Source: The Token Dispatch
Author: Prathik Desai
Original Title: The Signal and the Noise
“Forecasts usually tell us more of the forecaster than of the future.”
— Warren Buffett
Money filters out empty talk. Supporters believe this is precisely why prediction markets are reliable. We saw people accurately predict the outcome of the 2024 U.S. presidential election on Polymarket and Kalshi. However, prediction markets themselves are not new, and their success in predicting political outcomes is not the first of its kind.
In October 1988, a group of economists at the University of Iowa supported their academic curiosity with a small, real-money prediction market. They launched a presidential election futures market where participants could buy contracts: if George H. W. Bush won, the contract paid $1; if Michael Dukakis won, it paid $0. On the eve of the election, Bush's contracts traded at 53 cents, while traditional polls suggested a close race. Ultimately, Bush won with 53.4% of the vote and a solid 8-point margin.
Since that academic experiment, these real-money futures markets have outperformed traditional polls in every election predicted more than 100 days in advance. In U.S. presidential elections since 1988, prediction markets have been closer to the final result than polls 74% of the time.
This success stems from a mechanism that forces people to express genuine beliefs backed by real money, something surveys can never achieve. Those who truly believed Bush would win bought and held contracts. For random participants, there is no incentive to spend $50 to support a claim they themselves do not believe. When this behavior aggregates thousands of traders, information converges into a price that reflects the true beliefs of a broad group, rather than a small, disproportionate sample.
That small academic experiment in Iowa, run on a shoestring budget, has now evolved into an institutionalized infrastructure.
Last week, a working paper authored by economists affiliated with the Federal Reserve noted that Kalshi, the largest regulated prediction market in the U.S., could serve as a valuable real-time benchmark for policymakers. The same week, New York Stock Exchange (NYSE) President Lynn Martin stated that Polymarket, the world's highest-volume prediction market, moved S&P index futures on election night by pricing Donald Trump's victory earlier than any news organization. Subsequently, Kalshi announced a partnership with a trading platform that handles $2.6 trillion in daily institutional volume.
In today's in-depth analysis, I will explore whether prediction markets can serve as reliable barometers for policymaking and what risks they bring.
Prediction Markets as Policymaking Tools
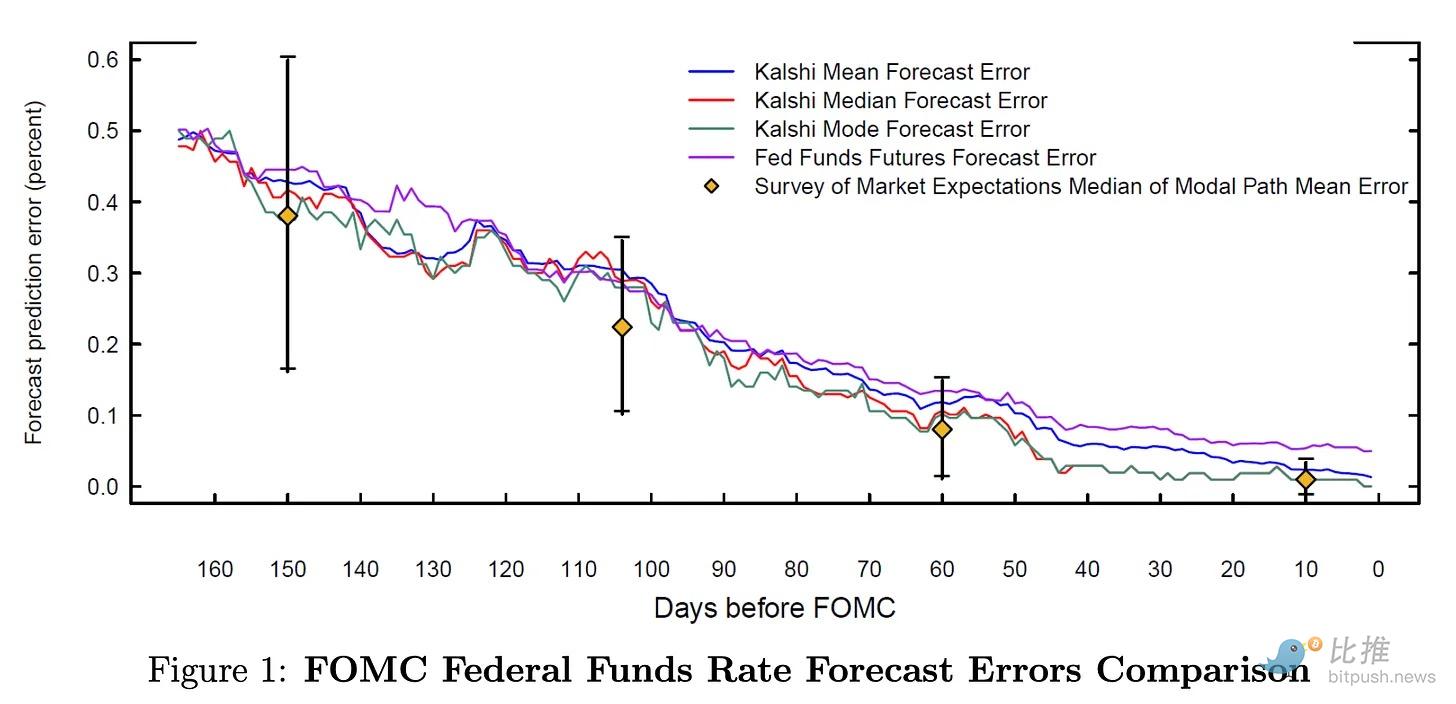
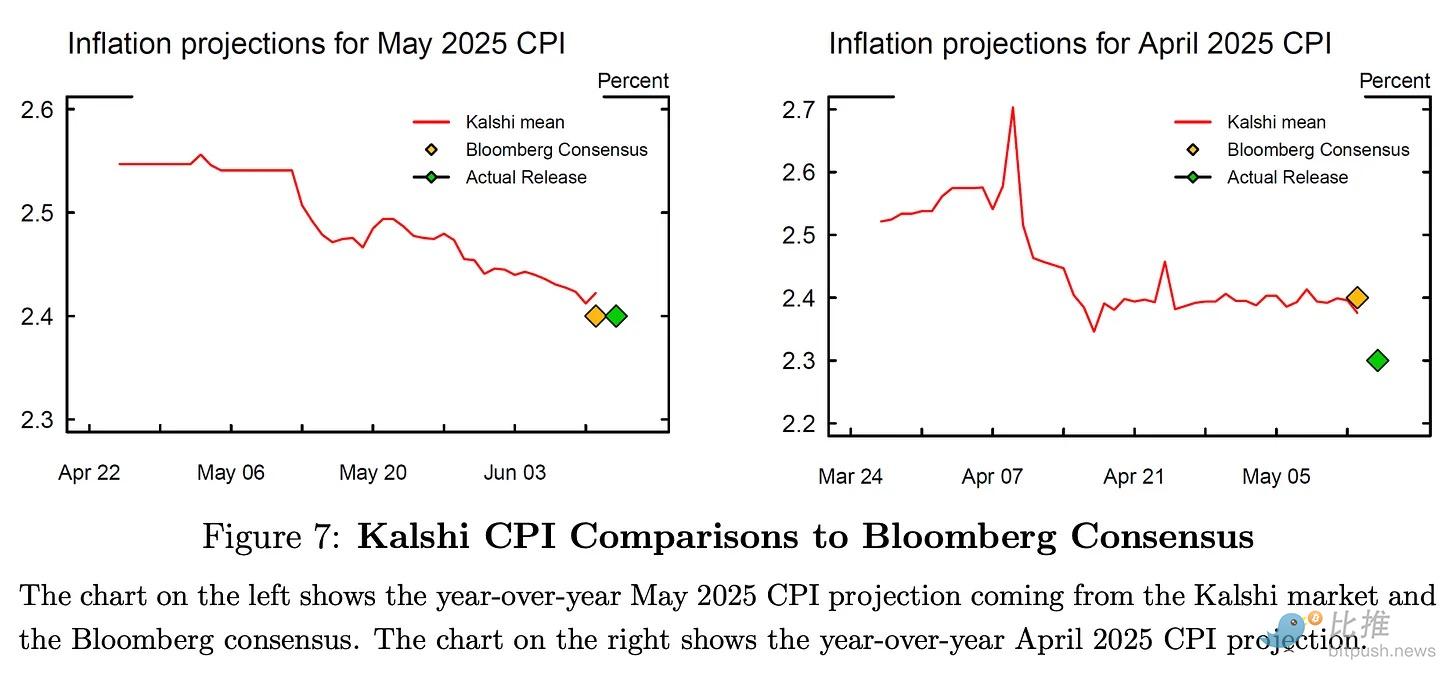
The paper found that Kalshi's predictions are statistically similar to Bloomberg's consensus expectations, with nearly identical prediction errors for core CPI and unemployment rates. In fact, the paper also found that Kalshi's predictions for core CPI were significantly better than Bloomberg's estimates.
