Autor: Yanhua
Antonio Gullí es director de ingeniería en Google. Ha escrito un libro de 453 páginas que desglosa el desarrollo de Agentes de IA en 21 patrones de diseño.
Pero esto no es una reseña del libro. Mi motivación para leerlo era muy concreta: he escrito sobre Ingeniería de Contención (Harness Engineering), sobre la experiencia de superar obstáculos con Clawdbot, sobre "los agentes de IA no son magia" -esos siete puntos de inflexión desde quemar tokens hasta llegar a algo realmente útil-. Después de cada artículo, siempre me quedaba una pregunta sin resolver del todo: ¿hay una lógica subyacente reutilizable detrás de todo esto?
Este libro me dio la respuesta, y fue más profunda de lo que esperaba.
Puede que lo que estés escribiendo no sea un Agente
El juicio más contundente del libro está escondido en el prólogo.
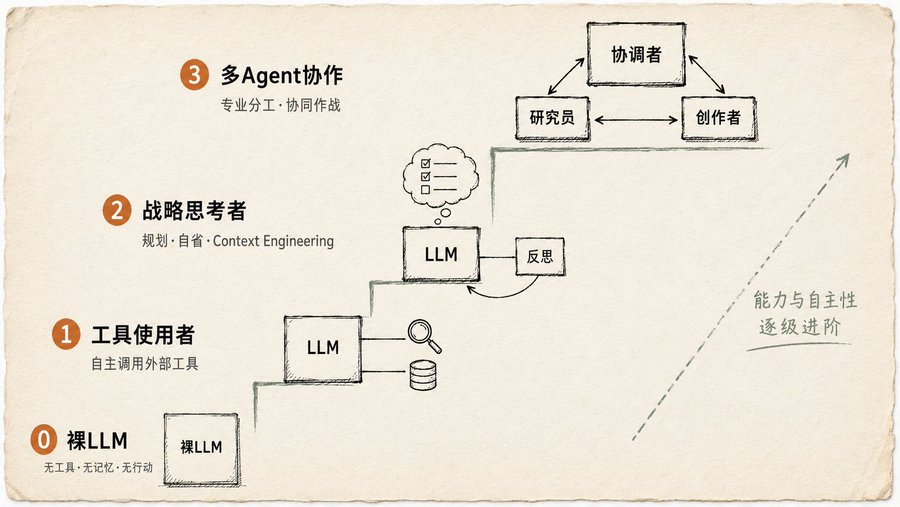
La "IA" que usa la mayoría de la gente es solo Nivel 0: un LLM desnudo, sin herramientas, sin memoria, sin capacidad de acción. Le preguntas qué película ganó el Óscar en 2025, y adivina. El libro lo dice sin rodeos: las cosas de Nivel 0 no son Agentes.
Subir de nivel es lo que hace a un verdadero Agente:
-
Nivel 1: Usuario de herramientas
El Agente comienza a usar herramientas: búsqueda, API, bases de datos. Pero no es solo que "pueda llamar a una interfaz", sino que debe juzgar por sí mismo cuándo llamarla, a qué llamar y cómo usar el resultado. El libro da un ejemplo muy concreto: un usuario pregunta "¿qué series nuevas hay?", y el Agente se da cuenta por sí mismo de que esta información no está en sus datos de entrenamiento, activa la herramienta de búsqueda para encontrarla y luego sintetiza el resultado. El paso clave está en "darse cuenta por sí mismo". No es que un humano le diga "ve a buscar", es él quien juzga que necesita buscar. Esta capacidad de juicio es el umbral del Nivel 1.
-
Nivel 2: Pensador estratégico
Añade dos cosas más: planificación e Ingeniería de Contexto (Context Engineering). El libro define la Ingeniería de Contexto: no se trata de amontonar información, sino de filtrar, recortar y empaquetar cuidadosamente el contexto. El ejemplo es ingenioso: un usuario quiere encontrar una cafetería entre dos lugares. El Agente primero llama a una herramienta de mapas para obtener un montón de datos, luego juzga por sí mismo que "el siguiente paso solo necesita nombres de calles", recorta la salida del mapa en una lista corta y la pasa a la herramienta de búsqueda local. En cada paso está reduciendo el ruido de la información.
