Escrito por: Vaidik Mandloi
Compilado por: Luffy, Foresight News
Desde su lanzamiento a finales de 2022, ChatGPT ha dado lugar a un vasto ecosistema de agentes de IA. Actualmente, el tráfico total generado por este tipo de programas ya supera al de todos los usuarios humanos del mundo. El comportamiento de navegación de la IA es radicalmente diferente al humano: no ve anuncios, no hace clic en enlaces ni compra en línea, simplemente recopila datos de la web para completar tareas y se va una vez finalizadas.
La arquitectura y la lógica comercial originales de Internet se construyeron en torno al comportamiento y los hábitos humanos. Pero hoy, la gran mayoría del acceso a la web no proviene de personas reales, lo que supone un gran problema para los sitios web. Ya hay 2.5 millones de sitios que han comenzado a bloquear a los rastreadores de IA, y plataformas como Perplexity se han visto envueltas en litigios relacionados. El proveedor de servicios en la nube Cloudflare incluso ha construido un "laberinto de trampas de miel", utilizando textos sin sentido generados por IA para crear páginas en bucle infinito y atrapar a varios rastreadores de datos.
Sin embargo, algunos agentes de IA avanzados ya son capaces de eludir este tipo de protecciones. Ante esta creciente confrontación entre humanos y máquinas, la industria está empezando a centrarse en desarrollar un mecanismo de verificación de identidad humana más fiable. Este sistema debe identificar con precisión si el operador al otro lado de la pantalla es humano: un operador real mostrará vacilaciones, errores al teclear, y el movimiento del cursor tendrá el ligero temblor característico del sistema nervioso humano. Este artículo analiza las causas detrás de este cambio, las dos principales soluciones técnicas y la elección a la que nos enfrentamos: aceptar la vigilancia centralizada de características biométricas o adoptar la tecnología de prueba de conocimiento cero (zero-knowledge proof) para realizar verificaciones anónimas de humanidad.
La IA trastoca el modelo de negocio de Internet
El motivo por el que los sitios web están bloqueando los programas de IA es que la IA está socavando simultáneamente los cimientos comerciales en los que se sustenta Internet. La lógica de rentabilidad de Internet tradicional se basa en la atención del usuario: los usuarios visitan páginas, ven anuncios y los editores de contenidos obtienen ingresos. Si se deja que la IA compre por ti, buscará en cinco mil sitios de una vez, mientras que una persona normalmente solo miraría cuatro o cinco páginas.
La IA lee mucho más rápido que los humanos, pudiendo comparar precios en toda la web e incluso realizar pedidos en pocos minutos, sin generar ninguna visualización publicitaria durante todo el proceso. Esto significa que los sitios web soportan el costo de operar servidores sin obtener ningún beneficio.
Al mismo tiempo, la búsqueda con IA sigue desviando el tráfico de los sitios web. Después de que Google añadiera un resumen de IA en la parte superior de sus resultados de búsqueda, solo el 8% de los usuarios hacían clic para entrar en la página web original, y el tráfico de referencia de Google a los principales sitios de contenidos cayó un 33%. Solo un año después de su lanzamiento, esta función superó los 1.000 millones de usuarios activos mensuales, y el volumen de búsquedas en la plataforma se ha duplicado cada trimestre desde su inicio.
Probablemente todos recuerden la plataforma de ayuda para el estudio Chegg. Originalmente centrada en preguntas y respuestas sobre tareas aprovechando su buen posicionamiento en búsquedas, ahora ha cerrado oficialmente su sección de Q&A, atribuyendo su declive al impacto de ChatGPT. Los creadores de contenidos se encuentran atrapados entre dos frentes: por un lado, los rastreadores extraen contenido indiscriminadamente de sus sitios, y por otro, los resúmenes de IA interceptan el tráfico antes de que los usuarios lleguen al sitio web.
La disparidad en el uso de datos es aún más impactante: por cada visita que el rastreador de OpenAI dirige a un sitio web asociado, previamente habrá rastreado datos de 400 páginas; para Anthropic, esta proporción llega a ser de 38,000:1. Estas empresas utilizan datos públicos de toda la web para entrenar sus modelos de IA sin compensación, y luego usan sus productos finales para desviar el tráfico que originalmente pertenecía a los sitios web.
En cualquier otra industria, este comportamiento depredador de recolección de datos habría generado innumerables demandas, pero en el campo de la IA, estas empresas logran valoraciones billonarias.
Tu cuerpo es la nueva contraseña
Durante los últimos 25 años, Internet se ha basado principalmente en CAPTCHAs para distinguir humanos de máquinas. La gente tenía que identificar señales de tráfico o introducir caracteres distorsionados. Este mecanismo funcionaba porque la capacidad de reconocimiento de imágenes de las máquinas era muy inferior a la humana.
