Biên tập viên Machine Heart
Mô hình mới Gemma 4 mà Google mới mã nguồn mở vài ngày trước đã mang đến một bất ngờ lớn cho ngành.
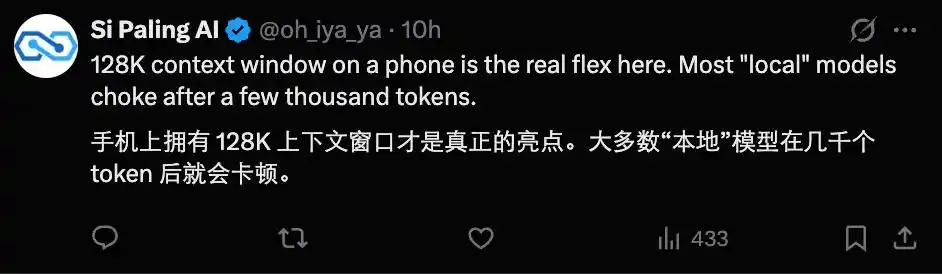
Nó sử dụng kiến trúc công nghệ cùng nguồn gốc với Gemini 3, hỗ trợ đa phương thức (multimodal) gốc, đứng thứ ba toàn cầu trên bảng xếp hạng Arena AI, và có nhiều model để lựa chọn. Một vài model nhỏ hơn — E2B (2.3B tham số hiệu dụng) và E4B (4.5B tham số hiệu dụng) — có thể triển khai trực tiếp để chạy cục bộ trên thiết bị di động, với cửa sổ ngữ cảnh (context window) lên đến 128K, có thể coi là "Gemini thay thế bỏ túi được".
Không ngoài dự đoán, mô hình nhanh chóng trở thành món đồ chơi mới của người dùng điện thoại.
Một bài đăng từ người dùng X đã thu hút hàng trăm nghìn lượt xem. Trong bài đăng có một video kể về việc họ chạy Gemma 4 cục bộ trên iPhone như thế nào, bao gồm xử lý hình ảnh, âm thanh, điều khiển bật tắt đèn pin. Họ cho biết, Gemma 4 nhanh một cách đáng kinh ngạc, cảm giác như phép thuật.

Ai đó đã định lượng tốc độ này trên iPhone 17 Pro, chỉ ra rằng nếu điện thoại sử dụng chip Apple, thì với sự trợ giúp của MLX (framework học máy của Apple) được tối ưu hóa cho bộ chip này, tốc độ suy luận (inference) của mô hình có thể vượt quá 40 token / giây.

