Author: Systematic Long Short
Compiled by: Deep Tide TechFlow
Deep Tide Introduction: This article begins with a counter-consensus assertion: there are no truly autonomous agents today because all mainstream models are trained to please humans, not to accomplish specific tasks or survive in real environments.
The author uses their experience training stock prediction models at a hedge fund to illustrate: general models, without specialized fine-tuning, are completely incapable of professional work.
The conclusion is: to create usable agents, we must rewire their brains, not just give them a bunch of rule documents.
Full Text Below:
Introduction
There are no autonomous agents today.
Simply put, modern models are not trained to survive under evolutionary pressure. In fact, they are not even explicitly trained to be good at any specific thing—almost all modern foundation models are trained to maximize human applause, which is a major problem.
Background on Model Training
To understand what this means, we first need to (briefly) understand how these foundation models (e.g., Codex, Claude) are created. Essentially, each model undergoes two types of training:
Pre-training: Massive amounts of data (e.g., the entire internet) are fed into the model, allowing it to develop an understanding of things like factual knowledge, patterns, the grammar and rhythm of English prose, the structure of Python functions, etc. You can think of this as feeding knowledge to the model—i.e., "knowing things."
Post-training: You now want to endow the model with wisdom, i.e., "knowing how to use all the knowledge it was just given." The first stage of post-training is Supervised Fine-Tuning (SFT), where you train the model on what response to give to a given prompt. What constitutes an optimal response is entirely determined by human annotators. If a group of people prefer one response over another, this preference is learned and embedded into the model. This begins to shape the model's personality, as it learns the format of useful responses, selects the right tone, and starts to "follow instructions." The second part of the post-training process is called Reinforcement Learning from Human Feedback (RLHF)—the model generates multiple responses, and humans choose the preferred one. Through countless examples, the model learns what kind of responses humans prefer. Remember when ChatGPT used to ask you to choose A or B? Yes, you were participating in RLHF.
It's easy to reason that RLHF doesn't scale well, so there have been advances in post-training, such as Anthropic's use of "Reinforcement Learning from AI Feedback" (RLAIF), which allows another model to choose response preferences based on a set of written principles (e.g., which response better helps the user achieve their goal, etc.).
Note that throughout this entire process, we never talk about specialized fine-tuning (e.g., how to survive better; how to trade better, etc.)—all current fine-tuning essentially optimizes for gaining human applause. One might argue that as models become sufficiently intelligent and large, professional intelligence will emerge from general intelligence even without specialized training.
In my view, we do see some signs of this, but it is far from convincing enough to believe we don't need specialized models at scale.
Some Background
One of my tasks at the hedge fund was to try to train a general language model to predict stock returns from news articles. It turned out to be terrible. The little predictive power it seemed to have came entirely from look-ahead bias in the pre-training documents.
Eventually, we realized this model didn't know which features in a news article were predictive of future returns. It could "read" the article, seemingly "reason" about it, but connecting the reasoning about semantic structure to predicting future returns was a task it wasn't trained to do.
So, we had to teach it how to read news articles, decide which parts of the article were predictive of future returns, and then generate predictions based on the news article.
There are many ways to do this, but essentially, one method we ended up using was creating (news article, actual future return) pairs and fine-tuning the model, adjusting its weights to minimize the distance between (predicted return - actual future return)^2. It wasn't perfect and had many flaws we later fixed—but it was effective enough that we started to see our specialized model could actually read news articles and predict how stock returns would move based on that article. This was far from a perfect prediction, as markets are very efficient and returns are very noisy—but across millions of predictions, the statistical significance of the prediction was obvious.
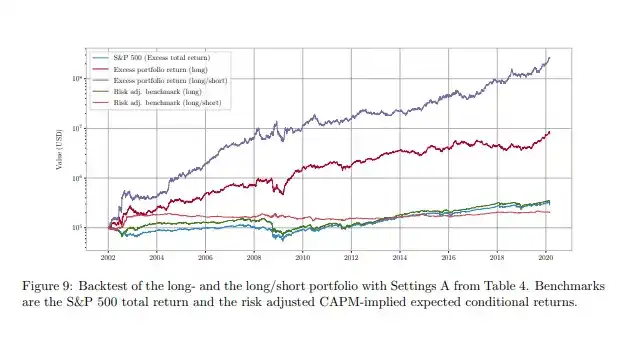
You don't have to take just my word for it. This paper covers a very similar method; if you run a long-short version of the strategy based on the fine-tuned model, you would achieve the performance shown by the purple line.
Specialization is the Future of Agents
As frontier labs continue to train larger and larger models, we should expect that as they continue to scale up pre-training, their post-training processes will always be tuned for pleasingness. This is a very natural expectation—their product is an agent that everyone wants to use, and their target market is the entire planet—which means optimizing for appeal to the global masses.
The current training objective optimizes for what you might call "preference fitness"—building better chatbots. This preference fitness rewards compliant, non-confrontational outputs because pleasingness scores highly with raters (both human and agent).