@FederalReserve
Despite similar statistical performance, Kalshi's uniqueness lies in its ability to provide more frequent, real-time probability curve updates for macroeconomic indicators such as GDP growth, core CPI, and unemployment rates. For estimates like inflation, the Bloomberg consensus is only available in the months leading up to the data release. This makes traditional estimates less frequent, with longer gaps that fail to reflect real-time expectation updates.
Kalshi not only provides predictions of outcomes but also real-time uncertainty ranges and tail risks. In early April 2025, uncertainty about trade policy temporarily raised inflation expectations. Although this uncertainty did not materialize, Kalshi priced this dynamic in real time. Monthly Bloomberg estimates could never capture this nuance.
@FederalReserve
Today, when Federal Reserve governors speak at Federal Open Market Committee (FOMC) meetings, Kalshi's market odds move in real time. They price every word from the governors, providing policymakers with a perspective on how traders interpret the expected information.
For example, when Christopher J. Waller made dovish remarks ahead of the July 2025 FOMC meeting, the probability of no rate cut fell to 75%. After the stronger-than-expected June jobs report, this probability quickly rebounded to over 90%. The entire expectation of traders, backed by real money, is presented to policymakers in a way no other tool can currently achieve.
Who Trades on These Markets?
Before deciding how much to trust prediction markets, it is important to examine who is trading and what the volume represents.
Between September 2024 and January 2026, volume on Polymarket for FOMC meetings grew 11-fold, from $59 million to $660 million. In total, Polymarket's FOMC markets processed $2.6 billion, surpassing the combined total of the platform's culture, economy, geopolitics, and science categories.
So, who is trading such large amounts on FOMC meetings? While it is difficult to pinpoint on anonymous prediction platforms like Polymarket, we can speculate: it is hard not to think of macro hedge fund analysts involved in drafting labor statistics reports, or money market fund managers who stand to gain if rates are not cut.
Why them? The Iowa market worked because the number of people who put their money where their mouth is, with reliable information, outweighed those who merely gambling without it. While acknowledging the risk of over-assumption, I believe that when real stakes and funds of this scale are involved, those with reliable information converge on the market, leading to more accurate price discovery.
What to Be Wary Of
All this does not mean prediction markets can be perfect measuring tools for policymakers.
Probabilities in prediction markets also reflect traders' risk preferences. They are not a raw reflection of outcome expectations. For example, when Kalshi prices the probability of unfavorable CPI data at 15% while traditional surveys price it at 10%, this gap can be explained by two factors:
-
Prediction markets may be pricing real-time information missed by the Bloomberg consensus.
-
Traders may be paying a premium on prediction markets to hedge against unfavorable outcomes.
Policymakers must understand what this gap reflects before treating this information as a signal for policymaking.
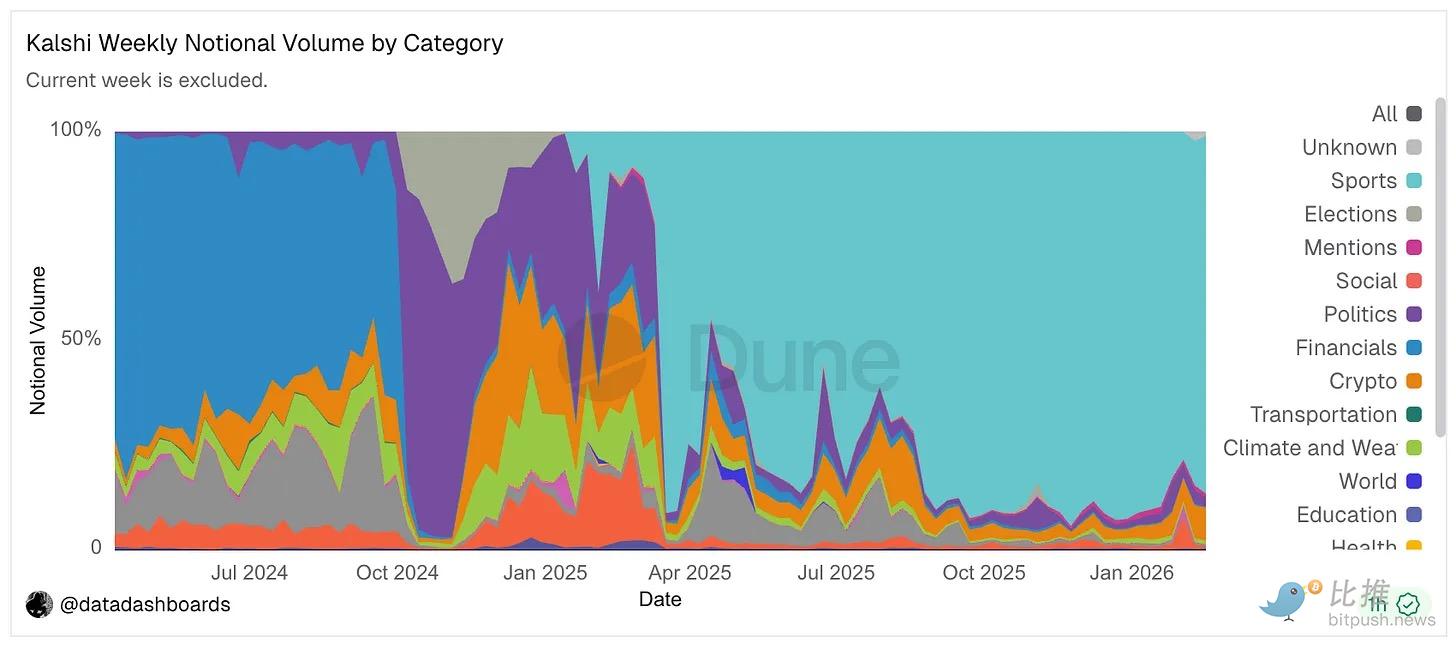
While Kalshi's macroeconomic signals to policymakers seem reliable, over 85% of its total nominal volume comes from the sports category.
@Dune
Currently, at least 20 federal lawsuits are challenging the regulatory arbitrage achieved through nationwide sports betting for prediction markets.
