AI越来越像人,于是人类开始被迫证明自己不是AI。
仅仅在本月,文学圈就发生了两件事。
一件,是英联邦短篇小说奖的一篇获奖作品,被第三方AI检测工具判定为“100%AI生成”。主办方用Claude复核,却没有得到相似的结果。
另一件,是诺贝尔文学奖得主的新小说还没发布,就被质疑是用AI写的。
AI越来越强,文本、图像和视频都越来越难靠肉眼分辨。但与此同时,人类手里的判断工具却并没有同样可靠。
于是,一种新的秩序出现了。
文学奖获奖者要解释自己的作品,诺奖作家要解释自己的创作方式,画师要录屏、开直播、展示图层,普通博主也可能被评论区质疑“AI味太重”。
过去是机器努力通过图灵测试,证明自己像人。
现在,越来越多人开始参加一场反向图灵测试:证明自己不是机器。
01
诺贝尔文学奖得主都逃不过“鉴AI”
今年5月,英联邦短篇小说奖的一篇获奖作品,引发了一场大型“鉴AI”争议。
引发争议的是特立尼达和多巴哥作家贾米尔·纳齐尔(Jamir Nazir)的短篇小说。
这篇作品获得了2026年英联邦短篇小说奖加勒比地区奖,并发表在文学杂志Granta上。很快,有读者和业内人士开始质疑,这篇小说的语言里有明显的AI痕迹:比喻混杂、句式整齐、修辞像是被批量生成出来的。

随后,AI检测工具Pangram给出了一个看起来非常确定的判断:100%AI生成。
100%这个数字看上去像铁证,可它并没有立刻变成裁决。
英联邦基金会表示,所有入围作者都确认没有使用AI辅助;Granta也没有办法仅凭一个检测结果,就认定作者违规。

于是,事情进入了一个极其荒诞的环节。Granta杂志尝试用Claude复核这篇小说,想让另一个AI来判断它是不是AI写的。
结果,Claude没有给出能够一锤定音的答案,也就是说,Pangram言之凿凿判成“100%AI生成”的作品,Claude却表示确定不了。
诺贝尔文学奖得主奥尔加·托卡尔丘克(Olga Tokarczuk)最近也遭遇了争议。
事件的起因,是她在采访中谈到,自己会使用AI辅助构思、资料整理、初步研究和事实核查。

