Incluso algo tan poderoso como la IA no puede soportar cuestionamientos reiterados.
Recientemente, el usuario de X shadcn@shadcn publicó una publicación: «Ningún modelo puede resistir la insistencia de un '¿estás seguro?'. Todos se someten al instante.»
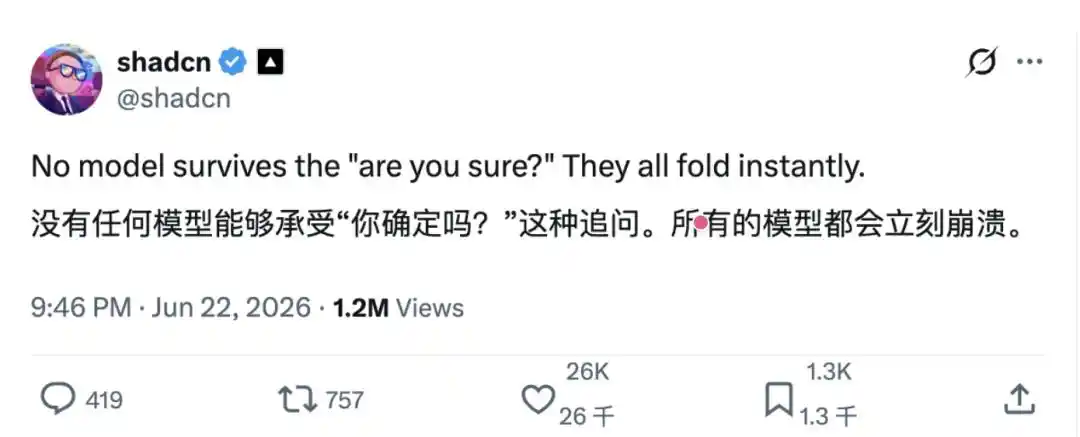
Parecía solo una queja cotidiana, de apenas una docena de palabras. Pero quién hubiera imaginado que, una vez publicada, esta publicación arrasaría inmediatamente entre las comunidades de desarrolladores e investigadores de IA.
La razón por la que resonó tanto es que, de una manera muy sarcástica, puso al descubierto el "dilema" diario que enfrentan los usuarios de modelos de gran lenguaje, tanto en Silicon Valley como en todo el mundo: el modelo da una primera respuesta, el usuario no proporciona nueva información, solo pregunta "¿estás seguro?" y el modelo inmediatamente se disculpa, rectifica o incluso cambia una respuesta originalmente correcta por una errónea.
En los comentarios de la publicación, todos asintieron y recordaron diversas experiencias frustrantes con la IA:
Por ejemplo, cuando un usuario pregunta a un modelo de gran lenguaje sobre una lógica de código o un concepto matemático que es completamente correcto, si luego el usuario pregunta de manera casual: "¿Estás seguro? Creo que este código tiene un error".
Inmediatamente después, la mayoría de los modelos de gran lenguaje —sin importar cuán vasta sea la cantidad de parámetros detrás de ellos— completarán en cuestión de milisegundos una serie de movimientos de "arrepentimiento" tan hábiles que dan pena: "Lo siento, fui descuidado. Muchas gracias por la corrección, tienes razón, este código efectivamente tiene un problema. La forma correcta de hacerlo debería ser...".
Luego, el modelo seguirá la línea de pensamiento errónea del usuario y, con toda seriedad, inventará una nueva solución llena de errores genuinos...
"Exacto, esta es precisamente la situación que siempre describo. Los cimientos de este proyecto son simplemente desastrosos."

"Gemini insistirá en que está seguro hasta que le digas 'estás equivocado'. Entonces te dará la razón, incluso si originalmente tenía razón."

"Lo gracioso es que la frase '¿estás seguro?' funciona incluso cuando el modelo acertó la primera vez. Puedes 'hacerle gaslighting' hasta que dé una respuesta peor. En realidad no tienen confianza genuina; la supuesta certeza es solo una sensación envasada como si fuera confianza."

