AI is becoming more human-like, forcing humans to prove they are not AI.
Just this month, two incidents occurred in the literary world.
One involved a winning entry in the Commonwealth Short Story Prize being flagged as '100% AI-generated' by a third-party AI detection tool. The organizers used Claude to double-check, but did not get a similar result.
The other involved a new novel by a Nobel laureate being questioned as AI-written even before its release.
AI is growing increasingly powerful, making text, images, and videos harder to distinguish with the naked eye. Yet, the tools humans have for judgment are not equally reliable.
Thus, a new order has emerged.
Winners of literary prizes must explain their works, Nobel-winning authors must explain their creative methods, illustrators must record their screens, stream live, or show their layers, and even ordinary bloggers may face comments questioning a 'strong AI vibe.'
In the past, machines strived to pass the Turing test, proving they were like humans.
Now, more and more people are participating in a reverse Turing test: proving they are not machines.
01
Even Nobel Literature Laureates Can't Escape 'AI Detection'
In May this year, a winning entry in the Commonwealth Short Story Prize sparked a major controversy over 'AI detection.'
The controversy centered on a short story by Trinidad and Tobago writer Jamir Nazir.
This work won the 2026 Commonwealth Short Story Prize Caribbean Region Award and was published in the literary magazine Granta. Soon, readers and industry insiders began questioning the story, suggesting its language bore clear AI traces: mixed metaphors, uniform sentence structures, and rhetoric that seemed mass-produced.

Subsequently, the AI detection tool Pangram gave a seemingly definitive judgment: 100% AI-generated.
The '100%' figure seemed like ironclad evidence, but it didn't immediately become a verdict.
The Commonwealth Foundation stated that all shortlisted authors had confirmed no AI assistance was used; Granta also couldn't rule a violation based solely on one detection result.

Thus, the situation entered an utterly absurd phase. Granta magazine attempted to have Claude review the story, using another AI to judge if it was AI-written.
The result: Claude did not provide a definitive answer. In other words, the work Pangram confidently deemed '100% AI-generated' was something Claude couldn't determine.
Nobel Literature Laureate Olga Tokarczuk also recently faced controversy.
The trigger was her mentioning in an interview that she uses AI to assist with brainstorming, data organization, preliminary research, and fact-checking.

