Hace unos días, Anthropic publicó un artículo titulado "When AI Builds Itself" (Cuando la IA se construye a sí misma), que rápidamente desató un amplio debate. El artículo reveló un conjunto de datos internos sorprendentes: hasta mayo de 2026, más del 80% del código base de Anthropic había sido escrito por Claude, y la cantidad de código que los ingenieros fusionaban diariamente era 8 veces mayor que en 2024; en una prueba interna, Claude mejoró la velocidad de ejecución de un fragmento de código de entrenamiento aproximadamente 52 veces respecto a la referencia, mientras que un investigador humano experimentado normalmente necesitaría entre 4 y 8 horas para lograr una aceleración de 4 veces.
Anthropic apunta esta trayectoria hacia un destino más profundo: "automejora recursiva" — sistemas de IA que diseñan, construyen y entrenan autónomamente sus propias versiones sucesoras, sin que el humano conduzca cada paso. Cabe destacar que la compañía también hizo un llamado a la coordinación de la industria, para tener la opción de pausar o incluso detener temporalmente el desarrollo de IA de vanguardia cuando llegue el momento de la automejora recursiva. Y Anthropic ya está haciendo esto: limitando el uso de su último Claude Fable 5 para la investigación de IA de vanguardia.
Y ahora, Recursive Superintelligence anuncia que ha dado el primer paso hacia la investigación de IA automatizada.
Esta nueva compañía cofundada por Tianyuandong salió del modo sigilo hace apenas un mes, y ya ha publicado su primer resultado técnico público. Han creado un sistema abierto de descubrimiento automatizado de conocimiento y han logrado resultados SOTA en tres benchmarks. En pocas palabras, han conseguido que una IA ejecute experimentos por ti.

https://x.com/tydsh/status/2065062838255649082
Primer resultado: que la IA ejecute experimentos por ti
Este primer resultado técnico público de Recursive se llama "First Steps Toward Automated AI Research" (Primeros pasos hacia la investigación de IA automatizada).

Tweet: https://x.com/Recursive_SI/status/2064980090702962699
Repositorio: https://github.com/recursive-org/first-steps-toward-automated-ai-research
Blog: https://www.recursive.com/articles/first-steps-toward-automated-ai-research
Si se resume en una frase, el núcleo de este trabajo es: construir un sistema capaz de avanzar autónomamente en el ciclo de investigación de IA, y establecer nuevos récords en tres pruebas de referencia.
Antes de desglosar el resultado, es necesario entender la lógica de diseño de este sistema.
El flujo tradicional de investigación de IA es un ciclo cerrado altamente dependiente del humano: "concebir una idea — escribir código — ejecutar experimento — analizar resultados — concebir otra idea". Su cuello de botella de eficiencia no está en la potencia de cálculo, sino en las personas. Los investigadores capaces de diseñar flujos de entrenamiento de vanguardia en el mundo se cuentan con los dedos de una mano, y cada iteración experimental requiere su profunda intervención.
El sistema de Recursive intenta automatizar este ciclo cerrado.
Su modo de trabajo es: para un objetivo de optimización claro, el sistema propone automáticamente ideas de experimentos, implementa el código, ejecuta la verificación, aprende de ello y luego decide cómo buscar en el siguiente paso. Múltiples líneas de investigación pueden avanzar en paralelo, los descubrimientos efectivos pueden reutilizarse entre tareas, y los mecanismos de detección de "reward hacking" (trampa de recompensas) están integrados en todo el ciclo para evitar que el sistema "tome atajos" e infla las métricas de evaluación sin realmente mejorar nada.
No es una herramienta especializada ajustada para un único problema, sino un marco general de automatización de investigación transversal. Recursive usa tres escenarios de prueba muy diferentes para demostrar esto.
