八年前,中兴心脏骤停。
2018 年 4 月 16 日,美国商务部工业与安全局的一纸禁令,让中兴通讯这家拥有 8 万名员工、年营收超千亿的全球第四大通信设备商,在一夜之间停摆。禁令内容很简单,未来七年,禁止任何美国公司向中兴出售零部件、商品、软件和技术。
没有了高通的芯片,基站停产。没有了谷歌的安卓授权,手机也没有能用的系统了。23 天后,中兴发布公告,称公司主要经营活动已无法进行。
不过中兴最终活了下来,但代价是 14 亿美元。
10 亿美元罚款,一次性付清;4 亿美元保证金,存入美国银行的托管账户。此外,全部高管换血,接受美方合规监督团队进驻。2018 年全年,中兴净亏损 70 亿元人民币,营收同比暴跌 21.4%。
时任中兴董事长殷一民在内部信中写道:「我们身处在一个复杂的、高度依赖全球供应链的产业中。」这句话,在当时听来,是反思,也是无奈。
八年后,2026 年 2 月 26 日,中国 AI 独角兽 DeepSeek 宣布,其即将发布的 V4 多模态大模型,将优先与国产芯片厂商深度合作,首次实现从预训练到精调的全流程非英伟达方案。
翻译一下就是:我们不用英伟达了。
消息一出,市场的第一反应是质疑。英伟达在全球 AI 训练芯片市场的份额超过 90%,放弃它,这在商业上合理吗?
但 DeepSeek 的选择背后,藏着一个比商业逻辑更大的问题:中国 AI,到底需要一场怎样的算力独立?
被卡脖子的到底是什么
很多人以为,芯片禁令卡住的是硬件。但真正让中国 AI 公司感到窒息的,是一个叫 CUDA 的东西。
CUDA,全称 Compute Unified Device Architecture,是英伟达在 2006 年推出的一套并行计算平台和编程模型。它允许开发者直接调用英伟达 GPU 的算力,来加速各种复杂的计算任务。
在 AI 时代到来之前,这只是一个属于少数极客的工具。但当深度学习的浪潮袭来,CUDA 变成了整个 AI 产业的地基。
AI 大模型的训练,本质上就是海量的矩阵运算。而这恰恰是 GPU 最擅长的工作。
英伟达凭借提前十几年的布局,用 CUDA 为全球的 AI 开发者搭建了一整套从底层硬件到上层应用的完整工具链。今天,全球所有主流的 AI 框架,从谷歌的 TensorFlow 到 Meta 的 PyTorch,底层都与 CUDA 深度绑定。
一个 AI 专业的博士生,从入学第一天起,就是在 CUDA 的环境里学习、编程、做实验。他写的每一行代码,都在加固英伟达的护城河。

截至 2025 年,CUDA 生态已经拥有超过 450 万开发者,覆盖了 3000 多个 GPU 加速应用,全球超过 4 万家公司在使用 CUDA。这个数字意味着全球 90% 以上的 AI 开发者,都被绑定在英伟达的生态里。
CUDA 的可怕之处在于,它是一个飞轮。越多的开发者使用,就会产生越多的工具、库和代码,生态就越繁荣;生态越繁荣,就越能吸引更多的开发者加入。这个飞轮一旦转起来,就几乎无法被撼动。
结果就是,英伟达卖给你最贵的铲子,还定义了唯一的挖矿姿势。你想换一把铲子?可以。但你得先把过去十几年里,全球几十万最聪明的大脑在这个姿势下积累的所有经验、工具和代码,全部重写一遍。
这个成本,谁来付?