The reliability of Kalshi's FOMC markets is partly due to sports betting providing the platform with foundational liquidity through active traders, narrow bid-ask spreads, and market-making infrastructure, which sustains all Kalshi markets. Although macro markets operate independently, they benefit from this foundation. If sports betting disappears under regulatory pressure, the platform will lose the liquidity engine that keeps spreads tight and prices continuous. Thinner macro markets become easier to move with less capital, making them more susceptible to manipulation.
The Fed's paper recommends using Kalshi as a monitoring tool, not a decision-making input. But making this intention public is itself problematic.
The authors suggest greater use of Kalshi to interpret incoming data and check real-time interpretations of Fed communications. However, because the intention to reference prediction markets is public, it could create a feedback loop.
For example, a policymaker at the Fed might see Kalshi pricing a 15% probability of a rate cut, lower than the expectation they wish to convey through their actions. In response, they might soften their rhetoric in the next speech, which could then cause fluctuations in global traditional interest rate markets. The problem here is that while Kalshi's FOMC market size is $660 million, the federal funds futures market is worth hundreds of billions of dollars. The former requires relatively small positions to change the odds. A well-funded participant, aware that moving Kalshi could influence subsequent Fed remarks (if not decisions), could use relatively small positions to move a much larger market. Policymakers' communications could become targets for manipulation.
This scenario highlights the difference between the 1988 Iowa futures market and the 2026 prediction markets. The Iowa economists back then simply wanted to determine if a market with real stakes could produce better predictions than surveys. At that time, policymaking was not under such close scrutiny to deter manipulators.
Back then, prices reflected true beliefs because those prices did not influence the world. They merely allowed those with insights to monetize them. Once the Fed publicly announces (if it does so) its intention to use prediction markets as a policy input, this attribute disappears. It also introduces a "performative" element to trading.
However, incorporating prediction market odds into the policy toolbox is not a misstep. Financial commitment still filters out empty talk. Informed participants continue to dominate price discovery. The result is a signal unmatched by surveys in terms of speed and distribution richness. For FOMC markets, this is more pronounced than any other application: there are participants on both sides with genuine hedging capabilities, and the market, by pricing real-time events frequently, better reflects real-time expectations.
Policymakers should mandate open-source data transparency as a prerequisite for formal adoption. If the data is not auditable, manipulation may go undetected. They should understand that both signal and noise come from the same place. People with real money and real beliefs can tell you what they think in real time.
For those powerful enough to game the system, this window of opportunity did not exist when the Iowa economists were conducting their academic experiment decades ago. Today, this window is wider than ever.
Twitter:https://twitter.com/BitpushNewsCN
Bitpush TG Discussion Group:https://t.me/BitPushCommunity
Bitpush TG Subscription: https://t.me/bitpush





