Tác giả: Lý Hải Luân, Tô Dương
Vào ngày 6 tháng 1 giờ Bắc Kinh, CEO NVIDIA Jensen Huang một lần nữa xuất hiện trên sân khấu chính của CES2026 trong chiếc áo da biểu tượng.
Tại CES năm 2025, NVIDIA đã trình diễn chip Blackwell sản xuất hàng loạt và ngăn xếp công nghệ AI vật lý hoàn chỉnh. Tại hội nghị, Huang nhấn mạnh rằng một "thời đại AI vật lý" đang bắt đầu. Ông đã vẽ nên một tương lai đầy trí tưởng tượng: xe tự lái có khả năng suy luận, robot có thể hiểu và suy nghĩ, AIAgent (tác nhân thông minh) có thể xử lý các tác vụ ngữ cảnh dài với hàng triệu token.
Một năm trôi qua, ngành công nghiệp AI đã trải qua những biến chuyển to lớn. Khi nhìn lại những thay đổi trong năm nay tại buổi ra mắt, Huang đặc biệt nhắc đến các mô hình mã nguồn mở.
Ông nói, các mô hình suy luận mã nguồn mở như DeepSeek R1 đã khiến toàn ngành nhận ra: khi sự hợp tác mở và toàn cầu thực sự được khởi động, tốc độ lan tỏa của AI sẽ cực kỳ nhanh. Mặc dù các mô hình mã nguồn mở vẫn chậm hơn khoảng nửa năm so với các mô hình tiên tiến nhất về tổng thể năng lực, nhưng cứ sau sáu tháng lại tiến gần hơn một bước, và lượng tải xuống cũng như sử dụng đã tăng trưởng bùng nổ.

So với năm 2025 tập trung nhiều hơn vào viễn cảnh và khả năng, lần này NVIDIA bắt đầu giải quyết một cách có hệ thống vấn đề "làm thế nào để đạt được": xoay quanh AI suy luận, bổ sung cơ sở hạ tầng tính toán, mạng lưới và lưu trữ cần thiết để vận hành lâu dài, giảm đáng kể chi phí suy luận và nhúng trực tiếp những khả năng này vào các kịch bản thực tế như lái xe tự động và robot.
Bài phát biểu của Jensen Huang tại CES lần này được triển khai xoay quanh ba chủ đề chính:
● Ở cấp độ hệ thống và cơ sở hạ tầng, NVIDIA đã tái cấu trúc kiến trúc tính toán, mạng lưới và lưu trữ xung quanh nhu cầu suy luận dài hạn. Với lõi là nền tảng Rubin, NVLink 6, Spectrum-X Ethernet và nền tảng lưu trữ bộ nhớ ngữ cảnh suy luận, những cập nhật này nhắm thẳng vào các nút thắt cổ chai như chi phí suy luận cao, ngữ cảnh khó duy trì và khả năng mở rộng bị hạn chế, giải quyết vấn đề AI suy nghĩ lâu hơn, tính toán được và chạy lâu dài.
● Ở cấp độ mô hình, NVIDIA đặt AI suy luận (Reasoning / Agentic AI) vào vị trí cốt lõi. Thông qua các mô hình và công cụ như Alpamayo, Nemotron, Cosmos Reason, thúc đẩy AI từ "tạo ra nội dung" tiến tới khả năng suy nghĩ liên tục, từ "mô hình phản hồi một lần" chuyển hướng sang "tác nhân thông minh có thể làm việc lâu dài".
● Ở cấp độ ứng dụng và triển khai thực tế, những khả năng này được đưa trực tiếp vào các kịch bản AI vật lý như lái xe tự động và robot. Cho dù là hệ thống lái xe tự động được cung cấp bởi Alpamayo, hay hệ sinh thái robot GR00T với Jetson, tất cả đều đang thúc đẩy triển khai quy mô lớn thông qua hợp tác với các nền tảng của nhà cung cấp dịch vụ đám mây và doanh nghiệp.

01 Từ lộ trình đến sản xuất hàng loạt: Rubin lần đầu tiên công bố đầy đủ dữ liệu hiệu năng
Tại CES lần này, NVIDIA lần đầu tiên công bố đầy đủ chi tiết kỹ thuật của kiến trúc Rubin.