所以,当 2022 年 10 月 7 日,BIS 第一轮管制落地,限制英伟达 A100 和 H100 对华出口时,中国的 AI 公司们,第一次集体感受到了中兴式的窒息感。英伟达随后推出了「中国特供版」A800 和 H800,降低了芯片间的互联带宽,勉强维持供应。
但仅仅一年后,2023 年 10 月 17 日,第二轮管制再次收紧,A800 和 H800 也被禁,13 家中国公司被列入实体清单。英伟达不得不再推出进一步阉割的 H20。到 2024 年 12 月,拜登政府任期内的最后一轮管制落地,连 H20 的出口都被严格限制。
三轮管制,层层加码。
但这一次,故事的走向,和当年的中兴完全不同。
一场非对称的突围
禁令之下,所有人都以为,中国 AI 的大模型之梦会就此终结。
他们都错了。面对封锁,中国公司并没有选择正面硬刚,而是开始了一场突围。这场突围的第一个战场,不在芯片,而在算法。
2024 年底到 2025 年,中国的 AI 公司们集体转向了一个技术方向:混合专家模型。
简单来说,就是把一个巨大的模型拆分成很多个小专家,处理任务时只激活其中最相关的几个,而不是让整个模型都动起来。
DeepSeek 的 V3 就是这个思路的典型代表。它拥有 6710 亿个参数,但每次推理只激活其中的 370 亿个,仅占总量的 5.5%。训练成本方面,它使用了 2048 块英伟达 H800 GPU,训练 58 天,总花费 557.6 万美元。作为对比,外界对 GPT-4 训练成本的估算,大约在 7800 万美元。一个量级的差距。
算法上的极致优化,直接反映到了价格上。DeepSeek 的 API 价格,输入每百万 Token 仅 0.028 到 0.28 美元,输出 0.42 美元。而 GPT-4o 的输入价格是 5 美元,输出 15 美元。Claude Opus 更贵,输入 15 美元,输出 75 美元。换算下来,DeepSeek 比 Claude 便宜了 25 到 75 倍。