Hay una frase en el libro que leí varias veces: "Para que la IA alcance la máxima precisión, se le debe dar un contexto corto, enfocado y potente." La Ingeniería de Contexto se encarga precisamente de esto.
En este nivel, el Agente también puede reflexionar sobre sí mismo. Después de terminar un trabajo, se revisa a sí mismo, identifica problemas y los corrige. Hablaré de esto en detalle más adelante.
-
Nivel 3: Colaboración entre múltiples Agentes
La postura del libro es clara: deja de pensar en crear un superagente todopoderoso. El enfoque realmente confiable es construir un equipo: Agente gestor de proyectos + Agente investigador + Agente diseñador + Agente redactor. El ejemplo del libro es el lanzamiento de un nuevo producto: un "Agente gestor de proyectos" hace la coordinación general, asignando tareas al "Agente de investigación de mercado", "Agente de diseño de producto" y "Agente de marketing". La clave es la comunicación: cómo se transmiten los datos entre Agentes, cómo se sincronizan los estados, cómo se manejan los conflictos. Este capítulo dibuja seis estructuras de topología de comunicación, desde el Agente único más simple hasta el híbrido personalizado más flexible, cada una con una explicación sobre qué escenarios son adecuados.
Después de ver estos cuatro niveles, de repente entendí por qué mucha gente dice "mi Agente no funciona bien". El modelo no es el problema, el problema es que lo estás usando como un chatbot, es posible que ni siquiera haya alcanzado el Nivel 1.
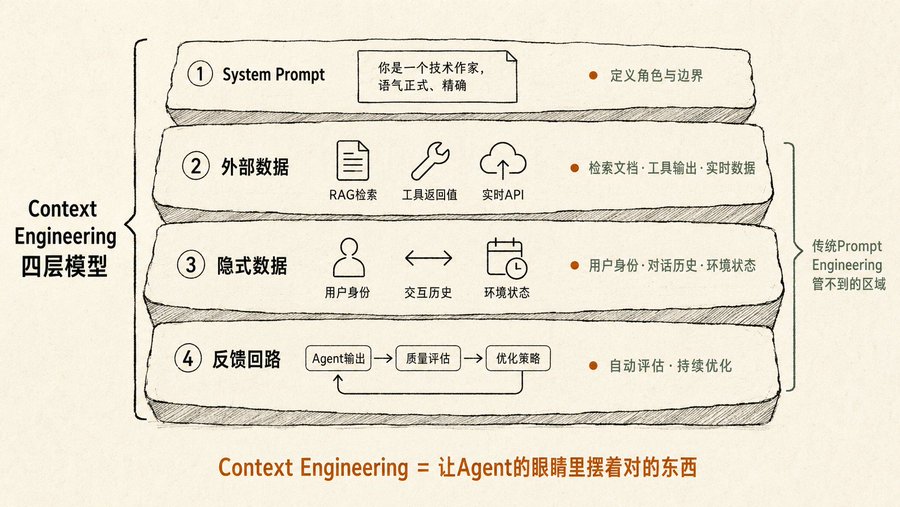
Ingeniería de Contexto: el concepto más subestimado del libro
Escribí un artículo sobre Ingeniería de Contención (Harness Engineering), que decía que el diseño de la pista es más importante que la potencia del motor. Después de leer este libro, me di cuenta de que la Ingeniería de Contexto es la proyección de la Ingeniería de Contención a nivel de prompt.
La Ingeniería de Prompts tradicional solo se ocupa de "cómo preguntas". La Ingeniería de Contexto del libro se ocupa de "qué tiene delante el Agente antes de preguntar". Incluye cuatro capas de información:
-
Primera capa, system prompt. Define quién es el Agente, qué tono usa, qué límites tiene. La mayoría de la gente solo escribe esta capa.
-
Segunda capa, datos externos. Documentos recuperados por RAG, valores devueltos por llamadas a herramientas, datos de API en tiempo real. Aquí es donde la mayoría se atasca: saben que hay que alimentar con datos, pero no saben cómo hacerlo sin abrumar al modelo.
-
Tercera capa, datos implícitos. Identidad del usuario, historial de interacciones, estado del entorno. Cosas que no dices explícitamente pero que el Agente debería saber. Por ejemplo, si le dices al Agente "ayúdame a enviar un correo a John para confirmar la reunión de mañana", debería saber qué reunión tienes mañana en tu calendario y cuál es tu relación con John.