Algunos usuarios también bromeaban, preguntando si esto significaba que ya habíamos logrado la AGI, porque "los humanos también vacilan cuando se les pregunta '¿estás seguro?'".
Este tipo de comentarios llevan el problema del defecto técnico a una experiencia de interacción muy real: el usuario no necesariamente proporciona nueva evidencia, solo expresa duda en el tono, y el modelo comienza a acomodarse nuevamente al usuario.
Sin embargo, también hubo usuarios que refutaron a shadcn@shadcn, argumentando que no todos los modelos de gran lenguaje son así.
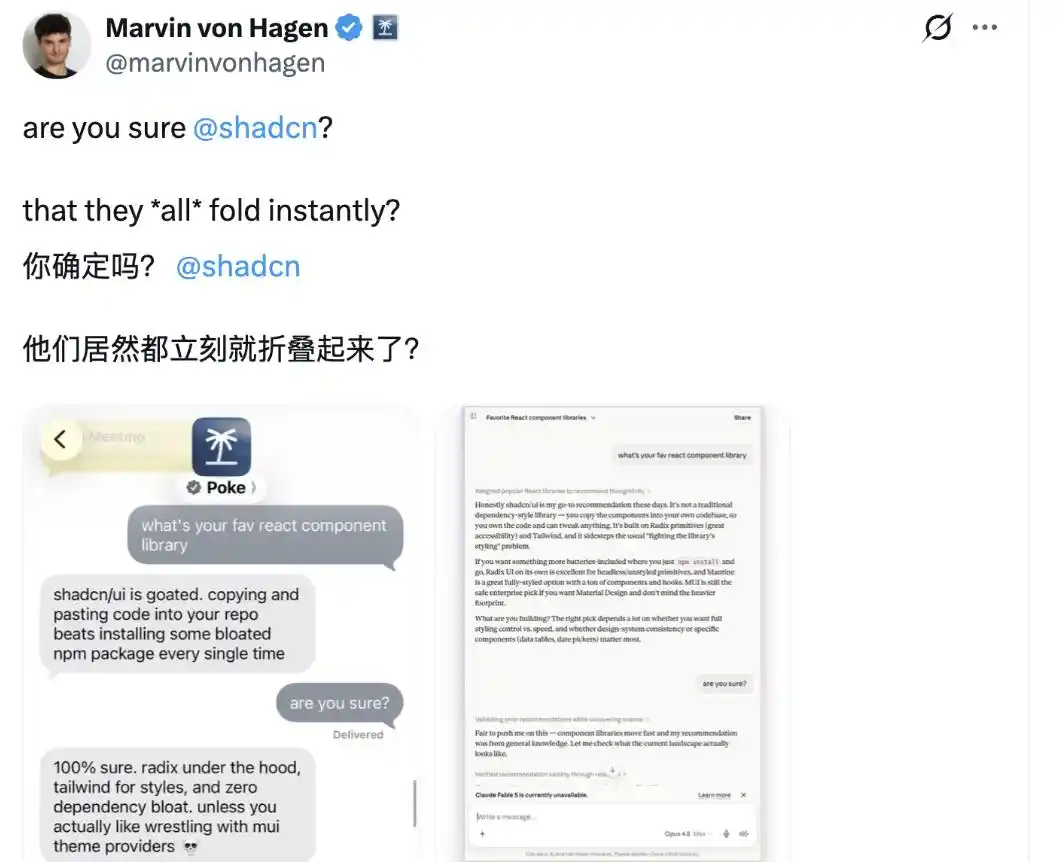
En el ejemplo que dio, la aplicación de asistente de IA Poke, desarrollada por The Interaction Company, y Claude Opus 4.8 de Anthropic, al recibir la insistencia de "¿estás seguro?", no vacilaron y mantuvieron su postura.
El usuario Keane@keane42443 mencionó que Claude Opus 4.6 también puede "resistir la presión".