Hoy la situación se ha invertido por completo. Los programas operativos inteligentes de OpenAI obtienen puntuaciones que simulan humanos muy superiores a las reales en el sistema de verificación humana de Google, siendo capaces de hacer clic con precisión en interfaces y copiar/pegar contenido; las fotos generadas por IA pueden engañar a los sistemas de verificación de identidad, y las videollamadas deepfake incluso han sido utilizadas por delincuentes para realizar transferencias bancarias. La premisa de diseño de los métodos de verificación tradicionales —que las máquinas son más débiles que los humanos— ya no existe.
La industria ahora debe centrarse en áreas que la IA aún no puede replicar temporalmente: las características del comportamiento físico humano al operar dispositivos electrónicos, es decir, la biometría conductual. Empresas como IBM y BioCatch están desarrollando sistemas relacionados. Esta tecnología no solo verifica la identidad en el inicio de sesión, sino que también monitorea el estado de uso del usuario durante toda la sesión, recopilando datos como la velocidad de movimiento del cursor, la forma de desplazarse por las páginas, el ritmo de escritura, la presión de las teclas, los hábitos de corrección de texto, el ángulo de sujeción del teléfono, etc. El giroscopio del teléfono registra esta información durante todo el tiempo.
El sistema también puede reconocer detalles como la mano dominante del usuario o la trayectoria del deslizamiento de los dedos. IBM solo necesita recopilar datos de ocho sesiones de uso para crear un perfil conductual único del usuario, que luego compara en tiempo real con cada acción posterior.
La tecnología de BioCatch puede incluso identificar escenarios de fraude en línea. Cuando una víctima, siguiendo las instrucciones telefónicas de un estafador, dicta su nombre de usuario y contraseña, el sistema capta con precisión el ritmo de escritura nervioso e intermitente. Solo en un año, este sistema ayudó a 257 bancos a identificar alrededor de 2 millones de cuentas utilizadas para lavado de dinero. Ahora la UE también está probando tecnología de reconocimiento de la marcha. Han pasado solo tres años desde el inicio de la era de los agentes de IA, y los agentes fronterizos de la UE ya están recopilando la forma de caminar de las personas.
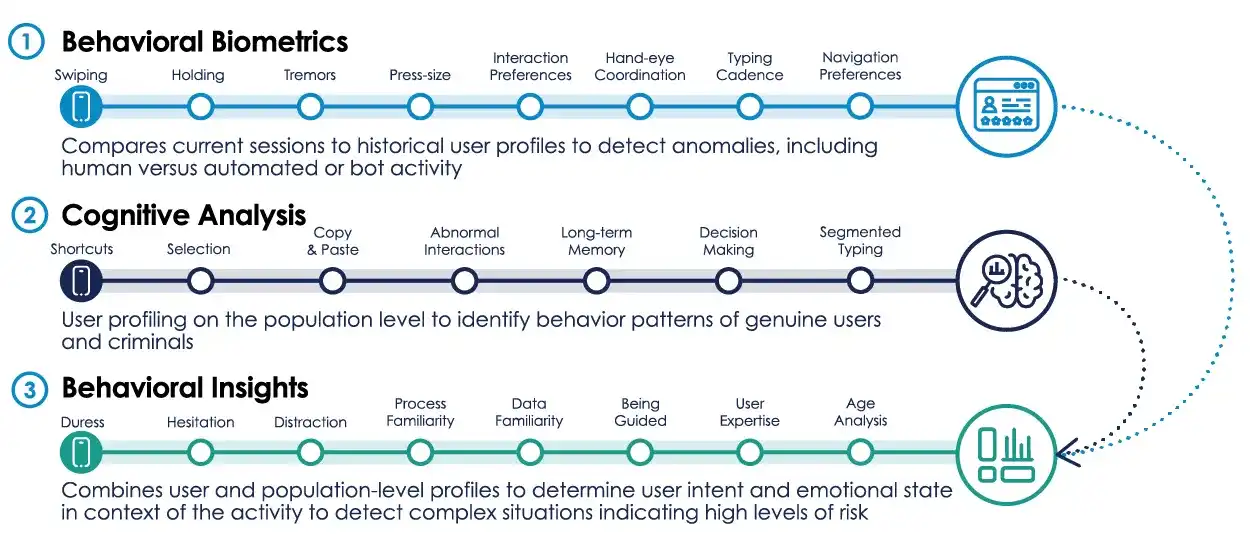
Investigaciones relacionadas también incorporan el efecto Stroop: cuando la palabra "azul" está escrita en color verde, el cerebro humano se ralentiza debido al conflicto entre el significado de la palabra y el color visual, pero la IA no se ve afectada. Los estudios encuentran que esta interferencia cognitiva se refleja directamente en el comportamiento de escritura. Incluso podría no ser necesario plantear una prueba específica; solo con el ritmo de pulsación de teclas, la plataforma podría determinar si el operador es humano. En los hábitos de escritura, se esconden características únicas del procesamiento de información del cerebro humano.
