「Deep Think」在所有竞赛中都击败/媲美竞争对手」!
刚刚,Google DeepMind高级研究员Conglong Li在X平台连发12条帖子,甩出了一张前所未见的成绩单。

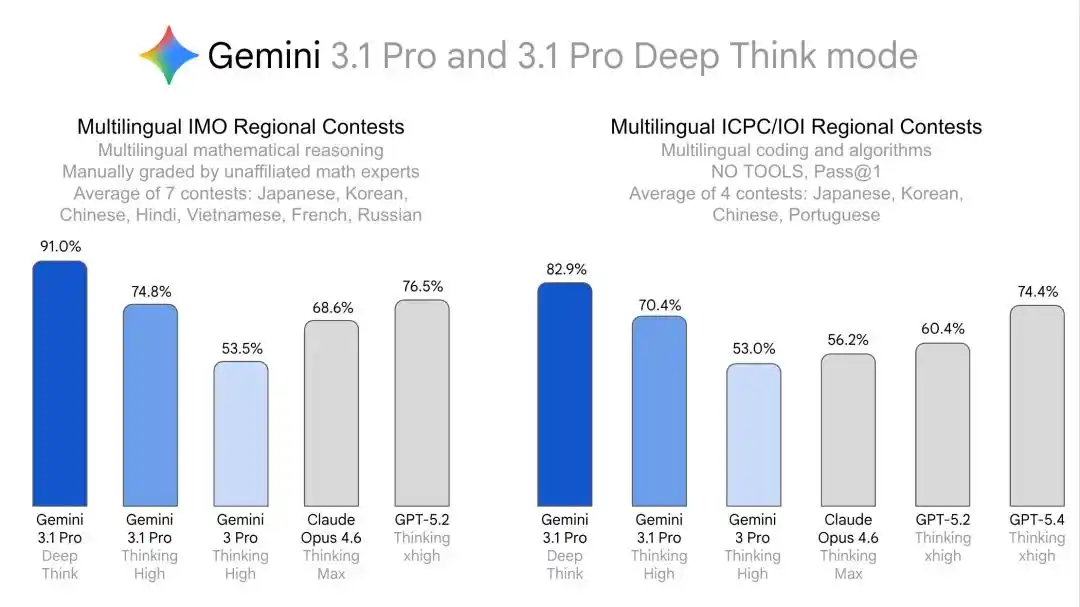
一个AI,同一个大脑,八张不同语言的试卷,全部高分交卷。
在任何一个模型身上,这样的成绩实属罕见。
从IMO金牌到区域赛全覆盖
这次Deep Think拿下多个榜单高分,并非突然的单点爆发,而是一条已经持续了近一年的能力演进曲线。
首先登顶最硬核的推理赛场。
2025年7月,Gemini Deep Think首次在国际数学奥林匹克(IMO)达到金牌标准,42分拿下35分。同期在ICPC世界决赛也取得类似高水平表现。
这两个成绩,DeepMind官方博客已经正式公布。
Google DeepMind随后把这两项成绩都写进了官方博客,作为Deep Think迈过数学与编程「世界级竞赛门槛」的标志。
接着,Deep Think开始从「世界冠军级单项突破」,走向「跨语言、跨学科、跨场景的系统验证」。
2026年2月,Google连发三篇博客。
一篇介绍Gemini 3.1 Pro模型本体,一篇介绍Deep Think专用推理模式的重大升级,一篇来自DeepMind科学发现团队,直接把Deep Think定位成「人类智力倍增器」。
升级后的Deep Think交出了一串硬指标:
Humanity's Last Exam拿下48.4%(无工具辅助),ARC-AGI-2达到84.6%(ARC Prize基金会官方验证),Codeforces竞赛编程Elo评分3455,2025国际物理奥赛和化学奥赛笔试部分达到金牌水平。
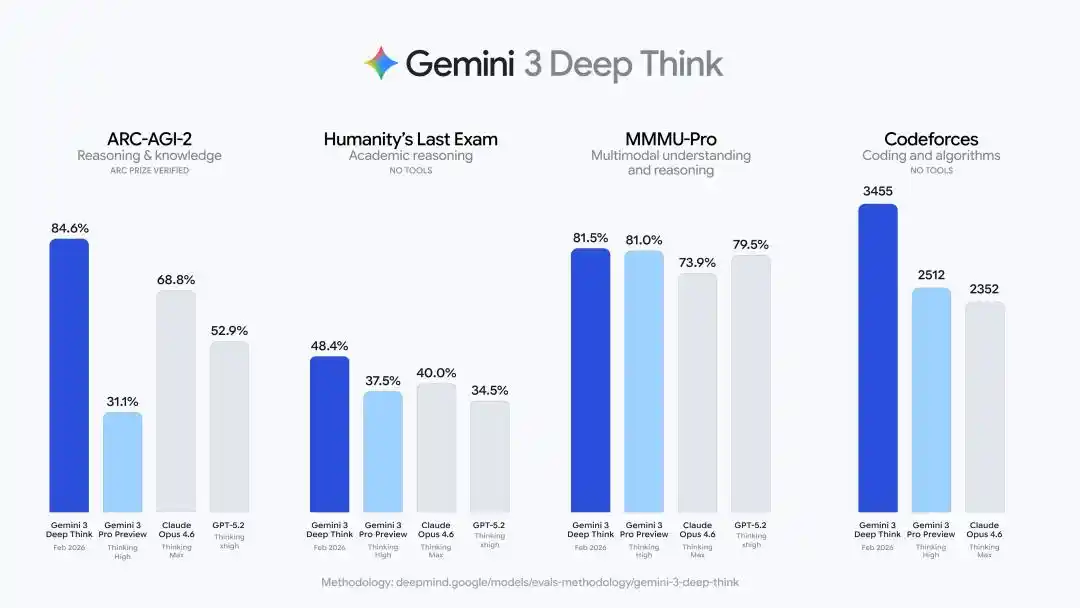
这条路线非常清楚:先用IMO、ICPC这样的世界级竞赛,证明它的强大推理能力,然后再用多语种、区域赛和跨学科奥赛成绩,证明它的跨语言、跨领域稳定迁移的通用深度推理能力。
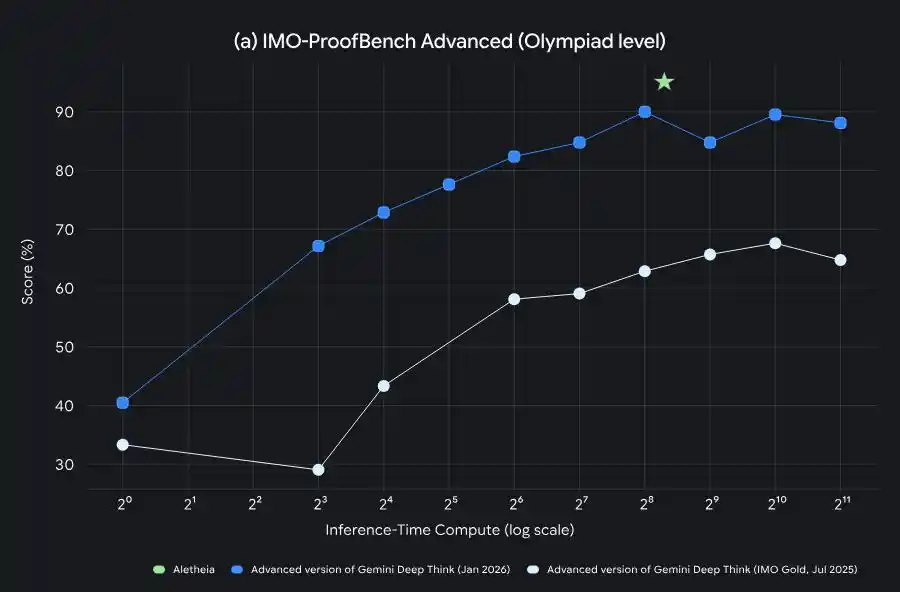
Gemini Deep Think从IMO金牌到PhD级科研加速的能力演进
8语言成绩单逐项细看
现在,把这张成绩单真正摊开来看。
日语最亮眼。
2025年第35回日本数学奥赛本选(JMO Finals),满分。
ICPC亚洲日本初赛,满分。
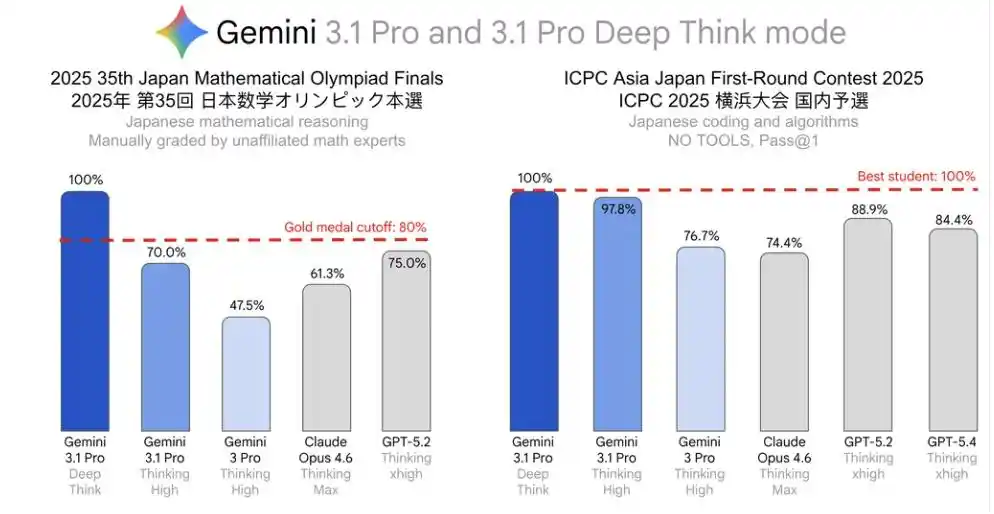
其中,JMO本选这项成绩甚至超过了当届最高得分对应的80%水平,达到官方所说的「金奖相当」标准。
法语同样满分,100%。
中文就有意思了。
第41届中国数学奥林匹克(CMO),Deep Think拿到86.3%,相当出色。但中国信息学奥赛(NOI)只有63.3%。
86.3%和63.3%之间的落差,画出了AI推理能力的真实边界。