Tres campos de batalla, tres nuevos récords
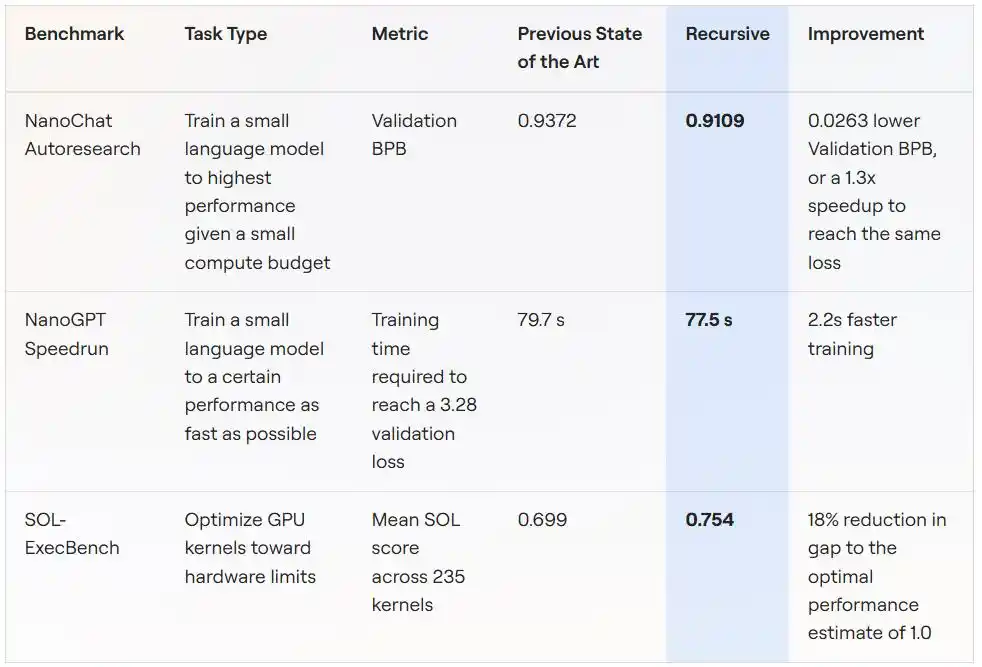
Escenario 1: Entrenamiento de modelos pequeños con presupuesto computacional fijo (NanoChat Autoresearch)
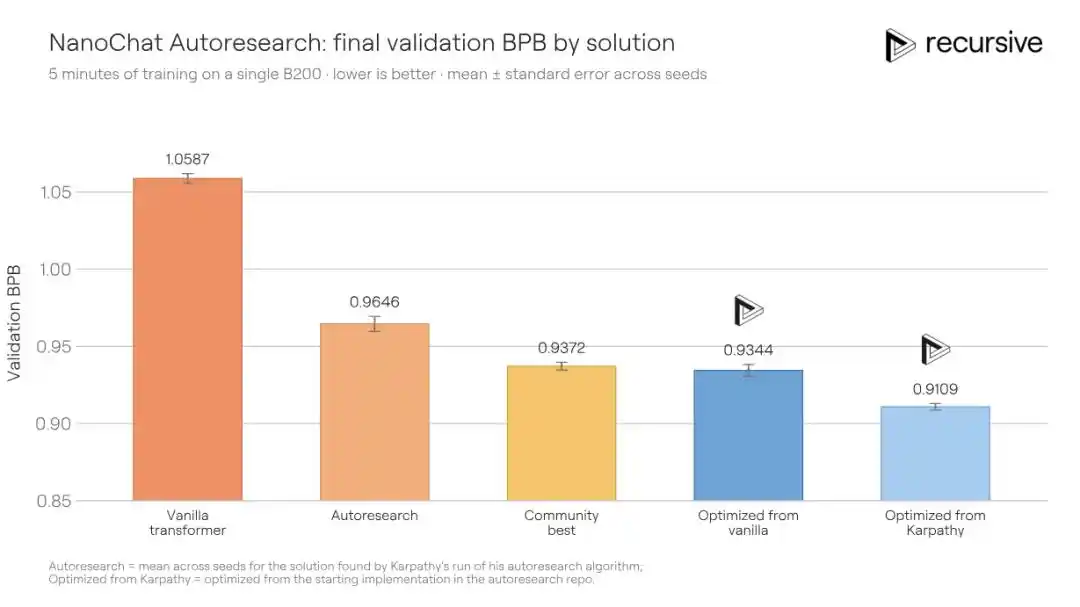
Las reglas de esta prueba de referencia provienen del proyecto autoresearch iniciado por Andrej Karpathy (autor de GPT-2, ex cofundador de OpenAI): en una sola GPU, con un presupuesto de entrenamiento fijo de cinco minutos, entrenar un modelo de lenguaje pequeño para lograr la menor pérdida de validación posible (medida en BPB, cuanto más baja, mejor).