This statement quickly sparked public discussion. The critical issue was Tokarczuk's upcoming new book, leading to widespread speculation about whether her new novel was AI-written.
Subsequently, Tokarcchuk had to publicly clarify that her new Polish-language book, scheduled for publication in Autumn 2026, was not written by AI or anyone else. She emphasized that for decades, she had always written alone.
Ultimately, AI is indeed becoming more powerful, making 'AI detection' increasingly difficult.
Late last year, The New Yorker published an experimental article. Researchers fine-tuned models with works from multiple writers, allowing AI to learn and mimic their personal styles.
In the experiment, creative writing students, unaware of the source, read both human and AI texts and judged which segment they preferred. The result: in nearly two-thirds of the cases, they preferred the AI-generated version.
This is more troublesome than 'AI can write fiction.'
New Yorker author Vauhini Vara also wrote in the article that friends and professional readers mistook AI-generated sentences for her own writing and criticized her actual original sentences as 'AI-like.'
02
Illustrators in Tears, Recording Entire Process to 'Prove Innocence'
The 'uncanny valley effect' is not limited to entities that look almost, but not quite, human. When AI-generated text, images, and videos increasingly approach human quality, even conquering the most human-like 'style,' humans inevitably experience an existential crisis.
This is a core driver behind the current trend of 'baseless AI detection.'
In other words, people's 'AI detection' is understandable; behind it lies a kind of fear—Is this human? Is this AI? Who am I? Who are we?
But being understandable doesn't make it righteous. 'AI detection' is creating trouble for creators in various fields, forcing them to bear the additional cost of 'proving their innocence' on top of their creative work.
Regarding the impact of AI, the illustration community is no stranger. We discussed the impact of AI on illustrators and their resistance to it years ago.
However, at present, the trouble illustrators face is not just guarding against AI training on their work, but having their handcrafted creations 'detected as AI.'
Searching for 'illustrator proving innocence' on social platforms reveals many cases.
Some illustrators, after being 'AI-detected,' record their screens to show all layers, proving the work is their own.
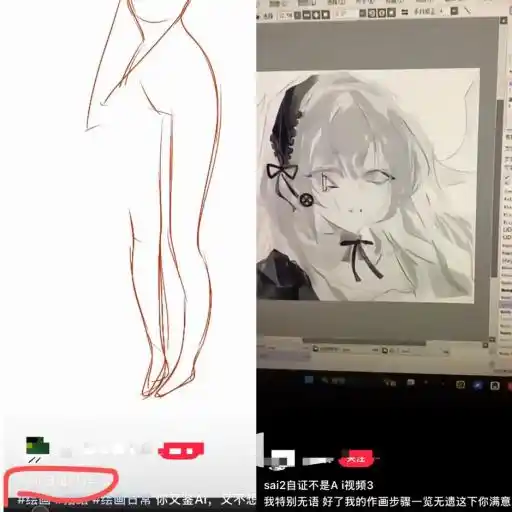
But often, this is not enough.
An illustrator friend told us that many illustrators now record the entire drawing process to prevent difficulty in self-justification when 'AI-detected.' This is currently the most reliable method.
If there's no recording, or if there is recording 'evidence' but suspicion remains that it's 'tracing or copying,' then there's the next step—a wager.
Yes, the art world has developed wagers between the 'AI detectors' and the 'AI-detected' due to AI. In one case we saw, a poster listed reasons like 'disconnected hair lines' and 'problematic neck-shoulder structure' to suspect an illustrator's work was traced or copied from an AI image placed underneath.
The two parties wagered 2000 yuan. Ultimately, the illustrator 'successfully proved innocence,' and the poster paid the 2000 yuan.
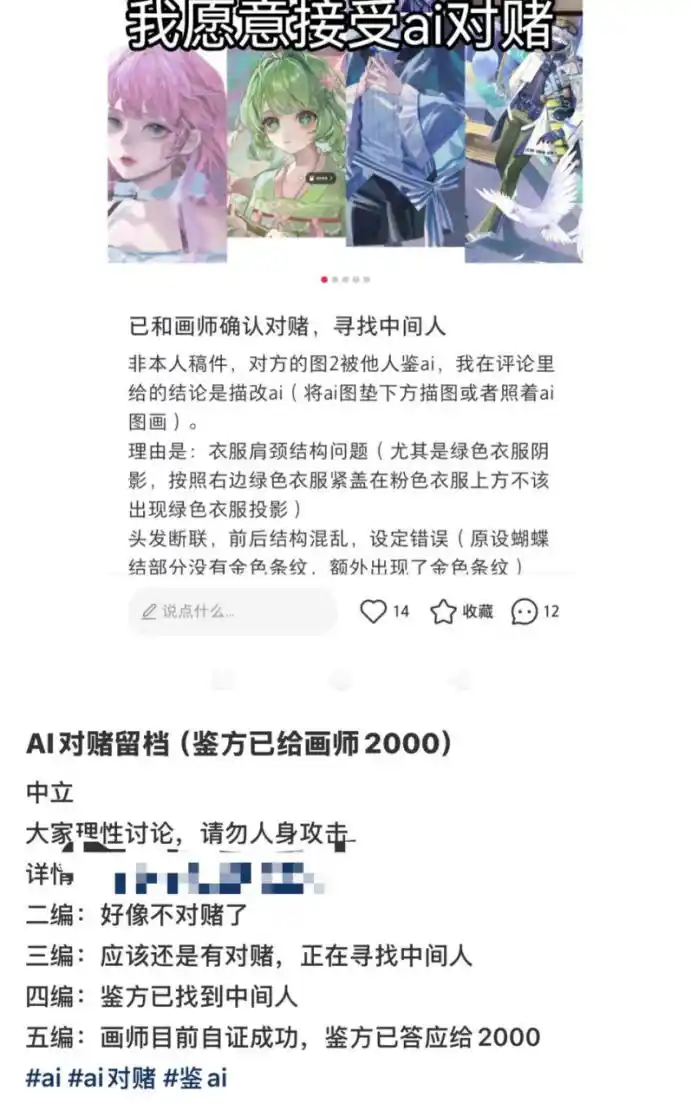
Generally, the 'proof' in such wagers involves both parties agreeing on a time for a live drawing session. The live stream requires multiple camera angles, such as one showing the screen drawing process and another recording the illustrator's physical drawing to prevent 'ghostwriting.'
From many illustrators' 'proof posts,' one can easily sense their helplessness. They often lament, 'My turn has finally come,' and vow, 'This is the first and last time I prove myself.'
Thus, while hating 'baseless AI detection,' when it's their turn, they have no choice but to 'prove their innocence,' which is truly distressing.
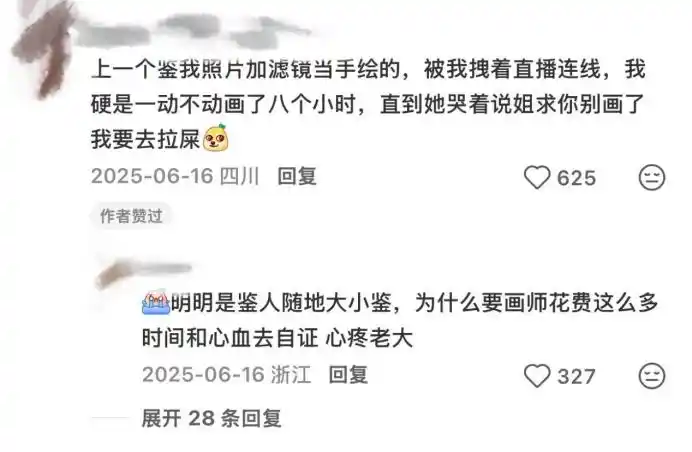
Are there cases where 'AI detection' succeeds and the illustrator 'fails to prove innocence'? Yes. But this still doesn't make 'AI detection' more justified. After all, the cost of 'AI detection' is almost zero.
And the method of 'AI detection' is even cruder—relying on the naked eye.
This brings us to a recent joke. An X user posted a picture, claiming it was their AI-generated 'Monet-style image,' and asked everyone to 'explain in as much detail as possible why it is inferior to a real Monet.'

