Một dòng import, fine-tune mô hình lớn MoE tăng tốc 3.7 lần.
Nghiên cứu mới nhất của NVIDIA hiện đã mã nguồn mở: NeMo AutoModel, được thiết kế chuyên biệt để xây dựng và tinh chỉnh quy mô lớn các mô hình AI tạo sinh.
Trên nền tảng Hugging Face Transformers v5, NeMo AutoModel có thể đạt được fine-tune mô hình MoE nhanh hơn mà không cần thay đổi mã API, chỉ cần thêm một dòng import.

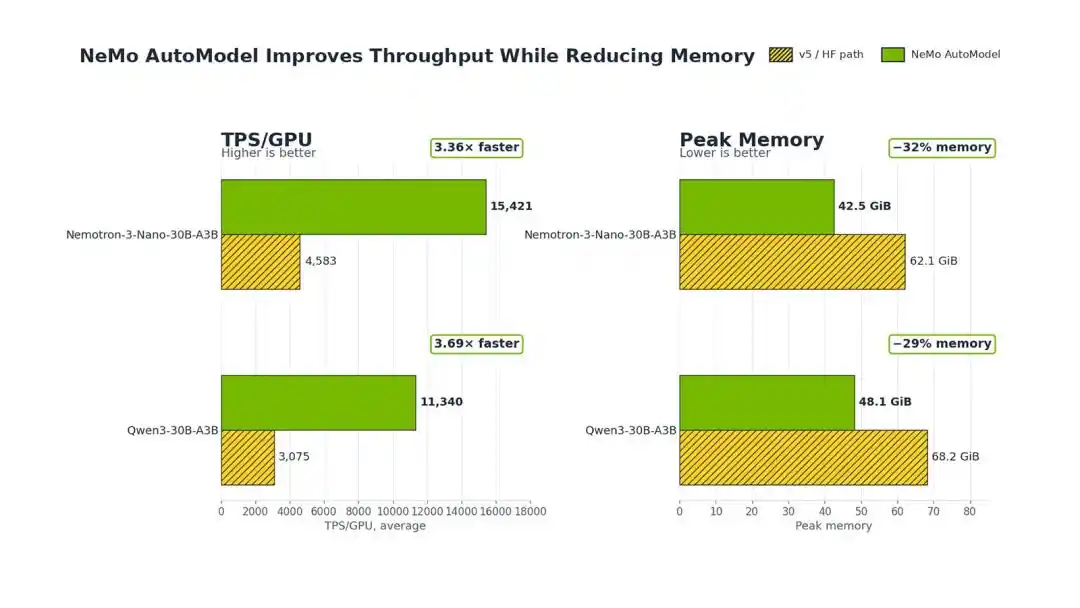
Thử nghiệm cho thấy, so với phiên bản Transformers v5 gốc của Hugging Face, NVIDIA NeMo AutoModel có thể đạt được từ 3.4 đến 3.7 lần cải thiện thông lượng huấn luyện trong fine-tune MoE, đồng thời giảm 29%-32% mức sử dụng bộ nhớ GPU.
Trên một node đơn với 8xH100 80GB GPU, lấy Qwen3-30B-A3B làm ví dụ, NeMo AutoModel trực tiếp kéo TPS/GPU (thông lượng mỗi giây trên mỗi GPU) từ 3075 lên 11340, mức tăng đạt 3.69 lần.
Phân Tích Công Nghệ Cốt Lõi
MoE đã trở thành kiến trúc chủ đạo của các mô hình tiên phong hiện nay, nhưng MoE cũng mang đến những thách thức mới cho việc huấn luyện hiệu quả:
Song song chuyên gia, hợp nhất truyền thông, tối ưu kernel... Những công trình phức tạp này đều cần cơ sở hạ tầng hỗ trợ đi kèm.
Transformers v5 của HuggingFace hiện là "nền tảng chung" được sử dụng khá nhiều để huấn luyện MoE. V5 tăng cường hỗ trợ native cho MoE, giới thiệu các khả năng cơ bản của MoE như expert backends, dynamic weight loading, thực thi phân tán.