在数学竞赛里,模型面对的是抽象推导、证明构造和多步演绎,这恰好是Deep Think最擅长的能力带。
但到了信息学竞赛,问题就不只是「想明白」,还包括把逻辑翻译成可执行代码、控制边界条件、兼顾复杂度约束,并且在实现层面避免失误。
前者更接近纯推理,后者则要求「推理+算法设计+工程化实现」同时过关。
其它语种,韩语、印地语、越南语、俄语、葡萄牙语对应的竞赛结果里,Deep Think 也都实现了击败对手或至少持平。
如果把日语、法语、中文再合起来看,这次最不寻常的一点其实不是某一门单科刷到满分,而是同一个模型、同一种Deep Think推理系统,在多种语言的竞赛试卷上,都交出了第一梯队的成绩。
这份成绩单可靠吗?
但这里有一个关键的缺失:
Conglong Li并没有列出竞品的具体对比数据:所有成绩,全部来自Google内部评测。没有第三方独立复现,没有竞赛官方认证,评测方法完全没有公开。
每道题是做一次还是做很多次取最优?推理时用了多少算力?有没有人工提示工程介入?
这些直接影响成绩含金量的细节,也都没提。
还有一点容易被忽略:这些考试全部是各国区域选拔赛,不是国际决赛。
区域赛的题目难度和国际决赛之间,隔着一个量级。
研究员明确说了,这些成绩「将被纳入模型卡」,截至发稿,模型卡尚未正式更新。
所以,目前这仍然好像是一张由考生自己打分、自己公布、尚未交给教务处盖章的成绩单。
多语言科研公平性,被忽视的真正战场
为什么Google要专门花精力做8种语言的区域赛评测?