Trong bài phát biểu, Huang bắt đầu với Test-time Scaling (Mở rộng khi suy luận), khái niệm này có thể hiểu là, để AI trở nên thông minh hơn, không còn chỉ là khiến nó "đọc nhiều hơn", mà là dựa vào việc "suy nghĩ thêm một lúc khi gặp vấn đề".
Trước đây, việc nâng cao năng lực AI chủ yếu dựa vào việc đổ thêm sức mạnh tính toán trong giai đoạn huấn luyện, làm cho mô hình ngày càng lớn hơn; còn bây giờ, thay đổi mới là ngay cả khi mô hình không tiếp tục mở rộng, chỉ cần cho nó thêm một chút thời gian và sức mạnh tính toán để suy nghĩ trong mỗi lần sử dụng, kết quả cũng có thể được cải thiện rõ rệt.
Làm thế nào để việc "AI suy nghĩ thêm một lúc" trở nên khả thi về mặt kinh tế? Nền tảng tính toán AI thế hệ mới với kiến trúc Rubin chính là để giải quyết vấn đề này.
Huang giới thiệu, đây là một hệ thống tính toán AI thế hệ tiếp theo hoàn chỉnh, thông qua thiết kế phối hợp của Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, Spectrum-6, nhằm đạt được sự sụt giảm cách mạng trong chi phí suy luận.

GPU Rubin của NVIDIA là chip lõi chịu trách nhiệm tính toán AI trong kiến trúc Rubin, mục tiêu là giảm đáng kể chi phí đơn vị cho suy luận và huấn luyện.
Nói một cách đơn giản, nhiệm vụ cốt lõi của GPU Rubin là "làm cho AI sử dụng ít tốn kém hơn và thông minh hơn".
Khả năng cốt lõi của GPU Rubin nằm ở: cùng một GPU có thể làm được nhiều việc hơn. Nó có thể xử lý nhiều tác vụ suy luận hơn trong một lần, ghi nhớ ngữ cảnh dài hơn, và giao tiếp với các GPU khác cũng nhanh hơn, điều này có nghĩa là nhiều kịch bản vốn cần phải "xếp chồng nhiều card" giờ đây có thể hoàn thành với ít GPU hơn.
Kết quả là, suy luận không chỉ nhanh hơn mà còn rẻ hơn đáng kể.
Huang tại hiện trường đã ôn lại các thông số phần cứng NVL72 của kiến trúc Rubin: chứa 220 nghìn tỷ transistor, băng thông 260 TB/giây, là nền tảng đầu tiên trong ngành hỗ trợ tính toán bảo mật quy mô giá đỡ.

Nhìn chung, so với Blackwell, GPU Rubin đạt được bước nhảy vọt thế hệ ở các chỉ số quan trọng: Hiệu năng suy luận NVFP4 tăng lên 50 PFLOPS (gấp 5 lần), hiệu năng huấn luyện tăng lên 35 PFLOPS (gấp 3.5 lần), băng thông bộ nhớ HBM4 tăng lên 22 TB/s (gấp 2.8 lần), băng thông kết nối NVLink trên một GPU tăng gấp đôi lên 3.6 TB/s.
Những cải tiến này cùng tác động, khiến một GPU đơn lẻ có thể xử lý nhiều tác vụ suy luận hơn và ngữ cảnh dài hơn, từ căn bản giảm sự phụ thuộc vào số lượng GPU.

Vera CPU là thành phần lõi được thiết kế chuyên cho di chuyển dữ liệu và xử lý Agentic, sử dụng 88 lõi Olympus tự nghiên cứu của NVIDIA, trang bị 1.5 TB bộ nhớ hệ thống (gấp 3 lần Grace CPU thế hệ trước), thông qua công nghệ NVLink-C2C 1.8 TB/s để thực hiện truy cập bộ nhớ nhất quán giữa CPU và GPU.
Khác với CPU đa dụng truyền thống, Vera tập trung vào điều phối dữ liệu và xử lý logic suy luận nhiều bước trong các kịch bản suy luận AI, về bản chất là người điều phối hệ thống giúp việc "AI suy nghĩ thêm một lúc" có thể vận hành hiệu quả.