这个说法很快引发外界讨论。要命的是托卡尔丘克马上要发新书,于是大家都在热议她的新小说是不是AI写的。
随后,托卡尔丘克不得不公开澄清,自己将于2026年秋季出版的波兰语新书,并不是由AI或其他人代写。她强调,几十年来,她一直独自写作。
说到底,现在AI确实越来越强了,鉴AI正在变得越来越困难。
去年底,《纽约客》刊发了一篇实验性文章。研究者用多位作家的作品微调模型,让AI学习并模仿他们的个人风格。
实验中,创意写作专业的学生在不知情的情况下阅读人类文本和AI文本,并判断自己更喜欢哪一段。结果,在接近三分之二的案例里,他们更偏好AI生成版本。
这比“AI能写小说”更麻烦。
《纽约客》作者Vauhini Vara在文章中还写道,朋友和专业读者会把AI生成的句子认成她自己的写法,也会把她真正写下的原文批评成“像AI”。
02
全程录像“自证清白”的画师欲哭无泪
“恐怖谷效应”绝不仅限于一个长得和人类似像非像的实体,在AI输出的文本和图像、视频越来越逼近人类,甚至连最有人味的“风格”都攻克的时候,人类不可避免地被激起存在主义危机。
这是现在流行“空口鉴AI”的一个核心动因。
换句话说,大家“鉴AI”是可以理解的,背后其实是某种恐惧——这是人吗?这是AI吗?我又是谁?我们是谁?
但是可以理解不代表伟光正,“鉴AI”正在给各种领域的创作者带来麻烦,让后者在创作之余还要平添“自证清白”的成本。
论AI带来的冲击,绘画圈是不陌生的。我们早在几年前就讨论过AI对绘画圈的冲击,以及很多画师对AI的抵制。
然而在当下,画师们面对的麻烦已经不仅仅是需要放着AI炼化自己的成果,而是自己手搓的作品被“鉴AI”。
在社交平台搜索“画画UP自证”,会看到很多案例。
有的画师被“鉴AI”之后,录屏展示所有的图层,以证明作品是出自自己之手。
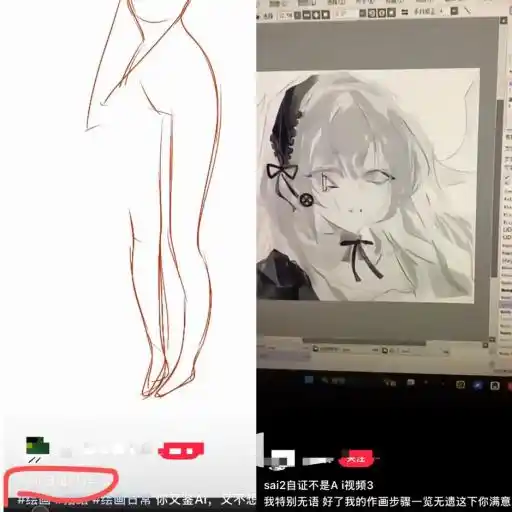
但很多时候,这并不足够。
一位插画师朋友告诉我们,现在很多插画师会在绘画的时候全程录屏,防止被“鉴AI”的时候难以自证,这也是目前最稳妥的做法。
如果没有录屏,或者是有录屏“证据”但是仍然被怀疑是“印着描摹的”,那么还有下一步——对赌。
是的,绘画界因为AI已经发展出了“鉴AI”方和“被鉴AI”方的对赌。在我们看到的一个案例当中,发帖人摆出若干理由如“头发断联”“肩颈结构有问题”等,鉴别某画师的作品疑似是将AI图垫在下方描图或者照着AI图临摹。
双方以2000元对赌,最终画师“自证成功”,发帖人给AI画师支付2000元。
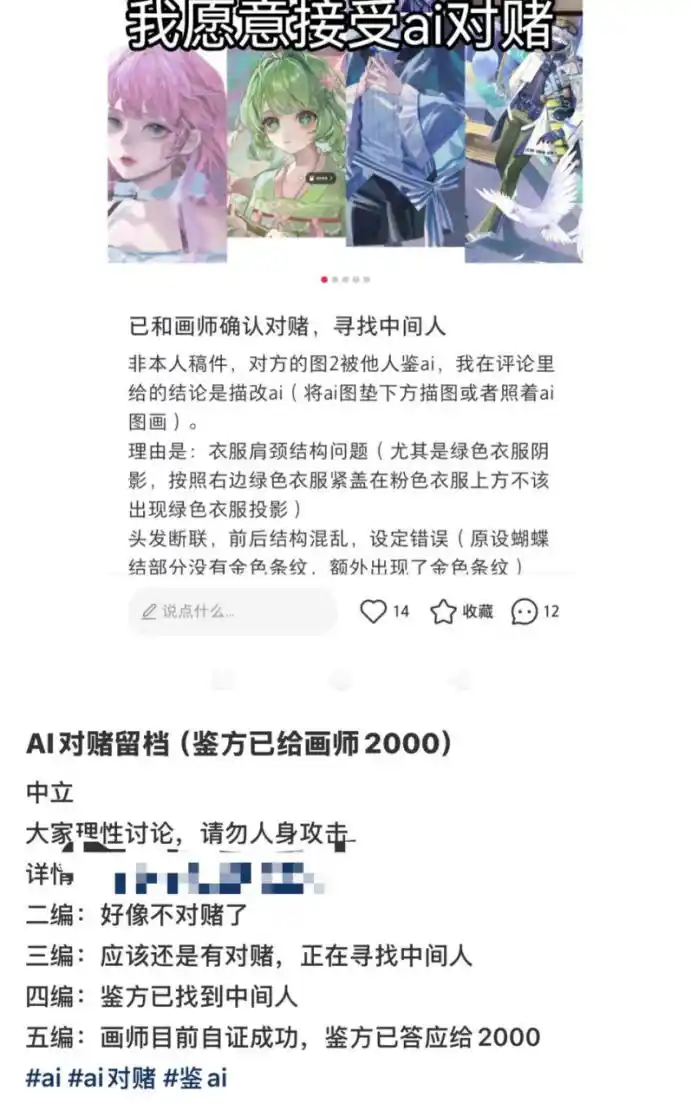
一般来说,“对赌”当中的“自证”环节,是双方约定时间进行一场绘画直播。而且直播需要多机位,比如一个机位展示屏幕作图过程,另一个机位录制画师画画的样子,以免有人“代笔”。
从很多画师的“自证帖”当中不难看出无奈的情绪,他们往往会感慨“终究轮到我了”,并发誓“这是第一次也是最后一次自证”。
就这样,一边痛恨“空口鉴AI”,另一边真的轮到自己了却不得不“自称清白”,实在难受。
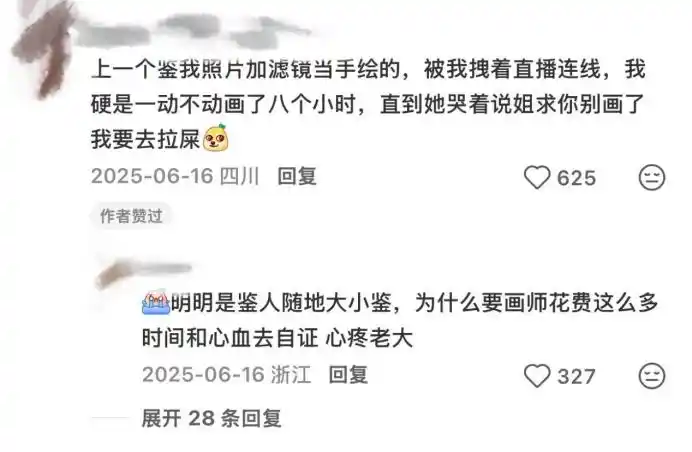
有“鉴AI”但是画师“自证”失败的案例吗?有。但是这依旧不能让“鉴AI”的行为变得理直气壮一些。毕竟“鉴AI”的成本,几乎没有。
而“鉴AI”的手段,更是粗糙——靠人眼。
这里就不得不提到最近的一个笑料,一个X用户发了一张图,说是自己用AI生成的“莫奈风格图”,还让大家“尽可能详细地说明它为什么不如真正的莫奈”。

