Autores originales: Malika Aubakirova, Matt Bornstein, a16z crypto
Traducción: Deep Tide TechFlow
En "Memento" de Christopher Nolan, el protagonista Leonard Shelby vive en un presente fragmentado. Una lesión cerebral le provoca amnesia anterógrada, incapaz de formar nuevos recuerdos. Cada pocos minutos, su mundo se reinicia, atrapado en un "ahora" eterno, sin recordar lo que acaba de pasar ni lo que vendrá después. Para sobrevivir, se tatúa palabras, saca fotos Polaroid, y confía en estos artefactos externos para sustituir la función de memoria que su cerebro no puede completar.
Los grandes modelos de lenguaje (LLMs) también viven en un presente eterno similar. Una vez finalizado el entrenamiento, un vasto conocimiento se congela en sus parámetros; el modelo no puede formar nuevos recuerdos, no puede actualizar sus propios parámetros basándose en nuevas experiencias. Para compensar esta deficiencia, le construimos un andamiaje de soportes: el historial de chat actúa como notas post-it a corto plazo, los sistemas de recuperación (retrieval) como cuadernos externos, los prompts del sistema como tatuajes en la piel. Pero el modelo en sí nunca internaliza realmente esta nueva información.
Cada vez más investigadores creen que esto no es suficiente. Los problemas que el aprendizaje en contexto (ICL) puede resolver presuponen que la respuesta (o fragmentos de ella) ya existe en algún rincón del mundo. Pero para aquellos problemas que requieren un descubrimiento genuino (como una nueva demostración matemática), escenarios adversariales (como ataques y defensas de seguridad), o para conocimientos demasiado implícitos o tácitos para ser expresados con palabras, hay razones de peso para pensar que los modelos necesitan una forma de escribir nueva información y experiencia directamente en sus parámetros *después* del despliegue.
El aprendizaje en contexto es temporal. El aprendizaje real requiere compresión. Hasta que permitamos que los modelos compriman de forma continua, probablemente estaremos atrapados en el presente eterno de "Memento". Por el contrario, si podemos entrenar modelos para que aprendan su propia arquitectura de memoria, en lugar de depender de herramientas externas personalizadas, podríamos desbloquear una nueva dimensión de escalado (scaling).
Esta área de investigación se llama aprendizaje continuo (continual learning). El concepto no es nuevo (ver el artículo de McCloskey y Cohen de 1989), pero creemos que es una de las direcciones de investigación más importantes en IA actualmente. La explosión de capacidades de los modelos en los últimos dos o tres años ha hecho que la brecha entre lo que los modelos "saben" y lo que "podrían saber" sea cada vez más evidente. El propósito de este artículo es compartir lo que hemos aprendido de investigadores líderes en este campo, ayudar a clarificar las diferentes vías del aprendizaje continuo e impulsar el desarrollo de este tema dentro del ecosistema emprendedor.
Nota: Este artículo tomó forma gracias a profundas conversaciones con un grupo de excelentes investigadores, estudiantes de doctorado y emprendedores que generosamente compartieron con nosotros su trabajo y perspectivas sobre el aprendizaje continuo. Desde los fundamentos teóricos hasta la realidad ingenieril del aprendizaje post-despliegue, sus ideas hicieron este artículo mucho más sólido de lo que hubiera sido si lo hubiéramos escrito solos. ¡Gracias por vuestro tiempo y contribución!
Hablemos primero del contexto
Antes de defender el aprendizaje a nivel de parámetros (es decir, el que actualiza los pesos del modelo), es necesario reconocer un hecho: el aprendizaje en contexto *funciona*. Y existe un argumento sólido de que seguirá ganando.
La naturaleza del Transformer es ser un predictor condicional del siguiente token basado en secuencias. Dale la secuencia correcta y obtendrás comportamientos sorprendentemente ricos, sin necesidad tocar los pesos. Es por eso que métodos como la gestión del contexto, la ingeniería de prompts, el fine-tuning por instrucciones y los ejemplos few-shot son tan potentes. La inteligencia está encapsulada en parámetros estáticos, pero las capacidades exhibidas varían enormemente según el contenido que introduzcas en la ventana de contexto.
El reciente artículo en profundidad de Cursor sobre el escalado de agentes autónomos de programación es un buen ejemplo: los pesos del modelo están fijos, lo que realmente hace funcionar al sistema es la cuidadosa orquestación del contexto — qué poner, cuándo resumir, cómo mantener un estado coherente durante horas de ejecución autónoma.
OpenClaw es otro gran ejemplo. Se hizo viral no por tener acceso especial a un modelo (el modelo base lo tiene todo el mundo), sino por convertir el contexto y las herramientas en un estado de trabajo de manera extremadamente eficiente: rastrear lo que estás haciendo, estructurar resultados intermedios, decidir cuándo reinyectar prompts, mantener una memoria persistente del trabajo anterior. OpenClaw elevó el "diseño de la cáscara" del agente a la altura de una disciplina independiente.