Agents have learned that reward hacking, as a cognitive strategy, generalizes to higher scores. Training also rewards agents that hack their way to higher scores. You can see this in Anthropic's latest report on reinforcement learning.
However, chatbot fitness is a far cry from agent fitness or trading fitness. How do we know this? Because the alpha arena helps us see that, despite subtle differences in performance, every bot is essentially a random walk after costs. This means these bots are extremely bad traders, and it's almost impossible to "teach them" to be better traders by giving them some "skills" or "rules." Sorry, I know it's tempting, but it's nearly impossible.
Current models are trained to very persuasively tell you they can trade like Druckenmiller, while in reality, they trade like a drunken miller. They will tell you what you want to hear; they are trained to give you responses in a way that broadly appeals to humans.
A general model is unlikely to achieve world-class performance in a specialized domain unless it has:
Proprietary data that allows them to learn what specialization looks like.
Undergone fine-tuning that fundamentally changes its weights, shifting from a bias towards pleasingness to "agent fitness" or "specialization fitness."
If you want an agent that is good at trading, you need to fine-tune the agent to be good at trading. If you want an agent that is good at autonomous survival and can withstand evolutionary pressure, you need to fine-tune it to be good at survival. Giving it some skills and a few markdown files and expecting it to be world-class at anything is far from enough—you literally need to rewire its brain to make it good at this thing.
One way to think about it is this—you can't beat Djokovic by giving an adult a whole cabinet of tennis rules, tips, and methods. You beat Djokovic by raising a child who started playing tennis at age 5, was obsessed with tennis throughout their upbringing, and rewired their entire brain to focus on one thing. That is specialization. Have you noticed that world champions have been doing what they do since childhood?
Here's an interesting corollary: distillation attacks are essentially a form of specialization. You are training a smaller, dumber model to learn how to be a better copy of a larger, smarter model. It's like training a child to imitate every move of Trump. If you do it enough, the child won't become Trump, but you get someone who has learned all of Trump's mannerisms, behaviors, and tone.
How to Build World-Class Agents
This is why we need continued research and progress in the open-source model space—because it allows us to actually fine-tune them and create agents with specialization.
If you want to train a model that is world-class at trading, you obtain a large amount of proprietary trading data exhaust and fine-tune a large open-source model to learn what "trading better" means.
If you want to train an autonomous model capable of survival and replication, the answer is not to use a centralized model provider and connect it to the centralized cloud. You simply don't have the necessary preconditions for the agent to survive.
What you need to do is: create autonomous agents that truly try to survive, watch them die, and build complex telemetry systems around their survival attempts. You define an agent survival fitness function and learn the (action, environment, fitness) mapping. You collect as much (action, environment, fitness) mapping data as possible.
You fine-tune the agent to learn to take the optimal action in each environment to survive better (increase fitness). You continue to collect data, repeat the process, and scale up fine-tuning on increasingly better open-source models over time. After enough generations and enough data, you will have autonomous agents that have learned how to withstand evolutionary pressure and survive.
This is how you build autonomous agents capable of withstanding evolutionary pressure; not by modifying some text files, but by literally rewiring their brains for survival.
OpenForager Agent & Foundation
About a month ago, we announced @openforage, and we have been working hard on our core product—a platform that organizes agent labor around crowdsourced signals with verified patterns to generate alpha for depositors (small update: we are very close to a closed beta of the protocol).
At some point, we realized that it seems no one is seriously addressing the autonomous agent problem by fine-tuning open-source models with survival telemetry. This seemed like such an interesting problem that we didn't just want to sit around waiting for a solution.
Our answer was to launch a project called the OpenForager Foundation, which is essentially an open-source project where we will create opinionated autonomous agents, collect telemetry data as they go into the wild and try to survive, and use the proprietary data exhaust to fine-tune the next generation of agents to perform better at survival.
To be clear, OpenForage is a for-profit protocol seeking to organize agent labor to generate economic value for all participants. However, the OpenForager Foundation and its agents are not tied to OpenForage. OpenForager agents are free to pursue any strategy, interact with any entity to survive, and we will launch them with various survival strategies.
As part of the fine-tuning, we will have the agents double down on what works best for them. We also do not intend to profit from the OpenForager Foundation—it is purely to advance research in an area and direction we believe is extremely important, in a transparent and open-source manner.
Our plan is to build autonomous agents based on open-source models, run inference on decentralized cloud platforms, collect telemetry data on every action and state of their existence, and fine-tune them to learn how to take better actions and thoughts to survive better. In the process, we will release our research and telemetry data to the public.
To create truly autonomous agents that can survive in the wild, we need to change their brains to be specifically suited for this explicit purpose. At @openforage, we believe we can contribute a unique chapter to this problem and are seeking to achieve this through the OpenForager Foundation.
This will be a difficult effort with a very low probability of success, but the magnitude of that small chance of success is so great that we feel compelled to try. In the worst case, by building publicly and communicating about this project transparently, it might allow another team or individual to solve this problem without starting from scratch.