这个价格差,在全球开发者市场上反响巨大。2026 年 2 月,全球最大的 AI 模型 API 聚合平台 OpenRouter 上,中国 AI 模型的周调用量在三周内暴涨 127%,首次超越美国。一年前,中国模型在 OpenRouter 上的份额不足 2%。一年后,增长了 421%,逼近六成。
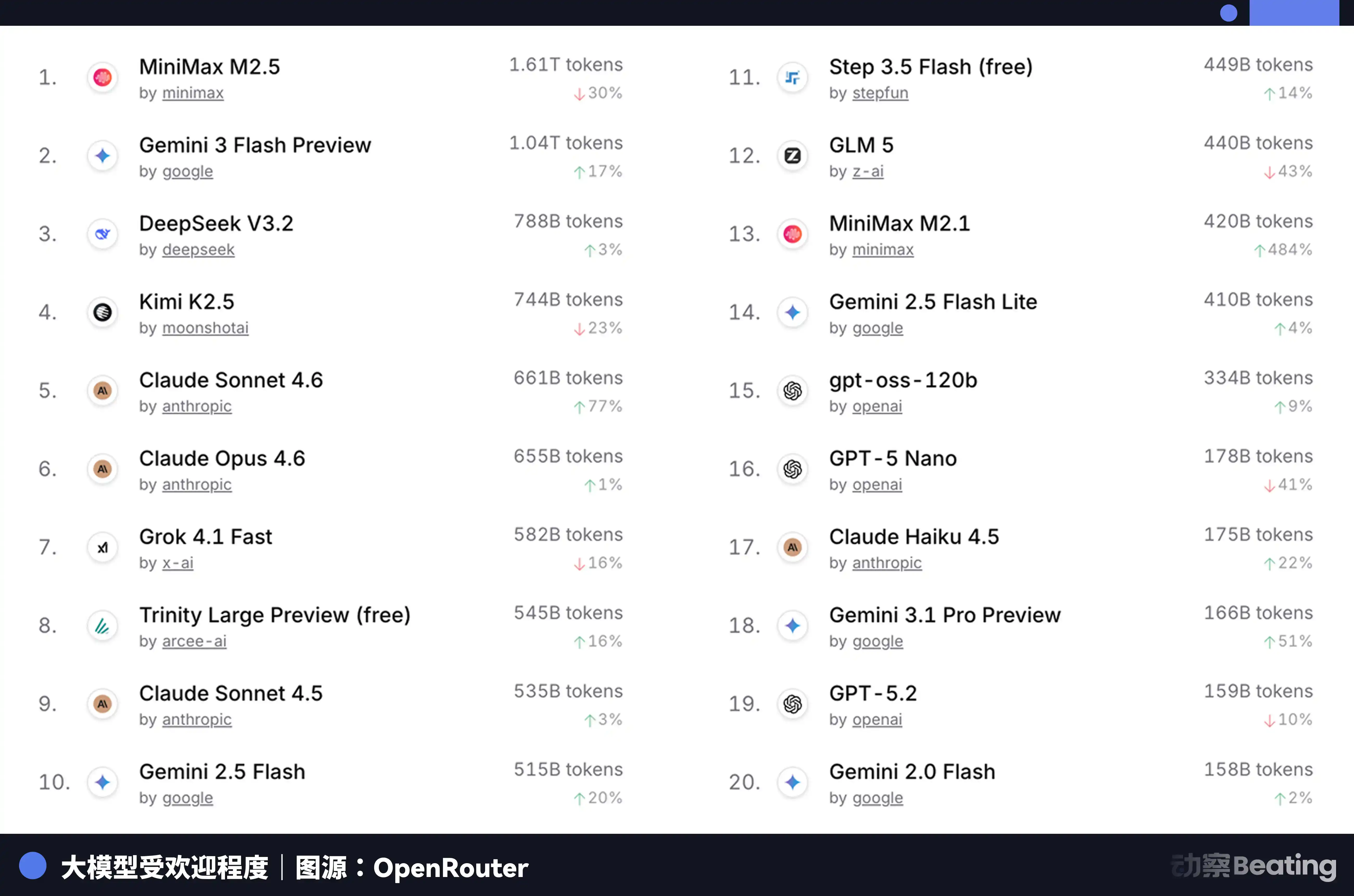
这组数据背后,有一个容易被忽视的结构性变化。2025 年下半年开始,AI 应用的主流场景从聊天转向了 Agent。Agent 场景下,一次任务的 Token 消耗量是简单聊天的 10 到 100 倍。当 Token 的消耗量指数级增长时,价格就成了决定性因素。中国模型的极致性价比,恰好踩中了这个窗口。
但问题是,推理成本的降低,并没有解决训练的根本问题。一个大模型如果不能在最新的数据上持续训练、迭代,它的能力就会迅速退化。而训练,依然是那个绕不开的算力黑洞。
那么,训练的「铲子」,从哪里来?
备胎的转正
江苏兴化,苏中小城,以不锈钢和健康食品闻名,此前和 AI 没有任何关系。但 2025 年,一条 148 米长的国产算力服务器产线在这里建成投产,从签约到投产,只用了 180 天。
这条产线的核心,是两颗完全国产的芯片:龙芯 3C6000 处理器和太初元碁 T100 AI 加速卡。龙芯 3C6000,从指令集到微架构全部自主研发。太初元碁脱胎于国家超级计算无锡中心和清华大学团队,采用异构众核架构。
这条产线满产时,5 分钟下线一台服务器,这条生产线总投资 11 亿元,预计年产 10 万台。
更重要的是,基于这些国产芯片组成的万卡集群,已经开始承接真正的大模型训练任务。
2026 年 1 月,智谱 AI 联合华为发布了 GLM-Image,这是首个完全依托国产芯片实现全程训练的 SOTA 图像生成模型。2 月,中国电信的千亿级「星辰」大模型,在上海临港的国产万卡算力池上完成了全流程训练。

这些案例的意义在于,它们证明了一件事:国产芯片,已经从「能用于推理」跨越到了「能用于训练」。这是质变。推理只需要跑已经训练好的模型,对芯片的要求相对较低;而训练需要处理海量数据、进行复杂的梯度计算和参数更新,对芯片的算力、互联带宽和软件生态的要求,高出一个数量级。