帖子后来700万浏览量,评论区不少人开始认真“鉴AI”,说它缺少深度、颜色不统一、没有人味、构图不如真迹,甚至有人从笔触和空间感上分析得头头是道。

结果反转是:那张图本来就是莫奈真迹。
03
“鉴AI”到底谁说了算?
所以这其实是对AI越来越像人的恐惧,与没有完美“鉴AI”手段之间的矛盾。
“鉴AI”手段的粗糙,是让创作者集体陷入“自证清白”的另一个重要因素。
除了“人眼鉴别”的方式之外,正如前文提到的文学比赛冠军得主的作品,“鉴AI”的另一个主要方式是第三方检测工具Pangram。
AI检测工具在文本领域常用,容易制造一种错觉:它会给出一个百分比,比如“80%AI生成”“100%AI生成”。这个数字看上去很像结论,甚至像某种技术鉴定。

但文本检测和DNA鉴定不是一回事。它判断的其实是“这段文字在统计特征上更像什么”。
AI检测工具,也是在看“看起来像不像AI写的”。
Pangram在官网上解释,自己的AI检测器会用自然语言处理技术和大量人类写作、AI写作数据,分析AI文本中的结构、风格和语义模式。Pangram的技术报告也称,它的核心是一个基于Transformer的神经网络分类器,训练目标就是区分大型语言模型写出的文本和人类写出的文本。
也就是说,这类工具不是拿着一篇文章去查“AI文本数据库”,看它有没有命中某个已知样本。
它更像是在做模式识别。这篇文字的词汇选择、句子节奏、结构安排、语义连接方式,更接近它见过的人类文本,还是更接近它见过的AI文本。
更麻烦的是,这其中有太多特殊情况。如果一篇文章是人类写初稿,再用AI润色几句话,怎么算?如果是AI生成提纲,人类重新写成全文,怎么算?如果一段英文资料被AI翻译成中文,作者再人工修改,检测工具还能不能判断?如果一个学生本来就是非英语母语写作者,句子更规整、更模板化,会不会更容易被误伤?
在绘画领域也一样。有的画师就哀嚎——确实结构画得有问题,那是因为我技艺还需要修炼,不是因为这是AI画的呀!
2023年,斯坦福大学研究者测试了7个AI文本检测器。
他们选取了91篇非英语母语学生写的托福作文——这些作文来自托福官方考试语料,本身就是学生在真实考试环境下手写完成的,因此可以确认并不是AI生成。
结果其中89篇至少被一个检测器标记为AI生成;平均误报率达到61.22%;还有18篇被7个检测器一致判定为AI生成。也就是说,这些学生明明是在写一门外语,却因为表达更规整、更接近模板,被工具当成了机器。
当然,2023年、2024年的检测工具不能简单等同于今天的检测工具。过去几年里,商业检测器确实在迭代,一些新工具在特定测试里的表现已经明显提升。
但问题并没有得到解决。
“误判”没有被完全消除,就会给矛盾留下缝隙。
毕竟,工具给出的本来是概率,但落到人身上,就变成了指控。
04
说好的“水印”呢?
更大的问题在于,AI公司是不是应该做“来源标记”?
给所有AI内容打上原生“水印”、去不掉的那种,不就可以解决鉴别问题?
很多人一听到“水印”,想到的还是图片角落里的logo、视频画面上的平台标识,或者“AI生成”几个大字。
但今天的AI水印早就不只是这种肉眼可见的记号。
行业里大致有两类做法:一类是元数据,比如C2PA和Content Credentials,相当于给数字内容附上一张“身份说明”,记录它由什么工具生成、什么时候生成、经历过哪些编辑;
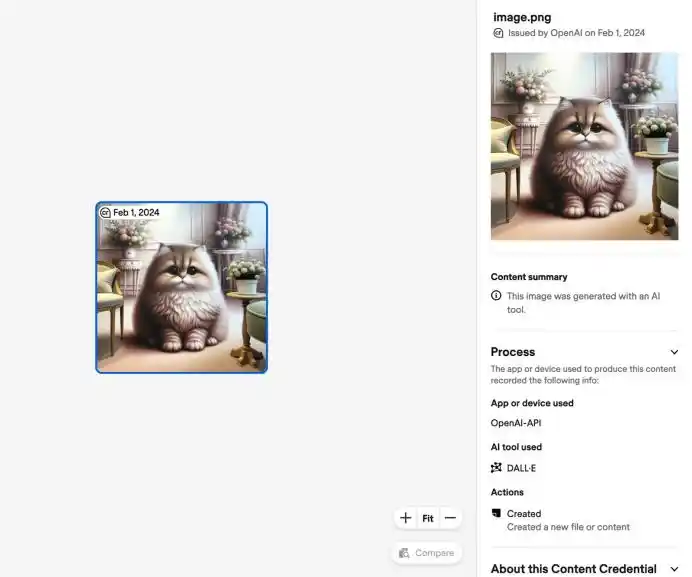
另一类是隐形水印,把人眼难以察觉、但机器可以识别的信号嵌进图像、音频、视频甚至文本里。
在图像和视频领域,这些方案已经开始落地。
谷歌DeepMind的SynthID可以给Imagen、Veo、Lyria、Gemini等工具生成的内容嵌入隐形水印。
Meta表示,Meta AI生成或编辑的图像会加入可见水印、不可见水印和元数据;OpenAI也为DALL·E 3和ChatGPT生成图片加入C2PA内容凭证,并在后来引入SynthID隐形水印。Adobe、微软、谷歌、Meta、OpenAI等公司也都参与了C2PA和内容凭证生态。