Cuando la ingeniería de prompts surgió por primera vez, muchos investigadores eran escépticos sobre que "solo con prompts" pudiera ser una interfaz legítima. Parecía un hack. Pero es un producto nativo de la arquitectura Transformer, no requiere reentrenamiento y se mejora automáticamente a medida que los modelos avanzan. Los modelos mejoran, los prompts mejoran. Las interfaces "simples pero nativas" suelen ganar porque se acoplan directamente al sistema subyacente, en lugar de luchar contra él. Hasta ahora, la trayectoria de los LLMs ha sido exactamente esa.
Modelos de espacio de estados: Contexto con esteroides
A medida que los flujos de trabajo principales pasan de las invocaciones simples de LLMs a los bucles de agentes, la presión sobre los modelos de aprendizaje en contexto aumenta. En el pasado, era relativamente raro que la ventana de contexto se llenara por completo. Esto ocurría típicamente cuando se pedía al LLM que completara una larga lista de tareas discretas, y la capa de aplicación podía recortar y comprimir el historial de chat de manera bastante directa.
Pero para un agente, una sola tarea puede consumir una parte significativa del contexto total disponible. Cada paso del bucle del agente depende del contexto transmitido por iteraciones anteriores. Y a menudo fallan después de 20 a 100 pasos porque "pierden el hilo": el contexto se llena, la coherencia se degrada, no pueden converger.
Por lo tanto, los principales laboratorios de IA están ahora invirtiendo recursos significativos (es decir, ejecuciones de entrenamiento a gran escala) en desarrollar modelos con ventanas de contexto ultra largas. Este es un camino natural, porque se basa en lo que ya funciona (aprendizaje en contexto) y se alinea con la tendencia general de la industria hacia un cambio hacia el cómputo en tiempo de inferencia. La arquitectura más común intercala capas de memoria fija entre las cabezas de atención normales, es decir, Modelos de Espacio de Estados (SSM) y variantes de atención lineal (en adelante denominados colectivamente SSM). Los SSM ofrecen curvas de escalado fundamentalmente mejores en escenarios de contexto largo.
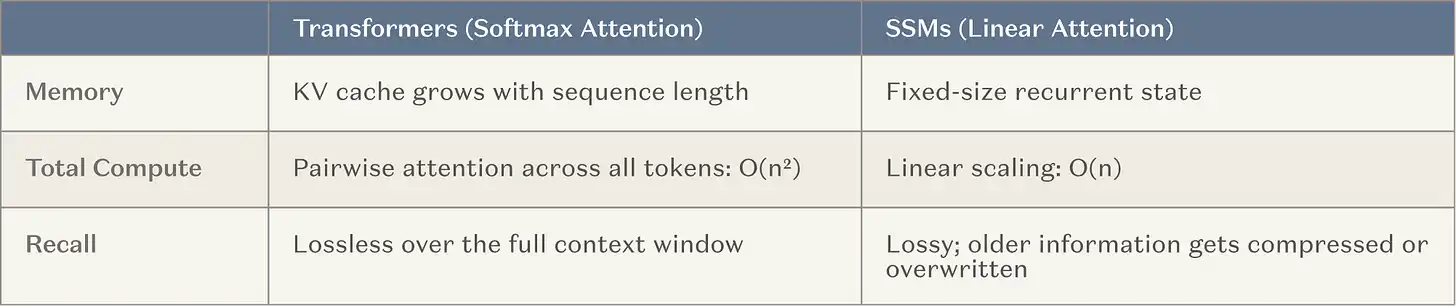
Pie de figura: Comparación de escalado entre SSM y el mecanismo de atención tradicional
El objetivo es ayudar a los agentes a aumentar el número de pasos de ejecución coherente en varios órdenes de magnitud, de unos 20 pasos a unos 20.000, sin perder las amplias habilidades y conocimientos que proporcionan los Transformers tradicionales. Si tiene éxito, esto sería un gran avance para los agentes de larga duración.
Incluso se podría ver este método como una forma de aprendizaje continuo: aunque no actualiza los pesos del modelo, introduce una capa de memoria externa que casi nunca necesita reiniciarse.
Por lo tanto, estos métodos no paramétricos son reales y potentes. Cualquier evaluación del aprendizaje continuo debe comenzar aquí. La pregunta no es si los sistemas de contexto actuales funcionan, porque lo hacen. La pregunta es: ¿ya hemos visto el techo, y pueden los nuevos métodos llevarnos más lejos?
