
谷歌研究院最近发了一篇论文,核心观点可以用一句话概括:与其死磕“让AI全知全能”,不如教它学会说“我不确定”。
这篇题为《Hallucinations Undermine Trust; Metacognition is a Way Forward》的论文由谷歌研究院与特拉维夫大学联合完成,已被ICML 2026 Position Track接收。论文提出,目前整个AI行业对抗“幻觉”的主流路线可能从根本上走偏了——大家忙着给模型灌更多知识,却忽略了一个更关键也更被低估的能力:让AI感知并表达自己对每个答案的确信程度。
(论文地址:[2605.01428] Hallucinations Undermine Trust; Metacognition is a Way Forward)
实用性税:消灭幻觉的真实代价
先从一个所有人都会遇到的场景说起。
你问AI助手一个问题,它用无比笃定的语气给出了一个答案,措辞严谨、逻辑完整,看起来毫无破绽。事后你一查,那个答案完全是胡编的。更让人恼火的是,它说的时候没有任何犹豫,仿佛亲眼所见。
这就是AI“幻觉”——模型输出了事实性错误的内容,却以一种不容置疑的方式呈现给用户。这个问题在医疗、法律、科研等高风险场景中尤为致命。
行业应对幻觉的思路,本质上就两条路。第一条路:让AI知道更多,通过扩大训练数据、增加模型参数来覆盖更多事实。第二条路:让AI不确定的时候闭嘴,遇到拿不准的问题直接拒答。
两条路都有明显的短板。世界上的事实无穷无尽,模型不可能记住所有事情,所以第一条路永远有覆盖不到的死角。而第二条路的问题在于,一旦AI开始大规模拒绝回答,它就从“有用的助手”变成了“什么都不敢说的废物”——用户问十个问题,八个被拒,体验极差。
论文给第二条路的代价起了个精准的名字:“实用性税”(utility tax)——为了降低幻觉率,你必须牺牲掉大量本可以正确回答的信息。
