
The most ambitious consensus overhaul foe Solana to date—SIMD-0326, nicknamed “Alpenglow”—has officially moved into the community voting window, a three-epoch process that began at the start of Epoch 840 and will conclude at the end of Epoch 842.
The proposal rewrites Solana’s core consensus, replacing Proof-of-History plus TowerBFT with a modern architecture centered on a direct-vote finality engine (“Votor”). The authors say Alpenglow significantly reduces latency (from 12.8 seconds under TowerBFT to as low as 100–150 milliseconds) while eliminating heavy vote-gossip traffic through off-chain messaging and signature aggregation.
Solana Validators Begin Deciding Future Of Alpenglow
Governance mechanics for SIMD-0326 are unusually explicit. Vote tokens are claimable by validators according to captured stake weights, using a Merkle distributor tool; tokens may be sent to “Yes,” “No,” or “Abstain” accounts. Passage requires a supermajority: the sum of Yes votes is equal to or greater than 2/3 of the total sum of Yes + No votes,” with a quorum of 33% in which abstentions count toward quorum but not toward the Yes/No denominator.
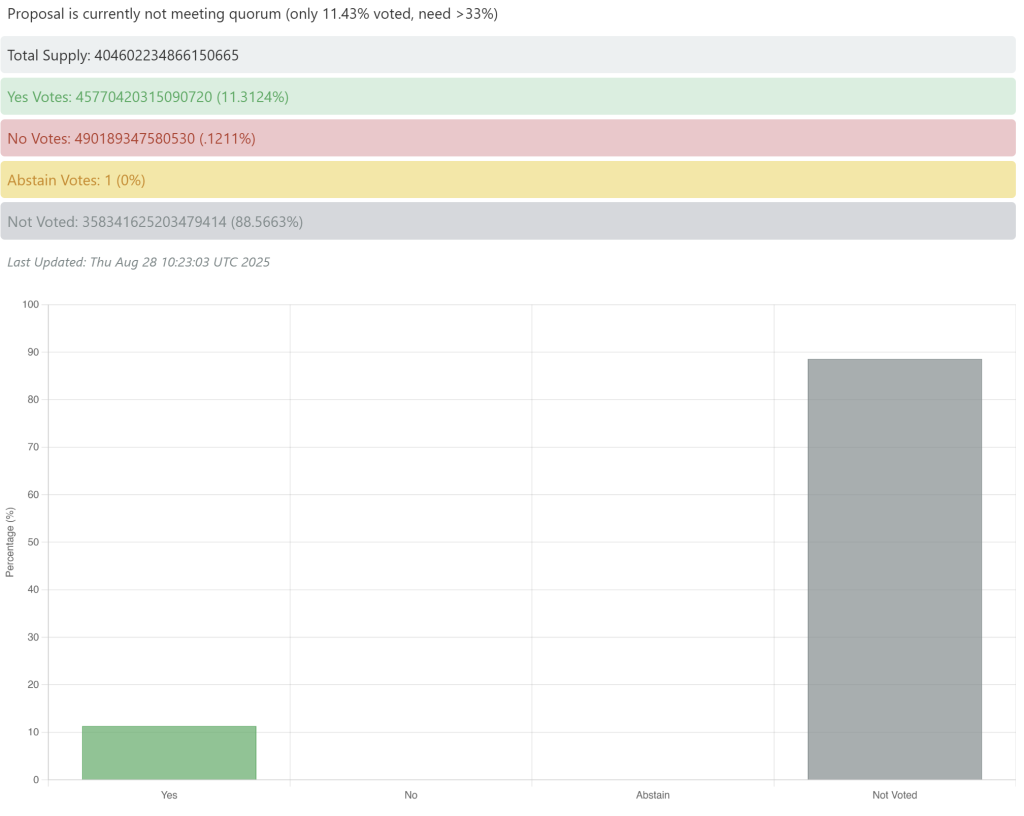
On day one of the window (Epoch 840), early snapshots show modest—but distinctly positive—participation. Multiple market data posts report turnout near 11.5%, with roughly 11.3% of stake signaling “Yes” and negligible “No.” Because the overwhelming share of stake has not yet cast ballots, this should be treated as an initial reading rather than a trend. A public tally dashboard is being maintained by Staking Facilities.
Alpenglow’s design changes go beyond speed. The protocol introduces certificate-based notarization and finalization, aggregates validator votes off-chain to reduce overhead, and rebalances incentives around voting. Notably, the proposal replaces per-slot on-chain vote fees with a fixed “Validator Admission Ticket” (VAT) currently set at 1.6 SOL per epoch and burned—an economic continuity measure intended to keep cost structures comparable to today’s while votes move off-chain.
“Before each epoch, each validator must pay a fixed fee—initially set to 1.6 SOL per epoch,” the authors write, adding that the figure mirrors roughly 80% of current on-chain voting costs. Forum participants have already begun debating whether a flat VAT raises entry barriers for smaller operators, underscoring that the governance discussion is as much about economics as it is about protocol mechanics.
Timing matters for operators and tokenholders following the vote. Solana epochs are approximately two days in length, so a three-epoch voting window implies about six days from start to finish. The network entered Epoch 840 on August 27, 2025, which places the expected end of the voting window around September 2, 2025, when Epoch 842 concludes.
If the supermajority threshold is reached, Alpenglow would clear governance, with subsequent activation depending on client readiness and the standard Solana release process. For now, the focus is on turnout. With ~90% of stake yet to be tallied in the opening snapshot, every validator ballot over the coming epochs will carry outsized weight in determining whether Solana pursues ~150-millisecond finality as its next consensus horizon.
At press time, SOL traded at $215.

Related Posts