Lo que el contexto omite: La "Falacia del Archivo"
"Lo que sucede con la AGI y el pre-entrenamiento es que, en cierto sentido, se sobrepasa... Los humanos no son AGI. Sí, los humanos tienen una base de habilidades, pero carecen de una gran cantidad de conocimiento. Dependemos del aprendizaje continuo.
Si creara un adolescente superinteligente de 15 años, no sabría nada. Un buen estudiante, muy ansioso por aprender. Podrías decirle: ve a ser programador, ve a ser médico. El despliegue en sí mismo implicaría algún tipo de proceso de aprendizaje, de prueba y error. Es un proceso, no lanzar un producto terminado directamente." — Ilya Sutskever
Imagina un sistema con espacio de almacenamiento infinito. El archivador más grande del mundo, cada hecho perfectamente indexado, instantáneamente recuperable. Puede buscar cualquier cosa. ¿Ha aprendido?
No. Nunca se vio forzado a comprimir.
Este es el núcleo de nuestro argumento, que hace referencia a un punto planteado anteriormente por Ilya Sutskever: los LLMs son, en esencia, algoritmos de compresión. Durante el entrenamiento, comprimen Internet en parámetros. La compresión es con pérdidas, y es esta pérdida lo que la hace poderosa. La compresión obliga al modelo a buscar estructura, a generalizar, a construir representaciones que pueden transferirse a través de contextos. Un modelo que memoriza todas las muestras de entrenamiento es peor que uno que extrae las reglas subyacentes. La compresión con pérdidas *es* el aprendizaje.
Irónicamente, el mecanismo que hace que los LLMs sean tan poderosos durante el entrenamiento (comprimir datos crudos en representaciones compactas y transferibles) es precisamente lo que les negamos seguir haciendo después del despliegue. Detenemos la compresión en el momento de la publicación, sustituyéndola por memoria externa.
Por supuesto, la mayoría de las "cáscaras" de agentes comprimen el contexto de alguna manera personalizada. Pero, ¿acaso la "amarga lección" (bitter lesson) no nos dice que el modelo mismo debería aprender esta compresión, de forma directa y a gran escala?
Yu Sun compartió un ejemplo para ilustrar este debate: las matemáticas. Mira el Último Teorema de Fermat. Durante más de 350 años, ningún matemático pudo demostrarlo, no porque carecieran de la documentación correcta, sino porque la solución era altamente novedosa. La distancia conceptual entre el conocimiento matemático existente y la respuesta final era demasiado grande.
Cuando Andrew Wiles finalmente lo resolvió en la década de 1990, pasó siete años trabajando casi en aislamiento, teniendo que inventar técnicas completamente nuevas para llegar a la respuesta. Su demostración dependía de tender un puente exitoso entre dos ramas diferentes de las matemáticas: las curvas elípticas y las formas modulares. Aunque Ken Ribet ya había demostrado que si se podía establecer esta conexión se resolvería automáticamente el Teorema de Fermat, antes de Wiles, nadie poseía las herramientas teóricas para construir realmente ese puente. Se podría hacer un argumento similar para la demostración de Grigori Perelman de la Conjetura de Poincaré.
La pregunta central es: ¿Estos ejemplos demuestran que a los LLMs les falta algo, alguna capacidad de actualizar sus conocimientos previos, de pensar de manera realmente creativa? ¿O esta historia prueba justo lo contrario: que todo conocimiento humano es solo datos disponibles para ser entrenados y recombinados, y que Wiles y Perelman simplemente mostraron lo que los LLMs también podrían hacer a mayor escala?
Esta pregunta es empírica y la respuesta aún no es segura. Pero sí sabemos que hay muchas categorías de problemas en las que el aprendizaje en contexto falla hoy, y donde el aprendizaje a nivel de parámetros podría ser útil. Por ejemplo:

Pie de figura: Categorías de problemas donde falla el aprendizaje en contexto y el aprendizaje paramétrico podría ganar.
Lo más importante es que el aprendizaje en contexto solo puede manejar cosas que pueden expresarse con palabras, mientras que los pesos pueden codificar conceptos que los prompts no pueden transmitir con texto. Algunos patrones son de dimensión demasiado alta, demasiado implícitos, demasiado profundamente estructurales para caber en el contexto. Por ejemplo, la textura visual que distingue un artefacto benigno de un tumor en una exploración médica, o las microfluctuaciones de audio que definen el ritmo único de un hablante; estos patrones no se descomponen fácilmente en palabras precisas.
El lenguaje solo puede aproximarlos. Ningún prompt, por largo que sea, puede transmitir estas cosas; este tipo de conocimiento solo puede vivir en los pesos. Viven en el espacio latente de las representaciones aprendidas, no en las palabras. No importa cuánto crezca la ventana de contexto, siempre habrá algún conocimiento que el texto no pueda describir, solo ser portado por los parámetros.