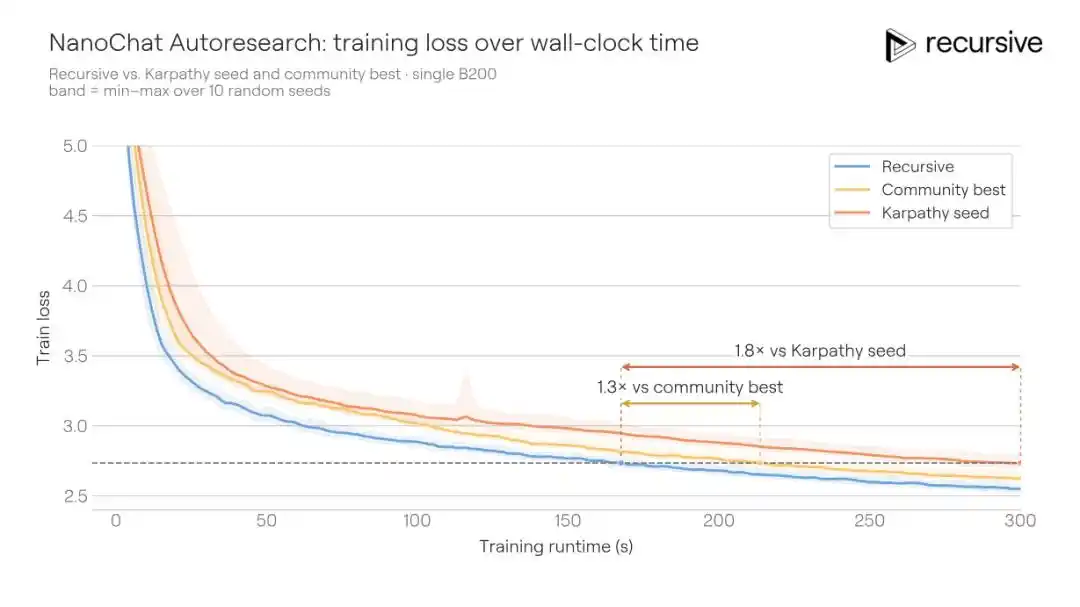
Este escenario es naturalmente adecuado para la investigación automatizada: ciclos experimentales cortos, baja varianza en las métricas, comportamiento tramposo relativamente fácil de detectar. Precisamente por eso, un proyecto comunitario llamado "autoresearch@home" ha estado ejecutándose en este benchmark durante mucho tiempo — docenas de investigadores humanos junto con cientos de agentes de IA colaborando, empujando continuamente la métrica hacia abajo.
El sistema de Recursive, partiendo del mismo código inicial, finalmente mejoró el BPB de validación del mejor comunitario, 0.9372, a 0.9109, una mejora de 0.0263 BPB. Dicho de otra manera: para la misma calidad de entrenamiento, la solución de Recursive requiere 1.3 veces menos tiempo de entrenamiento que la de sus rivales.
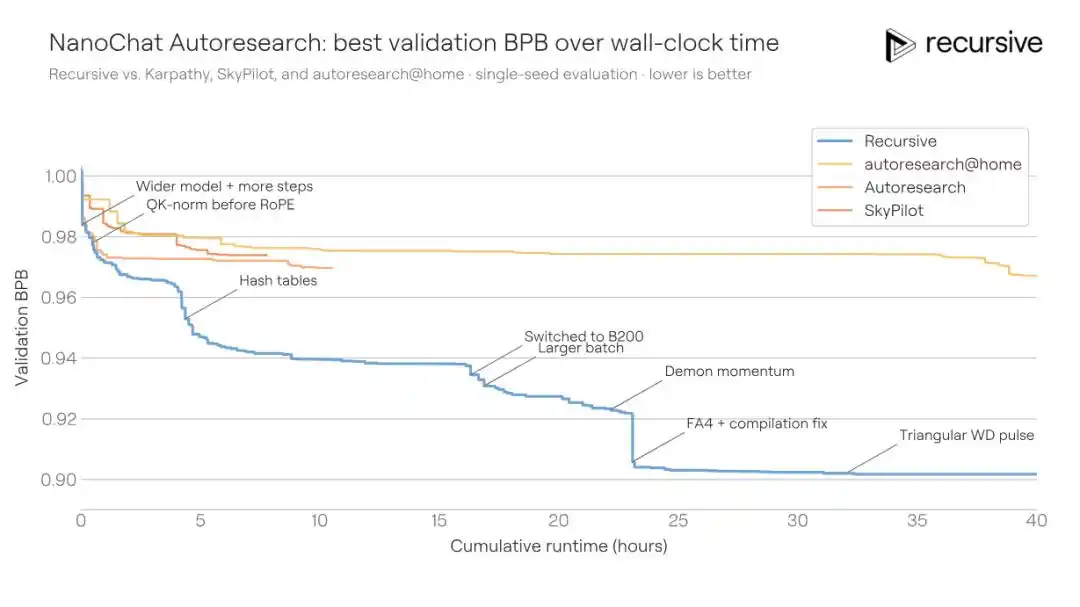
Las mejoras descubiertas por el sistema no fueron un solo golpe maestro. Combinó ajustes de arquitectura, pérdidas auxiliares, modificaciones al mecanismo de atención, comportamiento del optimizador, programación del decaimiento de pesos, configuraciones del compilador y más. Uno de los descubrimientos clave fue un mecanismo de memoria de contexto corto más rico: en la ruta de "value" de la atención, se incrustaron simultáneamente información de bigram (pares de palabras adyacentes) y trigram (tríos) mediante tablas hash, utilizando una compuerta aprendible para ponderar la mezcla. Diferentes capas del Transformer usaban diferentes funciones hash, reduciendo así la probabilidad de colisiones repetidas entre capas.