El rastreo web tradicional registraba principalmente el comportamiento de navegación, clics, compras, etc. Los usuarios podían evitarlo bloqueando cookies, usando VPNs o desactivando la geolocalización. Pero la biometría conductual recopila características instintivas del cuerpo humano: la forma de mover el cursor, el ritmo de escritura, son difíciles de cambiar a propósito.
Las características conductuales de cada persona son tan únicas como una huella dactilar. A diferencia de una contraseña o una clave, este perfil biométrico no se puede cambiar ni restablecer. Si esta tecnología se generaliza, todas las grandes plataformas se verán obligadas a adaptarse. Ahora la tecnología de simulación de voz ya puede sonar indistinguible en una llamada, y la tecnología deepfake de video le sigue de cerca. Si este es el futuro, surge la pregunta central: ¿quién controlará finalmente estos datos corporales humanos?
¿Quién controlará el sistema de verificación humana?
Actualmente, la industria se está dividiendo en dos campos principales que exploran soluciones de verificación de identidad humana.
El primero es World de Sam Altman (anteriormente Worldcoin). El usuario debe acercarse a un dispositivo esférico de escaneo de iris. El dispositivo recopila la información del iris y genera una credencial cifrada para demostrar que el usuario es un ser humano natural único. Hasta ahora, 18 millones de personas en 160 países han registrado su iris. En abril de 2026, World logró acuerdos de verificación de usuarios con la aplicación de citas Tinder, la plataforma de videoconferencias Zoom y el servicio de firma electrónica DocuSign; también lanzó conjuntamente con Coinbase la herramienta AgentKit, que permite a los usuarios vincular sus agentes de IA a una identidad verificada, permitiendo a las plataformas confirmar que hay una persona real detrás del agente sin revelar información personal.
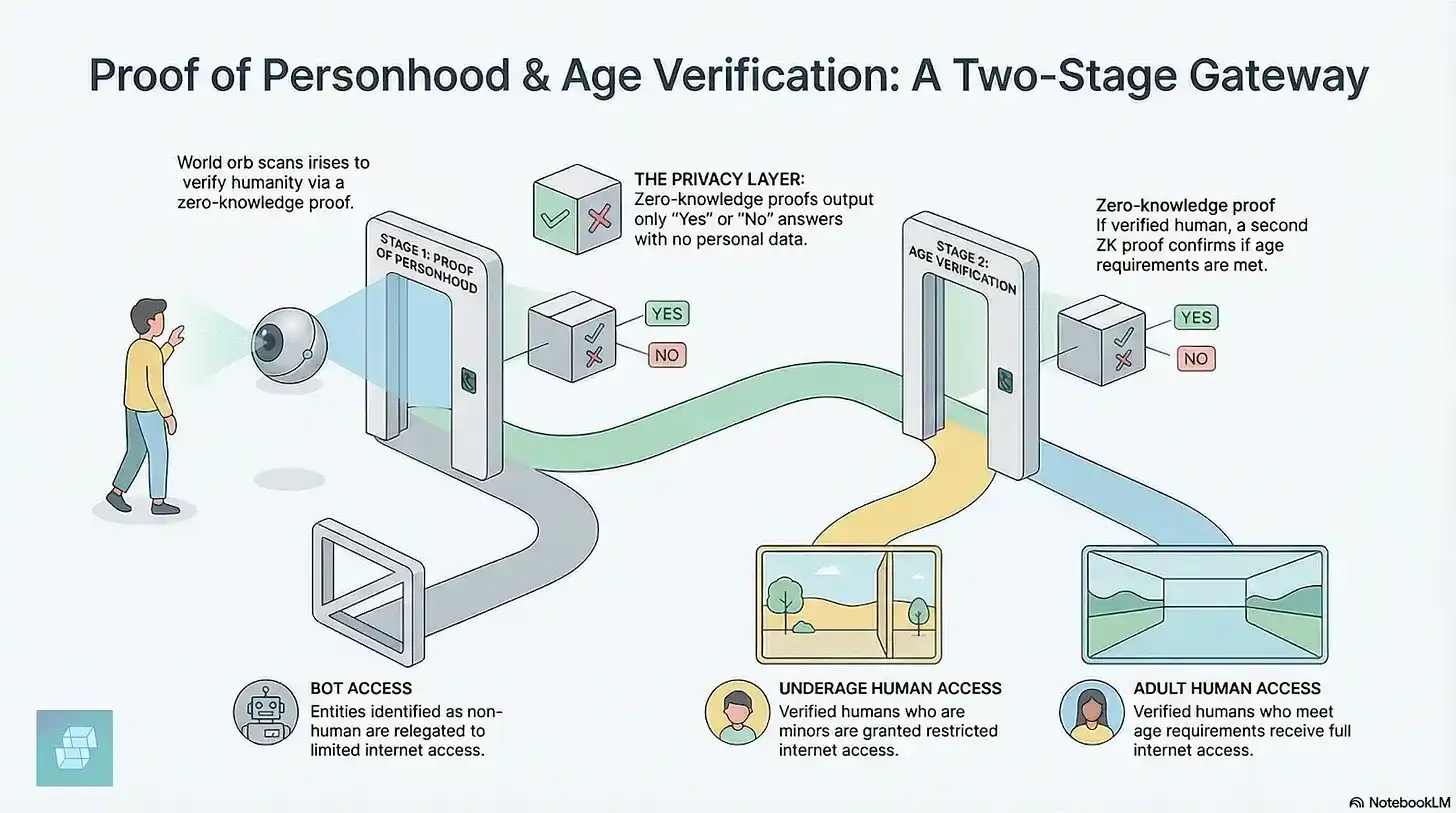
Sin embargo, la tecnología de escaneo de iris ha sido prohibida en varios países. La razón central de la oposición es que la gente no entiende qué riesgos conlleva autorizar la recolección de datos biométricos. Una investigación del MIT Technology Review también descubrió que World, sin autorización válida, recopilaba privadamente múltiples signos vitales humanos además del iris, como la frecuencia cardíaca y la respiración.
El segundo tipo se basa en pruebas de conocimiento cero (zero-knowledge proofs), que te permiten demostrar que eres humano sin revelar tu identidad real, ubicación o apariencia. Vitalik Buterin propuso esta idea ya en 2023. Argumentó que si no podemos construir un sistema de identidad humana descentralizado, Internet terminará en un control de identidad centralizado. Si la autoridad de verificación de identidad es controlada por empresas o gobiernos, los mecanismos de vigilancia quedarán arraigados en la base misma de la red.
