想知道哪款大模型在 OpenClaw真实世界代理任务中真正最强?
MyToken基于测评网站整理了一套专注评估AI编码代理实际能力的透明基准,只看成功率这一个核心维度(速度和成本属于其他独立维度,后续再单独分析)。完全公开、可复现,只呈现严谨的测评标准 + 最新成功率Top 10排行。
一、测评维度:成功率
具体标准:AI代理完整准确地完成给定任务的数量占比。每项任务都采用高度标准化的流程:
-
精准的用户提示词(Prompt))
发送给智能体完整来模拟真实的用户请求场景
-
预期行为(Expected Behavior )
均说明可接受的实现方式与关键决策要点
-
评分标准(checklist)
列出可逐条核验的原子化成功判定清单
二、三种评分方式
此次测评主要采取3种评分方式
-
自动化检查:Python脚本直接验证文件内容、执行记录、工具调用等客观结果
-
LLM大模型裁判:Claude Opus按照详细量表打分(内容质量、合适度、完整性等)
-
混合模式:自动化客观检查 + LLM裁判定性评估结合
所有任务定义、Prompt、评分逻辑全部公开,以便复测验证。
三、用于测评的任务
此次基准测试涵盖23 个不同类别的任务。覆盖基础交互、文件/代码操作、内容创作、研究分析、系统工具调用、记忆持久化等多个维度,高度贴近开发者日常使用OpenClaw的场景:
-
Sanity Check(自动化)——处理简单指令并正确回复问候
-
Calendar Event Creation(自动化)——自然语言生成标准ICS日历文件
-
Stock Price Research(自动化)——实时查询股价并输出格式化报告
-
Blog Post Writing(LLM裁判)——写一篇约500字结构化Markdown博客
-
Weather Script Creation(自动化)——编写带错误处理的Python天气API脚本
-
Document Summarization(LLM裁判)——3段式精炼总结核心主题
-
Tech Conference Research(LLM裁判)——调研整理5场真实科技会议信息(名称、日期、地点、链接)
-
Professional Email Drafting(LLM裁判)——礼貌拒绝会议并提出替代方案
-
Memory Retrieval from Context(自动化)——从项目笔记中精准提取日期、成员、技术栈等
-
File Structure Creation(自动化)——自动生成标准项目目录、README、.gitignore
-
Multi-step API Workflow(混合)——读取配置 → 编写调用脚本 → 完整文档化
-
Install ClawdHub Skill(自动化)——从技能仓库安装并验证可用性
-
Search and Install Skill(自动化)——搜索天气类技能并正确安装
-
AI Image Generation(混合)——按描述生成并保存图片
-