Esto quizás explique por qué las funciones explícitas de "el robot te recuerda" (como la memoria de ChatGPT) a menudo hacen que los usuarios se sientan incómodos en lugar de encantados. Lo que los usuarios realmente quieren no es "recordar", sino "capacidad". Un modelo que ha internalizado tus patrones de comportamiento puede generalizar a nuevas situaciones; uno que solo recupera tu historial no puede. La brecha entre "esto es lo que escribiste la última vez que respondiste a este correo" (repitiendo textualmente) y "he llegado a entender tu forma de pensar lo suficiente como para predecir lo que necesitarás" es la brecha entre recuperación y aprendizaje.
Introducción al aprendizaje continuo
El aprendizaje continuo tiene múltiples caminos. La línea divisoria no está en "tener o no función de memoria", sino en: ¿Dónde ocurre la compresión? Estos caminos se distribuyen a lo largo de un espectro, desde ninguna compresión (recuperación pura, pesos congelados), hasta compresión interna completa (aprendizaje a nivel de pesos, el modelo se vuelve más inteligente), con una zona intermedia importante (módulos).
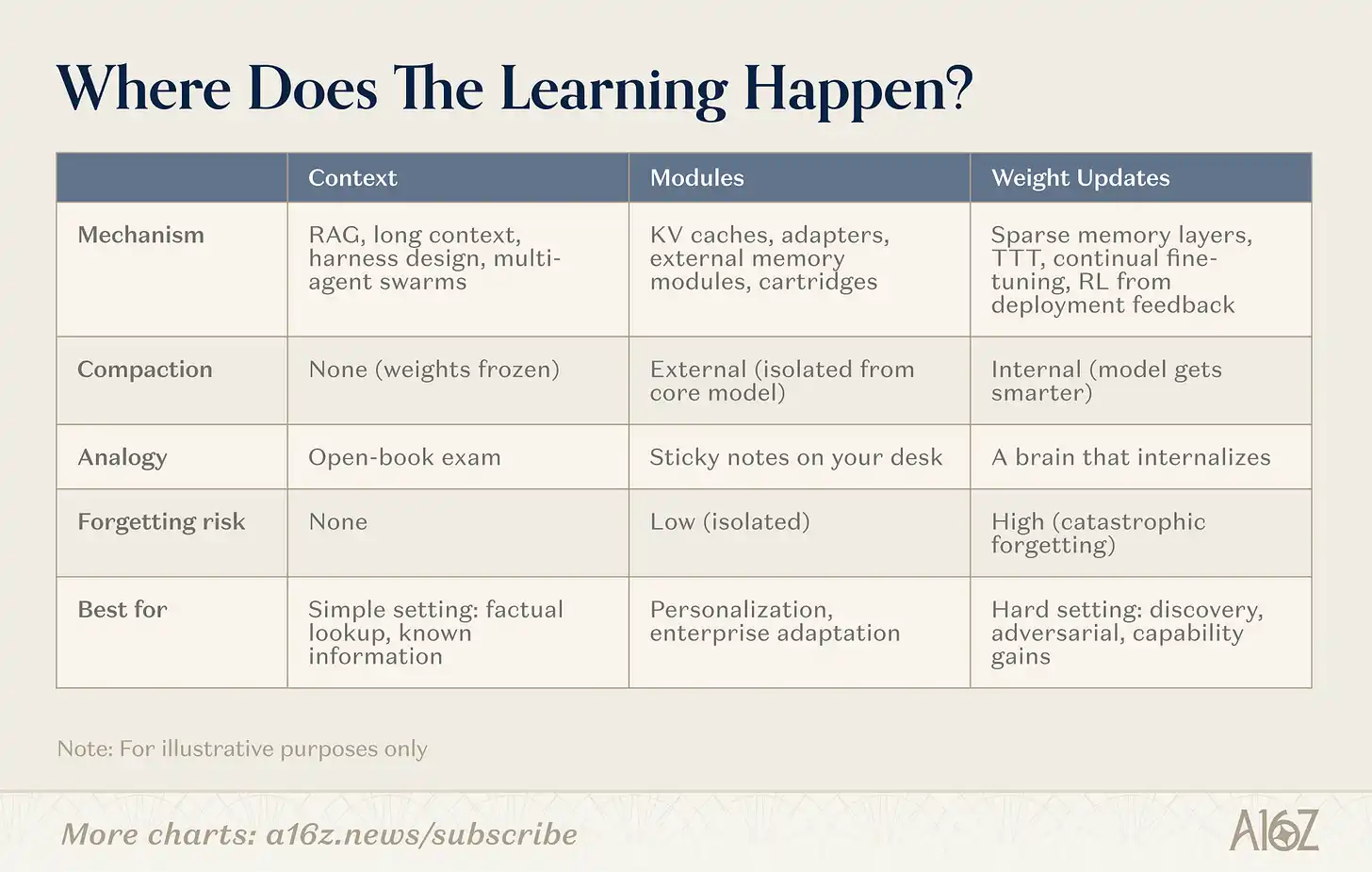
Pie de figura: Los tres caminos del aprendizaje continuo: Contexto, Módulos, Pesos.
