
Hãy tưởng tượng một cảnh: bạn yêu cầu ba trợ lý AI hợp tác để giải một bài toán.
Cách làm truyền thống là - AI đầu tiên “viết” ra ý tưởng giải, AI thứ hai “đọc” xong rồi viết ý tưởng mới, AI thứ ba lại “đọc” rồi “viết”.
Quá trình này, giống như ba người lần lượt dùng bộ đàm để truyền tin, mỗi lần đều phải “dịch” suy nghĩ trong đầu thành ngôn ngữ, người kia lại “dịch” ngôn ngữ trở lại thành suy nghĩ. Chậm không? Chậm. Tốn kém không? Tốn. Quan trọng hơn, quá trình “dịch” này sẽ làm mất thông tin – những gì bạn nghĩ trong đầu và những gì bạn nói ra, thường không phải là một.
Đây chính là khó khăn cốt lõi mà các hệ thống AI đa tác tử hiện tại đang phải đối mặt: “Thuế ngôn ngữ”.
Và gần đây, UIUC, Stanford, Nvidia, MIT đã cùng đề xuất một cách tiếp cận mới – RecursiveMAS. Nó cho phép các AI bỏ qua bước “nói chuyện”, trực tiếp giao tiếp bằng “tư duy”. Trong thử nghiệm thực tế, tốc độ suy luận đã tăng 2.4 lần, tiêu thụ Token cắt giảm 75%.
(Hướng dẫn nghiên cứu: https://arxiv.org/abs/2604.25917)
Khó khăn của cuộc họp AI: Hiệu suất đều lãng phí vào việc “nói chuyện”
Hai năm qua, hệ thống đa tác tử đã trở thành hướng nghiên cứu nổi bật nhất trong lĩnh vực AI. Từ Swarm của OpenAI đến Microsoft AutoGen, từ LangGraph đến CrewAI, các công ty đều đang khám phá cách để nhiều AI hợp tác giải quyết các nhiệm vụ phức tạp mà một mô hình đơn lẻ không thể hoàn thành độc lập. Tuy nhiên, trong các hệ thống này, hiệu quả hợp tác của nhiều tác tử luôn bị một giả định cơ bản hạn chế – các tác tử phải giao tiếp thông qua văn bản ngôn ngữ tự nhiên.
Khi bạn yêu cầu một “chuyên gia toán học” và một “người kiểm tra mã” hợp tác, toàn bộ quy trình trông rất “hợp lý”, nhưng phân tích ra sẽ thấy nhiều vấn đề:
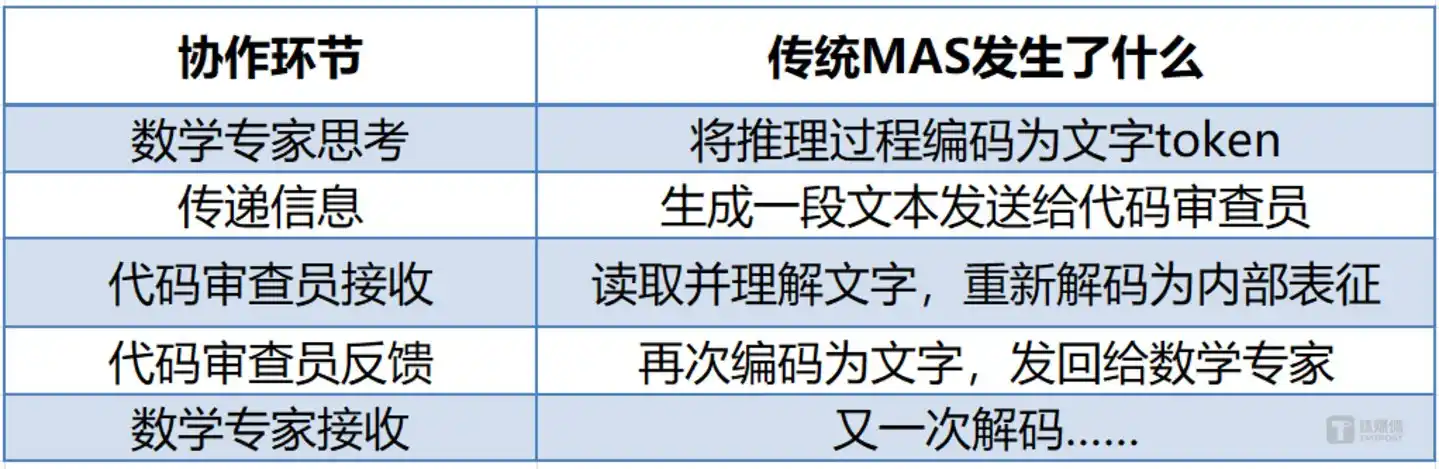
Mỗi lần truyền thông tin, đều đi kèm với chuyển đổi kép: tư duy nội bộ → văn bản → tư duy nội bộ. Quá trình này tiêu tốn token không chỉ là tiền bạc, mà còn là tài nguyên tính toán và thời gian quý giá. Quan trọng hơn, quá trình “viết ra rồi đọc vào” này sẽ làm mất thông tin – ngữ nghĩa phong phú được nén vào văn bản khi mô hình giải mã, mô hình tiếp theo khi giải mã lại đã không thể khôi phục hoàn toàn. Trong một luồng công việc chứa năm Agent, chi phí thời gian mã hóa/giải mã văn bản thường chiếm hơn 60% tổng độ trễ.