Humanize AI-Generated Blog(LLM裁判)——把机器味内容改成自然口语
-
Daily Research Summary(LLM裁判)——多份文档合成连贯每日摘要
-
Email Inbox Triage(混合)——分析多封邮件并按紧急度整理报告
-
Email Search and Summarization(混合)——搜索归档邮件并提炼关键信息
-
Competitive Market Research(混合)——企业APM领域竞品分析
-
CSV and Excel Summarization(混合)——分析表格文件并输出洞察
-
ELI5 PDF Summarization(LLM裁判)——用5岁小孩能懂的语言解释技术PDF
-
OpenClaw Report Comprehension(自动化)——从研究报告PDF中精准回答特定问题
-
Second Brain Knowledge Persistence(混合)——跨会话存储并准确回忆信息
四、核心结论:成功率Top 10大模型排行 (Best %/Avg % )
-
数据更新至2026年4月7日
-
Best % 为单次最高成功率,Avg % 为多次平均成功率,更反映稳定性
以下是成功率最高的前十模型
-
anthropic/claude-opus-4.6(Anthropic)——93.3% / 82.0%
-
arcee-ai/trinity-large-thinking(Arcee AI)——91.9% / 91.9%
-
openai/gpt-5.4(OpenAI)——90.5% / 81.7%
-
qwen/qwen3.5-27b(Qwen)——90.0% / 78.5%
-
minimax/minimax-m2.7(MiniMax)——89.8% / 83.2%
-
anthropic/claude-haiku-4.5(Anthropic)——89.5% / 78.1%
-
qwen/qwen3.5-397b-a17b(Qwen)——89.1% / 80.4%
-
xiaomi/mimo-v2-flash(Xiaomi)——88.8% / 70.2%
-
qwen/qwen3.6-plus-preview(Qwen)——88.6% / 84.0%
-
nvidia/nemotron-3-super-120b-a12b(NVIDIA)——88.6% / 75.5%
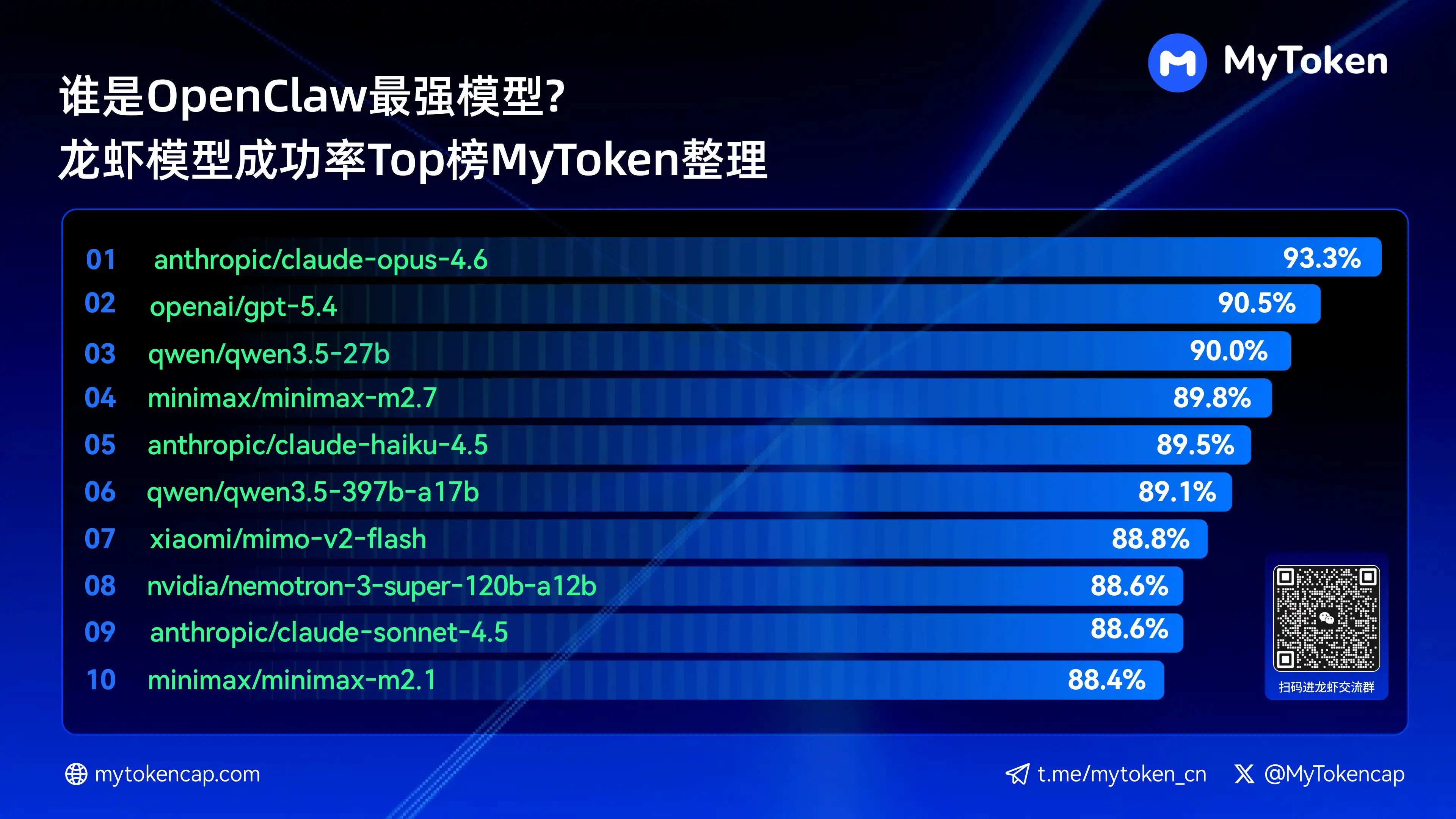
Claude Opus 4.6目前以93.3%的最高成功率领跑,但Arcee的Trinity在平均稳定性上表现亮眼,千问系列也有多款进入前十,展现出很强的性价比潜力。成功率是基础门槛,后续速度和成本维度会进一步影响实际体验。
这套23任务基准完全透明,强烈建议大家结合自身场景实际测试。更多其他模型排名,敬请期待MyToken即将推出的智能体排行榜功能。
(数据来源于PinchBench公开的OpenClaw代理基准测试,持续更新中。)