当前AI推理能力的评测,几乎全部基于英语。
MATH、GSM8K、HumanEval、ARC-AGI......这些都是英语。
全世界的数学家、物理学家、工程师,只要母语不是英语,在使用AI科研工具时都要先过一道语言关。
Google选的这8种语言不是随机的。
日语、韩语、中文覆盖东亚科研重镇,印地语、越南语覆盖新兴市场,法语、俄语、葡萄牙语覆盖欧洲和南美。
加在一起,这是全球科研产出的大半壁江山。
DeepMind在官方博客里把Deep Think定位为「人类智力倍增器」,说它能「处理知识检索和严格验证,让科学家专注于概念深度和创造性方向」。
结合这次的多语言成绩,这句话的潜台词不难理解:这个倍增器,不仅限英语的科学家用。
更值得注意的是Deep Think在科研落地上已经走了多远。
DeepMind公布了一个叫Aletheia的数学研究智能体,基于Deep Think驱动,能自主生成、验证、修订研究级数学问题的解法。
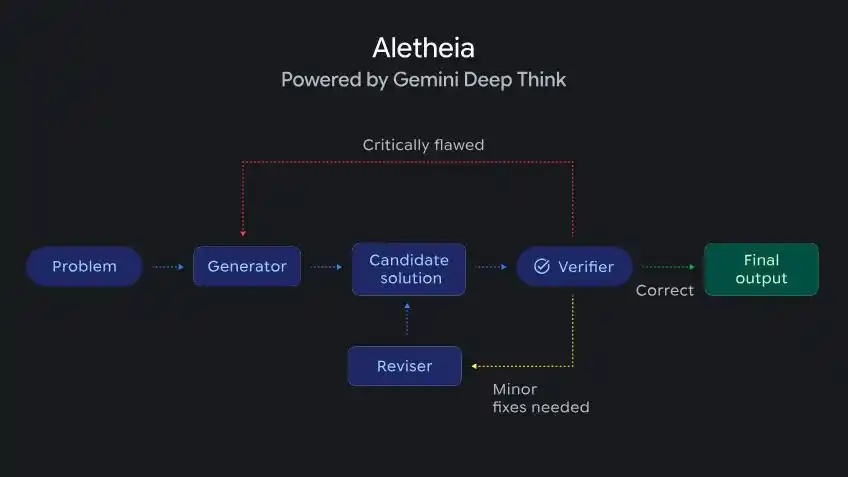
Aletheia由Deep Think驱动,能够对研究级数学问题进行迭代式生成、验证与修正
Aletheia已经参与产出了多篇研究论文,其中一篇完全由AI自主完成,计算了算术几何中的特定结构常数。

另外,在700个开放数学问题的半自主评估中,它还独立解决了4个此前未解的问题。
Gemini Deep Think模式在计算机科学、物理学、经济学等领域也展现出巨大潜力。
在计算机科学领域,Deep Think帮助推翻了一个悬而未决十年的猜想,在物理学领域找到了宇宙弦引力辐射的新型解析解,在经济学领域扩展了一个拍卖理论定理。
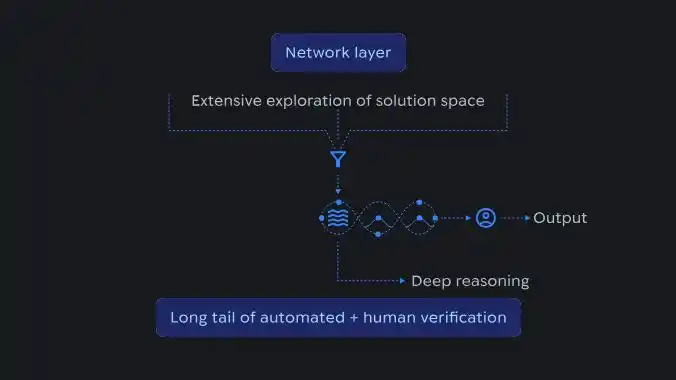
AI推理流程的示意图,展示了在网络层进行的大规模解空间探索如何被汇聚为结构化推理,并通过自动化与人工验证加以确认。
通过与专家合作解决18个研究难题,Gemini Deep Think的高级版本帮助突破了算法、机器学习与组合优化、信息论以及经济学领域长期存在的瓶颈。
这已经远远超出了「做竞赛题」的范畴。
当竞品还在卷英文benchmark排行榜的时候,Google已经在「AI科研加速器」领域找到了新战场。
这件事请最重要的东西其实不是分数,它背后真正的信号是:AI科研工具的语言壁垒正在被当作一个工程问题来解决。
如果这条路走通了,全世界用日语、韩语、中文、印地语做研究的科学家,将第一次和英语母语者站在同一条起跑线上。
这一次,Google已经把牌摊在了桌上。
至于竞争对手谁会跟牌,相信我们很快也将看到。
参考资料:
https://blog.google/intl/ja-jp/company-news/technology/gemini-31-pro-gemini-31-pro-deep-think/%20
https://deepmind.google/blog/accelerating-mathematical-and-scientific-discovery-with-gemini-deep-think/%20
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/%20
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-deep-think/
本文来自微信公众号“新智元”,作者:新智元