Lần này, ý tưởng của NVIDIA là đứng trên vai những người đi trước, tương thích với API của HuggingFace Transformers, để mọi người có thể không cần sửa đổi nhiều mã, mà vẫn đạt được thông lượng huấn luyện cao hơn và mức sử dụng bộ nhớ thấp hơn trong fine-tune MoE.
Cụ thể, NeMo AutoModel trên nền tảng Transformers v5 đã bổ sung Expert Parallelism (EP), DeepEP và TransformerEngine.
Expert Parallelism (Song Song Chuyên Gia)
Công nghệ song song chuyên gia chủ yếu dùng để giảm áp lực bộ nhớ.
EP phân phối trọng số chuyên gia (expert weights) trên nhiều GPU, mỗi GPU không còn giữ toàn bộ tham số expert, mà chỉ giữ một phần trong số đó.
Ví dụ, trên 8 GPU với ep_size=8, trọng số chuyên gia được phân phối đến 8 GPU, mức chiếm dụng bộ nhớ MoE trên mỗi GPU có thể giảm xuống còn 1/8 so với ban đầu.
Từ kết quả thử nghiệm, đối với Qwen3, công nghệ này có thể giảm bộ nhớ đỉnh từ 68.2GiB xuống 48.1GiB, giảm 29%.
Đối với mô hình Nemotron Nanomo, mức chiếm dụng bộ nhớ giảm từ 62.1 GiB xuống 42.5 GiB, giảm 32%.
Không gian được giải phóng có thể được sử dụng để hỗ trợ kích thước batch lớn hơn, chuỗi dài hơn.
DeepEP
DeepEP thực hiện hợp nhất tính toán và truyền thông.
Trong cách truyền thống, giữa việc phân phối token và tính toán chuyên gia có chi phí truyền thông đáng kể. DeepEP tích hợp các thao tác phân phối và kết hợp token vào kernel GPU được tối ưu, đạt được sự chồng chéo giữa quá trình truyền thông và tính toán chuyên gia.
TransformerEngine
Kernel TransformerEngine cung cấp gia tốc cho các phép toán lõi khác nhau.
Công nghệ này cung cấp các triển khai hợp nhất cho cơ chế chú ý (attention), lớp tuyến tính và RMSNorm, không chỉ tăng tốc lớp MoE mà còn tăng tốc lớp Transformer thông thường.
Một Dòng Import, Tăng Tốc 3 Lần
Tóm lại, đối với những ai đã sử dụng Transformers v5, NVIDIA NeMo AutoModel mang đến một giải pháp nâng cấp không đau:
Chỉ cần thêm một dòng mã import, bạn có thể ngay lập tức nhận được tốc độ fine-tune MoE tăng 3 lần.

Trên Qwen3-30B-A3B và Nemotron 3 Nano 30B-A3B, so với Transformers v5, giải pháp này có thể đạt được cải thiện thông lượng huấn luyện từ 3.4 đến 3.7 lần, đồng thời tiêu thụ bộ nhớ giảm 29%-32%.
NVIDIA cũng trình diễn kết quả fine-tune toàn bộ tham số của Nemotron 3 Ultra 550B A55B trên 16 node H100, 128 GPU.
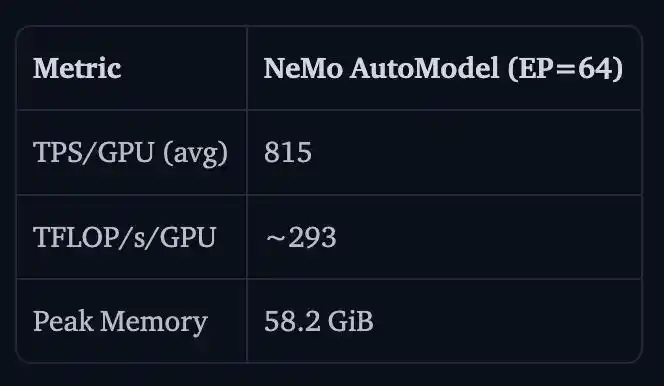
TPS/GPU là 815, TFLOP/s/GPU xấp xỉ 293, bộ nhớ đỉnh là 58.2GiB.
Lý do không so sánh với v5 ở đây, là vì Transformers v5 ở quy mô này sẽ trực tiếp làm tràn bộ nhớ ̄_(ツ)_/ ̄
Nếu quan tâm, NVIDIA đã đặt mã nguồn, cấu hình và script benchmark trên GitHub: https://github.com/NVIDIA-NeMo/Automodel/tree/blog/transformers-v5-automodel/blog_experiments
Hướng dẫn sử dụng cụ thể ở đây: https://docs.nvidia.com/nemo/automodel/latest/get-started/hf-compatibility
Bài viết từ tài khoản công chúng WeChat "QbitAI", tác giả: Yu Yang






