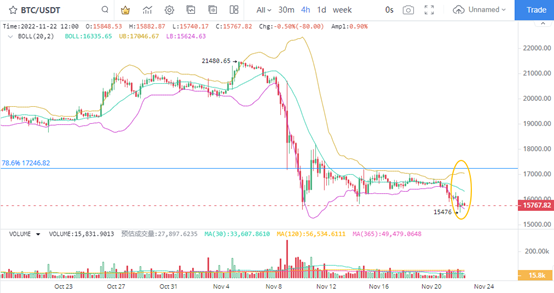
Nuevo trabajo del equipo de Kaiming He: Eliminando VAE y datos privados, la generación de texto a imagen resulta ser más potente
El equipo de investigación de He Kaiming presenta MiniT2I, un modelo de generación de imagen a partir de texto (text-to-image, T2I) minimalista y directo en el espacio de píxeles, que desafía la complejidad de los enfoques dominantes.
El modelo elimina componentes estándar como el VAE para codificación, mecanismos de inyección condicional complejos (AdaLN), funciones de pérdida auxiliares, datos privados y etapas de alineación RL/DPO. Utiliza un objetivo de "flow matching" entrenado directamente sobre píxeles RGB. Con solo 258M de parámetros (versión B/16), supera a modelos de espacio de píxeles mucho más grandes en benchmarks como GenEval (0.87) y DPG-Bench (84.2).
Su arquitectura, MM-JiT, simplifica el Transformer estándar: añade dos adaptadores ligeros para las características de texto de T5 (congelado) y elimina la rama AdaLN, confiando en que la imagen ruidosa ya contiene información temporal. Esto reduce parámetros y permite más capas, mejorando el FID a 13.7.
El entrenamiento, de bajo costo (~3 días en 8 H100 para el modelo de ablación), se realiza en dos fases con datos completamente públicos: preentrenamiento en CC12M reetiquetado y ajuste fino en ~120K pares de alta calidad. Esto demuestra que un modelo pequeño puede igualar o superar en ciertos aspectos a gigantes como SD3-Medium en escenas imaginativas, aunque muestra limitaciones en renderizado de texto y entidades nombradas debido a los datos públicos.
MiniT2I señala un cambio de paradigma hacia la simplificación y eficiencia en la generación de imágenes, haciendo que la tecnología T2I sea más accesible fuera de los laboratorios industriales líderes.
marsbitHace 11 min(s)