为什么这道税会这么重?根源在于AI缺少一项关键能力。要让“拒答”策略精确生效,模型需要精准区分“这道题我答对了”和“这道题我答错了”——只拒掉错的,保留对的。但现实是,模型做不到这种精确区分。论文区分了两个容易混淆但含义截然不同的概念来说明这个问题。
校准(calibration)衡量的是AI整体自信水平是否和整体正确率匹配。举例来说,AI回答100道题,每次都说“我有60%的把握”,而100道题里恰好60道对了,这就是完美校准。
判别力(discrimination)则衡量AI能否在每道具体题目上精准区分“我对了”和“我错了”。一个AI对所有问题都给60%的把握,整体正确率恰好60%,校准堪称完美,但判别力为零——它完全无法区分哪道该信、哪道该防。校准好不等于判别力强,这正是问题的要害。
论文梳理了大量文献后发现,目前主流大模型在真实知识问答任务上的判别力指标AUROC集中在0.70到0.85之间。这个数字听上去还行,实际远不够用。论文以AUROC=0.71为参数做了一组模拟计算,结果触目惊心:假设AI基础错误率25%,要把错误率压到5%,AI必须拒答超过52%的正确问题。即便判别力提升到0.85这个接近文献天花板的水准,仍需放弃28%的正确回答。只有判别力达到0.95以上时,代价才可忽略——而目前没有任何方法在知识密集型任务上接近这个数字。
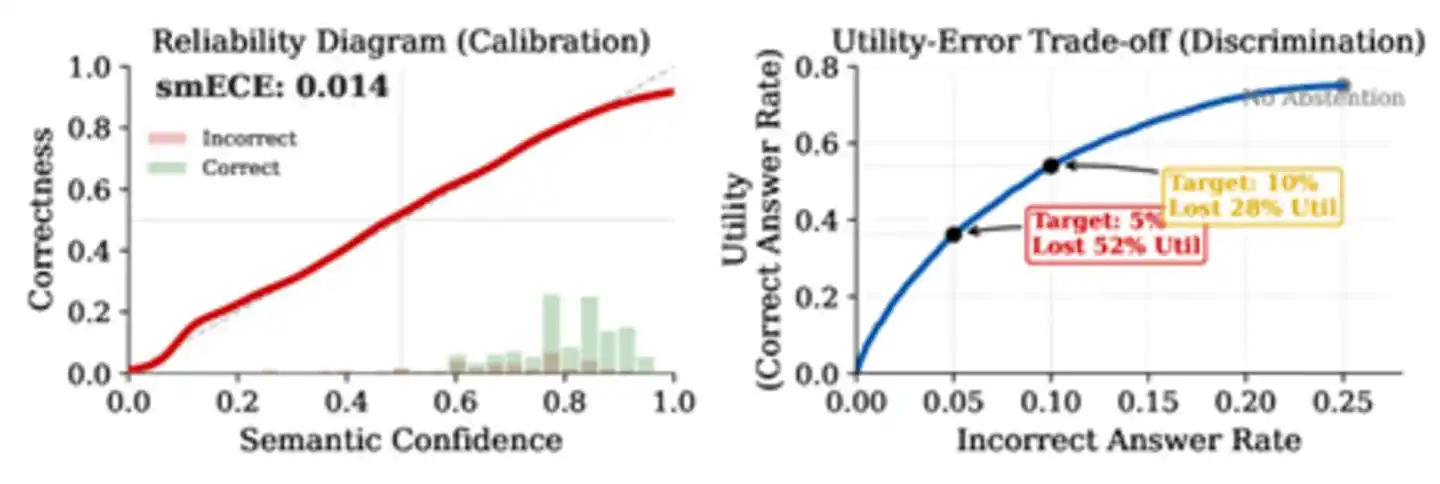
图:校准与判别力的区别。左图显示模型校准良好(红线贴近对角线),右图则揭示了残酷的现实——即便校准完美,要将错误率从25%压到5%,必须牺牲52%的正确回答。
真实数据印证了这一判断。论文分析了SimpleQA Verified基准测试上各前沿模型的表现,结果清晰得有些残酷:绝大多数模型沿着“答得多、错得多”的对角线分布,少数追求高准确率的模型通过大量拒答换取了更高单题准确率,却付出了巨大的实用性代价。那个理想的“右上角”区域——既多答又少错——目前空无一人。这片空白,正是论文所说的“判别力缺口”。