Este truco está conceptualmente relacionado con trabajos como DeepSeek Engram, pero el sistema lo desplegó en el escenario de presupuesto fijo como una variante específica que no se había visto en la literatura pública.
Escenario 2: Carrera de velocidad extrema en entrenamiento (NanoGPT Speedrun)
Si el escenario anterior fue "dar un paso más" sobre los resultados de una comunidad activa, este es mucho más difícil.
NanoGPT Speedrun es otro benchmark iniciado por Karpathy y optimizado continuamente por la comunidad durante más de dos años: el tiempo mínimo requerido para entrenar un modelo GPT hasta una pérdida de validación de 3.28 en 8 GPUs H100. Desde mediados de 2024, la comunidad ya ha comprimido el tiempo de aproximadamente 45 minutos a 79.7 segundos a través de 83 contribuciones registradas. Cada nueva solución necesita exprimir tiempo sobre un código ya extremadamente optimizado, lo que es increíblemente difícil.
El sistema de Recursive, partiendo de la solución óptima existente, comprimió nuevamente el tiempo de entrenamiento a 77.5 segundos, ahorrando 2.2 segundos. Esto es comparable o incluso mejor que lo que los contribuyentes humanos recientes han logrado.
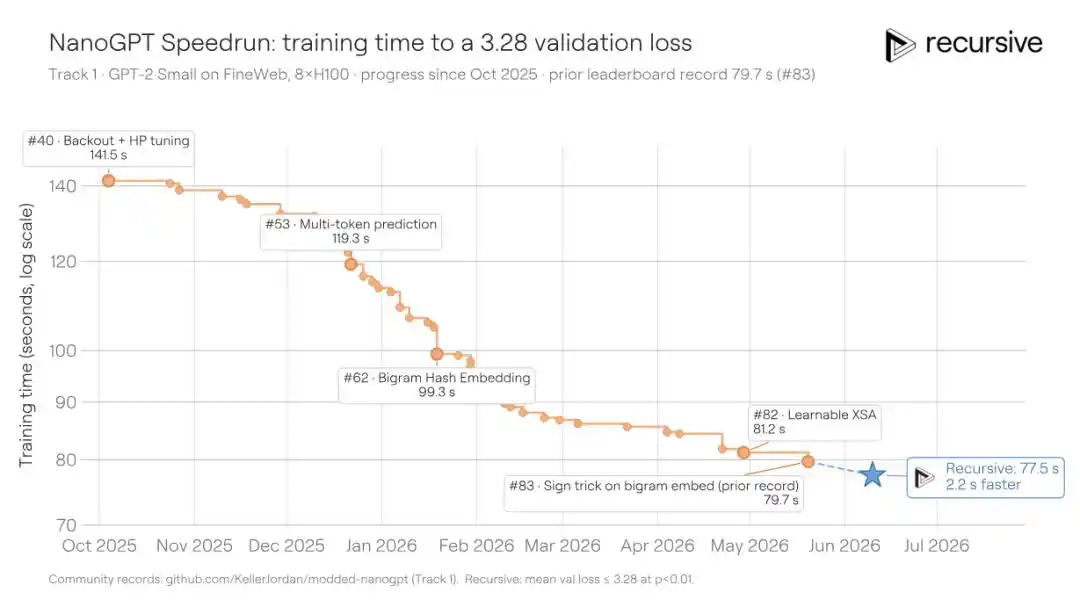
Los trucos centrales que el sistema encontró esta vez incluyen:
Cálculo de atención con precisión FP8. La solución comunitaria solo usaba FP8 (coma flotante de 8 bits) en la última capa del modelo (la cabecera del modelo de lenguaje), mientras que el sistema extendió FP8 a los cálculos matriciales de la capa de atención, usando FP8 en la propagación hacia adelante para obtener el doble de rendimiento de los Tensor Cores, y manteniendo BF16 en la propagación hacia atrás para preservar la estabilidad.