NVLink 6 thông qua băng thông 3.6 TB/s và khả năng tính toán trong mạng, cho phép 72 GPU trong kiến trúc Rubin có thể làm việc phối hợp như một siêu GPU, đây là cơ sở hạ tầng then chốt để đạt được việc giảm chi phí suy luận.
Bằng cách này, dữ liệu và kết quả trung gian mà AI cần khi suy luận có thể nhanh chóng lưu chuyển giữa các GPU, không cần phải chờ đợi, sao chép hoặc tính toán lại nhiều lần.


Trong kiến trúc Rubin, NVLink-6 chịu trách nhiệm tính toán phối hợp nội bộ GPU, BlueField-4 chịu trách nhiệm điều phối ngữ cảnh và dữ liệu, còn ConnectX-9 thì đảm nhận kết nối mạng tốc độ cao đối ngoại của hệ thống. Nó đảm bảo hệ thống Rubin có thể giao tiếp hiệu quả với các giá đỡ khác, trung tâm dữ liệu và nền tảng đám mây, là tiền đề cho việc vận hành suôn sẻ các tác vụ huấn luyện và suy luận quy mô lớn.
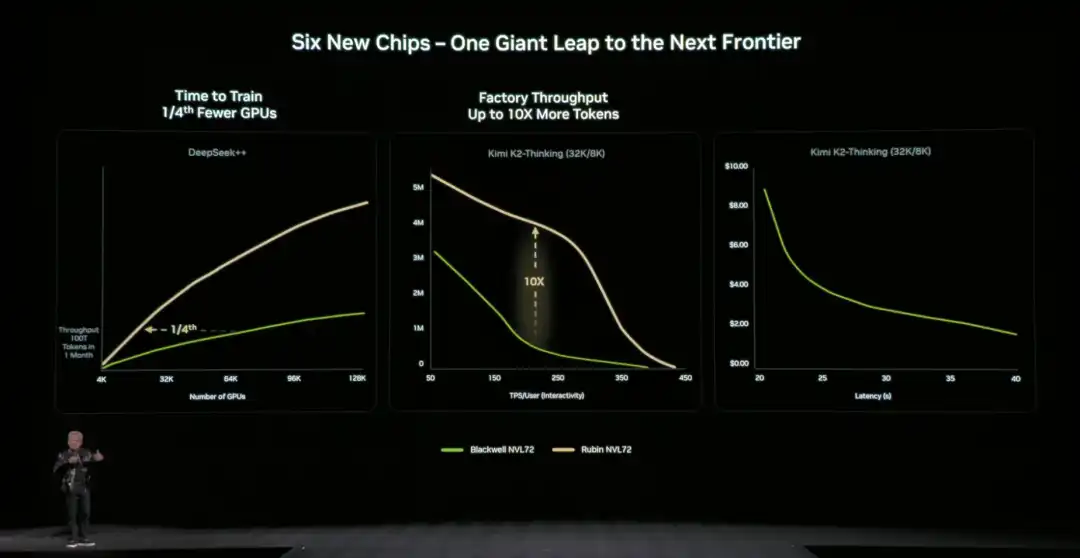
So với kiến trúc thế hệ trước, NVIDIA cũng đưa ra dữ liệu cụ thể trực quan: So với nền tảng NVIDIA Blackwell, có thể giảm chi phí token trong giai đoạn suy luận tối đa 10 lần, và giảm số lượng GPU cần thiết để huấn luyện mô hình chuyên gia hỗn hợp (MoE) xuống còn 1/4 so với ban đầu.
NVIDIA chính thức tuyên bố, hiện Microsoft đã cam kết triển khai hàng trăm nghìn chip Vera Rubin trong siêu nhà máy AI Fairwater thế hệ tiếp theo, các nhà cung cấp dịch vụ đám mây như CoreWeave sẽ cung cấp instance Rubin vào nửa cuối năm 2026, cơ sở hạ tầng "cho AI suy nghĩ thêm một lúc" này đang từ trình diễn kỹ thuật tiến tới thương mại hóa quy mô lớn.

02 "Nút thắt cổ chai lưu trữ" được giải quyết như thế nào?
Việc để AI "suy nghĩ thêm một lúc" còn đối mặt với một thách thức kỹ thuật then chốt: dữ liệu ngữ cảnh nên được đặt ở đâu?