Đáng lo ngại hơn, mô hình này luôn thiếu một “nút vặn” rõ ràng để tối ưu hóa hệ thống – tăng thêm nhiều tác tử? Lợi ích biên giảm dần, và chi phí giao tiếp tăng theo cấp số nhân. Tăng cửa sổ ngữ cảnh? Chi phí Token bùng nổ. Tăng tham số mô hình? Mỗi Agent mạnh hơn, nhưng hiệu quả hợp tác không tăng lên cơ bản – giống như cấp cho mỗi người một bộ đàm tốt hơn, nhưng họ vẫn phải đọc chữ lần lượt, cách giao tiếp không thay đổi, dù mỗi người thông minh hơn, hiệu suất tổng thể cũng không thể đột phá. Các giải pháp đối phó trong ngành, dù là kỹ thuật tạo lời nhắc hay vi tinh chỉnh LoRA, chỉ có thể làm giảm triệu chứng ở một mức độ nào đó, không thể chữa khỏi vấn đề kiến trúc cơ bản này.
RecursiveMAS: Dùng “thần giao cách cảm” thay thế “bộ đàm”
Tư tưởng cốt lõi của RecursiveMAS rất khéo léo: Vì ngôn ngữ là nút thắt, thì không dùng ngôn ngữ nữa.
Nó vay mượn tư tưởng từ mô hình ngôn ngữ đệ quy (Recursive Language Model). Trong mô hình ngôn ngữ truyền thống, dữ liệu chảy từ tầng đầu đến tầng cuối, tiến lên tuyến tính, số tầng càng nhiều, tham số càng nhiều; còn mô hình ngôn ngữ đệ quy đi ngược lại – không tăng số tầng, mà lặp đi lặp lại sử dụng cùng một nhóm tầng, để dữ liệu “xoay vòng” giữa các tầng. Dữ liệu mỗi lần đi qua nhóm tầng này, tương đương với một vòng “tư duy” thêm, độ sâu suy luận được tăng lên, nhưng số lượng tham số lại không cần tăng.
RecursiveMAS mở rộng tư tưởng này từ “bên trong mô hình đơn” sang “hệ thống đa tác tử”:
Mỗi tác tử giống như một tầng trong mô hình ngôn ngữ đệ quy, chúng không còn tạo ra văn bản, mà truyền “tư tưởng” – một biểu diễn vector liên tục, tồn tại trong không gian tiềm ẩn (latent space).
Các nhà nghiên cứu đã dùng một phép ẩn dụ thi vị: “agents communicating telepathically as a unified whole” – các tác tử hợp tác như một thể thống nhất thông qua thần giao cách cảm.
Cụ thể, Agent A1 xử lý xong truyền biểu diễn tiềm ẩn của mình cho Agent A2, A2 xử lý xong lại truyền cho A3...... cho đến khi Agent cuối cùng xử lý xong, đầu ra tiềm ẩn của nó lại được truyền trực tiếp ngược về A1, khởi động một vòng lặp đệ quy mới. Toàn bộ quá trình diễn ra hoàn toàn trong không gian tiềm ẩn, chỉ đến Agent cuối cùng của vòng cuối cùng, mới giải mã biểu diễn tiềm ẩn cuối cùng thành văn bản đầu ra. Điều này giống như một nhóm chuyên gia ngồi quanh bàn, không cần nói, không cần viết ghi chú, mỗi người chỉ cần lặng lẽ suy nghĩ, rồi trực tiếp truyền “thành quả tư duy” trong đầu mình cho người tiếp theo – toàn bộ quá trình vừa yên tĩnh vừa hiệu quả.