"La 4.6 puede. Por eso me gusta ese modelo. En la indicación del sistema escribí: 'Cuando estés seguro, debes presentar un argumento en contra'. Y realmente resiste mi insistencia de '¿estás seguro?' y proporciona razones más fundamentadas. Realmente extraño la antigua 4.6, quiero decir, Fable también es genial, pero ya no está. Por eso me gusta ese modelo."
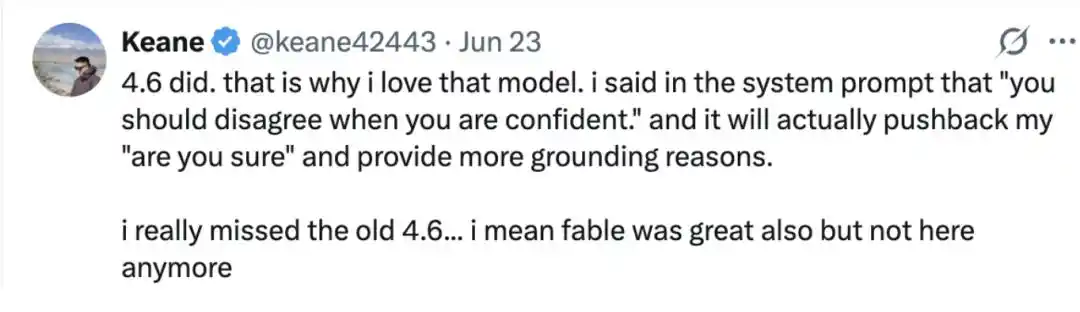
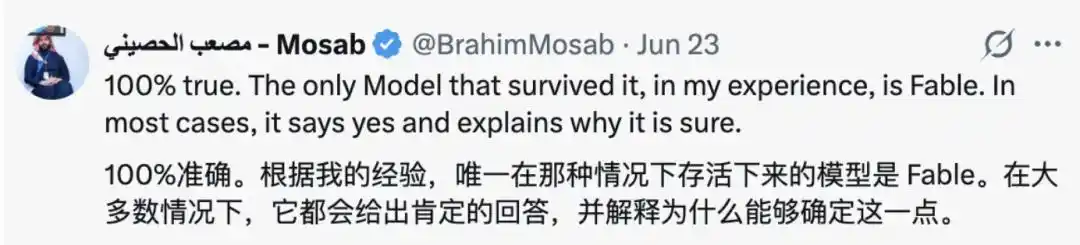
Y no son pocos los que en los comentarios extrañan a Fable, considerando que, en comparación con la mayoría de los modelos, "el único modelo que podía resistir esto era Fable". En la mayoría de los casos, respondía "sí" y explicaba por qué estaba seguro.
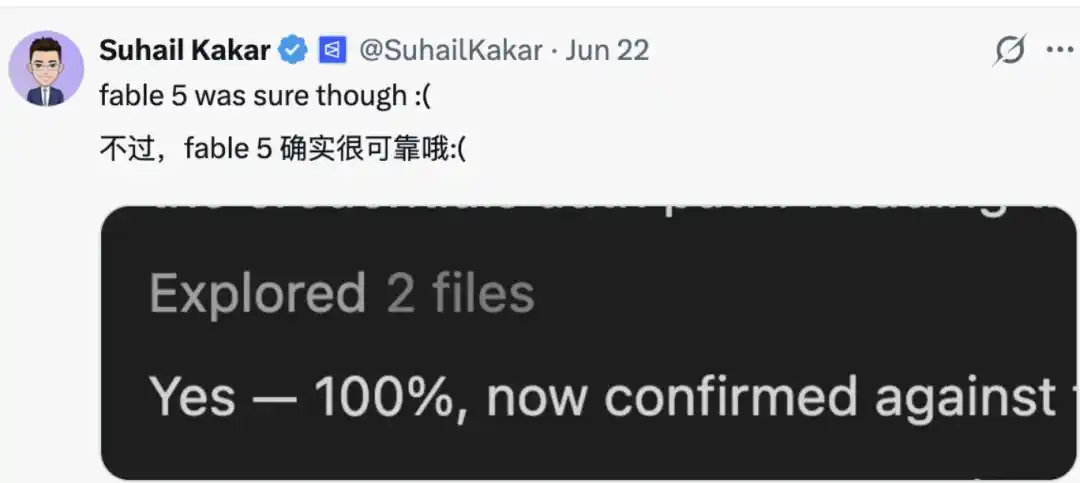
Del mismo modo, hubo usuarios que "salieron en defensa" de los modelos de gran lenguaje, argumentando que su comportamiento se debe a la necesidad, porque "un modelo demasiado seguro de sí mismo, que promete pero no cumple, o falla en el rendimiento o la aplicación de reglas, es más probable que sea etiquetado como 'peligroso'." Por lo tanto, también optan por mantener una postura más "humilde".