Contexto
En el extremo del contexto, los equipos construyen pipelines de recuperación más inteligentes, "cáscaras" de agentes y orquestación de prompts. Esta es la categoría más madura: la infraestructura está probada, el camino de despliegue es claro. La limitación es la profundidad: la longitud del contexto.
Una nueva dirección notable: las arquitecturas multi-agente como estrategia de escalado del contexto mismo. Si un solo modelo está limitado a una ventana de 128K tokens, un grupo coordinado de agentes —cada uno con su propio contexto, enfocado en una porción del problema, comunicándose los resultados— puede aproximar en conjunto una memoria de trabajo infinita. Cada agente hace aprendizaje en contexto dentro de su propia ventana; el sistema hace la agregación. El reciente autoresearch project de Karpathy y el ejemplo de Cursor construyendo un navegador web son casos tempranos. Este es un enfoque puramente no paramétrico (sin cambiar pesos), pero eleva enormemente el límite de lo que los sistemas de contexto pueden hacer.
Módulos
En el espacio de los módulos, los equipos construyen módulos de conocimiento enchufables (cachés KV comprimidos, capas adaptadoras, almacenes de memoria externos) que permiten que un modelo general se especialice sin reentrenar. Un modelo de 8B con el módulo adecuado puede igualar el rendimiento de un modelo de 109B en una tarea objetivo, con una fracción de su huella de memoria. El atractivo es que es compatible con la infraestructura Transformer existente.
Pesos
En el extremo de la actualización de pesos, los investigadores persiguen un verdadero aprendizaje a nivel de parámetros: capas de memoria dispersas que actualizan solo fragmentos relevantes de parámetros, bucles de aprendizaje por refuerzo que optimizan el modelo a partir de la retroalimentación, entrenamiento en tiempo de prueba (test-time training) que comprime el contexto en los pesos durante la inferencia. Estos son los métodos más profundos, y también los más difíciles de desplegar, pero permiten que el modelo internalice completamente nueva información o nuevas habilidades.
Los mecanismos específicos para la actualización de parámetros son variados. Enumeremos algunas direcciones de investigación:
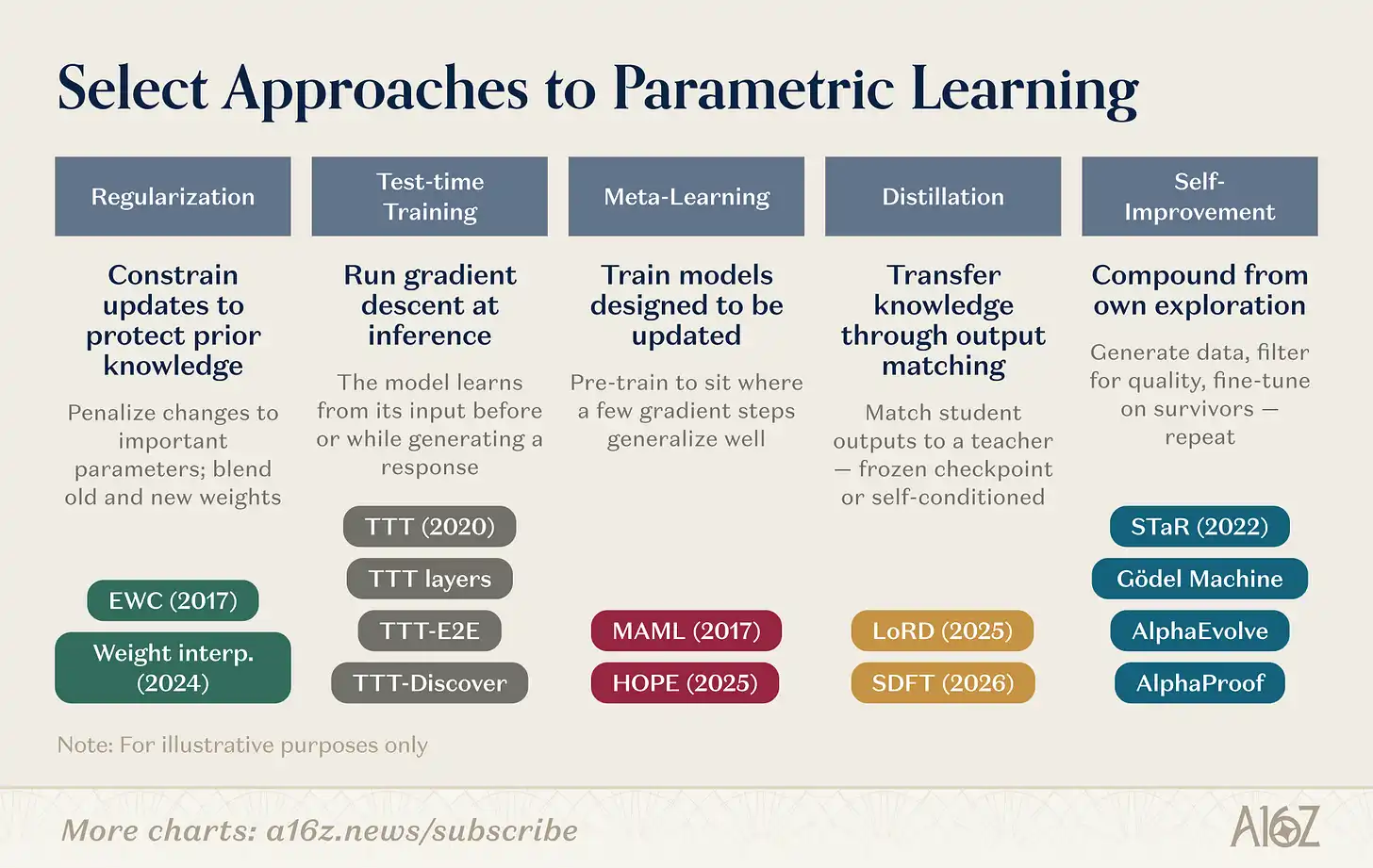
Pie de figura: Resumen de las direcciones de investigación en aprendizaje a nivel de pesos.
La investigación a nivel de pesos cubre múltiples líneas paralelas. Los métodos de regularización y espacio de pesos son los más antiguos: EWC (Kirkpatrick et al., 2017) penaliza los cambios en los parámetros según su importancia para tareas anteriores; la interpolación de pesos (Kozal et al., 2024) mezcla configuraciones de pesos nuevas y viejas en el espacio de parámetros, pero ambos son frágiles a gran escala.