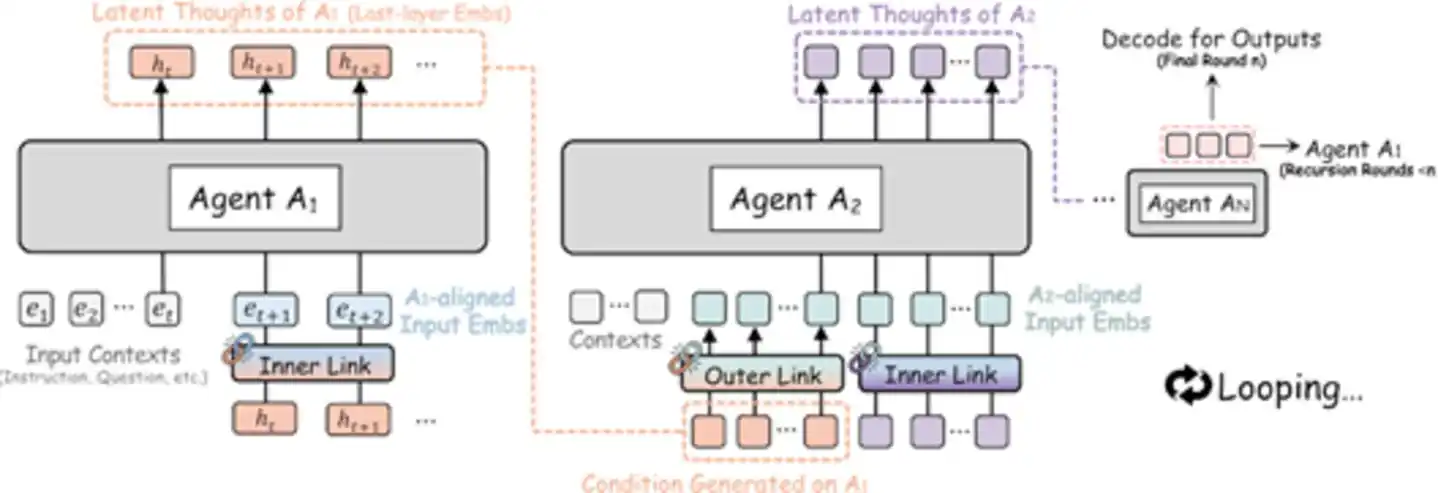
Hình: Kiến trúc RecursiveMAS – đa Agent hợp tác đệ quy vòng kín thông qua không gian nhúng (Nguồn: arXiv)
Thành phần chính của hệ thống này gọi là RecursiveLink, một mô-đun dư hai tầng nhẹ, chịu trách nhiệm giữ và chuyển đổi biểu diễn tầng ẩn của một mô hình, sau đó truyền vào không gian nhúng của mô hình tiếp theo. Trạng thái ẩn của tầng cuối cùng trong mô hình ngôn ngữ, thực tế đã mã hóa thông tin suy luận ngữ nghĩa phong phú, RecursiveLink cần làm là “chuyển” những thông tin đa chiều này một cách nguyên vẹn, chứ không phải dịch thành văn bản rồi giải thích lại. Nó chia thành hai phiên bản trong và ngoài:

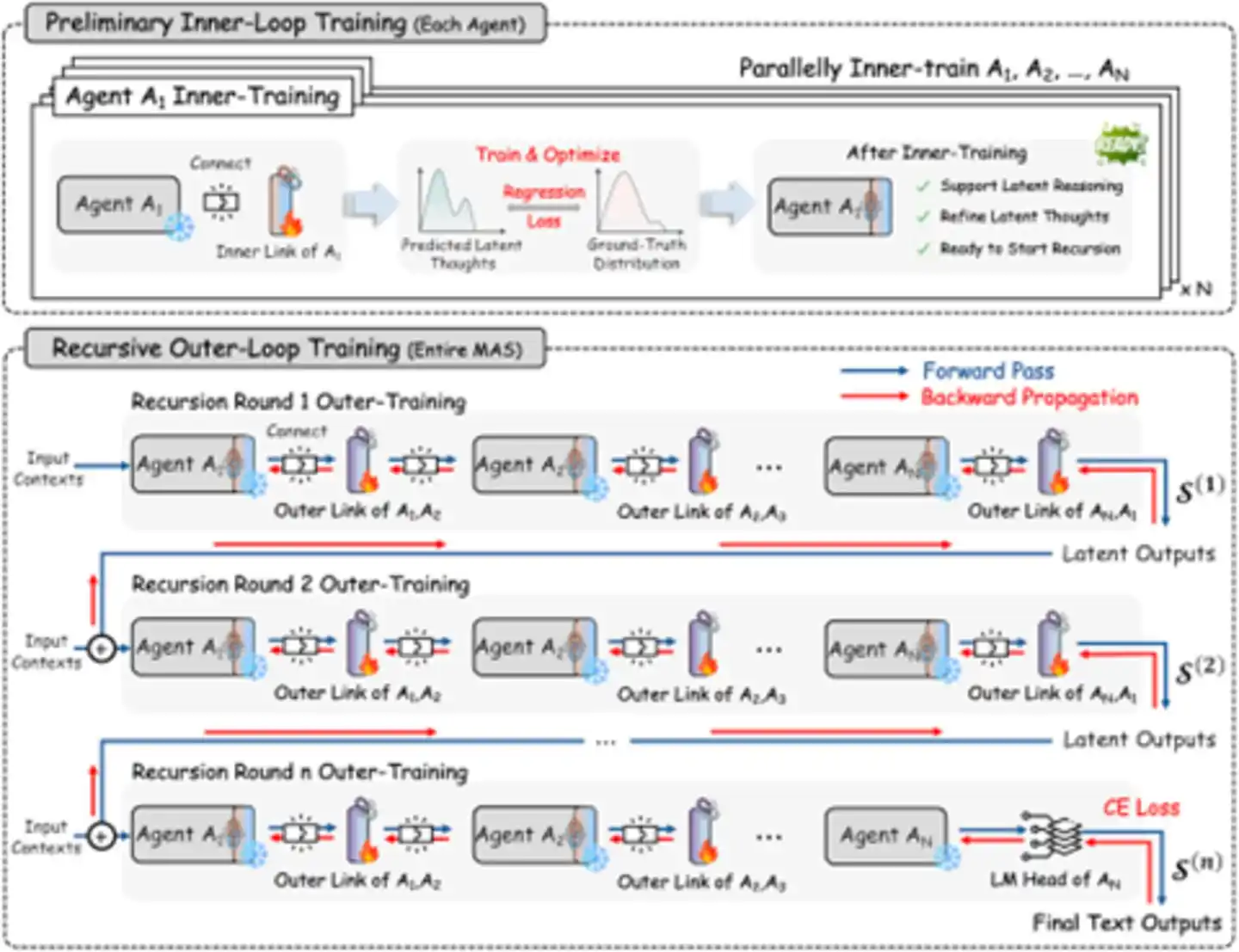
Hình: Quá trình học đệ quy – liên kết nội bộ và liên kết bên ngoài huấn luyện phối hợp (Nguồn: arXiv)
Về chiến lược huấn luyện, RecursiveMAS có một thiết kế tinh tế: Trọng số mô hình chính hoàn toàn đóng băng, chỉ cần huấn luyện mô-đun RecursiveLink. Điều này có tinh thần tương tự LoRA (Low-Rank Adaptation), nhưng RecursiveLink nhẹ hơn: toàn bộ hệ thống chỉ cần cập nhật khoảng 13 triệu tham số, chỉ chiếm 0.31% tổng số tham số có thể huấn luyện. Nhu cầu bộ nhớ GPU đỉnh điểm thấp nhất trong tất cả các phương pháp so sánh, chi phí huấn luyện giảm hơn 50% so với vi tinh chỉnh toàn bộ. Bạn có thể hiểu nó như một “đầu nối nhẹ”, cắm trực tiếp vào hệ sinh thái Agent hiện có, không cần huấn luyện lại mô hình mới từ đầu. Nếu nhiều Agent dựa trên cùng một mô hình nền (ví dụ đều dùng Qwen), chúng thậm chí có thể chia sẻ cùng một bộ trọng số mô hình, tiết kiệm thêm bộ nhớ.
Huấn luyện tiến hành theo hai giai đoạn:
Khởi động vòng lặp nội bộ: Các tác tử độc lập huấn luyện RecursiveLink Nội bộ của riêng mình, để chúng học cách “nghĩ vấn đề” trong không gian tiềm ẩn thay vì “viết vấn đề”. Giai đoạn này có thể tiến hành song song, giống như để mỗi người luyện tập “độc thoại nội tâm”.
Huấn luyện vòng lặp bên ngoài: Nối tất cả tác tử thành một chuỗi đệ quy hoàn chỉnh, lấy chất lượng đầu ra văn bản cuối cùng làm mục tiêu tối ưu hóa, thông qua gradient chia sẻ để tối ưu hóa chung tất cả RecursiveLink. Giai đoạn này giải quyết vấn đề “phân bổ công trạng” – làm thế nào để quy kết thành bại của kết quả cuối cùng một cách chính xác cho đóng góp của mỗi Agent. Chiến lược phân giai đoạn này tránh được vấn đề bất ổn định huấn luyện có thể xảy ra nếu “thực hiện một bước”.
Các nhà nghiên cứu đã chứng minh trên lý thuyết rằng gradient huấn luyện đệ quy có thể giữ ổn định, không xuất hiện vấn đề gradient bùng nổ hoặc biến mất thường thấy trong RNN, đồng thời về độ phức tạp thời gian chạy cũng vượt trội so với MAS kiểu văn bản truyền thống.
Hiệu quả thực tế: Độ chính xác, tốc độ, chi phí “ba diệt”
Lý thuyết nói hay đến đâu, cuối cùng vẫn phải dùng số liệu nói chuyện. Nhóm nghiên cứu đã tiến hành đánh giá toàn diện trên 9 bài kiểm tra chuẩn chính thống thuộc các lĩnh vực toán học, khoa học và y học, tạo mã, hỏi đáp tìm kiếm và 4 chế độ hợp tác (suy luận tuần tự, hỗn hợp chuyên gia, chưng cất kiến thức, gọi công cụ kiểu thương lượng). Dàn mô hình nguồn mở sử dụng trong thí nghiệm khá “sang trọng” – Qwen, Llama-3, Gemma3, Mistral, những mô hình này được phân công vai trò khác nhau, tạo thành nhiều chế độ hợp tác.
