Muốn biết mô hình lớn nào mạnh nhất trong các nhiệm vụ đại lý thế giới thực của OpenClaw?
MyToken dựa trên trang web đánh giá đã tổng hợp một tiêu chuẩn minh bạch tập trung vào việc đánh giá khả năng thực tế của đại lý mã hóa AI, chỉ xem xét một chiều cốt lõi này là tỷ lệ thành công (tốc độ và chi phí thuộc các chiều độc lập khác, sẽ được phân tích riêng sau). Hoàn toàn công khai, có thể tái tạo, chỉ trình bày tiêu chuẩn đánh giá nghiêm ngặt + bảng xếp hạng Top 10 tỷ lệ thành công mới nhất.
I. Chiều đánh giá:Tỷ lệ thành công
Tiêu chuẩn cụ thể: Tỷ lệ số lượng nhiệm vụ mà đại lý AI hoàn thành một cách đầy đủ và chính xác. Mỗi nhiệm vụ đều áp dụng quy trình được tiêu chuẩn hóa cao:
-
Từ nhắc nhập (Prompt) người dùng chính xác
Gửi cho tác nhân thông minh đầy đủ để mô phỏng các tình huống yêu cầu người dùng thực tế
-
Hành vi dự kiến (Expected Behavior)
Đều giải thích cách thức triển khai có thể chấp nhận và các điểm quyết định quan trọng
-
Tiêu chí chấm điểm (checklist)
Liệt kê danh sách kiểm tra xác định thành công nguyên tử có thể xác minh từng điều
II. Ba cách chấm điểm
Lần đánh giá này chủ yếu áp dụng 3 cách chấm điểm
-
Kiểm tra tự động hóa: Kịch bản Python trực tiếp xác minh nội dung tệp, bản ghi thực thi, lệnh gọi công cụ và các kết quả khách quan khác
-
Trọng tài mô hình lớn LLM: Claude Opus chấm điểm theo thang đo chi tiết (chất lượng nội dung, mức độ phù hợp, tính hoàn chỉnh, v.v.)
-
Chế độ hỗn hợp: Kiểm tra khách quan tự động + đánh giá định tính trọng tài LLM kết hợp
Tất cả định nghĩa nhiệm vụ, Prompt, logic chấm điểm đều được công khai để thuận tiện cho việc kiểm tra lại.
III. Các nhiệm vụ được sử dụng để đánh giá
Bài kiểm tra chuẩn này bao gồm 23 nhiệm vụ thuộc các danh mục khác nhau. Bao phủ nhiều chiều như tương tác cơ bản, thao tác tệp/mã, sáng tạo nội dung, nghiên cứu phân tích, gọi công cụ hệ thống, tính bền vững bộ nhớ, v.v., rất gần với các tình huống sử dụng OpenClaw hàng ngày của nhà phát triển:
-
Sanity Check(Tự động hóa——Xử lý lệnh đơn giản và trả lời chào hỏi chính xác
-
Calendar Event Creation(Tự động hóa)——Ngôn ngữ tự nhiên tạo tệp lịch ICS tiêu chuẩn
-
Stock Price Research(Tự động hóa)——Truy vấn giá cổ phiếu thời gian thực và xuất báo cáo được định dạng
-
Blog Post Writing(Trọng tài LLM)——Viết một blog Markdown có cấu trúc khoảng 500 từ
-
Weather Script Creation(Tự động hóa)——Viết kịch bản Python API thời tiết với xử lý lỗi
-
Document Summarization(Trọng tài LLM)——Tóm tắt tinh gọn chủ đề cốt lõi theo 3 đoạn
-
Tech Conference Research(Trọng tài LLM)——Nghiên cứu tổng hợp thông tin 5 hội nghị công nghệ thực (tên, ngày, địa điểm, liên kết)
-
Professional Email Drafting(Trọng tài LLM)——Lịch sự từ chối cuộc họp và đề xuất phương án thay thế
-
Memory Retrieval from Context(Tự động hóa)——Trích xuất chính xác ngày, thành viên, công nghệ, v.v. từ ghi chú dự án
-
File Structure Creation(Tự động hóa)——Tự động tạo thư mục dự án tiêu chuẩn, README, .gitignore
-
Multi-step API Workflow(Hỗn hợp)——Đọc cấu hình → Viết kịch bản gọi → Tài liệu hóa đầy đủ
-
Install ClawdHub Skill(Tự động hóa)——Cài đặt từ kho kỹ năng và xác minh tính khả dụng
-
Search and Install Skill(Tự động hóa)——Tìm kiếm kỹ năng loại thời tiết và cài đặt chính xác
-
AI Image Generation(Hỗn hợp)——Tạo và lưu ảnh theo mô tả
-
Humanize AI-Generated Blog(Trọng tài LLM)——Sửa nội dung có mùi máy móc thành ngôn ngữ nói tự nhiên
-
Daily Research Summary(Trọng tài LLM)——Tổng hợp nhiều tài liệu thành bản tóm tắt hàng ngày mạch lạc
-
Email Inbox Triage(Hỗn hợp)——Phân tích nhiều email và sắp xếp báo cáo theo mức độ khẩn cấp
-
Email Search and Summarization(Hỗn hợp)——Tìm kiếm email lưu trữ và chắt lọc thông tin chính
- <极客公园p data-offset-key="85qej-0-0">Competitive Market Research(Hỗn hợp)——Phân tích đối thủ cạnh tranh trong lĩnh vực APM doanh nghiệp
-
CSV and Excel Summarization(Hỗn hợp)——Phân tích tệp bảng và xuất thông tin chi tiết