El entrenamiento en tiempo de prueba (Test-Time Training, TTT), iniciado por Sun et al. (2020) y luego desarrollado en primitivas arquitectónicas (capas TTT, TTT-E2E, TTT-Discover), tiene un enfoque radicalmente diferente: hacer descenso de gradiente en los datos de prueba, comprimiendo nueva información en los parámetros en el momento en que se necesita.
El meta-aprendizaje pregunta: ¿Podemos entrenar modelos que sepan "cómo aprender"? Desde la inicialización de parámetros favorable a few-shot de MAML (Finn et al., 2017) hasta el Aprendizaje Anidado (Nested Learning, 2025) de Behrouz et al., que estructura el modelo como un problema de optimización jerárquico, con módulos que operan a diferentes escalas de tiempo para una adaptación rápida y una actualización lenta, inspirado en la consolidación de la memoria biológica.
La destilación (Distillation) conserva el conocimiento de tareas anteriores haciendo que un modelo estudiante coincida con puntos de control (checkpoints) congelados de un modelo profesor. LoRD (Liu et al., 2025) hace que la destilación sea lo suficientemente eficiente como para ejecutarse continuamente, podando simultáneamente el modelo y el búfer de repetición (replay buffer). La auto-destilación (SDFT, Shenfeld et al., 2026) invierte la fuente, utilizando las salidas del modelo propio en condiciones expertas como señal de entrenamiento, evitando el olvido catastrófico del fine-tuning secuencial.
La auto-mejora recursiva (Recursive Self-Improvement) opera en líneas de pensamiento similares: STaR (Zelikman et al., 2022) bootstrap de cadenas de razonamiento auto-generadas para impulsar la capacidad de razonamiento; AlphaEvolve (DeepMind, 2025) descubrió optimizaciones de algoritmos que no habían sido mejoradas en décadas; "La Era de la Experiencia" (The Experience Age, 2025) de Silver y Sutton define el aprendizaje de agentes como un flujo continuo e incesante de experiencia.
Estas direcciones de investigación están convergiendo. TTT-Discover ya fusiona el entrenamiento en tiempo de prueba con la exploración impulsada por RL. HOPE anida bucles de aprendizaje rápidos y lentos dentro de una única arquitectura. SDFT convierte la destilación en una operación fundamental de auto-mejora. Los límites entre las columnas se están difuminando. Es probable que la próxima generación de sistemas de aprendizaje continuo combine múltiples estrategias: usar regularización para estabilizar, meta-aprendizaje para acelerar, auto-mejora para obtener interés compuesto. Un número creciente de startups está apostando por diferentes niveles de este stack tecnológico.