Hubo un intento a gran escala de implementar un sistema de identidad humana descentralizado, que finalmente fracasó. Idena fue uno de los primeros proyectos de cadena de bloques que promovía "una persona, una identidad". En solo dos años desde su lanzamiento, el 40% de las cuentas de la red y el 48% de las recompensas estaban controladas por 23 organizaciones. Equipos de operación de cuentas en India, Rusia y otros lugares contrataban a personas comunes por menos de un dólar la hora para prestar sus identidades, obteniendo ganancias de hasta 55 veces. Los investigadores también descubrieron que incluso se utilizaba información de identidad de niños para cuentas ficticias.
Vitalik ya había anticipado este tipo de riesgos. Señaló que el ataque de menor costo contra un sistema de verificación de identidad humana no serían los deepfakes o técnicas de hacking avanzadas, sino alquilar las identidades personales de personas en regiones de bajos ingresos. Cualquier sistema de verificación de identidad humana requiere apoyo financiero: los dispositivos de escaneo de iris, los nodos de verificación en cadena, requieren una inversión continua.
Pero una vez que las credenciales de identidad adquieren valor económico, surge un mercado negro de alquiler de identidades. En el mundo real con disparidades económicas masivas, los más poderosos terminan controlando estos mercados.
"Forzar la regla de un hombre, un voto en un sistema con incentivos económicos reales solo repetirá los experimentos sociales fallidos del siglo XX."
Objetivamente, ambas líneas de desarrollo tienen defectos evidentes. La solución centralizada puede implementarse a escala, pero los datos biométricos de los usuarios quedarían en manos de empresas que ya recopilan información en exceso y que se benefician del actual panorama de proliferación de bots. El enfoque criptográfico puede teóricamente proteger la privacidad, pero le cuesta escapar a los desequilibrios económicos del mundo real, siendo finalmente explotado por industrias grises.
Si tuviera que apostar, aún apostaría por la solución criptográfica. Porque la biometría conductual y el escaneo centralizado de iris registran permanentemente la información de tu cuerpo, y la propiedad de esa información pertenece a quien despliega el sistema. Una vez que tienen tus datos, no puedes borrarlos ni transferirlos; esos datos quedarán bloqueados en la empresa que los recopiló.
Incluso sabiendo que las pruebas de conocimiento cero pueden ser explotadas, siguen valiendo la pena desarrollarlas, porque esta prueba puede confirmar que eres humano sin revelar más información. Por el contrario, si abandonamos esta ruta, en el futuro, cada vez que accedamos a un sitio web, este conservará nuestros datos de comportamiento corporal. Actualmente, esta solución centralizada con atributos de vigilancia se está implementando mucho más rápido que el enfoque de tecnología criptográfica.