Биткоин застрял всего в 2% от своего исторического максимума, но аналитики предупреждают: третий квартал может стать для первой криптовалюты настоящим испытанием. Причина? Слишком много оптимизма от розничных инвесторов.
Брайан Квинливан (Brian Quinlivan), аналитик Santiment, объясняет парадокс: «Мы видим ожидания следующего исторического максимума биткоина в социальных сетях. Поскольку рынки движутся в противоположном направлении от ожиданий розничных трейдеров, это обычно указывает на то, что мы еще не готовы к новому бычьему ралли».
За последние 12 месяцев рост составил впечатляющие 61,32%, но этого может оказаться недостаточно для прорыва.
Фрустрация как катализатор роста
Квинливан считает, что именно отсутствие сомнений мешает установлению новых рекордов. Однако несколько «болезненных промахов» могут изменить ситуацию: «Не удивлюсь, если мы прорвемся очень скоро после нескольких фрустрирующих попыток, которые заставят мелких трейдеров разочароваться и потерять терпение к BTC, нейтрализовав этот уровень оптимизма».
Индекс страха и жадности показывает значение 72 из 100 — это уровень «жадности», что подтверждает избыточный оптимизм инвесторов.
Q3: время испытаний для биткоина
Все указывает на то, что биткоин, скорее всего, покажет слабые результаты в третьем квартале этого года. Макроэкономическая неопределенность становится серьезной проблемой для трейдеров. Несмотря на политическое давление в пользу снижения ставок, Федеральная резервная система, похоже, готова сохранить процентные ставки на стабильном уровне, что может ослабить привлекательность биткоина для получения сверхдоходности.
По данным инструмента FedWatch от CME, 99,9% участников рынка ожидают, что 18 июня ФРС сохранит ставки в диапазоне 4,25-4,50%.
Историческое проклятие третьего квартала
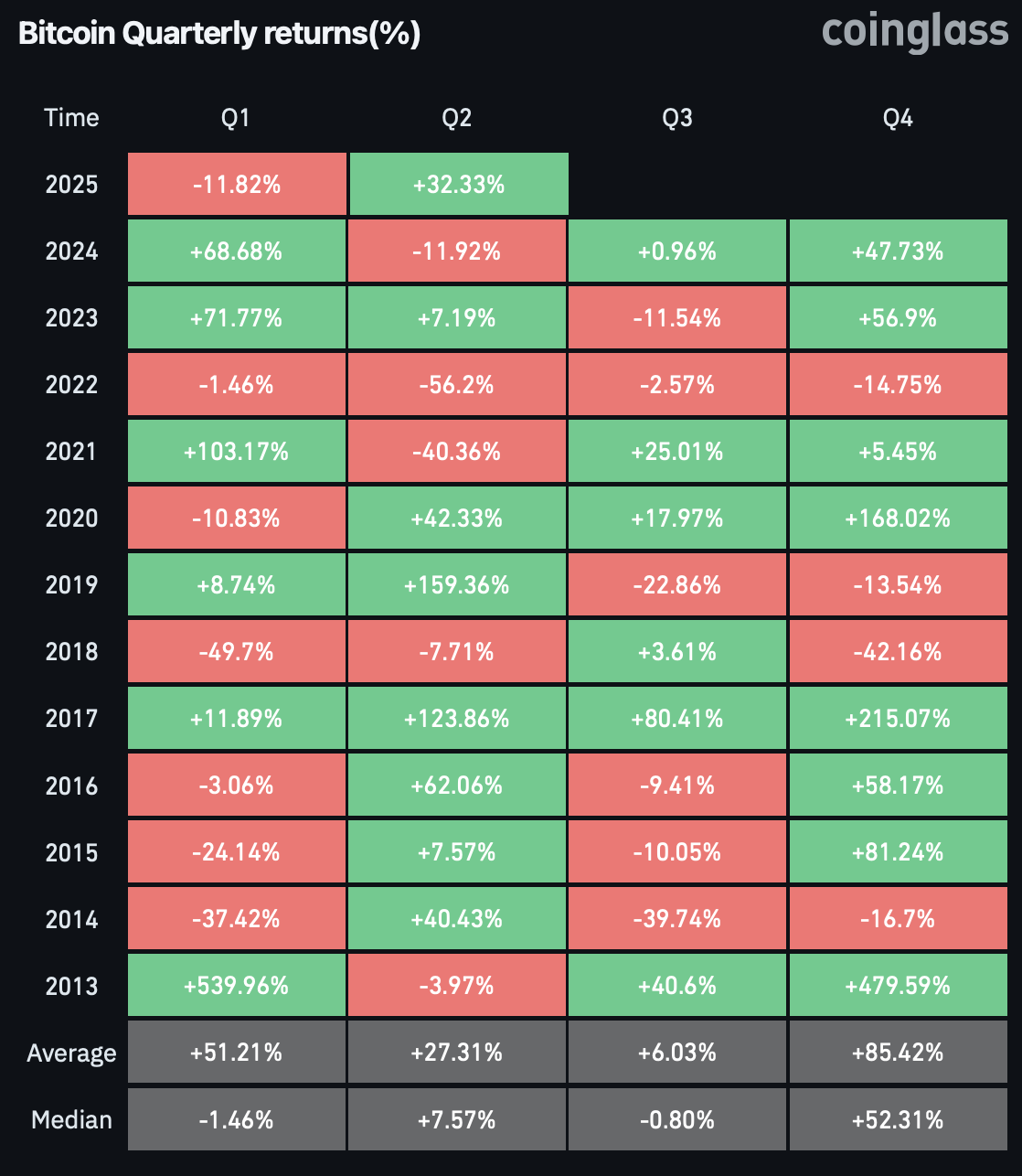
Статистика не на стороне биткоина. С 2013 года третий квартал каждого года был самым слабым для первой криптовалюты, принося в среднем всего 6,03% доходности. Для сравнения: четвертый квартал показывает среднюю доходность 85,42% — колоссальная разница, которая заставляет задуматься о сезонных факторах.
Общий объем торговли криптовалютами может снизиться в ближайшее время, поскольку наступление лета в Северном полушарии приводит к тому, что многие инвесторы уходят в отпуска. Это сезонное затишье повышает шансы бокового движения или даже резких откатов, поскольку трейдеры фиксируют прибыль от предыдущих достижений.
Ethereum в роли догоняющего
Пока биткоин борется с психологическими барьерами, все больше внимания привлекает Ethereum. Квинливан отмечает «высокий уровень оптимизма в отношении Ethereum» и подчеркивает, что актив «играет в догонялки с тех пор, как рынки начали восстановление в середине апреля».
«Рост биткоина за последние пару месяцев, конечно, позволил перераспределить прибыль и дать возможность другим активам достичь роста. И до недавнего времени не было ясно, пока ETH действительно не показал максимальный медвежий настрой пару месяцев назад», — поясняет аналитик.
Текущая ситуация создает интересную дилемму для инвесторов. Биткоин находится на пороге исторического прорыва, но избыток оптимизма может отложить этот момент. Ethereum же получил второе дыхание и может удивить рынок своей динамикой в период традиционной летней слабости.