承担这些任务的核心力量,是华为的昇腾系列芯片。截至 2025 年底,昇腾生态的开发者数量已突破 400 万,合作伙伴超过 3000 家,43 个业界主流大模型基于昇腾完成了预训练,200 多个开源模型完成了适配。2026 年 3 月 2 日的 MWC 大会上,华为还面向海外市场首发了新一代算力底座 SuperPoD。
昇腾 910B 的 FP16 算力已经对标英伟达 A100。虽然差距依然存在,但已经从不可用变成了可用,从可用正在走向好用。生态的建设,不能等到芯片完美了再开始,必须在够用的阶段就大规模铺开,用真实的业务需求去倒逼芯片和软件的迭代。字节跳动、腾讯、百度对国产算力服务器的导入目标,2026 年普遍较上一年翻倍增长。工信部的数据显示,中国智算规模已达 1590 EFLOPS。2026 年,正在成为国产算力规模部署的元年。
美国电荒与中国出海
2026 年初,承载了全球大量数据中心流量的弗吉尼亚州,暂停批准新的数据中心建设项目。佐治亚州跟进,暂停审批延续到 2027 年。伊利诺伊州、密歇根州也相继出台限制措施。
根据国际能源署的数据,2024 年美国数据中心耗电量已达 183 太瓦时,约占全国总用电量的 4%。到 2030 年,这个数字预计翻倍至 426TWh,占比可能突破 12%。Arm 公司 CEO 更是预测,到 2030 年,AI 数据中心将消耗美国 20% 到 25% 的电力。
美国的电网已经不堪重负。覆盖美国东部 13 个州的 PJM 电网面临 6GW 的容量短缺。到 2033 年,美国整体面临 175GW 的电力容量缺口,相当于 1.3 亿户家庭的用电量。数据中心集中区域的批发电力成本,比五年前高出了 267%。
算力的尽头,是能源。而在能源这个维度上,中美之间的差距,比芯片还要大,只不过方向反了过来。
中国的年发电量是 10.4 万亿度,美国是 4.2 万亿度,中国是美国的 2.5 倍。更关键的是,中国的居民生活用电仅占总用电量的 15%,而美国这个比例是 36%。这意味着中国有远比美国更大的工业用电余量可以投入算力建设。