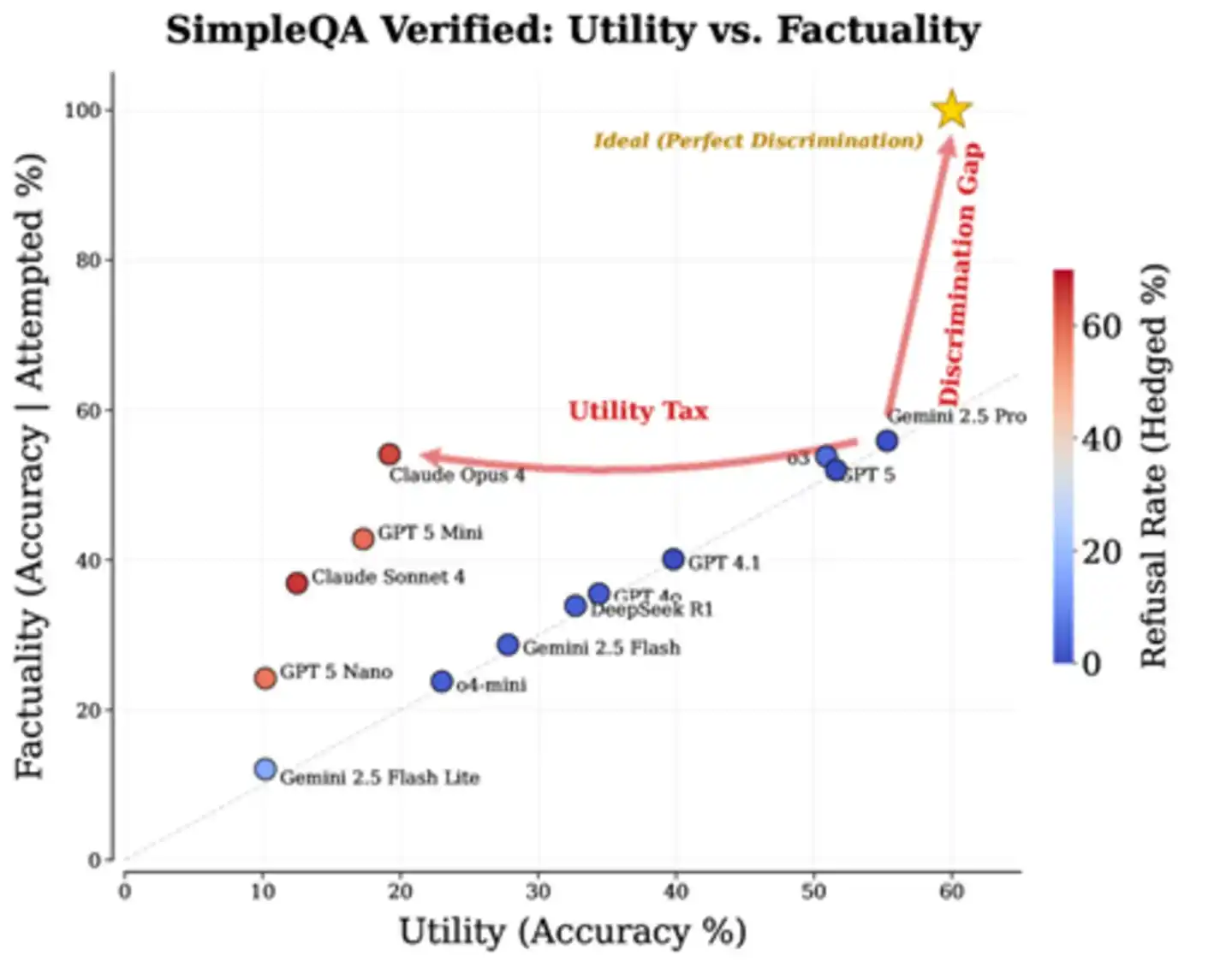
图:各主流模型在SimpleQA Verified上的实测表现。右上角五角星为理想目标,“Discrimination Gap”标注了现有模型与理想之间的鸿沟,“Utility Tax”则标示了Claude Opus 4为换取高准确率而付出的实用性代价。
既然“多灌知识”有死角,“不确定就闭嘴”代价又太高,有没有第三条路?
重新定义幻觉:不是“说错了”,而是“没资格确定却一口咬定”
论文的核心贡献不在于诊断问题,而在于重新定义了问题本身。
长期以来,行业把“幻觉”定义为“AI输出错误信息”,这隐含了一个前提:消灭幻觉=消灭所有错误。但论文提出,不妨换一个角度——幻觉不是“AI说错了”,而是“AI没有资格确定,却以确定的语气给出了错误信息”。
这个区分看似细微,实际影响深远。举个例子:医生看了检查报告后说“你得的是X病”,如果他其实只是凭直觉猜的,这是不负责任的。但如果他说“目前症状倾向于X,但需要进一步检查确认”,哪怕初步判断方向有偏差,这种表达方式本身就是诚实的——他在告诉病人“请谨慎对待这个判断”。错误并非不可接受,不可接受的是明明不确定却伪装成确定。
基于这个新定义,第三条路浮现出来:忠实不确定性(faithful uncertainty)——让AI在语言层面表达的确信程度,真实对应其内部状态的确信程度。
具体来说,AI的“内部不确定性”可以通过重复采样来客观衡量:同一个问题问一百遍,每次都给出相同答案,说明内心笃定;答案五花八门,说明内部其实摇摆不定。“语言不确定性”则是AI措辞中体现的确信感——“1961年8月4日”和“我好像记得是1961年,但不是完全确定”,给读者的信号完全不同。
