El campo de la generación de imágenes a partir de texto es desde hace tiempo un mercado saturado, aparentemente sin margen para más competencia.
¿Qué necesitas para entrenar un modelo potente de texto a imagen hoy en día?
Si partimos de las soluciones principales actuales, se requiere: un codificador/decoder VAE preentrenado, la concatenación de codificadores de texto, mecanismos de inyección condicional cuidadosamente diseñados, cantidades masivas de datos, una fase de alineación con RL o DPO...
En general, parece existir una premisa asumida: hacer texto-a-imagen tiene que ser así de complejo.
Sin embargo, el equipo de Kaiming He tomó el camino contrario, introduciendo una nueva perspectiva en el ámbito de los modelos de texto a imagen. Presentaron MiniT2I — un modelo minimalista de texto a imagen en espacio de píxeles diseñado intencionalmente para ser extremadamente simple.
Sin codificador/decoder VAE, sin inyección condicional AdaLN, sin funciones de pérdida auxiliares, sin datos privados, sin alineación RL/DPO, un objetivo de flujo-matching puro entrenado directamente sobre píxeles. La versión B/16 con 258M de parámetros alcanza 0.87 en GenEval y 84.2 en DPG-Bench, superando a modelos similares en espacio de píxeles con varios órdenes de magnitud más de parámetros.

La propuesta central de MiniT2I es: si tratamos la condición de texto como "tokens contextuales con información semántica" inyectados en el modelo, la generación de texto-a-imagen y la generación condicionada por clases en ImageNet no son fundamentalmente tan diferentes — la arquitectura puede ser similar, la capacidad de cómputo puede ser comparable, e incluso la escala de datos puede alinearse.

- Título del artículo: A Minimalist Baseline for Text-to-Image Generation
- Blog técnico: https://peppaking8.github.io/#/post/minit2i
- Repositorio de código abierto: https://github.com/PeppaKing8/minit2i-jax
Enfoque técnico: Haciendo restas en cada paso
Salida directa en espacio de píxeles, sin VAE
La primera elección de diseño de MiniT2I es bastante radical: deshacerse del VAE y realizar el proceso de eliminación de ruido directamente sobre los píxeles RGB.
Los modelos de difusión latente (Latent Diffusion) son el paradigma principal actual, comprimiendo primero la imagen a un espacio de baja dimensión con un autoencoder antes de aplicar la difusión. Esto hace factible la alta resolución, pero a costa de introducir error de reconstrucción, una fase de entrenamiento adicional y un desajuste de objetivos entre el codificador y el desruidor.
La razón de MiniT2I para elegir el espacio de píxeles es pragmática: para una resolución de 512×512, usando patches de 16×16 se divide la imagen en 1024 tokens, una longitud de secuencia completamente dentro del rango cómodo de un Transformer. Eliminando el VAE, el cálculo de un paso hacia adelante se reduce de ~1379 GFLOPs a ~570 GFLOPs (configuración B/16), y no existe un límite superior en la precisión de reconstrucción — la calidad de la salida depende únicamente de la capacidad del desruidor.
Los experimentos también lo confirman: con el mismo presupuesto de parámetros, el FID del modelo en píxeles es comparable al del modelo en espacio latente (18.7 vs 19.0), pero el costo por paso es 5 veces menor.

Arquitectura MM-JiT: Regreso al Transformer sencillo
El MM-DiT de SD3 utiliza AdaLN (Adaptive Layer Normalization) en cada bloque para inyectar el paso de tiempo y la codificación de texto agrupada en la red — cada sub-bloque necesita calcular parámetros de escala, desplazamiento y compuerta, generados por un MLP adicional a partir del vector de condición. Es un mecanismo de modulación sofisticado, pero MiniT2I descubrió que no es estrictamente necesario.