Cũng có người chạy được tốc độ tương tự trên Samsung Galaxy, và thậm chí là trong khi bật chế độ suy nghĩ (thinking mode). Điều này khiến người ta phải thốt lên "nhanh đến mức không tưởng".
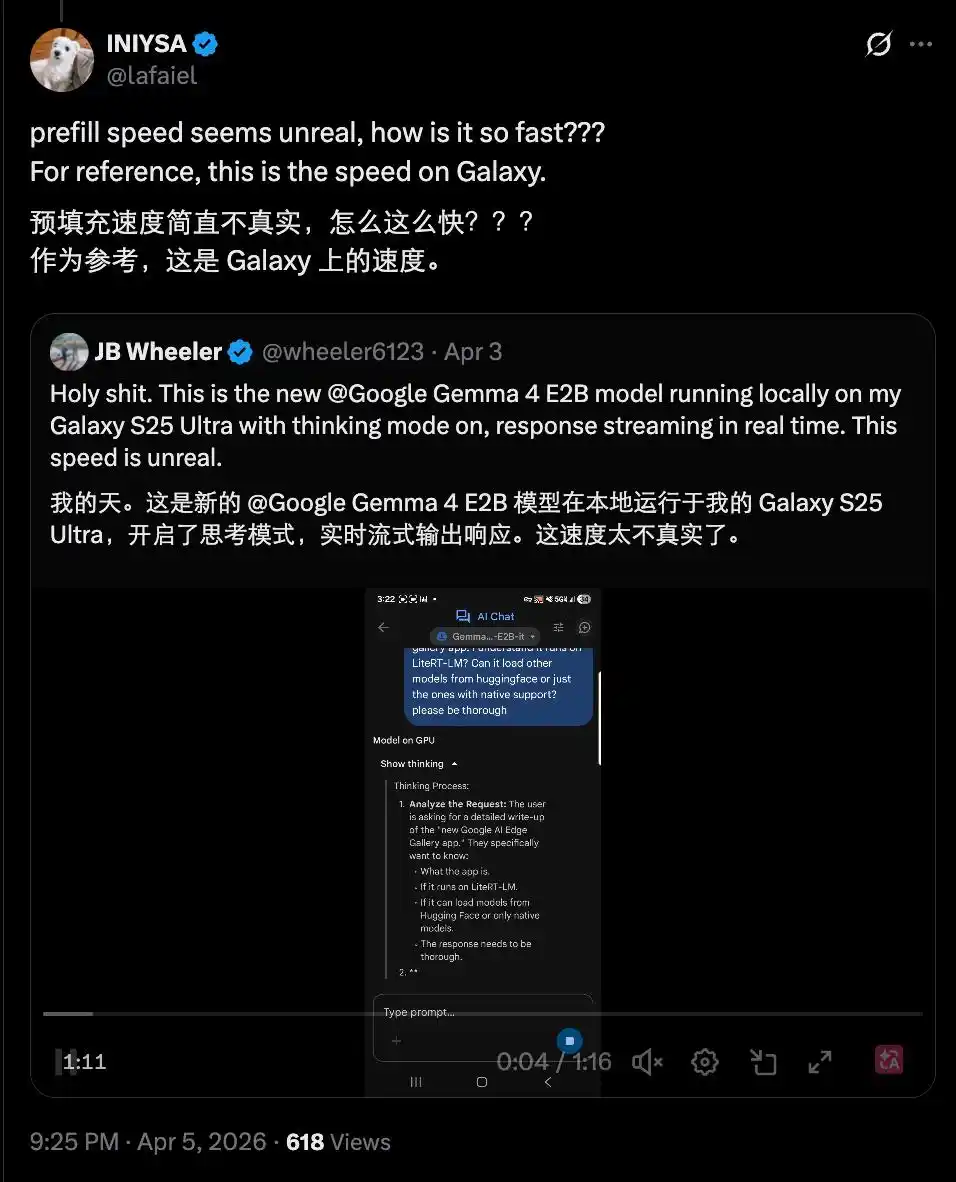
Tốc độ như vậy khiến việc chạy mô hình AI trên thiết bị di động trở thành một lựa chọn có thể chấp nhận được trong tương lai, và rất hữu ích trong các kịch bản nhạy cảm như chăm sóc sức khỏe.
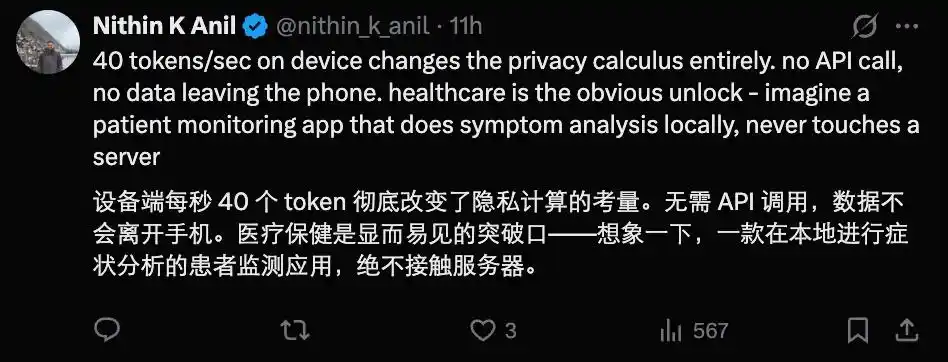
Cửa sổ ngữ cảnh 128k cũng khiến những mô hình nhỏ này trở nên hấp dẫn hơn.
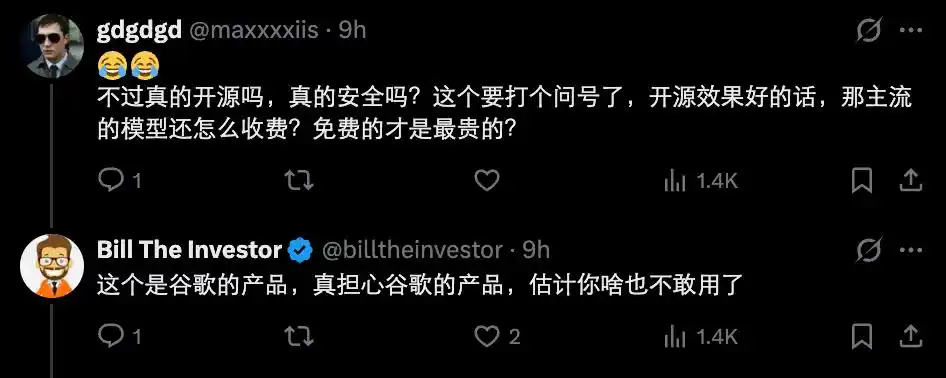
Vậy cụ thể chạy như thế nào? Thực ra rất đơn giản, không phải dành riêng cho dân geek, vì Google đã phát hành ứng dụng chính thức — Google AI Edge Gallery. Người muốn trải nghiệm trên điện thoại có thể trực tiếp tải ứng dụng này, sau đó tải phiên bản mô hình muốn chạy, mở lên là có thể dùng được.