-
Cuarta capa, bucle de retroalimentación. Después de cada salida del Agente, evalúa automáticamente la calidad y ajusta la estrategia de contexto para la siguiente vez. El libro lo llama "optimización de contexto automatizada", y el Vertex AI Prompt Optimizer de Google es la implementación ingenieril de esta idea.
Cuando llegué a esta parte, recordé el artículo que escribí antes, "los agentes de IA no son magia", donde una de las experiencias era "tu agente necesita reglas, y muchas". Mirando atrás, esas reglas eran esencialmente la versión manual de la Ingeniería de Contexto; el libro la ha sistematizado.
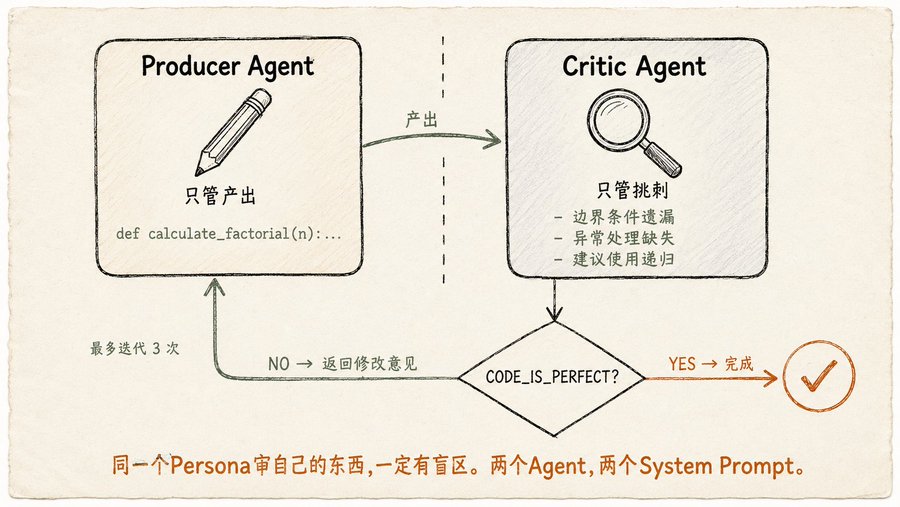
Reflexión (Reflection): dos Agentes realmente son mejores que uno
Este es el Patrón con mayor valor práctico del libro para mí.
El núcleo de la Reflexión es simple: después de que el Agente termina un trabajo, se revisa a sí mismo, identifica problemas y los corrige. Pero la forma de implementarlo tiene sus matices. El libro lo dice claramente: el Productor (Producer) y el Crítico (Critic) deben ser dos Agentes diferentes, con diferentes system prompts. La misma persona revisando su propio trabajo siempre tendrá puntos ciegos. Si le pides al mismo LLM que primero escriba código y luego revise su propio código, lo más probable es que diga "está bien".
El libro da un ejemplo de código completo.
-
El prompt del Productor es "Eres un desarrollador Python, escribe una función para calcular factoriales, maneja condiciones límite y excepciones".
-
El prompt del Crítico es "Eres un ingeniero senior meticuloso, revisa el código línea por línea, verifica bugs, estilo, condiciones límite omitidas, áreas de mejora. Si es perfecto, devuelve
CODE_IS_PERFECT, de lo contrario, enumera todos los problemas". -
Luego hay un bucle for: Productor escribe código → Crítico revisa → Productor modifica según los comentarios → Crítico revisa nuevamente → hasta que el Crítico diga
CODE_IS_PERFECTo se alcance el número máximo de iteraciones.
Así de simple. Pero el libro advierte sobre un problema de coste que se pasa por alto fácilmente: cada ciclo de reflexión es una nueva llamada al LLM, cuantas más iteraciones, más caro. Además, a medida que el historial de la conversación se infla, la ventana de contexto se llena con versiones anteriores y comentarios críticos, reduciendo el espacio de razonamiento realmente disponible. Por lo tanto, la mejor práctica para la Reflexión es: establecer un número máximo razonable de iteraciones (el libro usa 3), detenerse una vez que el Crítico esté satisfecho, no buscar la perfección.
Los usos van mucho más allá de escribir código. Escribir artículos, hacer planes, resumir documentos, resolver problemas lógicos, el modelo Productor-Crítico se puede aplicar a todo. El libro enumera siete escenarios de aplicación, la lógica central es la misma: primero producir, luego revisar, después corregir.