Khi AI xử lý các tác vụ phức tạp cần đối thoại nhiều vòng, suy luận nhiều bước, sẽ tạo ra lượng lớn dữ liệu ngữ cảnh (KV Cache). Kiến trúc truyền thống hoặc là nhét chúng vào bộ nhớ GPU đắt đỏ và có dung lượng hạn chế, hoặc là đưa vào bộ lưu trữ thông thường (truy cập quá chậm). "Nút thắt cổ chai lưu trữ" này nếu không giải quyết, GPU mạnh đến mấy cũng bị kéo tụt.
Để giải quyết vấn đề này, NVIDIA tại CES lần này lần đầu tiên công bố đầy đủ nền tảng lưu trữ bộ nhớ ngữ cảnh suy luận (Inference Context Memory Storage Platform) được cung cấp bởi BlueField-4, mục tiêu cốt lõi là tạo ra một "lớp thứ ba" giữa bộ nhớ GPU và bộ lưu trữ truyền thống. Vừa đủ nhanh, vừa có dung lượng dồi dào, lại còn có thể hỗ trợ AI vận hành lâu dài.
Xét về mặt triển khai kỹ thuật, nền tảng này không phải là một thành phần đơn lẻ phát huy tác dụng, mà là kết quả của một thiết kế phối hợp:
- BlueField-4 chịu trách nhiệm tăng tốc quản lý và truy cập dữ liệu ngữ cảnh ở cấp phần cứng, giảm thiểu việc di chuyển dữ liệu và chi phí hệ thống;
- Spectrum-X Ethernet cung cấp mạng lưới hiệu năng cao, hỗ trợ chia sẻ dữ liệu tốc độ cao dựa trên RDMA;
- Các thành phần phần mềm như DOCA, NIXL và Dynamo, thì chịu trách nhiệm tối ưu hóa điều phối ở cấp hệ thống, giảm độ trễ, nâng cao thông lượng tổng thể.
Chúng ta có thể hiểu, cách làm của nền tảng này là, mở rộng dữ liệu ngữ cảnh vốn chỉ có thể đặt trong bộ nhớ GPU, ra một "lớp ký ức" độc lập, tốc độ cao, có thể chia sẻ. Một mặt giải phóng áp lực cho GPU, mặt khác lại có thể nhanh chóng chia sẻ thông tin ngữ cảnh này giữa nhiều node, nhiều tác nhân thông minh AI.
Về hiệu quả thực tế, dữ liệu do NVIDIA chính thức đưa ra là: trong các kịch bản cụ thể, cách này có thể làm tăng số token xử lý mỗi giây lên tối đa 5 lần, và đạt được mức tối ưu hóa hiệu suất năng lượng tương đương.
Huang nhiều lần nhấn mạnh trong buổi ra mắt, AI đang tiến hóa từ "chatbot đối thoại một lần", thành tác nhân hợp tác thông minh thực sự: chúng cần hiểu thế giới thực, suy luận liên tục, gọi công cụ hoàn thành tác vụ, và đồng thời lưu giữ ký ức ngắn hạn và dài hạn. Đây chính là đặc trưng cốt lõi của Agentic AI. Nền tảng lưu trữ bộ nhớ ngữ cảnh suy luận, chính được thiết kế cho hình thái AI vận hành lâu dài, suy nghĩ lặp lại này, thông qua mở rộng dung lượng ngữ cảnh, tăng tốc chia sẻ xuyên node, khiến đối thoại nhiều vòng và hợp tác đa tác nhân thông minh ổn định hơn, không còn "chạy càng lâu càng chậm".

03 DGX SuperPOD thế hệ mới: Cho phép 576 GPU làm việc phối hợp
NVIDIA tại CES lần này đã công bố ra mắt DGX SuperPOD (siêu node) thế hệ mới dựa trên kiến trúc Rubin, mở rộng Rubin từ giá đỡ đơn lẻ thành giải pháp hoàn chỉnh cho toàn bộ trung tâm dữ liệu.
DGX SuperPOD là gì?
Nếu nói Rubin NVL72 là một "siêu giá đỡ" chứa 72 GPU, thì DGX SuperPOD là kết nối nhiều giá đỡ như vậy lại, hình thành một cụm tính toán AI quy mô lớn hơn. Phiên bản được công bố lần này bao gồm 8 giá đỡ Vera Rubin NVL72, tương đương với 576 GPU làm việc phối hợp.