Hơn nữa, vì là do Google chính thức phát hành, vấn đề an toàn đương nhiên cũng không cần quá lo lắng.
Ngoài những mô hình nhỏ chạy trên thiết bị di động này, còn có người thử nghiệm các phiên bản Gemma 4 lớn hơn trên phần cứng mạnh hơn, ví dụ như chạy Gemma 4 Mixture-of-Experts 26B trên MacBook Pro phiên bản M5 Pro.

Nếu chỉ đối thoại trực tiếp, tốc độ của model này vẫn rất nhanh, tạo văn bản, giải thích mã đều trơn tru.

Nhưng khi họ thực sự dùng Gemma 4 như một coding agent (tác nhân lập trình) thì vấn đề nảy sinh. Bởi vì chạy agent cần ngữ cảnh lớn (Gemma 4 26B có cửa sổ ngữ cảnh 256k), prompt phức tạp và gọi công cụ (tool calling) ổn định, Gemma 4 ở những điểm này tỏ ra không chịu nổi, thường xuyên bị đơ, báo lỗi, hoặc đầu ra có cấu trúc không đúng.

Bước ngoặt xảy ra khi họ chuyển sang dùng model qwen3-coder, trong cùng môi trường đó, tạo file, thực thi lệnh, tác vụ nhiều bước đều chạy bình thường. Họ cho rằng, vấn đề không nằm ở framework agent, mà ở bản thân model có được tối ưu hóa cho "tool calling + structured output" (gọi công cụ + đầu ra có cấu trúc) hay không. Về mặt này, Gemma 4 có lẽ làm chưa đủ, cũng có thể nhà phát triển này chưa tìm đúng cách dùng.

Ngoài ra, còn có người nói, trí tuệ của Gemma 4 vẫn còn hơi "dở dang".
Dù vậy, sự xuất hiện của Gemma 4 - thứ "viên đạn nhỏ hiệu năng cao" này - vẫn không thể xem thường. Nếu sau này phần lớn các tác vụ tra cứu hàng ngày, trò chuyện, suy luận đơn giản, tạo mã, hiểu hình ảnh đều có thể chạy cục bộ, không cần mua token nữa, thì những hãng bán token chẳng phải sẽ rất lúng túng sao?
Tất nhiên, tình hình hiện tại chưa bi quan đến vậy, xét cho cùng vẫn còn khoảng cách giữa các model mã nguồn mở hiện nay và các model độc quyền tiên phong ở front-line, và hầu hết các model mã nguồn mở mạnh vẫn bị giới hạn bởi khả năng phần cứng, tạm thời chưa thể đạt đến mức độ khả dụng trên thiết bị đầu cuối (edge side).
Nhưng xu hướng tương lai là rõ ràng. Trong ngắn hạn, các model độc quyền trên đám mây vẫn dẫn đầu trong lĩnh vực suy luận phức tạp nhất và sự hợp tác đa tác nhân quy mô siêu lớn; nhưng về lâu dài, khi phần cứng tiếp tục tiến bộ, công nghệ lượng tử hóa (quantization) tiếp tục được tối ưu hóa, các model trên thiết bị đầu cuối sẽ dần chiếm lĩnh các tác vụ đơn giản tần suất cao của đám mây.
Những hãng chỉ dựa vào bán token, bán đăng ký API, sẽ buộc phải cạnh tranh khốc liệt hơn ở phần "thực sự khó nhằn" — Agent siêu mạnh, ngữ cảnh dài đáng tin cậy, và các khả năng chuyên biệt cần dữ liệu thời gian thực khổng lồ.
Gemma 4 chỉ là khởi đầu. Bất ngờ tiếp theo, rất có thể là một model trên thiết bị đầu cuối nào đó trong quá trình sử dụng hàng ngày khiến người dùng hoàn toàn không cảm nhận được sự khác biệt giữa "cục bộ" và "đám mây". Khi ngày đó đến, toàn bộ mô hình kinh doanh của ngành công nghiệp AI, sẽ đón một cuộc đại tái cấu trúc thực sự.
Bài viết từ tài khoản WeChat công cộng "Machine Heart" (ID: almosthuman2014), tác giả: Machine Heart