea la IA, más difícil será para Google continuar digiriendo los costos mediante "actualizaciones de funciones gratuitas".
Es por eso que, a lo largo de toda la presentación, Google I/O parece hablar sobre mejoras en la experiencia, pero en realidad apunta a suscripciones, contratos empresariales, facturas de computación y tarifas de servicio a largo plazo.

Por supuesto, las entradas gratuitas no desaparecerán, porque siguen siendo la base para que Google obtenga usuarios, datos y posición en el ecosistema. Pero sobre estas entradas, Google está superponiendo una nueva capa de servicios inteligentes: modelos más potentes, memoria más larga, permisos de sistema más profundos, ejecución de tareas más complejas y servicios empresariales más estables.
En otras palabras, Google está pasando de ser una empresa de servicios de internet gratuitos a convertirse aún más en una empresa de infraestructura de suscripción de IA.
Solo que, con ello, surge la pregunta: ¿están los usuarios dispuestos a pagar por la búsqueda? Normalmente, no.
Pero, ¿y si se trata de un "asistente súper versátil" que puede procesar tu correo electrónico las 24 horas, coordinar tareas, analizar informes, gestionar tu hogar inteligente, e incluso ayudarte a escribir código y desarrollar aplicaciones? ¿Estarías dispuesto a pagar docenas o cientos de dólares al mes por ello?
Este es precisamente el principal desafío comercial que Google I/O de este año busca validar urgentemente. Y mirando el mercado frenético actual, la respuesta parece ya evidente.
Este artículo proviene de la cuenta oficial de WeChat "APPSO", autor: descubriendo los productos del mañana