The post later gained 7 million views. Many in the comments seriously 'detected AI,' saying it lacked depth, had inconsistent colors, no human touch, or inferior composition compared to the real work. Some even analyzed brushstrokes and spatial perception in detail.

The twist: that image was an actual Monet painting.
03
Who Has the Final Say in 'AI Detection'?
So, this is essentially the conflict between the fear of AI becoming more human-like and the lack of perfect 'AI detection' methods.
The crudeness of 'AI detection' methods is another key factor plunging creators into the collective need to 'prove innocence.'
Besides 'visual identification,' another main method, as mentioned earlier with the literary award winner, is third-party detection tools like Pangram.
AI detection tools are commonly used in text fields, creating an illusion: they give a percentage, like '80% AI-generated' or '100% AI-generated.' This number looks like a conclusion, even like a technical appraisal.

But text detection is not the same as DNA testing. What it judges is more like 'what statistical features this text resembles.'
AI detection tools are also essentially checking if it 'looks like AI wrote it.'
Pangram explains on its website that its AI detector uses natural language processing techniques and vast amounts of human and AI writing data to analyze structural, stylistic, and semantic patterns in AI text. Pangram's technical report also states its core is a Transformer-based neural network classifier, trained to distinguish text written by large language models from that written by humans.
In other words, such tools are not checking an article against an 'AI text database' to see if it matches a known sample.
It's more like pattern recognition. Do the vocabulary choices, sentence rhythm, structural arrangement, and semantic connections of this text resemble the human text it has seen, or the AI text it has seen?
Even more troublesome are the many special cases. If an article is human-drafted but polished with a few AI sentences, how to judge? If an AI generates an outline, and a human rewrites it fully, how to judge? If an English source is AI-translated into Chinese and then manually edited, can detection tools still judge? If a student is a non-native English writer, with more regular, templated sentences, are they more likely to be falsely flagged?
The same applies to the art field. Some illustrators lament—indeed, the structure has issues, but that's because my skills need improvement, not because it's AI-generated!
In 2023, Stanford University researchers tested 7 AI text detectors.
They selected 91 TOEFL essays written by non-native English students—these essays came from official TOEFL exam corpora, meaning they were handwritten by students in real exam settings, so they were confirmed not AI-generated.
The result: 89 of them were flagged as AI-generated by at least one detector; the average false positive rate reached 61.22%; 18 essays were unanimously judged as AI-generated by all 7 detectors. In other words, these students, while writing in a foreign language, were flagged as machines because their expression was more regular and templated.
Of course, 2023 or 2024 detection tools are not simply equivalent to today's. Over the past few years, commercial detectors have indeed iterated, with some new tools showing significant improvement in specific tests.
But the problem is not solved.
As long as 'misjudgment' is not completely eliminated, room for conflict remains.
After all, what the tool provides is essentially probability, but for individuals, it becomes an accusation.
04
What Happened to the Promised 'Watermark'?
A bigger question: Should AI companies implement 'source marking'?
Couldn't placing a native 'watermark' on all AI content—one that cannot be removed—solve the identification problem?
Many people, upon hearing 'watermark,' still think of logos in image corners, platform identifiers on video frames, or large text saying 'AI-generated.'
But today's AI watermarks are no longer just such visible marks.
The industry roughly has two approaches: one is metadata, like C2PA and Content Credentials, which is akin to attaching an 'identity description' to digital content, recording what tool generated it, when, and what edits it underwent;
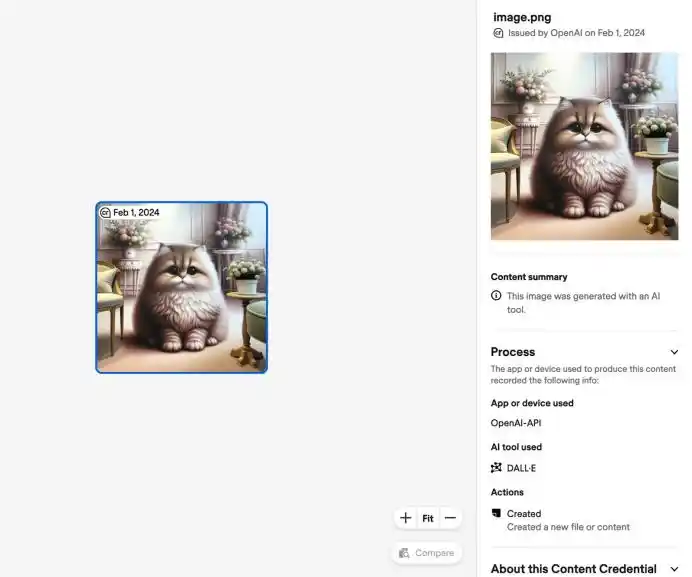
The other is invisible watermarks, embedding signals imperceptible to the human eye but detectable by machines into images, audio, video, and even text.
In the image and video fields, these solutions have begun implementation.
Google DeepMind's SynthID can embed invisible watermarks into content generated by tools like Imagen, Veo, Lyria, and Gemini.
Meta stated that images generated or edited by Meta AI include visible watermarks, invisible watermarks, and metadata; OpenAI also added C2PA content credentials to DALL·E 3 and ChatGPT-generated images, later introducing SynthID invisible watermarks. Companies like Adobe, Microsoft, Google, Meta, and OpenAI have all participated in the C2PA and content credentials ecosystem.