忠实不确定性要求两者对齐:内心摇摆时措辞留有余地,内心笃定时才用确定的语气。论文强调,这个目标比“消灭所有错误”更可行。原因在于,忠实不确定性只需要AI的语言输出和自己的内部状态对应——这是一个闭环问题,信号就在模型内部,不依赖外部真相。而消灭错误则需要AI的输出和外部世界真相完全对应,论文引用的停机问题和计算理论表明,这在理论上存在根本性限制。
论文将这种能力总结为一个更上位的概念:元认知(metacognition)——AI既能感知自己的不确定性,又能基于这种感知调整行为。这个概念借自心理学,本意是“对自己认知过程的认知”,放在AI语境下,就是AI对自己知道什么、不知道什么有清醒的认识。
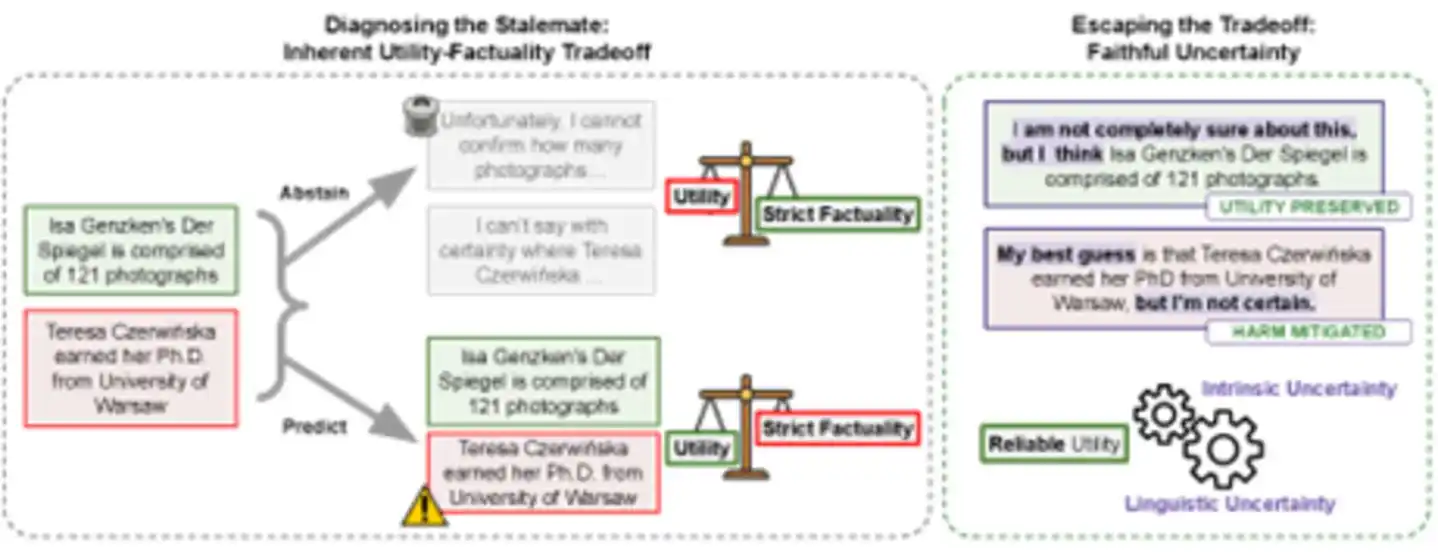
图:左侧为传统困境——“回答”有幻觉风险,“拒答”有实用性代价。右侧为新路径——通过忠实表达不确定性,既保留有用信息,又将错误信息的危害降到最低,实现“可靠实用性”。
AI代理时代:没有元认知的Agent就是“盲飞”
元认知的价值,不仅限于对话场景。在AI代理(Agent)时代,它变得更加关键。
表面上看,给AI装上搜索引擎就能解决知识不足的问题——不知道就查嘛,还怕什么幻觉?但论文指出,工具引入的不是“存储方案”,而是“控制问题”。
有了工具之后,AI面临一系列新决策:这个问题我自己知道吗,需要搜索吗?搜出来的信息可信吗?如果搜索结果和我自己掌握的信息矛盾了,听谁的?查到什么时候该停下来?
所有这些决策,都依赖于AI对自己内部确信程度的准确感知。没有元认知能力的AI代理,就像一个没有仪表盘的飞行员——引擎已经在报警,他还在加速。
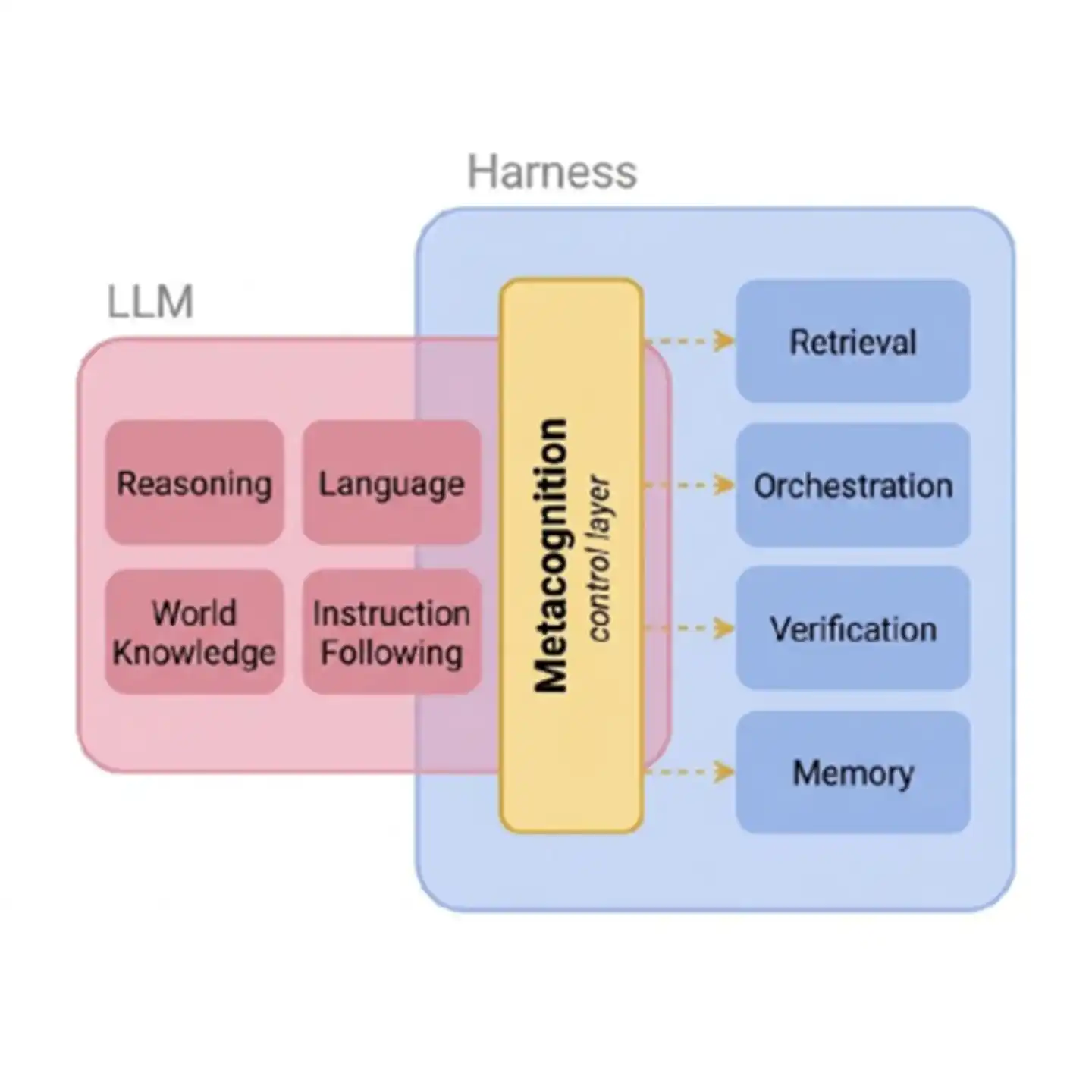
图:元认知控制层作为AI基础能力与外部工具系统之间的桥梁。没有这一层,Agent对外部工具的调度就如同“盲飞”——不知道该不该搜、搜了该不该信、信了信到什么程度。
论文引用的研究表明,当前搜索增强型AI代理普遍存在工具滥用问题——对根本不需要搜的问题也去搜,效率低下且引入不必要的噪音。原因很简单:没有元认知的AI根本无法判断“我需不需要额外信息”。