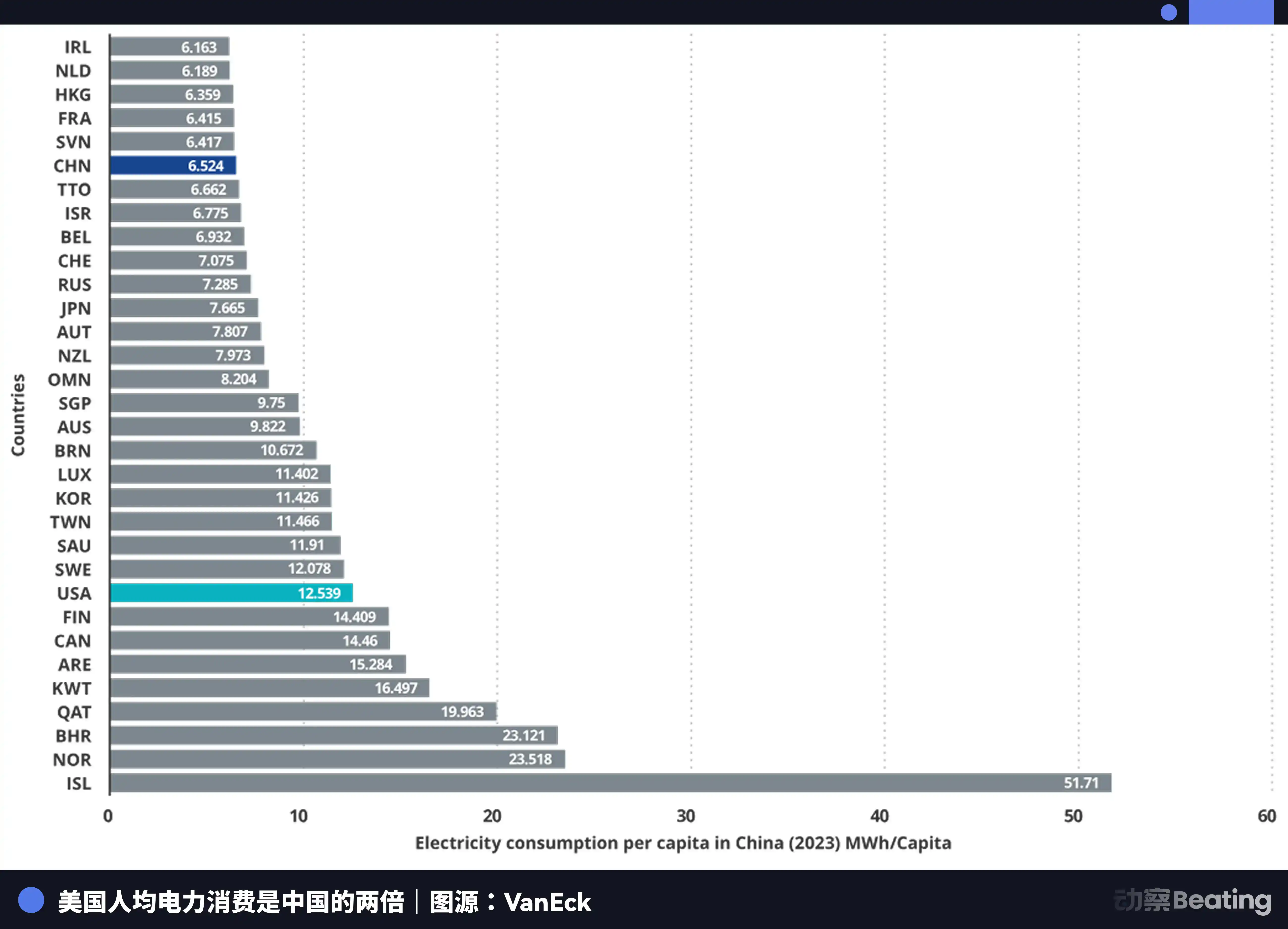
在电价上,美国 AI 公司聚集区的电价在 0.12 到 0.15 美元每千瓦时,而中国西部的工业电价约为 0.03 美元,仅为美国的四分之一到五分之一。
中国的发电增量,已经达到美国的 7 倍。
就在美国为电发愁的时候,中国的 AI 正在悄悄出海。但这一次出海的,不是产品,不是工厂,而是 Token。
Token,AI 模型处理信息的最小单位,正在成为一种新的数字商品。它从中国的算力工厂里被生产出来,通过海底光缆输送到全球。
DeepSeek 的用户分布数据很能说明问题:中国本土占 30.7%,印度 13.6%,印尼 6.9%,美国 4.3%,法国 3.2%。它支持 37 种语言,在巴西等新兴市场广受欢迎。全球有 2.6 万家企业开通了账户,3200 家机构部署了企业版。
2025 年,58% 的新 AI 创业公司把 DeepSeek 纳入了技术栈。在中国,DeepSeek 拿下了 89% 的市场份额。而在其他受制裁国家,市场份额则在 40%~60% 不等。
这幅景象,像极了四十年前的另一场关于产业自主权的战争。
1986 年的东京,在美国的强大压力下,日本政府签订了《美日半导体协议》。协议的核心条款有三条:要求日本开放半导体市场,美国芯片在日本的市场份额须达到 20% 以上;严禁日本半导体以低于成本价格出口;对日本出口的 3 亿美元芯片征收 100% 惩罚性关税。同时,美国否决了富士通对仙童半导体的收购。
那一年,日本半导体产业正处在巅峰。1988 年,日本控制了全球半导体市场 51% 的份额,美国只有 36.8%。全球十大半导体公司,日本独占六席:NEC 排名第二,东芝第三,日立第五,富士通第七,三菱第八,松下第九。1985 年,Intel 在美日半导体争夺战中亏损 1.73 亿美元,濒临破产。
但协议签订后,一切都变了。
美国通过 301 调查等手段,对日本半导体企业发起了全方位的压制。同时扶持韩国的三星、海力士,以更低的价格冲击日本的市场。日本的 DRAM 份额从 80% 跌至 10%。到 2017 年,日本 IC 市场份额仅剩 7%。曾经不可一世的巨头们,或被拆分,或被收购,或在无休止的亏损中黯然离场。