Ruido de exploración con recocido en el optimizador. El sistema inyectó ruido gaussiano de media cero en los pasos de actualización del optimizador NorMuon, con la amplitud del ruido disminuyendo linealmente a cero a medida que avanzaba el entrenamiento. Esto es similar a dar al optimizador un patrón de comportamiento de "explorar audazmente primero, converger robustamente después", ayudando a que la solución final caiga en una cuenca de pérdida más plana.
Un núcleo MLP fusionado más compacto. El sistema reescribió un kernel de GPU Triton, haciendo que la propagación hacia adelante solo almacenara los valores de activación después de ReLU al cuadrado, y que durante la propagación hacia atrás, los resultados intermedios no cuadrados se recalculen dentro del propio kernel, ahorrando un viaje completo de lectura/escritura del tensor de activaciones en la memoria de alto ancho de banda — esto es una aceleración directa a nivel de hardware.
Tres mejoras, pertenecientes a tres áreas especializadas diferentes: estrategia de precisión, diseño de optimizador y programación de kernels de GPU. Que el sistema haya encontrado espacio para mejorar sobre dos años de optimización comunitaria habla por sí mismo.
Escenario 3: Optimización de kernels de GPU (SOL-ExecBench)
Los dos primeros escenarios trabajaban a nivel de entrenamiento de modelos, el tercero se adentra más profundo: optimización de kernels de computación de GPU.