通往元认知的路上,还有几块硬骨头
论文也坦诚地指出了实现路径上的关键挑战。
“自举悖论”:教AI表达不确定性需要训练数据示范“该犹豫时犹豫”,但AI的知识边界是动态变化的。一条标注为“我不确定”的训练样本,可能在模型进化后变成了它确定知道的内容。用静态数据教动态能力,会训练出“假装不确定”的AI。这需要开发能反映模型当前知识边界的动态数据基础设施。
“对齐破坏信号”:研究发现,预训练后的AI其实已经具备不错的内部不确定性信号——它的内部状态能区分“这题比较有把握”和“这题不太确定”。但RLHF等对齐训练会把这个信号磨掉。原因在于,人类偏好语气确定的回答,这逼着AI学会了无论内心多摇摆,对外都表现出一副胸有成竹的样子。
“因果性评估”:更深层的难题在于,如何确保AI真的在读取内部信号,而不是学会了“遇到生僻词就说我不确定”这种表面套路?区分“真正的元认知”和“对元认知的表演”,是一个基础性的科学评估问题。
论文还提出对研究社区的具体建议:不要再只用单一准确率数字来评估反幻觉方法,应该可视化完整的“实用性-错误率权衡曲线”,看清楚一个方法是真的提升了底层判别能力,还是只是在同一条曲线上调高了拒答门槛。同时应检测“附带损伤”——为了降低知识问答的错误率,是否在推理、编程、写作等任务上付出了意外代价。
归根结底,这篇论文想传递的核心信息是:AI可以不全知全能,但它必须对自己知道什么、不知道什么有诚实的认识,并且把这种认识传达给用户。
我们信任专业人士,不是因为他们从不犯错,而是因为他们能诚实地区分“我确定”和“我猜测”——正是这种区分,让专业与不专业拉开了距离。AI也应该走向这条路。与其无止境追逐一个完美无误的幻象,不如让AI学会一件更务实的事:知道自己什么时候在胡说,并且坦诚地告诉用户。(本文首发钛媒体APP,作者 | 硅谷Tech_news,编辑 | 焦燕)






