一行import,MoE大模型微调提速3.7倍。
英伟达最新研究成果现已开源:NeMo AutoModel,专为大规模构建和微调生成式AI模型而打造。
在Hugging Face Transformers v5的基础之上,NeMo AutoModel能做到不改代码API,只添一行import,就实现对MoE模型更快速的微调。

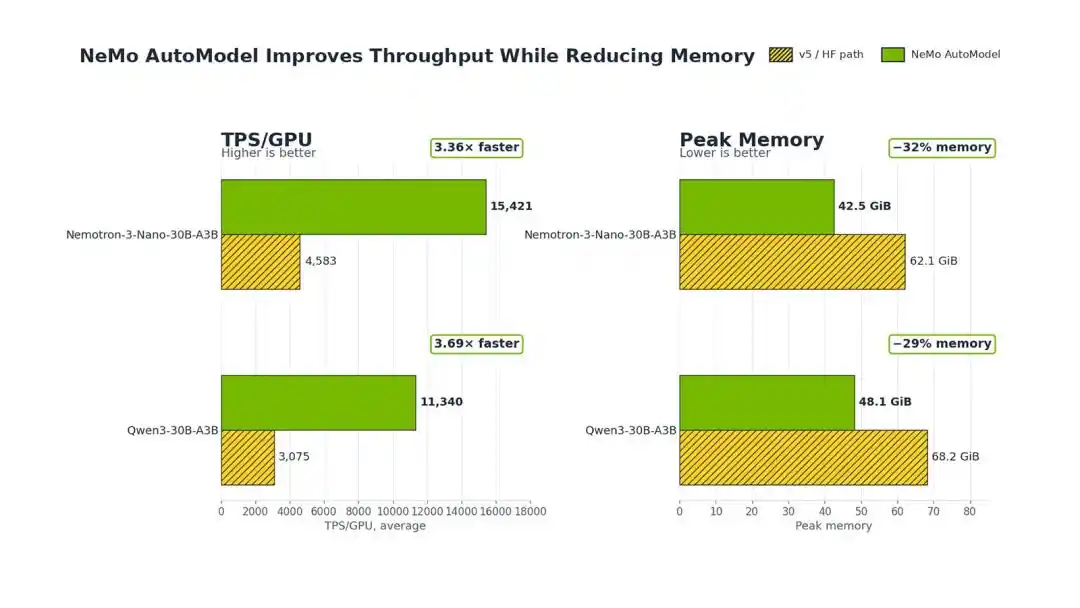
实验显示,相比Hugging Face原版Transformers v5,英伟达NeMo AutoModel能在MoE微调中实现3.4-3.7倍训练吞吐提升,并减少29%-32% GPU显存占用。
在单节点8xH100 80GB GPU上,以Qwen3-30B-A3B为例,NeMo AutoModel直接把TPS/GPU(每GPU每秒吞吐量)从3075拉到11340,提升达到3.69倍。
核心技术解析
MoE已经成为当前前沿模型的主流架构,但MoE也给高效训练带来了新的挑战:
专家并行、通信融合、kernel优化......这些复杂工程都需要配套的基础设施来支持。
HuggingFace的Transformers v5是目前被用得比较多的MoE训练“通用底座”。v5增强了对MoE的原生支持,引入了expert backends、dynamic weight loading、分布式执行等MoE基础能力。

这一次,英伟达的思路就是站在前辈的肩膀上,兼容HuggingFace Transformers的API,让大家能不大改代码,就在MoE微调里获得更高训练吞吐和更低显存占用。
具体来说,NeMo AutoModel在Transformers v5的基础上,增加了专家并行(EP)、DeepEP和TransformerEngine。
专家并行(Expert Parallelism)
专家并行技术主要用来降低内存压力。
EP把专家权重分布到了多个GPU上,每张GPU不再完整持有所有expert,而是只持有其中一部分参数。
举个例子,8张GPU上ep_size=8,专家权重被分布至8块GPU,每张GPU的MoE内存占用能降到原来的1/8。
从实验结果来看,对于Qwen3,这项技术能将峰值内存从68.2GiB降至48.1GiB,降幅29%。
对于Nemotron Nanomo模型,内存占用从62.1 GiB降至42.5 GiB,降幅 32%。
释放出的空间可以用来支持更大批次、更长的序列。
DeepEP
DeepEP实现了计算和通信的融合。
传统方式里,token分发和专家计算之间有明显通信成本。DeepEP把token分发和组合操作整合进优化的GPU内核,实现了通信过程和专家计算的重叠。
TransformerEngine
TransformerEngine内核为各类核心运算提供加速。
这项技术提供了融合注意力机制、线性层和RMSNorm等实现,不只加速MoE层,也加速普通Transformer层。
一行import,3倍速度提升
总结来说,对于原本就用上了Transformers v5的盆友们来说,英伟达NeMo AutoModel带来了一个无痛升级方案:
只需加上一行import代码,即可获得3倍MoE微调速度提升。

在Qwen3-30B-A3B和Nemotron 3 Nano 30B-A3B上,相较于Transformers v5,该方案可以实现3.4-3.7倍的训练吞吐量提升,同时内存消耗降低29%-32%。
英伟达还展示了Nemotron 3 Ultra 550B A55B在16个H100节点、128张GPU上的全参数微调结果。
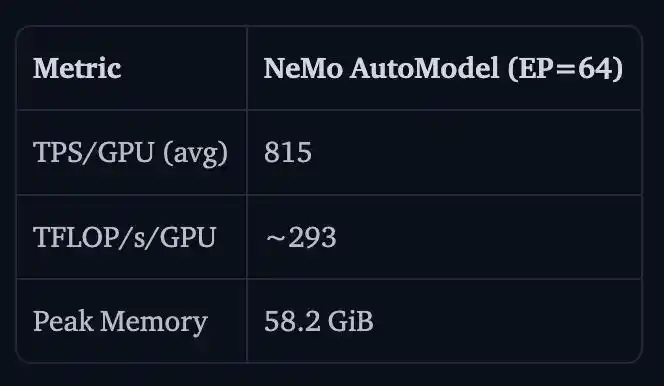
TPS/GPU为815,TFLOP/s/GPU约为293,峰值内存为58.2GiB。
这里没跟v5对比的原因,是Transformers v5在这种规模下会直接撑爆内存 ̄_(ツ)_/ ̄
感兴趣的话,英伟达已经把代码、配置和基准测试脚本都放在GitHub上了:https://github.com/NVIDIA-NeMo/Automodel/tree/blog/transformers-v5-automodel/blog_experiments
具体使用指南在这里:https://docs.nvidia.com/nemo/automodel/latest/get-started/hf-compatibility
本文来自微信公众号“量子位”,作者:鱼羊