Khi quy mô tác vụ AI tiếp tục mở rộng, 576 GPU của một giá đỡ có thể vẫn chưa đủ. Ví dụ như huấn luyện mô hình siêu lớn, đồng thời phục vụ hàng nghìn tác nhân thông minh Agentic AI, hoặc xử lý các tác vụ phức tạp cần ngữ cảnh hàng triệu token. Lúc này cần nhiều giá đỡ phối hợp làm việc, và DGX SuperPOD chính là giải pháp tiêu chuẩn hóa được thiết kế cho kịch bản này.
Đối với doanh nghiệp và nhà cung cấp dịch vụ đám mây, DGX SuperPOD cung cấp một giải pháp cơ sở hạ tầng AI quy mô lớn "dùng ngay". Không cần tự mình nghiên cứu cách kết nối hàng trăm GPU, cách cấu hình mạng, cách quản lý lưu trữ, v.v.
Năm thành phần cốt lõi của DGX SuperPOD thế hệ mới:
○ 8 giá đỡ Vera Rubin NVL72 - cung cấp năng lực tính toán cốt lõi, mỗi giá đỡ 72 GPU, tổng cộng 576 GPU;
○ Mạng mở rộng NVLink 6 - cho phép 576 GPU trong 8 giá đỡ này có thể làm việc phối hợp như một siêu GPU khổng lồ;
○ Mạng mở rộng Spectrum-X Ethernet - kết nối các SuperPOD khác nhau, cũng như kết nối với lưu trữ và mạng bên ngoài;
○ Nền tảng lưu trữ bộ nhớ ngữ cảnh suy luận - cung cấp lưu trữ dữ liệu ngữ cảnh chia sẻ cho các tác vụ suy luận dài hạn;
○ Phần mềm Mission Control của NVIDIA - quản lý điều phối, giám sát và tối ưu hóa toàn hệ thống.
Lần nâng cấp này, nền tảng của SuperPOD lấy hệ thống cấp giá đỡ DGX Vera Rubin NVL72 làm cốt lõi. Mỗi NVL72 tự thân đã là một siêu máy tính AI hoàn chỉnh, bên trong kết nối 72 GPU Rubin thông qua NVLink 6, có thể hoàn thành các tác vụ suy luận và huấn luyện quy mô lớn trong một giá đỡ. DGX SuperPOD mới, thì được tạo thành từ nhiều NVL72, hình thành một cụm cấp hệ thống có thể vận hành lâu dài.
Khi quy mô tính toán mở rộng từ "giá đỡ đơn" sang "đa giá đỡ", nút thắt cổ chai mới xuất hiện: làm thế nào để truyền tải lượng dữ liệu khổng lồ giữa các giá đỡ một cách ổn định và hiệu quả. Xoay quanh vấn đề này, NVIDIA tại CES lần này đã đồng thời công bố switch Ethernet thế hệ mới dựa trên chip Spectrum-6, và lần đầu tiên giới thiệu công nghệ "quang học đóng gói chung" (CPO).
Nhìn một cách đơn giản, là đóng gói trực tiếp các mô-đun quang vốn có thể cắm rút vào bên cạnh chip switch, rút ngắn khoảng cách truyền tín hiệu từ vài mét xuống vài milimet, từ đó giảm đáng kể công suất tiêu thụ và độ trễ, cũng nâng cao độ ổn định tổng thể của hệ thống.