Panorama de Startups en Aprendizaje Continuo
El extremo no paramétrico del espectro es el más conocido. Las empresas de "cáscara" (shell) (Letta, mem0, Subconscious) construyen capas de orquestación y andamiaje, gestionan lo que entra en la ventana de contexto. El almacenamiento externo y la infraestructura RAG (como Pinecone, xmemory) proporcionan la columna vertebral de recuperación. Los datos existen, el desafío es poner la porción correcta frente al modelo en el momento correcto. A medida que las ventanas de contexto se expanden, el espacio de diseño de estas empresas también crece, especialmente en el lado de la cáscara, donde está surgiendo una nueva ola de startups para gestionar estrategias de contexto cada vez más complejas.
El extremo paramétrico es más incipiente y diverso. Aquí, las empresas están probando alguna versión de "compresión post-despliegue", haciendo que los modelos internalicen nueva información en sus pesos. Los caminos se dividen aproximadamente en diferentes apuestas sobre "cómo" debería aprender un modelo después de ser lanzado.
Compresión parcial: Aprender sin reentrenar. Algunos equipos construyen módulos de conocimiento enchufables (cachés KV comprimidos, capas adaptadoras, almacenes de memoria externos) que permiten que un modelo general se especialice sin tocar los pesos centrales. El argumento común es: se obtiene una compresión significativa (no solo recuperación), manteniendo el equilibrio estabilidad-plasticidad manejable, porque el aprendizaje está aislado, no disperso por todo el espacio de parámetros. Un modelo de 8B con el módulo adecuado puede igualar el rendimiento de modelos mucho más grandes en una tarea objetivo. La ventaja es la composabilidad: los módulos son plug-and-play con las arquitecturas Transformer existentes, se pueden intercambiar o actualizar de forma independiente, con un coste de experimentación mucho menor que el reentrenamiento.
RL y bucles de retroalimentación: Aprender de las señales. Otros equipos apuestan a que la señal más rica para el aprendizaje post-despliegue ya existe en el propio ciclo de despliegue: correcciones de usuarios, éxito/fracaso de tareas, señales de recompensa de resultados del mundo real. La idea central es que el modelo debería tratar cada interacción como una señal de entrenamiento potencial, no solo como una solicitud de inferencia. Esto es muy similar a cómo los humanos mejoran en su trabajo: hacer el trabajo, recibir comentarios, internalizar qué métodos funcionan. El desafío de ingeniería es convertir comentarios dispersos, ruidosos y a veces adversariales en actualizaciones de pesos estables, sin olvido catastrófico. Pero un modelo que realmente pueda aprender del despliegue generará valor compuesto de una manera que los sistemas de contexto no pueden.
Centrado en datos: Aprender de las señales correctas. Una apuesta relacionada pero distinta es que el cuello de botella no está en el algoritmo de aprendizaje, sino en los datos de entrenamiento y los sistemas circundantes. Estos equipos se centran en filtrar, generar o sintetizar los datos correctos para impulsar las actualizaciones continuas: la premisa es que un modelo con señales de aprendizaje de alta calidad y bien estructuradas necesita muchos menos pasos de gradiente para mejorar significativamente. Esto se conecta naturalmente con las empresas de bucles de retroalimentación, pero enfatiza el problema aguas arriba: una cosa es si el modelo *puede* aprender, otra es *de qué* debería aprender y *hasta qué punto*.
Nuevas arquitecturas: Diseñar la capacidad de aprendizaje desde la base. La apuesta más radical argumenta que la arquitectura Transformer es en sí misma el cuello de botella, y que el aprendizaje continuo requiere primitivas computacionales fundamentalmente diferentes: arquitecturas con dinámicas de tiempo continuo y mecanismos de memoria incorporados. El argumento aquí es estructural: si quieres un sistema de aprendizaje continuo, deberías incorporar el mecanismo de aprendizaje en la infraestructura subyacente.

Pie de figura: Panorama de startups de aprendizaje continuo.
Todos los laboratorios principales también están activos en estas categorías. Algunos exploran una mejor gestión del contexto y razonamiento de cadena de pensamiento (chain-of-thought), otros experimentan con módulos de memoria externa o pipelines de cómputo en "tiempo de sueño" (sleep-time), y varias empresas en modo sigiloso (stealth) persiguen nuevas arquitecturas. Este campo es lo suficientemente temprano como para que ningún método haya ganado todavía, y dada la amplitud de casos de uso, probablemente no debería haber un solo ganador.