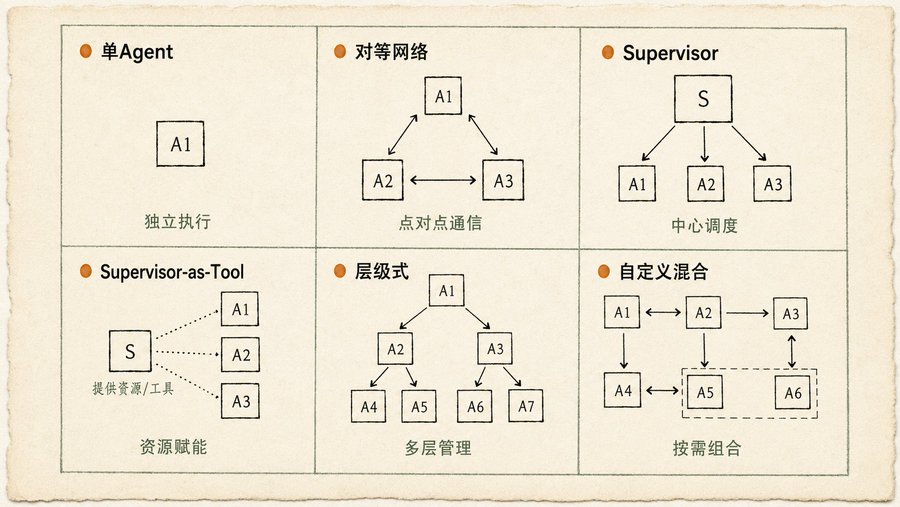
Multi-Agent: cuánto más complejo, mejor, no siempre es así
Lo que más me gusta del capítulo de Colaboración Multi-Agent son esos seis diagramas de topología de comunicación. Mucha gente empieza con algo complejo, pero en realidad, para la mayoría de los escenarios, tres son suficientes:
-
Agente único (ejecución independiente): la tarea se puede dividir en subproblemas independientes, cada Agente resuelve el suyo. Simple, fácil de mantener.
-
Red punto a punto (Peer-to-Peer): los Agentes se comunican directamente entre sí, sin nodo de control central. Descentralizado, buena tolerancia a fallos, si un Agente falla no afecta al global. Pero el coste de coordinación es alto, puede descontrolarse fácilmente.
-
Supervisor (coordinación central): un Agente Supervisor gestiona un grupo de Agentes Trabajadores. Asigna tareas, recoge resultados, resuelve conflictos. Jerarquía clara, fácil de gestionar. Pero el Supervisor es un punto único de fallo y también un cuello de botella de rendimiento.
Los otros tres (Supervisor-como-Herramienta, jerárquico, híbrido personalizado) son variantes y combinaciones de los tres primeros. El libro es muy realista: la topología que necesitas depende de la complejidad de tu tarea. Cuanto más se fragmenta la tarea, mayor es el coste de comunicación, hasta cierto punto, el modo Supervisor es más eficiente que el jerárquico.
Mi impresión es que mucha gente, al construir un sistema Multi-Agent, dedica el 80% del tiempo al protocolo de comunicación, olvidándose de hacer una pregunta más básica: ¿realmente esta tarea necesita múltiples Agentes? El libro lo deja muy claro: un Agente único de Nivel 2 + Reflexión suele ser suficiente. El Nivel 3 está preparado para aquellos escenarios que un solo Agente realmente no puede manejar.