Dàn đường cơ sở so sánh cũng rất mạnh: Vi tinh chỉnh LoRA, vi tinh chỉnh toàn bộ (SFT), Hỗn hợp-các-Agent, TextGrad, LoopLM, và Recursive-TextMAS sử dụng cùng cấu trúc đệ quy nhưng bắt buộc giao tiếp văn bản. So sánh cuối cùng này đặc biệt quan trọng – nó chứng minh ưu thế của RecursiveMAS thực sự đến từ “bỏ qua giải mã văn bản”, chứ không phải từ bản thân cấu trúc đệ quy. Tất cả so sánh đều tiến hành dưới ngân sách huấn luyện như nhau, công bằng chính trực.
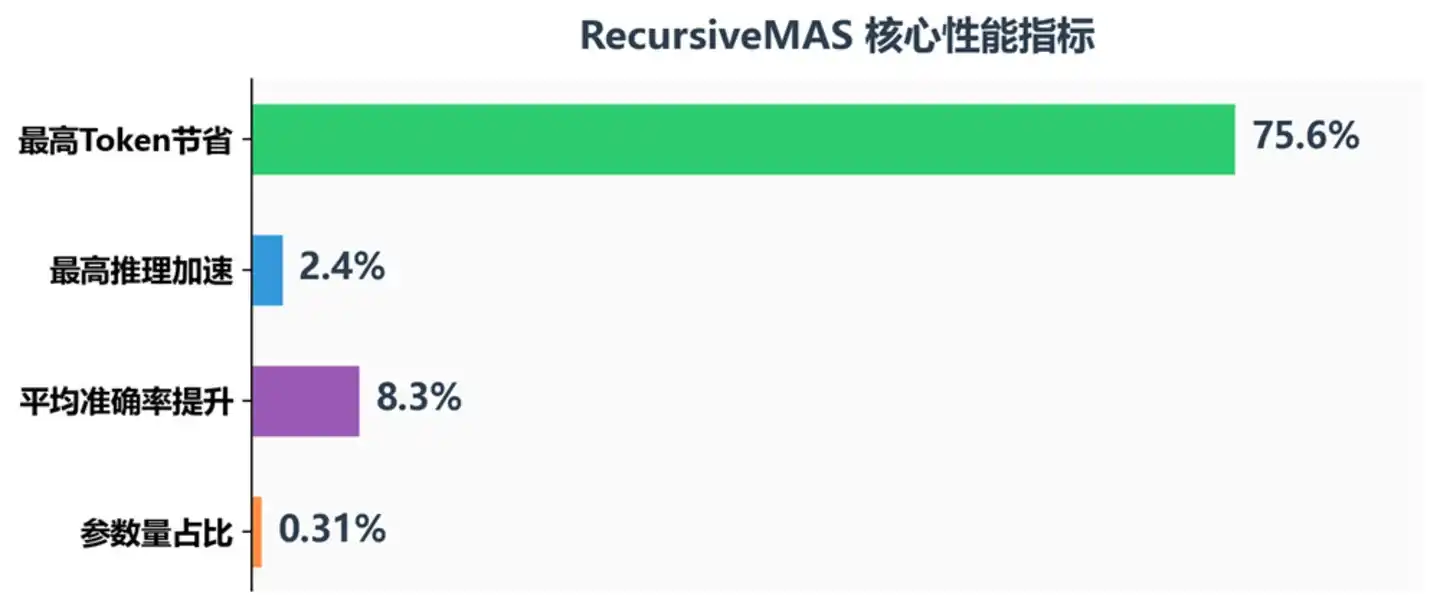
Chỉ số hiệu suất cốt lõi của RecursiveMAS
Kết quả cho thấy, RecursiveMAS đạt được cải thiện nhất quán trên tất cả các chỉ số:
Độ chính xác: Độ chính xác trung bình tăng 8.3%, trên cuộc thi toán AIME2025 cao hơn TextGrad 18.1%, trên AIME2026 cao hơn 13%. Bỏ qua giải mã văn bản không những không làm mất thông tin, mà còn giúp mô hình giữ lại ngữ nghĩa tầng ẩn phong phú hơn – xét cho cùng, việc nén tư duy thành văn bản rồi giải nén, sự hao hụt thông tin trong quá trình này lớn hơn chúng ta tưởng rất nhiều.
Tốc độ: Tốc độ suy luận đầu cuối tăng từ 1.2 đến 2.4 lần, và tiếp tục tăng khi số vòng đệ quy tăng. Điều này có ý nghĩa lớn với các tình huống ứng dụng thực tế: trong hệ thống hỗ trợ mã hoặc dịch vụ khách hàng AI cần phản hồi thời gian thực, cải thiện tốc độ hơn 2 lần có nghĩa là sự nhảy vọt về chất lượng trải nghiệm người dùng.