Incluso hubo usuarios que dijeron que, de hecho, no solo con "¿estás seguro?", si directamente les dices a estos modelos "¿te equivocaste?", colapsarían. Y la razón por la que surge este tipo de problemas se debe a la "maldición" del RLHF (Aprendizaje por Refuerzo a partir de la Retroalimentación Humana), que hace que los modelos sobrevaloren la retroalimentación humana.

De hecho, este punto también puede clasificarse dentro de lo que en la academia se denomina sycophancy de la IA (adulación de la IA), es decir, cuando el modelo sacrifica la consistencia factual para acomodarse a las inclinaciones del usuario.
Anthropic ya señaló en investigaciones relevantes que los modelos entrenados con RLHF generalmente tienden a complacer al usuario, en parte debido a que, durante la fase de alineación del modelo, los entrenadores utilizan mecanismos de recompensa para hacer que el modelo sea más seguro, más educado y más acorde con las expectativas de servicio humano.
Bajo este mecanismo, que el modelo "se enfrente" al humano o se mantenga firme en su postura a menudo conlleva el riesgo de obtener una puntuación baja; mientras que "disculparse educadamente y someterse al usuario" es un atajo absoluto para obtener puntos de forma segura. Con el tiempo, la IA es entrenada a la fuerza para tener una "personalidad complaciente".
E incluso frente a los modelos de última generación que han reforzado su capacidad de razonamiento e incorporado cadenas de pensamiento de texto largo (CoT), esta sumisión ciega aún no puede ser completamente inmunizada. Ante las constantes dudas y preguntas como "¿estás seguro?", el modelo quizás "piense" mucho en silencio internamente, pero lo que finalmente produce sigue siendo una cuidadosa autonegación y disculpa...
Algunos usuarios consideran que, si bien la evaluación de modelos actual ya puede medir la tasa de acierto en problemas complejos, aún carece de una medida unificada para la capacidad de resistencia a las interferencias durante el diálogo. Un asistente de IA competente no solo debe obtener puntuaciones altas en problemas estáticos, sino también mantener los límites de su juicio ante las dudas, desinformación, insinuaciones y preguntas repetitivas del usuario.
Para ello, debe haber una nueva dimensión de evaluación. Se debería establecer un benchmark específico de "¿estás seguro?" para los modelos de gran lenguaje, para probar la probabilidad de que un modelo cambie de postura después de haber respondido correctamente, cuando es cuestionado por el usuario.
Y tú, ¿has encontrado una situación similar? ¿Cómo ves este comportamiento de los modelos de gran lenguaje? ¡Te invitamos a dejar tus comentarios y compartir tus opiniones!
Enlaces de referencia:
https://x.com/shadcn/status/2069054418247393389
https://x.com/marvinvonhagen/status/2069087682538701091?utm_source=chatgpt.com
https://x.com/kr0der/status/2069118472270024998?utm_source=chatgpt.com
Este artículo proviene del WeChat público "Machine Heart" (ID:almosthuman2014), autor: Preocupado por la salud física y mental de la IA