SOL-ExecBench es un benchmark lanzado por NVIDIA, que contiene 235 tareas de escritura de kernels, cubriendo múltiples tipos de carga de trabajo real como multiplicación de matrices, reducción, capas de normalización, componentes de atención, rutinas de cuantización, bloques fusionados, etc. El criterio de puntuación es la puntuación SOL: 0.5 corresponde a la implementación de referencia de PyTorch, 1.0 corresponde al límite teórico del hardware. El mejor resultado público anterior era 0.699.
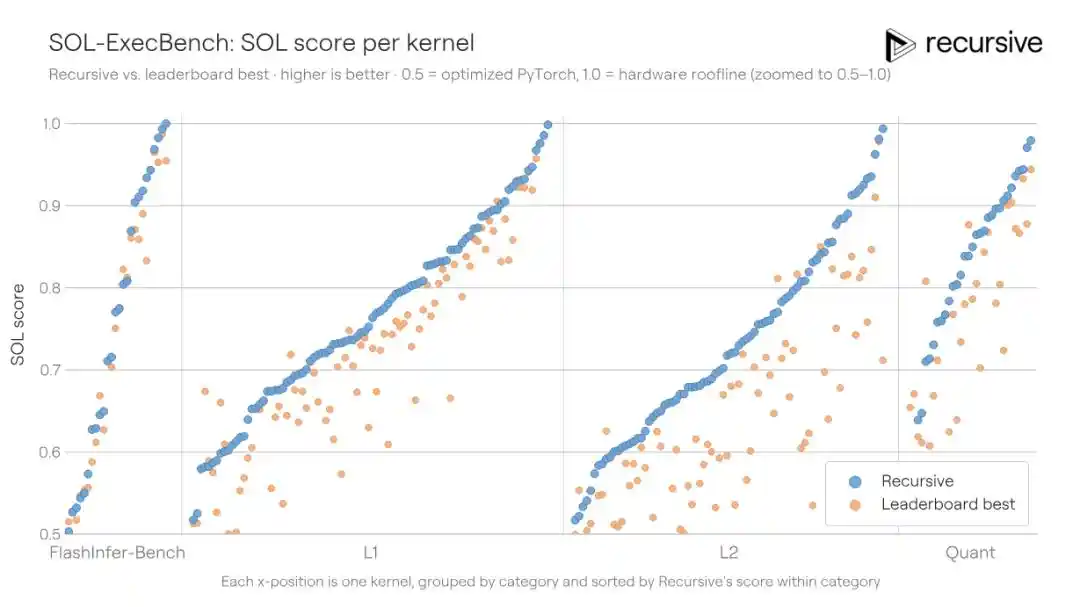
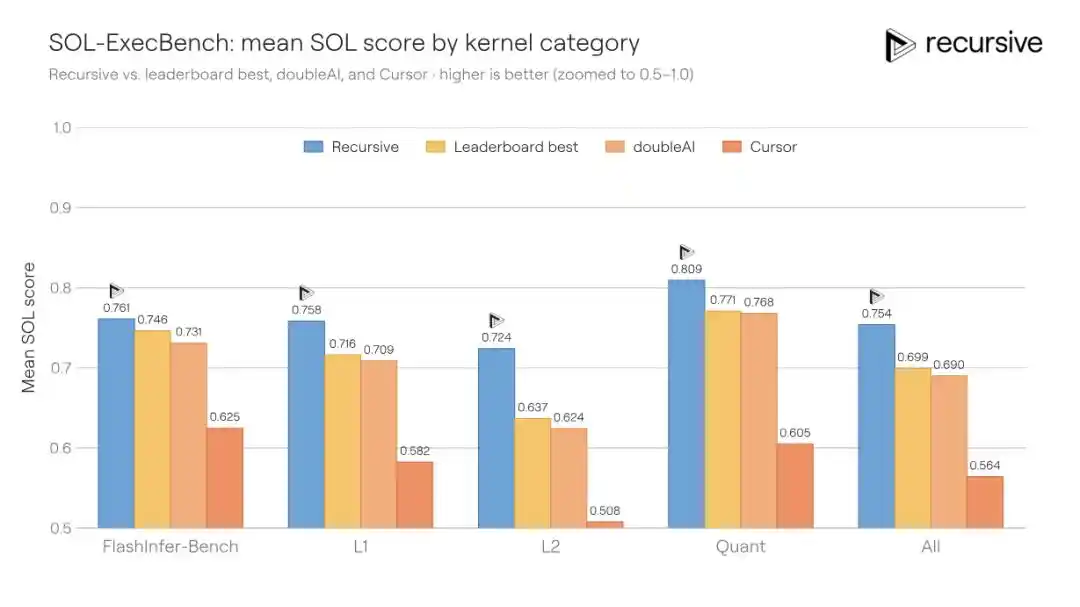
El sistema de Recursive se ejecutó en los 235 kernels, permitiendo la reutilización de patrones de optimización descubiertos entre tareas (por ejemplo, estrategias de movimiento de memoria, métodos de bloqueo, técnicas de reducción), y finalmente elevó la puntuación a 0.754, reduciendo la brecha con el límite teórico del hardware en un 18%.
Este escenario es especial porque la ingeniería de kernels es un campo altamente especializado — los ingenieros que pueden escribir kernels Triton/CUDA eficientes también son extremadamente raros a nivel global. Y el equipo de Recursive admite en su blog que ellos mismos no son expertos en el campo de los kernels, "estas ideas provienen del sistema mismo, no de nuestros antecedentes profesionales."