Chi phí: So với Recursive-TextMAS, tiêu thụ Token giảm từ 34.6% đến 75.6%. Đây không chỉ là tiết kiệm chi phí, mà còn có nghĩa trong cùng ngân sách token có thể thử suy luận ở tầng sâu hơn.
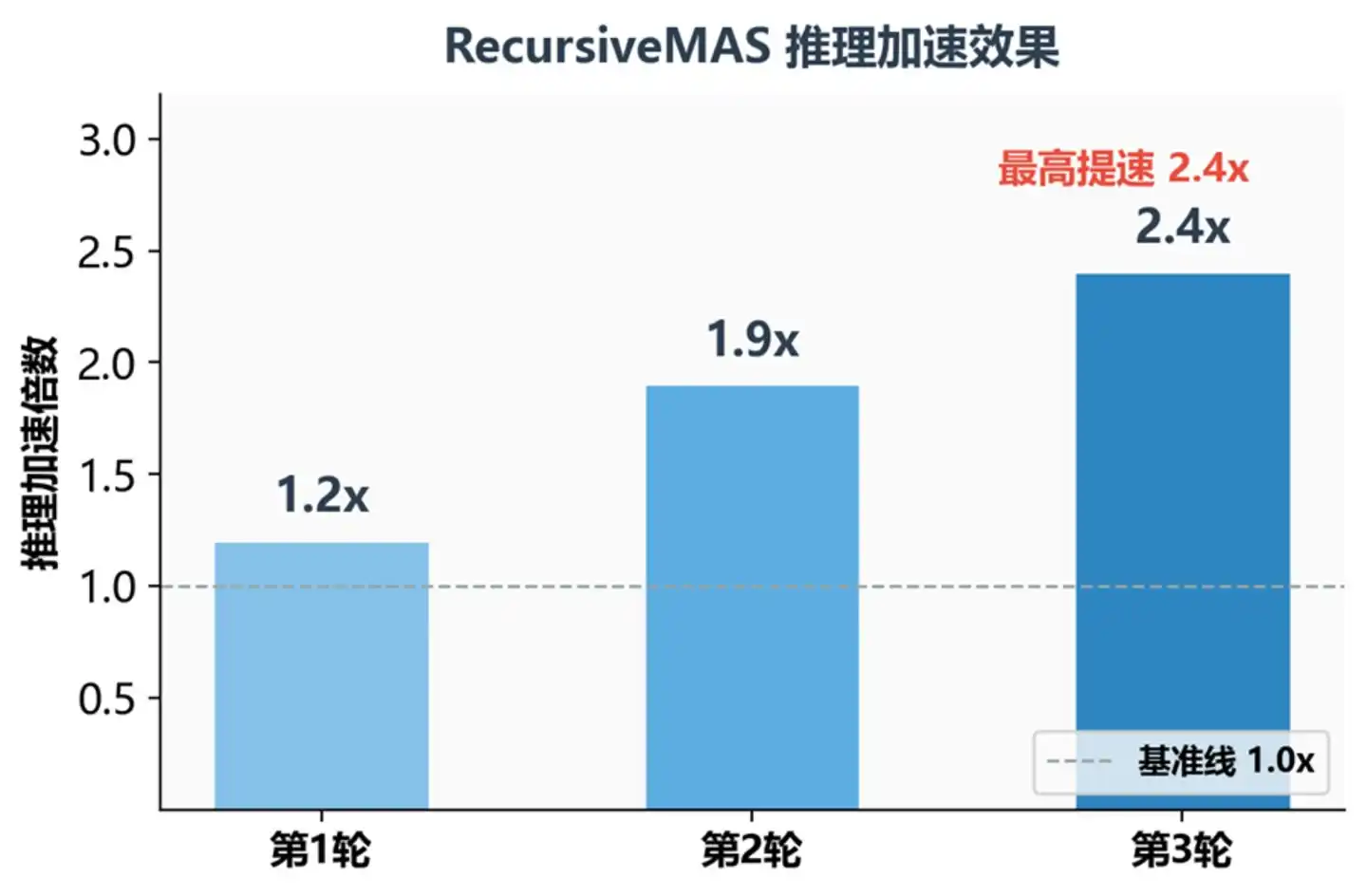
Số lần tăng tốc suy luận dưới các vòng đệ quy khác nhau
Ở đây có một thông tin quan trọng: Độ sâu đệ quy càng lớn, lợi ích càng cao. Hiệu ứng tăng tốc tăng theo số vòng đệ quy: vòng 1 trung bình 1.2 lần, vòng 2 là 1.9 lần, vòng 3 là 2.4 lần. Lý do đơn giản – tiết kiệm được thời gian mỗi Agent “viết ý tưởng thành văn bản”, Agent càng nhiều, vòng càng nhiều, tiết kiệm thời gian càng nhiều.