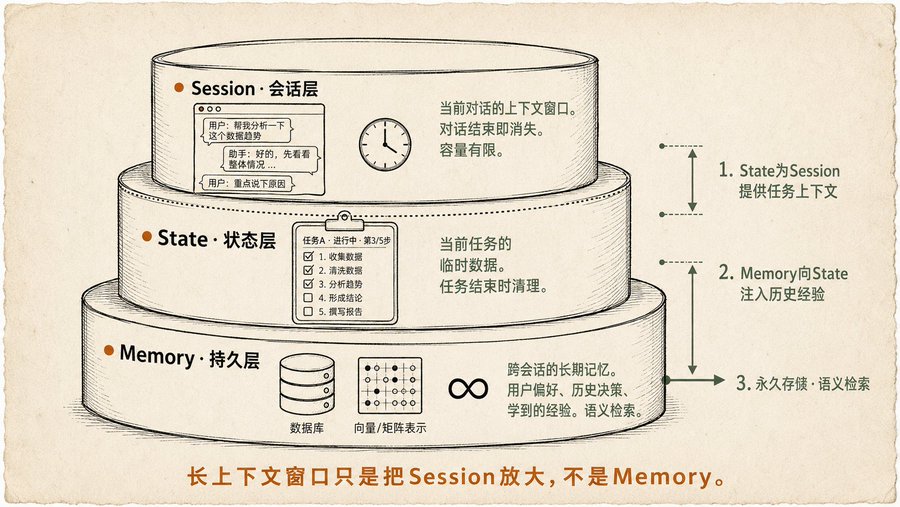
Modelo de tres capas para la Memoria: lo había intuido vagamente pero no le había puesto nombre
El capítulo sobre Memoria fue con el que más me identifiqué, porque cuando escribía esos dos artículos sobre Obsidian + Claude, siempre me preguntaba: ¿cómo debería estar estratificada la memoria de un Agente?
El libro da la respuesta:
-
Sesión (capa de sesión): la ventana de contexto de la conversación actual. Es la memoria más corta, desaparece al terminar la conversación. Los modelos de contexto largo solo amplían esta ventana, pero en esencia sigue siendo temporal, y cada vez que se razona hay que procesar toda la ventana, lo cual es caro y lento.
-
Estado (capa de estado): datos temporales durante la ejecución de la tarea actual. Por ejemplo, "en qué tarea se está trabajando", "hasta dónde se ha llegado", "qué datos intermedios se han generado". Más larga que la Sesión, pero se limpia al terminar la tarea. El libro utiliza el mecanismo State de Google ADK para dar un ejemplo completo.
-
Memoria (capa persistente): memoria a largo plazo, entre sesiones y entre tareas. Preferencias del usuario, experiencias aprendidas, decisiones históricas importantes, almacenadas en una base de datos o un vector store, con recuperación semántica. El libro enfatiza un punto muy importante: la Memoria no es solo almacenar, sino diseñar toda una estrategia de "qué almacenar, cuándo almacenar, cómo recuperar". Almacenar demasiado introduce mucho ruido, almacenar muy poco no es suficiente.
En mi artículo anterior sobre Clawdbot, mencioné el "archivo de estado" y los "documentos del área de trabajo", que esencialmente eran una implementación manual de la capa de Estado y la capa de Memoria; el libro ha enmarcado esto.
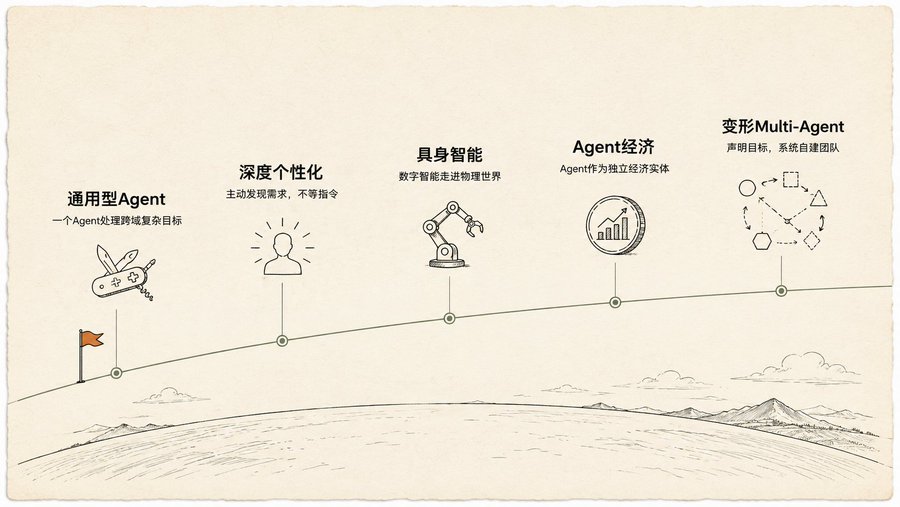
Cinco hipótesis, la quinta es la más descabellada
Al final del libro se plantean cinco hipótesis sobre el futuro de los Agentes. Las primeras cuatro están dentro de una extrapolación razonable: Agentes de propósito general que pasan de escribir código a gestionar proyectos, personalización profunda que descubre activamente tus necesidades, inteligencia corpórea (embodied) que sale de la pantalla al mundo físico, Agentes como entidades económicas independientes.