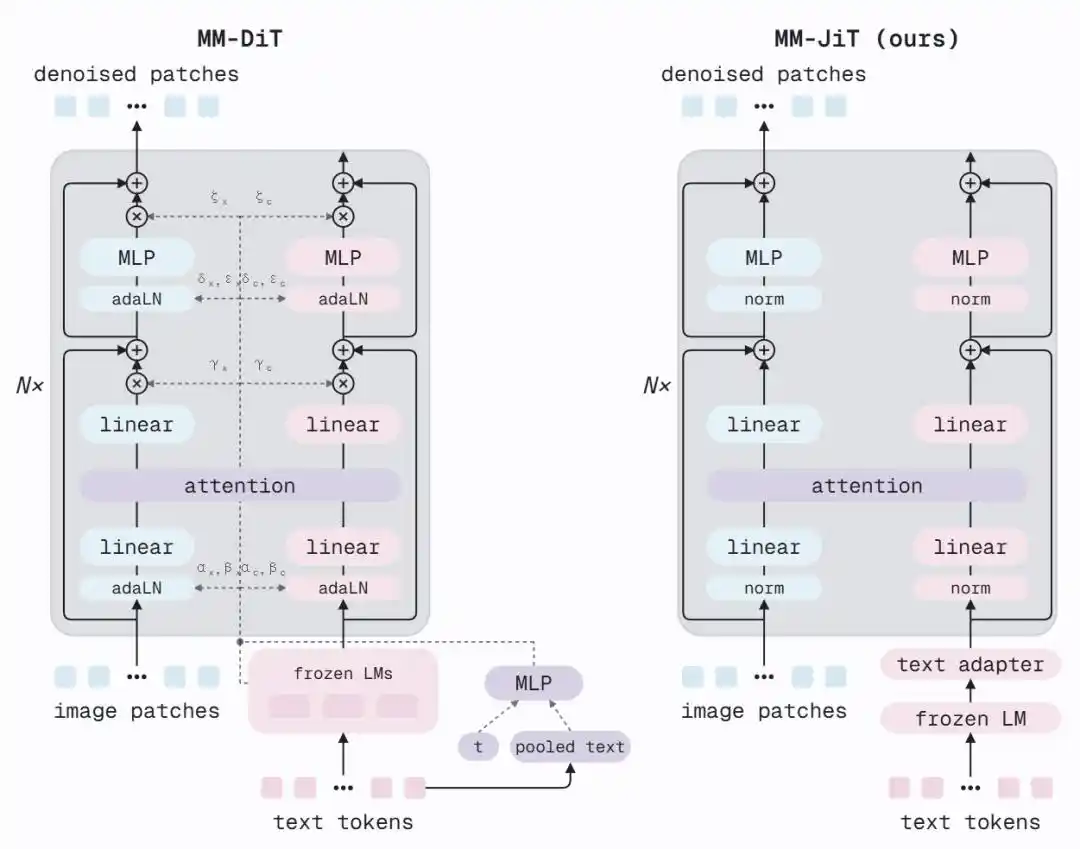
La arquitectura MM-JiT propuesta por MiniT2I hace dos cosas:
1. Añadir dos adaptadores de texto: Antes de la atención conjunta, inserta dos bloques Transformer ligeros, permitiendo que las características congeladas de T5 se "adapten" primero a las necesidades del desruidor.
2. Eliminar la rama AdaLN: Ya no se inyecta información del paso de tiempo y del texto global a través de una ruta adicional. El modelo aún puede percibir el nivel de ruido — porque la imagen contaminada con ruido en sí misma lleva información del paso temporal.
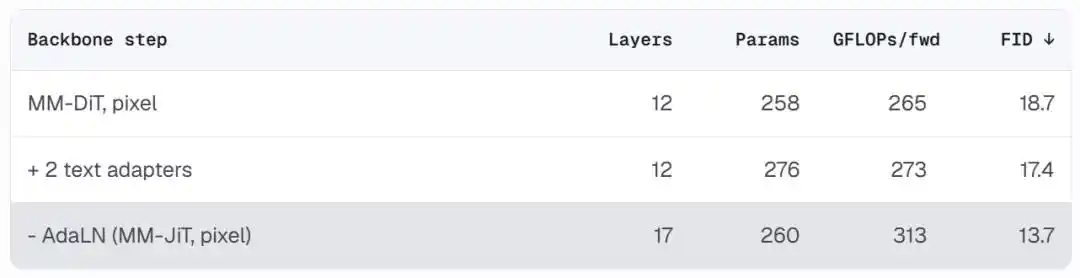
El resultado es una arquitectura limpia que se acerca a un Transformer estándar con pre-normalización. Eliminando AdaLN se reducen parámetros, permitiendo, con el mismo presupuesto computacional, más capas (12 capas → 17 capas). El FID baja de 18.7 a 13.7, y la arquitectura en sí misma es más fácil de entender y modificar.
Datos de entrenamiento: Todo público, dos fases
Los datos de entrenamiento de MiniT2I también buscan el minimalismo:
- Pre-entrenamiento: LLaVA-recaptioned CC12M (conjunto de datos reetiquetado por VLM, disponible públicamente), 250K pasos.