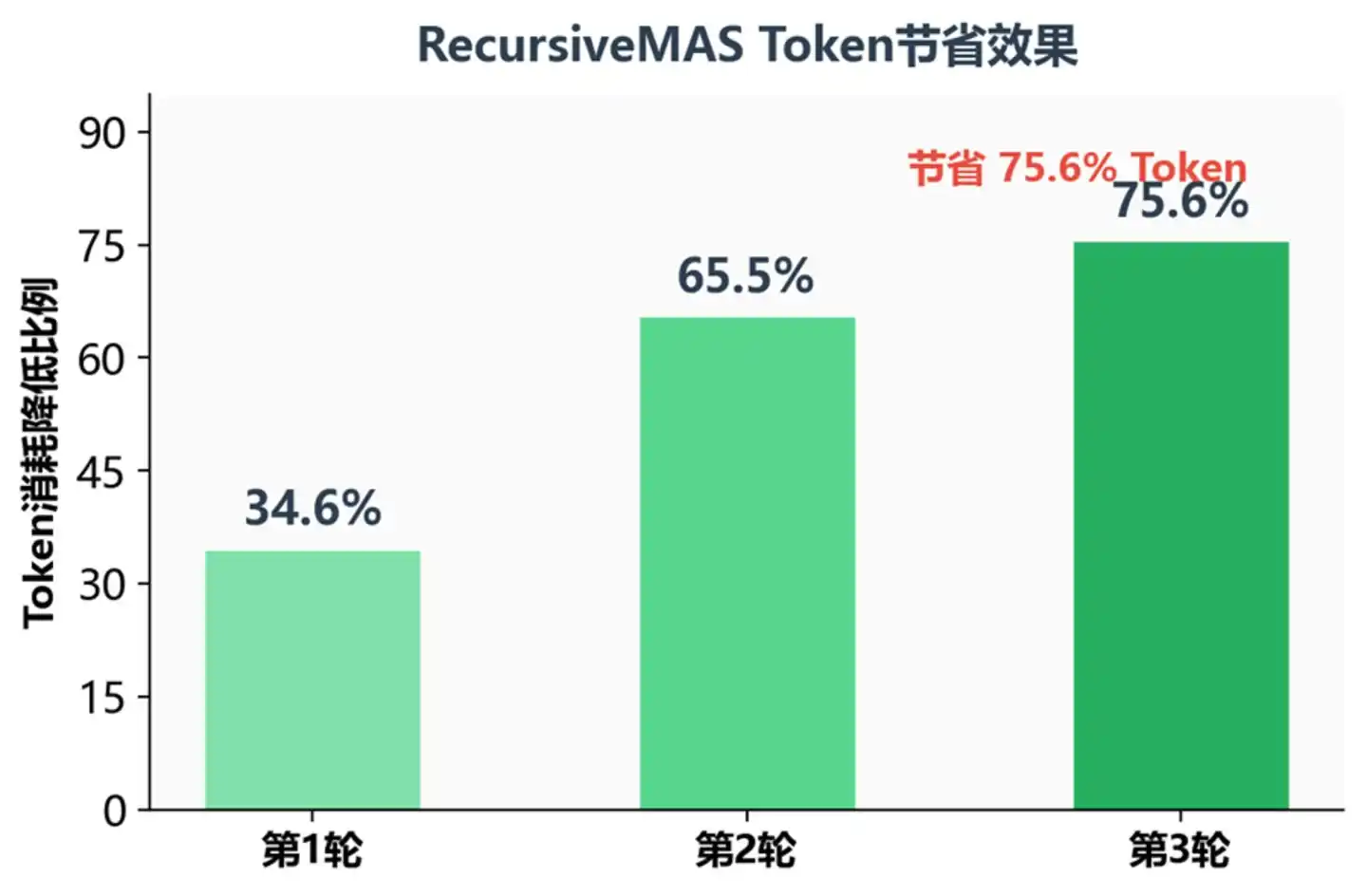
Tỷ lệ tiết kiệm Token dưới các vòng đệ quy khác nhau
Ở vòng đệ quy thứ ba, tiêu thụ Token giảm 75.6% – điều này có nghĩa với hiệu suất tương đương, chi phí vận hành có thể nén xuống còn khoảng một phần tư. Đối với môi trường sản xuất cần suy luận nhiều bước phức tạp, đây chắc chắn là sức hút lớn.
Tại sao nghiên cứu này đáng chú ý?
Nếu chỉ là cải thiện về số liệu, bài báo này có lẽ chưa đủ để gây chú ý nhiều như vậy. Điều thực sự khiến nó đáng chú ý, nằm ở việc nó có thể định nghĩa lại hướng Scaling của hệ thống đa tác tử.
Vài năm qua, thử nghiệm Scaling trong lĩnh vực đa tác tử chủ yếu xoay quanh ba con đường: tăng số lượng tác tử, mở rộng cửa sổ ngữ cảnh, chồng chất mô hình lớn hơn. Nhưng các phương pháp này đều đối mặt với nút thắt riêng – tác tử nhiều thì giao tiếp bùng nổ, cửa sổ lớn thì chi phí bùng nổ, mô hình lớn thì huấn luyện bùng nổ.