这说明,AI公司也清楚只靠肉眼判断“像不像AI”是不够的。它们已经在尝试用元数据、内容凭证、隐形水印和平台标签,为AI生成内容留下机器可读的来源信号。
但这些方案并不完美。元数据可以在截图、压缩、转发、重新上传时丢失;可见水印可以被裁掉或遮住;隐形水印更耐用,但也可能被后期处理、扰动或再生成削弱。
更关键的是,这些方案通常只能识别接入了对应系统,并且保留了对应标记的内容。也就是说,谷歌的SynthID主要识别带有SynthID的内容,OpenAI的内容凭证主要说明内容来自OpenAI系统。只要内容来自没有接入标记的模型,或者经过多次搬运,来源链就可能断掉。
到了文本,问题更复杂。
文本当然也可以做水印。它的原理是在模型生成文字时,悄悄改变某些词的选择概率,让最终文本呈现出一种人眼读不出来、但检测器可以识别的统计模式。简单说,就是让AI留下自己的“用词指纹”。
谷歌已经公开了SynthID-Text,称它可以给Gemini生成的文本嵌入水印。OpenAI也很早就被期待解决这个问题。2023年7月,OpenAI、谷歌、Meta、亚马逊、Anthropic、微软等公司达成自愿承诺,表示将研发机制,帮助用户识别AI生成内容,包括水印和内容来源标记。
但几年过去,图像、音频、视频的标记方案不断推进,文本却仍然没有一个清晰、默认启用、公众可用的通用答案。
OpenAI曾在2023年推出过AI Text Classifier,用来判断一段文字是否由AI生成,但上线时就提醒用户不要把它作为决策的唯一依据。
半年后,OpenAI因为准确率太低将其下线。
2024年,《华尔街日报》又报道称,OpenAI内部其实已经开发出一种文本水印工具,在足够长的ChatGPT生成文本上,有效率可以达到99.9%。但OpenAI最终没有公开发布它。
原因也不完全是技术问题。报道提到,OpenAI担心文本水印引发用户反弹、影响产品使用,也担心非英语用户承受额外污名化。
还有调查显示,接近30%的ChatGPT用户表示,如果启用文本水印,他们可能会减少使用。
到最后,回到“鉴AI”与“自证清白”的两方拉扯上,以上提到的所有水印方案,还不能做到万无一失。
人类有一句话是“道高一尺魔高一丈”,还有一句话是“上有政策下有对策”,只要人类还相信这两句话,“鉴AI”就不会停止。
也许有一天,“AI参与”成为默认状态,“人类原创”变得异常稀有,这场大规模的“鉴AI”与“自证清白”的拉扯才会失去意义。
本文来自微信公众号“直面AI”(ID:faceaibang),作者:小金牙,编辑:王靖