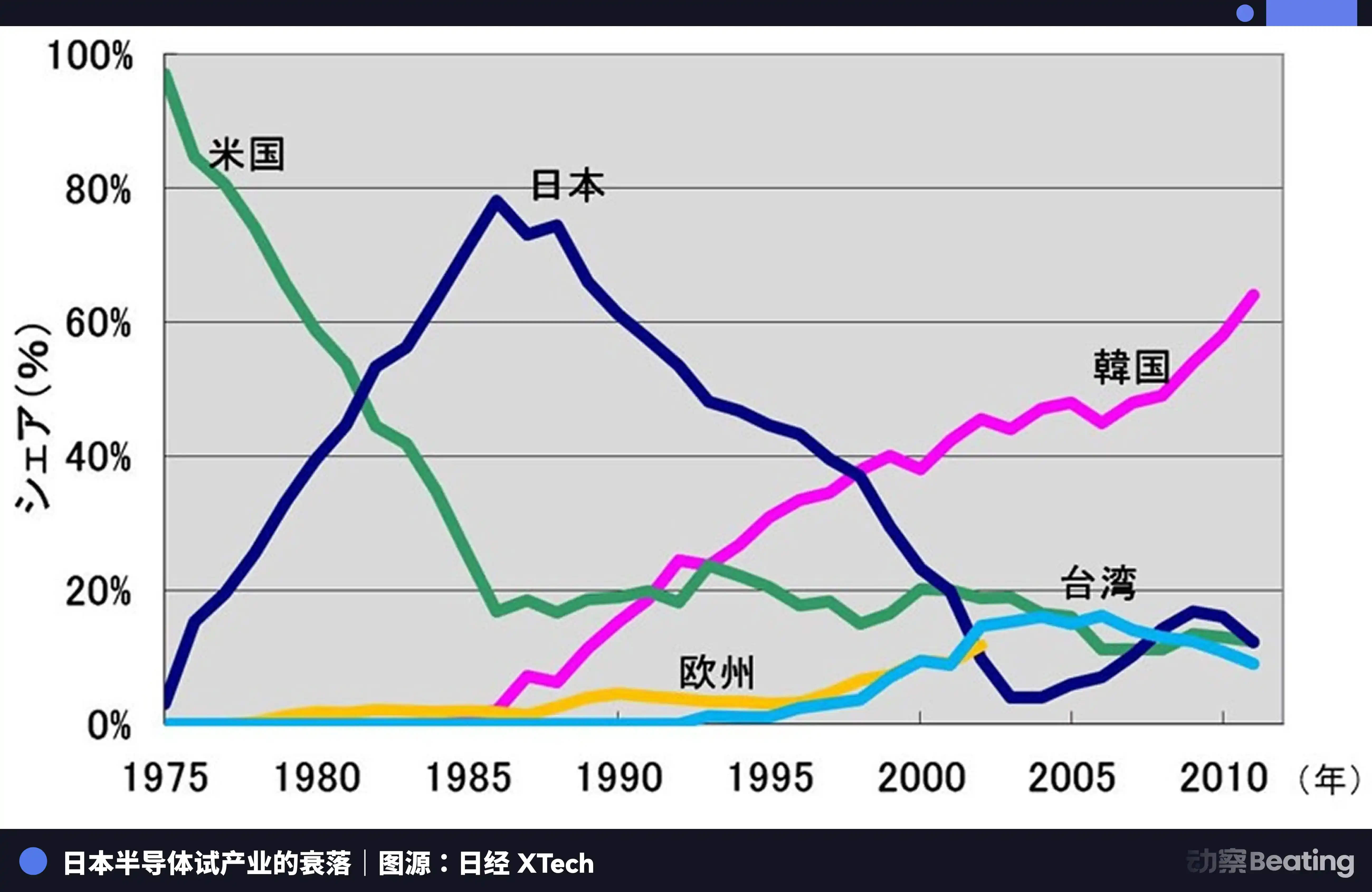
日本半导体的悲剧在于,它满足于在一个由单一外部力量主导的全球分工体系中,做那个最优秀的生产者,却从未想过去构建一个属于自己的、独立的生态。当潮水退去,它才发现,自己除了生产本身,一无所有。
今天的中国 AI 产业,正站在一个相似却又完全不同的路口。
相似的是,我们同样面临着来自外部的巨大压力。三轮芯片管制,层层加码,CUDA 生态的壁垒依然高耸。
不同的是,这一次,我们选择的是一条更难的路。从算法层面的极致优化,到国产芯片从推理到训练的跨越,再到昇腾生态 400 万开发者的积累,再到 Token 出海对全球市场的渗透。这条路上的每一步,都在构建一种日本当年从未拥有过的独立产业生态。
尾声
2026 年 2 月 27 日,三份来自本土 AI 芯片公司的业绩快报,在同一天发布。
寒武纪,营收暴增 453%,首次实现全年盈利。摩尔线程,营收增长 243%,但净亏损 10 亿。沐曦,营收增长 121%,净亏损近 8 亿。
一半是火焰,一半是海水。
火焰,是市场的极度饥渴。黄仁勋让出的那 95% 的空白,正在被这些本土公司的营收数字,一寸一寸地填满。无论性能如何,无论生态怎样,市场需要英伟达之外的第二个选择。这是地缘政治撕开的、一个千载难逢的结构性机会。
海水,是生态建设的巨大成本。每一分亏损,都是为追赶 CUDA 生态而付出的真金白银。是研发的投入,是软件的补贴,是派驻到客户现场、一个一个解决编译问题的工程师的人力成本。这些亏损,不是经营不善,而是构建一个独立生态所必须支付的战争税。
这三份财报,比任何一份行业报告都更诚实地记录了这场算力战争的真实面貌。它不是一场高歌猛进的胜利,而是一场惨烈的、一边流血一边冲锋的阵地战。
但战争的形态,确实已经变了。八年前,我们讨论的是「能不能活下来」的问题。今天,我们讨论的是「活下来要付出多大代价」的问题。
代价本身,就是进步。