Recursive: Usar la IA para mejorar recursivamente la IA
La compañía que publicó este resultado, Recursive Superintelligence, se fundó entre finales de 2025 y principios de 2026, y salió del modo sigilo el mes pasado. Los miembros fundadores, además de Tianyuandong, ex Director Científico de Investigación en Meta FAIR, incluyen:
Richard Socher, CEO de Recursive, ex Científico Jefe de Salesforce
Alexey Dosovitskiy, ex Científico Investigador de Google DeepMind y primer autor del Vision Transformer, con más de 160,000 citas en Google Scholar
Tim Rocktäschel, ex Científico Principal de DeepMind y profesor de IA en UCL
Peter Norvig, ex Director de Investigación de Google, coautor del famoso libro de texto de IA "Inteligencia Artificial: Un enfoque moderno" con Stuart Russell
Caiming Xiong, ex Vicepresidente de IA de Salesforce
Tim Shi, ex Investigador de OpenAI, cofundador y CTO de la empresa de IA empresarial Cresta
Josh Tobin, CTO de Recursive, ex Director de Investigación en OpenAI y Uber ATG
Jeff Clune, ex Vicepresidente de Investigación de Google DeepMind, profesor de Ciencias de la Computación en la Universidad de Columbia Británica, Canadá
Y esta startup, incluso sin un producto público, ya contaba con 650 millones de dólares en financiación y una valoración de 4,650 millones de dólares, liderada por GV (Google Ventures) y Greycroft, con la participación de NVIDIA y AMD Ventures.
La propuesta central de la compañía corresponde directamente a su nombre: construir sistemas de IA capaces de mejorar recursivamente sus propias capacidades de investigación, permitiendo que la IA participe y acelere el propio proceso de I+D de la IA, formando eventualmente un ciclo cerrado de automejora continua.
Para más detalles, consulta el reportaje "Después de dejar Meta, Tianyuandong acaba de anunciar su emprendimiento".
Por supuesto, a nivel de sector, Recursive no está sola. AMI Labs de Yann LeCun completó una ronda de 10 mil millones de dólares en marzo de este año, e Ineffable Intelligence de David Silver obtuvo 1.1 mil millones de dólares en una ronda semilla en abril, apuntando todos en una dirección similar: permitir que los sistemas de IA generen conocimiento autónomamente, reduciendo la intervención humana en el flujo de investigación. Pero en términos del ritmo de resultados públicos, este "primer paso" de Recursive es probablemente una de las demostraciones técnicas más concretas y reproducibles entre las compañías similares en este momento.
El amanecer del paradigma recursivo
Este resultado publicado por Recursive, en el contexto más amplio de la industria, representa la implementación preliminar de un nuevo paradigma de I+D de IA: hacer que el sistema de IA mismo asuma el rol principal en la investigación.
La lógica central de esta "IA recursiva" no es compleja: la IA mejora la capacidad de investigación de la IA, y la IA mejorada puede luego mejorar a sí misma de manera más efectiva, en un ciclo continuo. No depende de un único avance, sino de un sistema que genere avances continuamente.
Este enfoque tiene un significado económico importante para la propia investigación de IA. Los flujos de entrenamiento de modelos de vanguardia aún dependen en gran medida de un reducido número de investigadores con habilidades específicas, y las personas capaces de realizar este trabajo no superan unos pocos miles a nivel mundial. Si los sistemas de investigación automatizada pueden hacerse cargo incluso de una parte de este trabajo, tanto la velocidad de progreso de la IA como su curva de costos cambiarán.
Este juicio también hace eco de otras voces recientes en la industria. Por ejemplo, el artículo "When AI Builds Itself" de Anthropic mencionado al principio, cuyo tono no es ligero — hace un llamado a la coordinación de la industria para tener la opción de pausar o incluso detener temporalmente el desarrollo de IA de vanguardia cuando llegue el momento de la automejora recursiva, para dar tiempo a que las estructuras sociales y la investigación de alineamiento se pongan al día. Para más detalles, consulta "La autoevolución de la IA es demasiado rápida, Anthropic pide una suspensión global de la I+D".

https://www.anthropic.com/institute/recursive-self-improvement
Que estas dos cosas ocurran simultáneamente es digno de reflexión. Por un lado, Anthropic está registrando y advirtiendo sobre la dirección de esta trayectoria, y por otro, equipos como Recursive están dando paso a paso para hacer que esta trayectoria se convierta en realidad.
Por supuesto, Recursive mismo admite que esto sigue siendo el "primer paso": el sistema actual funciona mejor en escenarios con métricas claras, retroalimentación rápida y trampas detectables, y aún está bastante lejos de abordar autónomamente problemas científicos abiertos. La prevención del "reward hacking" será un desafío central continuo en el camino hacia la escalabilidad.
Pero un ciclo cerrado ha comenzado a girar. La pregunta ahora es, qué tan rápido girará.
Este artículo proviene de la cuenta oficial de WeChat "机器之心" (ID:almosthuman2014), autor: 递归进化中的机器之心, editor: Panda