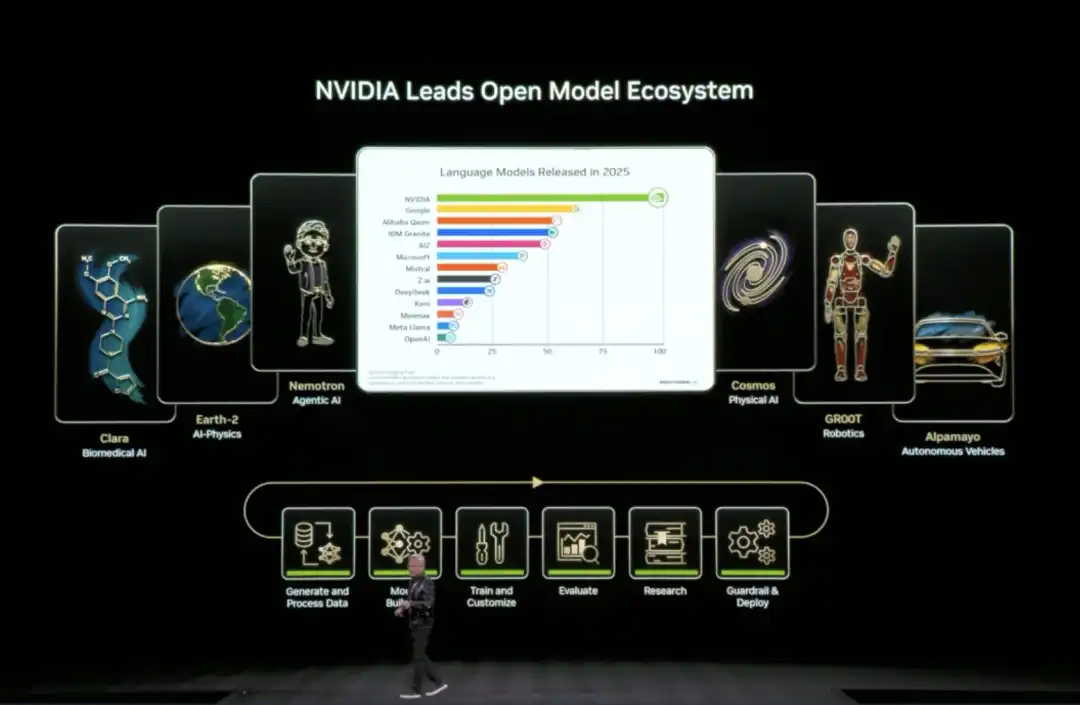
04 "Cả tá" AI mã nguồn mở của NVIDIA: Từ dữ liệu đến mã code đầy đủ
Tại CES lần này, Huang thông báo mở rộng hệ sinh thái mô hình mã nguồn mở (Open Model Universe) của mình, bổ sung và cập nhật một loạt mô hình, tập dữ liệu, kho mã code và công cụ. Hệ sinh thái này bao phủ sáu lĩnh vực: AI y sinh (Clara), mô phỏng vật lý AI (Earth-2), Agentic AI (Nemotron), AI vật lý (Cosmos), robot (GR00T) và lái xe tự động (Alpamayo).
Huấn luyện một mô hình AI không chỉ cần sức mạnh tính toán, mà còn cần tập dữ liệu chất lượng cao, mô hình tiền huấn luyện, mã code huấn luyện, công cụ đánh giá, v.v. toàn bộ cơ sở hạ tầng. Đối với hầu hết doanh nghiệp và tổ chức nghiên cứu, việc xây dựng những thứ này từ con số 0 quá tốn thời gian.
Cụ thể, NVIDIA đã mở mã nguồn sáu cấp độ nội dung: nền tảng tính toán (DGX, HGX, v.v.), tập dữ liệu huấn luyện các lĩnh vực, mô hình cơ sở tiền huấn luyện, thư viện mã code suy luận và huấn luyện, kịch bản quy trình huấn luyện hoàn chỉnh, và mẫu giải pháp end-to-end.
Dòng Nemotron là trọng tâm của lần cập nhật này, bao phủ bốn hướng ứng dụng.
Ở hướng suy luận, bao gồm các mô hình suy luận thu nhỏ như Nemotron 3 Nano, Nemotron 2 Nano VL, v.v., và các công cụ huấn luyện học tăng cường như NeMo RL, NeMo Gym. Ở hướng RAG (tạo thành tăng cường truy xuất), cung cấp Nemotron Embed VL (mô hình nhúng vector), Nemotron Rerank VL (mô hình sắp xếp lại), tập dữ liệu liên quan và NeMo Retriever Library (thư viện truy xuất). Ở hướng an toàn, có mô hình an toàn nội dung Nemotron Content Safety và tập dữ liệu đi kèm, thư viện rào chắn NeMo Guardrails.