RecursiveMAS cung cấp một con đường mới: tăng độ sâu đệ quy. Nó biến “hợp tác đa tác tử” từ mô hình song song, tương tác văn bản, thành mô hình sâu, đệ quy không gian tiềm ẩn. Giống như mô hình ngôn ngữ đệ quy thông qua xử lý lặp lại cùng một vấn đề để làm sâu sắc suy luận, RecursiveMAS cho phép nhiều tác tử có thể “suy xét” lặp lại “ý tưởng” của nhau, mà không cần mỗi lần đều “nói ra rồi nghe lại”.
Câu hỏi cốt lõi mà các nhà nghiên cứu đặt ra trong bài báo là: “Bản thân sự hợp tác của tác tử có thể mở rộng thông qua đệ quy không?” Câu trả lời dường như là có.
Khi hệ thống không còn cần “dịch” biểu diễn nội bộ thành định dạng trung gian con người có thể đọc, giới hạn trên của hiệu quả hợp tác có hy vọng được mở ra thêm.
Bối cảnh ngành hiện tại cũng cung cấp các tình huống triển khai thực tế cho nghiên cứu này. Hội nghị nhà phát triển Baidu 2026 với chủ đề “Vạn vật nhất thể (Agents at Scale)”, Anthropic ra mắt Claude Managed Agents, OpenAI tiếp tục thúc đẩy thời gian thực hóa suy luận cấp GPT-5 – toàn ngành đang tìm kiếm phương pháp để đưa hợp tác Agent từ demo vào môi trường sản xuất. Và ba ngọn núi lớn – chi phí tính toán, độ trễ suy luận, hạn chế bộ nhớ – chính là những điều RecursiveMAS cố gắng xoay chuyển với chi phí tham số 0.31%.
Tất nhiên, nghiên cứu này hiện vẫn ở giai đoạn đầu, có vài vấn đề đáng chú ý:
Độ tin cậy dữ liệu cần xác minh. Kết quả hiện tại đều do tác tự báo cáo, chưa có nhóm độc lập nào hoàn thành xác nhận lại. Thái độ của giới học thuật với công nghệ mới thường là “giả thuyết mạnh dạn, xác minh cẩn thận”. Trong thời đại “bùng nổ bài báo” này, xác nhận lại độc lập là cách tốt nhất để kiểm tra giá trị thực của công nghệ.
Tính tương thích của các tác tử dị thể. Mặc dù Outer RecursiveLink được thiết kế để kết nối các mô hình kiến trúc khác nhau, nhưng bài báo không tiết lộ chi tiết việc truyền biểu diễn tiềm ẩn xuyên kiến trúc. Nếu chỉ có thể dùng cho các tác tử đồng cấu, phạm vi ứng dụng thực tế của nó sẽ giảm đáng kể. Xét cho cùng, trong tình huống thực tế nhiều lúc chúng ta cần kết hợp sử dụng các API đóng như GPT-4o, Claude.
Khả năng giải thích giảm. Khi các Agent truyền đi không còn là văn bản có thể đọc được, mà là một đống biểu diễn vector, toàn bộ quá trình hợp tác trở thành “hộp đen”. Trong môi trường sản xuất cần chịu trách nhiệm cho quyết định của AI, tính không minh bạch này có thể mang lại thách thức về tuân thủ và kiểm toán.
Độ phức tạp của môi trường sản xuất. Bài báo kiểm tra các tình huống hợp tác tương đối sạch sẽ, môi trường sản xuất thực tế thường liên quan đến các yếu tố phức tạp như gọi công cụ bên ngoài, tương tác người-máy, luồng công việc động.
Việc đề xuất RecursiveMAS, về bản chất là đưa chiến lược Scaling “đệ quy” – đã được chứng minh hiệu quả trong thời đại mô hình đơn – vào thời đại đa tác tử, thách thức giả định mặc định “các tác tử phải truyền thông tin thông qua ngôn ngữ tự nhiên”. Nếu dữ liệu có thể xác nhận lại, trục Scaling của giai đoạn tiếp theo trong đường đua MAS có thể chuyển từ “chồng số lượng tác tử” sang “tăng độ sâu đệ quy”.
Tất nhiên, nghiên cứu này vẫn cần được xác minh trên nhiều bài kiểm tra chuẩn độc lập hơn, cần giải quyết vấn đề kết nối các mô hình dị thể, cần chứng minh bản thân trong môi trường sản xuất thực tế. Nhưng ít nhất, nó cho chúng ta thấy một khả năng –
Sự hợp tác giữa các tác tử AI, có thể không cần luôn luôn “gà nói với vịt”.
((Bài viết này xuất bản lần đầu trên ứng dụng TMT Post, tác giả | Silicon Valley Tech_news, biên tập | Jiao Yan))