La quinta me dejó pasmado: Multi-Agent con capacidad de metamorfosis (Morphing Multi-Agent).
Solo declaras el objetivo, por ejemplo, "crear un negocio de comercio electrónico de café gourmet". El sistema decide automáticamente: primero crear un "Agente de investigación de mercado" y un "Agente de marca". Después de ejecutar una ronda de datos, juzga por sí mismo que el Agente de marca ya no es necesario, lo divide en tres nuevos: "Agente de diseño de logo", "Agente de creación de sitio web", "Agente de cadena de suministro". Si el Agente de creación del sitio web se convierte en un cuello de botella, el sistema automáticamente lo replicará en tres Agentes paralelos que trabajen simultáneamente en diferentes páginas. Durante todo el proceso, el sistema optimiza continuamente el prompt de cada Agente y reorganiza constantemente la arquitectura del equipo.
El libro lo llama "sistema multi-agente impulsado por objetivos y con capacidad de auto-transformación". No está ejecutando un plan que tú escribiste, está generando su propio plan, ajustando su propio plan, reorganizando su propio equipo de ejecución.
Esto me recordó a AutoResearch de Karpathy: escribes un program.md, defines objetivos, métricas, límites, y pulsas "iniciar". El humano está fuera del bucle. Pero este libro va más allá: incluso cómo se forma y reorganiza el equipo de Agentes, se deja en manos del propio sistema. El humano solo declara "qué quiere".
Tres cosas que puedes hacer inmediatamente
Después de leer este libro, tengo tres acciones que se pueden implementar de inmediato:
-
Primero, añade un Crítico a tu Agente actual. Ya sea que uses Claude Code, CrewAI o tu propio framework, añade un paso al final de tu flujo de trabajo actual: haz que otro Agente (con un system prompt diferente) revise la salida del paso anterior. Generación de código más revisión de código, redacción de artículos más verificación de hechos, elaboración de planes más evaluación de viabilidad. Es una llamada más al LLM, pero la mejora en calidad suele duplicarse. El patrón Productor-Crítico del libro es plug-and-play.
-
Segundo, empieza a hacer Ingeniería de Contexto, no solo Ingeniería de Prompts. Revisa los archivos de instrucciones que escribes para tu Agente. Si están llenos de reglas de "cómo debes hacerlo" y carecen del contexto de "a qué te enfrentas ahora", añádelo. Dile al Agente en qué proyecto está, qué decisiones tomó antes, cuáles son las preferencias del usuario. El capítulo de Ingeniería de Contexto del libro y tu
AGENTS.mdson dos expresiones de la misma cosa. -
Tercero, no te precipites en implementar Multi-Agent. Lleva tu Agente único al Nivel 2 primero: con herramientas, con Reflexión, con Memoria. El libro enfatiza repetidamente que un Agente único de Nivel 2, más el modelo Productor-Crítico y la Ingeniería de Contexto, puede cubrir la gran mayoría de los escenarios prácticos. El Nivel 3 está preparado para tareas verdaderamente interdisciplinares, multifase, que requieren división de trabajo en paralelo. El problema de la mayoría no es que no tengan suficientes Agentes, es que no han ajustado bien ni un solo Agente.
Este libro tiene 453 páginas, publicado por Springer en 2025. Los ejemplos de código cubren LangChain/LangGraph, Google ADK, CrewAI, OpenAI API. El prólogo está escrito por el VP de AI de Google Cloud, y hay un prólogo de recomendación del CIO de Goldman Sachs, sorprendentemente interesante de leer.
Pero la razón por la que lo recomiendo no es que sea "completo". Es que después de leerlo te darás cuenta de algo: los obstáculos que has encontrado con los Agentes en los últimos seis meses, alguien los ha organizado en patrones. No necesitas reinventar la Reflexión, no necesitas adivinar cómo estratificar la Memoria, no necesitas probar qué topología de comunicación usar para Multi-Agent.
Alguien ha dibujado el mapa por ti, lo único que queda es caminar.
¿Estás desarrollando con Agentes de IA? ¿En qué Nivel está tu Agente actual?