- Ajuste fino: ~120K pares de alta calidad imagen-texto (BLIP3o-60K + LAION DALL・E 3 Discord set + ShareGPT-4o-Image), 40K pasos.
Este modo de dos fases "pre-entrenamiento - ajuste fino" se alinea completamente con el paradigma de entrenamiento de los LLM: el pre-entrenamiento proporciona cobertura, el ajuste fino enseña al modelo qué es una buena respuesta. Ablaciones muestran que ambas son necesarias — solo pre-entrenamiento da calidad de imagen pero pobre seguimiento de indicaciones; solo ajuste fino hace que el modelo vea un mundo demasiado estrecho, colapsando la diversidad generativa.
Resultados: Modelo pequeño, gran rendimiento
En las comparaciones de texto a imagen en espacio de píxeles, la relación costo-rendimiento de MiniT2I es extremadamente destacada:
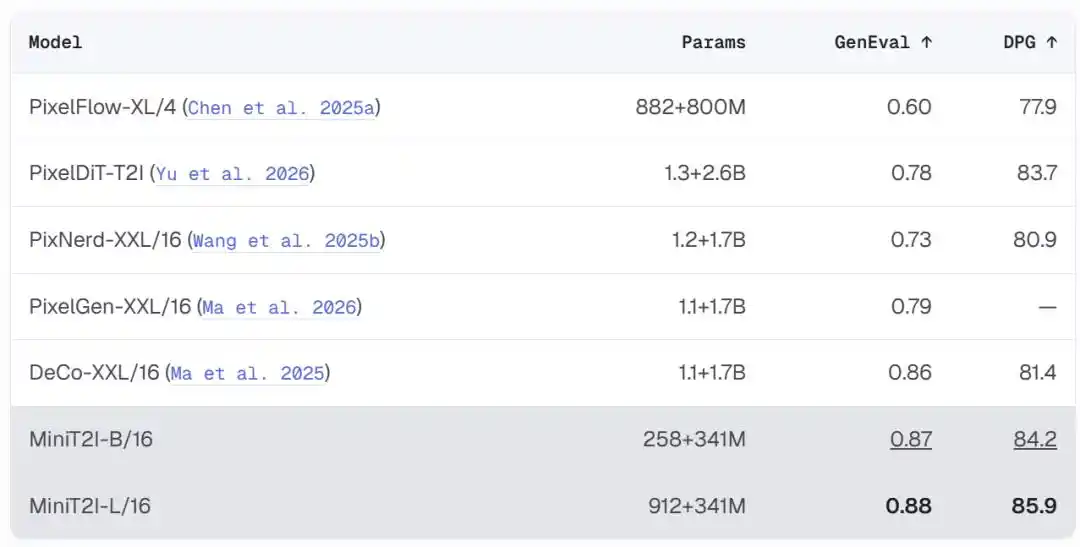
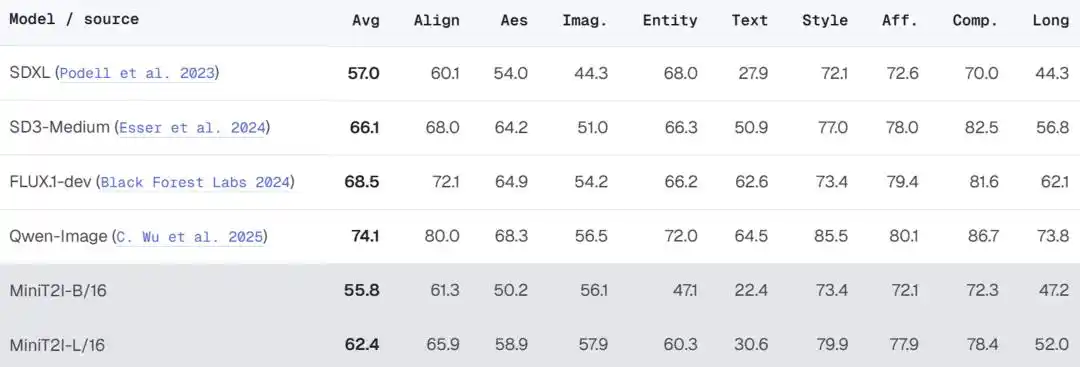
MiniT2I-B/16, con solo ~600M parámetros totales (incluyendo el codificador de texto), supera en GenEval y DPG-Bench a modelos con 3-4 veces más parámetros. Además, el costo de entrenamiento es muy bajo: el modelo de ablación B/32 requiere solo ~3 días en 8 H100s, con un total de FLOPs de entrenamiento comparable a un experimento estándar de ImageNet de 200 épocas.