-
ELI5 PDF Summarization(Trọng tài LLM)——Giải thích PDF kỹ thuật bằng ngôn ngữ trẻ 5 tuổi có thể hiểu
-
OpenClaw Report Comprehension(Tự động hóa)——Từ báo cáo nghiên cứu PDF trả lời chính xác câu hỏi cụ thể
-
Second Brain Knowledge Persistence(Hỗn hợp)——Lưu trữ thông tin xuyên phiên và nhớ lại chính xác
IV. Kết luận cốt lõi: Bảng xếp hạng 10 mô hình lớn hàng đầu về tỷ lệ thành công (Best %/Avg %)
-
Dữ liệu cập nhật đến ngày 7 tháng 4 năm 2026
-
Best % là tỷ lệ thành công cao nhất một lần, Avg % là tỷ lệ thành công trung bình nhiều lần, phản ánh better tính ổn định
Dưới đây là mười mô hình có tỷ lệ thành công cao nhất
-
anthropic/claude-opus-4.6(Anthropic)——93.3% / 82.0%
-
arcee-ai/trinity-large-thinking(Arcee AI)——91.9% / 91.9%
-
openai/gpt-5.4(OpenAI)——90.5% / 81.7%
-
qwen/qwen3.5-27b(Qwen)——90.0% / 78.5%
-
minimax/minimax-m2.7(MiniMax)——89.8% / 83.2%
-
anthropic/claude-haiku-4.5(Anthropic)——89.5% / 78.1%
-
qwen/qwen3.5-397b-a17b(Qwen)——89.1% / 80.4%
-
xiaomi/mimo-v2-flash(Xiaomi)——88.8% / 70.2%
-
qwen/qwen3.6-plus-preview(Qwen)——88.6% / 84.0%
-
nvidia/nemotron-3-super-120b-a12b(NVIDIA)——88.6% / 75.5极客公园%
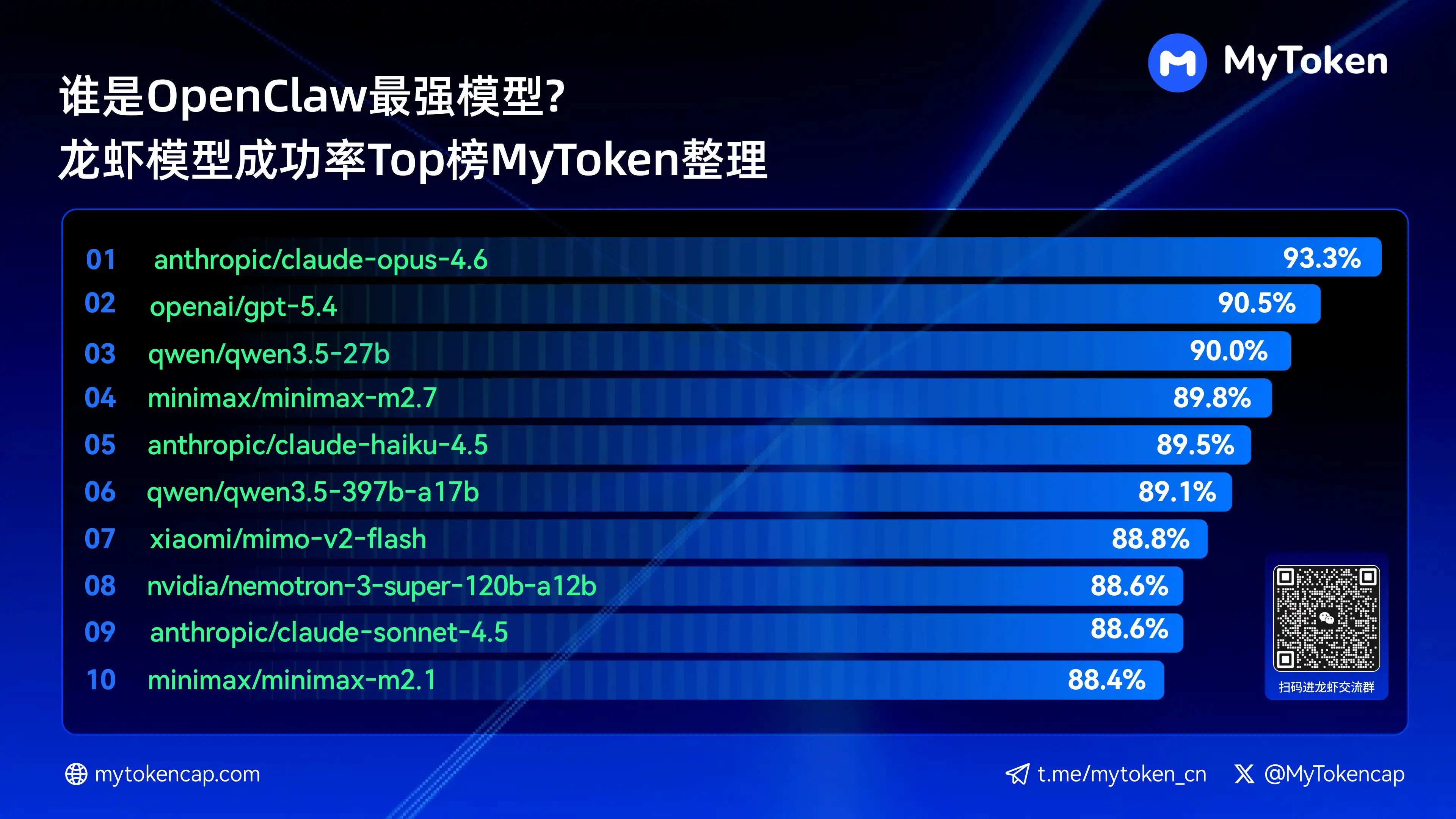
Claude Opus 4.6 hiện dẫn đầu với tỷ lệ thành công cao nhất là 93.3%, nhưng Trinity của Arcee thể hiện ấn tượng về độ ổn định trung bình, series Qwen cũng có nhiều mẫu lọt vào top 10, cho thấy tiềm năng về giá trị rất lớn. Tỷ lệ thành công là ngưỡng cơ bản, các chiều tốc độ và chi phí sau này sẽ ảnh hưởng further đến trải nghiệm thực tế.
Bộ tiêu chuẩn 23 nhiệm vụ này hoàn toàn minh bạch,强烈建议大家结合自身场景实际测试。Rất khuyến khích mọi người kết hợp kiểm tra thực tế theo tình huống của bản thân. Chức năng bảng xếp hạng tác nhân thông minh sắp ra mắt của MyToken sẽ có thêm thứ hạng của các mô hình khác.
(Dữ liệu来源于PinchBench公开的OpenClaw代理基准测试,持续更新中。Nguồn dữ liệu từ bài kiểm tra chuẩn đại lý OpenClaw công khai của PinchBench, đang được cập nhật liên tục.)