Ở hướng giọng nói, thì bao gồm nhận dạng giọng nói tự động Nemotron ASR, tập dữ liệu giọng nói Granary Dataset và thư viện xử lý giọng nói NeMo Library. Điều này có nghĩa là doanh nghiệp muốn làm một hệ thống dịch vụ khách hàng AI có RAG, không cần tự huấn luyện mô hình nhúng và mô hình sắp xếp lại, có thể sử dụng trực tiếp mã code mà NVIDIA đã huấn luyện và mở mã nguồn.
05 Lĩnh vực AI vật lý, tiến tới triển khai thương mại
Lĩnh vực AI vật lý cũng có cập nhật mô hình - Cosmos dùng để hiểu và tạo video thế giới vật lý, mô hình cơ sở chung cho robot Isaac GR00T, mô hình hành động-ngôn ngữ-thị giác cho lái xe tự động Alpamayo.

Huang tại CES tuyên bố, "thời khắc ChatGPT" của AI vật lý sắp đến rồi, nhưng đối mặt với thách thức cũng rất nhiều: thế giới vật lý quá phức tạp và biến đổi, thu thập dữ liệu thực lại chậm và đắt, mãi mãi không đủ.
Làm thế nào bây giờ? Dữ liệu tổng hợp là một con đường. Vì thế NVIDIA đã cho ra mắt Cosmos.
Đây là một mô hình cơ sở thế giới AI vật lý mã nguồn mở, hiện đã được tiền huấn luyện với lượng lớn video, dữ liệu lái xe và robot thực tế, cũng như mô phỏng 3D. Nó có thể hiểu thế giới vận hành như thế nào, có thể liên kết ngôn ngữ, hình ảnh, 3D và hành động.
Huang cho biết, Cosmos có thể đạt được không ít kỹ năng AI vật lý, ví dụ như tạo nội dung, suy luận, dự đoán quỹ đạo (cho dù chỉ cho nó một bức ảnh). Nó có thể tạo video chân thực dựa trên cảnh 3D, tạo chuyển động phù hợp quy luật vật lý dựa trên dữ liệu lái xe, còn có thể tạo video toàn cảnh từ trình mô phỏng, hình ảnh đa camera hoặc mô tả bằng văn bản. Ngay cả các cảnh hiếm gặp, cũng có thể khôi phục lại.
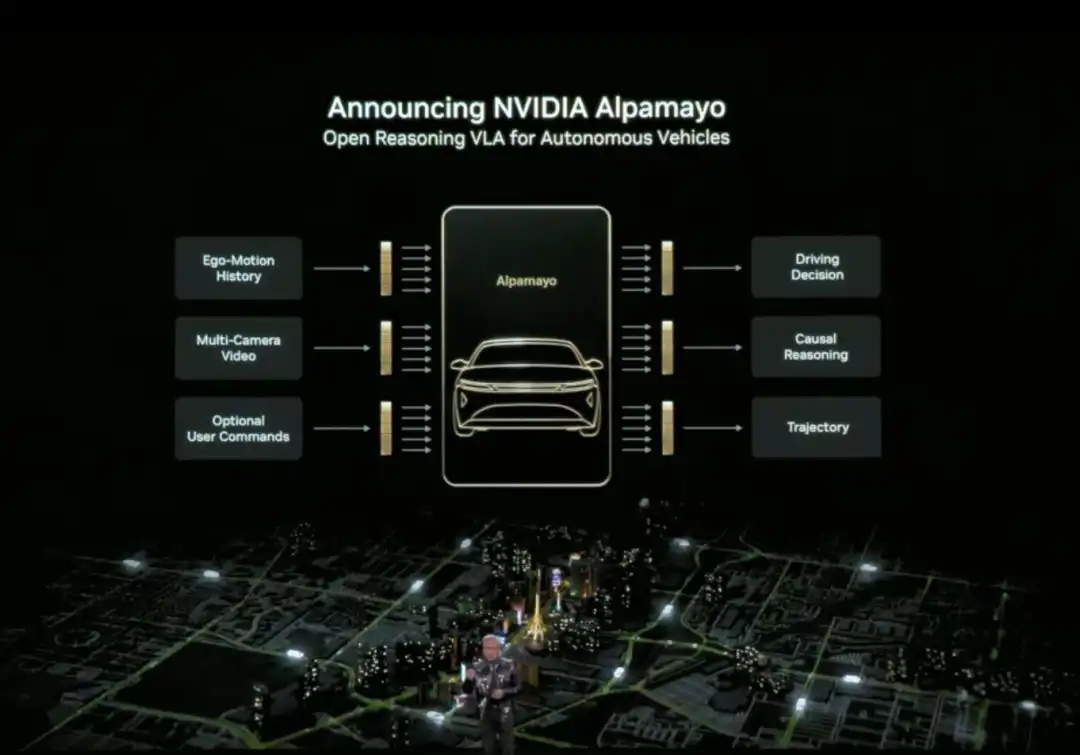
Huang còn chính thức phát hành Alpamayo. Alpamayo là một chuỗi công cụ mã nguồn mở cho lĩnh vực lái xe tự động, cũng là mô hình suy luận hành động-ngôn ngữ-thị giác (VLA) mã nguồn mở đầu tiên. Khác với trước đây chỉ mở mã nguồn code, lần này NVIDIA mở mã nguồn toàn bộ tài nguyên phát triển từ dữ liệu đến triển khai.