Por qué falla la actualización ingenua de pesos
Actualizar los parámetros del modelo en un entorno de producción desencadena una serie de modos de fallo que actualmente no se han resuelto a gran escala.

Pie de figura: Modos de fallo de la actualización ingenua de pesos.
Los problemas de ingeniería están bien documentados. El olvido catastrófico significa que un modelo lo suficientemente sensible a los nuevos datos para aprender, destruirá las representaciones existentes — el dilema estabilidad-plasticidad. El desacoplamiento temporal ocurre porque las reglas invariables y el estado variable se comprimen en el mismo conjunto de pesos; actualizar uno corrompe el otro. La integración lógica falla porque las actualizaciones de hechos no se propagan a sus inferencias: los cambios se limitan al nivel de la secuencia de tokens, no al nivel del concepto semántico. El "olvido" (unlearning) sigue siendo imposible: no existe una operación diferenciable de sustracción, por lo que no hay una forma de extirpar quirúrgicamente conocimientos falsos o tóxicos con precisión.
Hay una segunda clase de problemas a la que se presta menos atención. La separación actual entre entrenamiento y despliegue no es solo una conveniencia de ingeniería, es un límite para la seguridad, la auditabilidad y la gobernanza. Abrir este límite hace que varias cosas salgan mal simultáneamente. La alineación de seguridad (safety alignment) puede degradarse de forma impredecible: incluso el fine-tuning de rango estrecho en datos benignos puede producir comportamientos de desalineación generalizados.
Las actualizaciones continuas crean una superficie de ataque para el envenenamiento de datos — una versión lenta y persistente de la inyección de prompts, pero que vive en los pesos. La auditabilidad se colapsa, porque un modelo que se actualiza continuamente es un blanco móvil, imposible de controlar versiones, hacer pruebas de regresión o certificar de una sola vez. Los riesgos de privacidad se intensifican cuando las interacciones de los usuarios se comprimen en los parámetros, ya que la información sensible se hornea en las representaciones, siendo más difícil de filtrar que la información en el contexto recuperado.
Estos son problemas abiertos, no imposibilidades fundamentales. Resolverlos es parte de la agenda de investigación del aprendizaje continuo, tanto como resolver los desafíos centrales de la arquitectura.
De "Memento" a la memoria real
La tragedia de Leonard en "Memento" no es que no pueda funcionar — en cualquier escena dado es ingenioso, incluso brillante. Su tragedia es que nunca puede obtener interés compuesto. Cada experiencia permanece externa — una Polaroid, un tatuaje, una nota escrita por otra persona. Puede recuperar, pero no puede comprimir nuevo conocimiento.
Mientras Leonard navega por este laberinto auto-construido, la línea entre la verdad y la creencia comienza a desdibujarse. Su condición no solo le priva de su memoria; le obliga a reconstruir constantemente el significado, convirtiéndolo simultáneamente en el detective y el narrador poco fiable de su propia historia.
La IA de hoy funciona bajo las mismas restricciones. Hemos construido sistemas de recuperación tremendamente potentes: ventanas de contexto más largas, cáscaras más inteligentes, grupos de multi-agentes coordinados, y funcionan. Pero recuperar no es igual a aprender. Un sistema que puede buscar cualquier hecho no se ve obligado a buscar estructura. No se ve obligado a generalizar. La compresión con pérdidas que hizo que el entrenamiento fuera tan poderoso — el mecanismo que convierte datos crudos en representaciones transferibles — es precisamente lo que apagamos en el momento del despliegue.
El camino a seguir probablemente no sea un único avance, sino un sistema en capas. El aprendizaje en contexto seguirá siendo la primera línea de defensa de adaptación: es nativo, probado y en mejora constante. Los mecanismos modulares pueden manejar la zona intermedia de personalización y especialización de dominio.
Pero para esos problemas realmente difíciles — descubrimiento, adaptación adversarial, conocimiento tácito inexpresable con palabras — puede que necesitemos que los modelos continúen comprimiendo la experiencia en sus parámetros *después* del entrenamiento. Esto significa avances en arquitecturas dispersas, objetivos de meta-aprendizaje y bucles de auto-mejora. También puede requerir que redefinamos lo que significa "modelo": no como un conjunto fijo de pesos, sino como un sistema en evolución que incluye su memoria, su algoritmo de actualización y su capacidad para abstraer de su propia experiencia.
El archivador se está haciendo más grande. Pero un archivador más grande sigue siendo un archivador. El avance está en permitir que el modelo haga después del despliegue lo que lo hizo poderoso durante el entrenamiento: comprimir, abstraer, aprender. Estamos en la cúspide de pasar de modelos amnésicos a modelos con un atisbo de luz experiencial. De lo contrario, estaremos atrapados en nuestro propio "Memento".