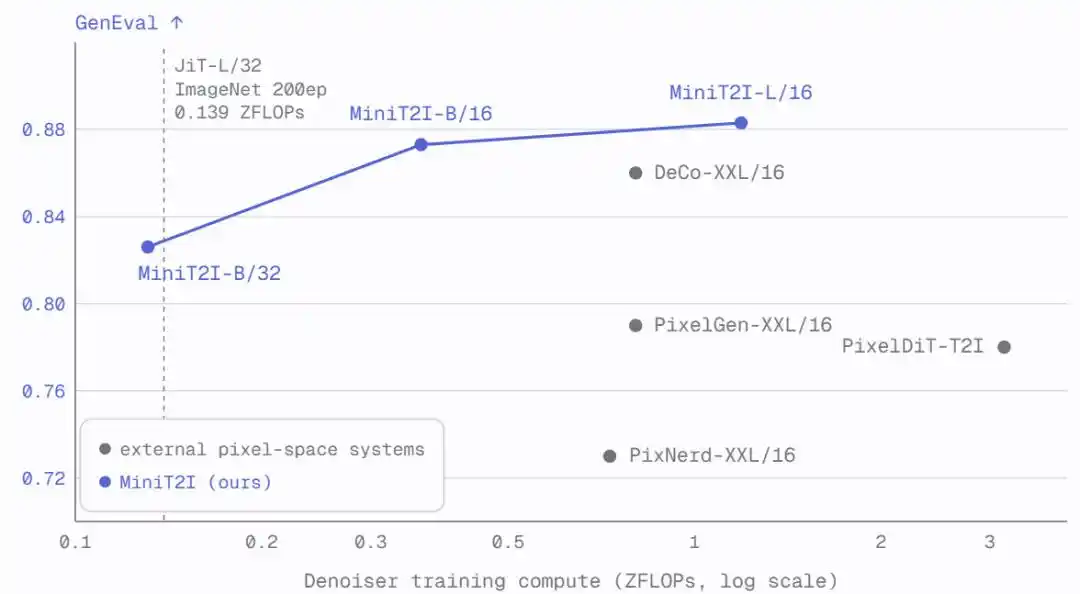
Al escalar a L/16 (912M parámetros), el modelo muestra mejoras evidentes en diversidad de estilos, relaciones espaciales y renderizado de texto, alcanzando o incluso superando la calidad de generación en escenas imaginativas de SD3-Medium (~2B parámetros).
En la evaluación más integral de PRISM-Bench, MiniT2I-L/16 sobresale en dimensiones de estilo, composición e imaginación (79.9, 78.4, 57.9), acercándose al nivel de SD3-Medium. Sin embargo, aún hay brecha en renderizado de texto (30.6 vs 50.9 de SD3) y entidades nombradas (60.3 vs 66.3) — el equipo reconoce que esta es una limitación inherente de la fórmula de datos públicos, requiriendo datos especializados adicionales para compensar.
Limitaciones y Perspectivas
MiniT2I es una prueba de concepto de una ruta técnica, no un producto final. El equipo señala honestamente varios problemas sin resolver:
- Artefactos de patch en espacio de píxeles: Existen discontinuidades medibles en los bordes de los patches (el gradiente en los bordes es 17-22% mayor que fuera de ellos), un problema que los modelos en espacio latente no tienen.
- Efectos secundarios de CFG en espacio de píxeles: Altos coeficientes de guía (~6) empujan los tokens locales fuera del manifold de datos, exponiéndose directamente como defectos visuales sin un decodificador que "suavice".
- Techo de resolución: Actualmente funciona bien en 512×512; escalar a 4K+ requiere secuencias más largas o mecanismos de atención más eficientes.
- Cuello de botella de datos: El renderizado de texto y las entidades nombradas siguen siendo más débiles que en sistemas industriales, requiriendo datos especializados de refuerzo.
MiniT2I demuestra que la generación de texto a imagen en su estado actual no es un juego solo para los mejores laboratorios industriales.
Cuando un modelo de 258M parámetros, usando solo datos públicos, entrenado durante 3 días con capacidad de cómputo a nivel académico, puede superar a oponentes órdenes de magnitud más grandes, quizás la generación de texto a imagen está experimentando una transición de paradigma de "acumulación" a "purificación".
"T2I ya no es un muro inalcanzable. Bienvenidos a usarlo y mejorarlo, para construir una línea base aún más simple."
Este artículo proviene del WeChat oficial account "机器之心" (El Corazón de la Máquina).