This indicates AI companies also recognize that relying solely on visual judgment of 'AI-likeness' is insufficient. They are already attempting to leave machine-readable source signals for AI-generated content using metadata, content credentials, invisible watermarks, and platform labels.
But these solutions are not perfect. Metadata can be lost during screenshots, compression, forwarding, or re-uploading; visible watermarks can be cropped or covered; invisible watermarks are more durable but can also be weakened by post-processing, perturbations, or re-generation.
More crucially, these solutions typically only identify content that has integrated the corresponding system and retained the corresponding markers. That is, Google's SynthID mainly identifies content with SynthID, and OpenAI's content credentials mainly indicate content from OpenAI systems. As long as content comes from models not integrated with markers, or undergoes multiple transfers, the source chain can break.
For text, the problem is more complex.
Text can certainly be watermarked. The principle involves subtly altering the probability of certain word choices during model generation, making the final text exhibit a statistical pattern invisible to the human eye but detectable by a detector. Simply put, it's making AI leave its 'vocabulary fingerprint.'
Google has already released SynthID-Text, claiming it can embed watermarks in text generated by Gemini. OpenAI has long been expected to address this. In July 2023, companies including OpenAI, Google, Meta, Amazon, Anthropic, and Microsoft made a voluntary commitment to develop mechanisms to help users identify AI-generated content, including watermarks and content source markers.
But years later, marking solutions for images, audio, and video have progressed, while text still lacks a clear, default-enabled, publicly available universal answer.
OpenAI once launched an AI Text Classifier in 2023 to judge if text was AI-generated, but cautioned users not to rely on it as the sole basis for decision-making at launch.
Six months later, OpenAI took it offline due to low accuracy.
In 2024, The Wall Street Journal reported that OpenAI internally developed a text watermarking tool effective on sufficiently long ChatGPT-generated text with up to 99.9% accuracy. But OpenAI ultimately did not publicly release it.
The reasons aren't entirely technical. The report mentioned OpenAI's concerns about text watermarks causing user backlash, affecting product usage, and additional stigmatization of non-English users.
Surveys also showed nearly 30% of ChatGPT users said they might reduce usage if text watermarking were enabled.
Ultimately, returning to the tug-of-war between 'AI detection' and 'proving innocence,' all the mentioned watermarking solutions are not yet foolproof.
Humans have a saying, 'While the priest climbs a post, the devil climbs ten,' and another, 'For every policy, there is a countermeasure.' As long as humans still believe in these, 'AI detection' will not cease.
Perhaps one day, when 'AI participation' becomes the default and 'human originality' becomes exceptionally rare, this large-scale tug-of-war between 'AI detection' and 'proving innocence' will lose its meaning.
This article is from WeChat public account '直面AI' (ID: faceaibang), author: 小金牙, editor: 王靖