Đột phá lớn nhất của Alpamayo nằm ở chỗ nó là mô hình lái xe tự động "suy luận". Hệ thống lái xe tự động truyền thống là kiến trúc đường ống "cảm nhận - lập kế hoạch - điều khiển", thấy đèn đỏ thì phanh, thấy người đi bộ thì giảm tốc, tuân theo quy tắc định sẵn. Còn Alpamayo giới thiệu khả năng "suy luận", hiểu quan hệ nhân quả trong cảnh phức tạp, dự đoán ý định của các xe khác và người đi bộ, thậm chí có thể xử lý các quyết định cần suy nghĩ nhiều bước.
Ví dụ tại ngã tư, nó không chỉ nhận ra "phía trước có xe", mà còn có thể suy luận "chiếc xe kia có thể rẽ trái, vì vậy tôi nên đợi nó đi qua trước". Khả năng này nâng cấp lái xe tự động từ "chạy theo quy tắc" lên "suy nghĩ như con người".
Huang thông báo hệ thống DRIVE của NVIDIA chính thức bước vào giai đoạn sản xuất hàng loạt, ứng dụng đầu tiên là Mercedes-Benz CLA hoàn toàn mới, dự kiến lưu thông tại Mỹ vào năm 2026. Chiếc xe này sẽ được trang bị hệ thống lái xe tự động cấp L2++, sử dụng kiến trúc lai "mô hình AI end-to-end + đường ống truyền thống".
Lĩnh vực robot cũng có tiến triển thực chất.
Huang cho biết các doanh nghiệp hàng đầu toàn cầu về robot bao gồm Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics và XRlabs, đang phát triển sản phẩm dựa trên nền tảng Isaac và mô hình cơ sở GR00T của NVIDIA, bao phủ nhiều lĩnh vực từ robot công nghiệp, robot phẫu thuật đến robot hình người, robot cấp tiêu dùng.

Tại hiện trường buổi ra mắt, phía sau Huang đứng đầy các robot với hình thái và công dụng khác nhau, chúng được trưng bày tập trung trên sân khấu phân tầng: từ robot hình người, robot dịch vụ hai chân và bánh xe, đến cánh tay máy công nghiệp, máy móc kỹ thuật, máy bay không người lái và thiết bị hỗ trợ phẫu thuật, thể hiện một "bức tranh hệ sinh thái robot".
Từ ứng dụng AI vật lý đến nền tảng tính toán RubinAI, rồi đến nền tảng lưu trữ bộ nhớ ngữ cảnh suy luận và "cả tá" AI mã nguồn mở.
Những động thái mà NVIDIA thể hiện tại CES này, đã cấu thành nên tường thuật của họ về cơ sở hạ tầng AI trong thời đại suy luận. Như Huang đã nhiều lần nhấn mạnh, khi AI vật lý cần suy nghĩ liên tục, vận hành lâu dài, và thực sự bước vào thế giới thực, vấn đề không còn chỉ là sức mạnh tính toán có đủ hay không, mà là ai có thể thực sự dựng lên toàn bộ hệ thống.
Tại CES 2026, NVIDIA đã đưa ra một bản trả lời.








