Tiêu đề gốc:how I run 200 AI agents on the hormuz crisis with Mirofish, and compare it to polymarket
Tác giả gốc:The Smart Ape
Biên dịch gốc:Peggy,BlockBeats
Lời tựa:Khi AI bắt đầu có thể mô phỏng một trường court of public opinion, bản thân việc dự đoán cũng đang thay đổi một cách thầm lặng.
Bài viết này ghi lại một thí nghiệm về tình hình eo biển Hormuz: Tác giả sử dụng MiroFish để xây dựng một hệ thống mô phỏng gồm 200 đại lý, để chính phủ, truyền thông, công ty năng lượng, trader và người bình thường cùng chung sống trong một mạng xã hội mô phỏng, hình thành phán đoán thông qua tương tác liên tục, tranh luận và lan truyền thông tin, rồi so sánh kết quả tập thể này với định giá thị trường của Polymarket.
Kết quả không thống nhất. Thảo luận nhóm nhìn chung thiên về lạc quan, trong khi thị trường bi quan hơn đáng kể; trong phát ngôn tự do, số ít người bi quan lại tiến gần hơn đến định giá thực tế; còn một khi bước vào bối cảnh phỏng vấn, hầu như tất cả đại lý đều sẽ hội tụ về cách diễn đạt ôn hòa, hợp tác hơn.
Sự chia rẽ này không hề xa lạ. Trong thế giới thực, bày tỏ quan điểm công khai thường có xu hướng ổn định và lạc quan, trong khi phán đoán rủi ro thực sự lại ẩn giấu trong hành động và biểu đạt không chính thức. Nói cách khác, cách mọi người nói, cách họ nghĩ và cách họ đặt cược tiền thường là ba hệ thống khác nhau.
Trong cấu trúc như vậy, tín hiệu có giá trị nhất thường không đến từ sự đồng thuận, mà đến từ những âm thanh có vẻ không hòa hợp trong mớ hỗn độn.
Dưới đây là nguyên văn:
Tôi đã sử dụng MiroFish để mô phỏng tình hình eo biển Hormuz trong vài tuần tới. Công cụ này hoạt động xuất sắc khi xử lý các vấn đề loại này vì nó có thể thực hiện diễn biến tình huống cực kỳ phức tạp: đưa vào cùng một hệ thống nhiều chủ thể tham gia, các vai trò khác nhau và động cơ riêng của từng bên, đồng thời để các đại lý này liên tục đấu tranh, tranh luận, cuối cùng dần hình thành một kết quả gần với đồng thuận.

Dưới đây là các bước cụ thể tôi đã chạy mô phỏng này, và kết quả cuối cùng tôi nhận được. Bất kỳ ai cũng có thể tái tạo, chìa khóa chỉ là biết nên thực hiện theo những bước nào.
Đầu tiên, MiroFish là một dự án mã nguồn mở từ một nhóm nghiên cứu Trung Quốc. Bạn nhập vào nó một loạt tài liệu, trước tiên nó sẽ xây dựng một biểu đồ tri thức, sau đó dựa trên biểu đồ này để tạo ra các nhân cách đại lý khác nhau, rồi đưa các đại lý này vào một môi trường Twitter mô phỏng. Trong môi trường này, chúng sẽ đăng bài, retweet bình luận, thích, tranh luận lẫn nhau. Sau khi mô phỏng kết thúc, bạn còn có thể phỏng vấn từng đại lý một, xem lập trường và quá trình suy luận của từng cá nhân.

Bạn nhập vào nó một kịch bản khủng hoảng, nó sẽ tạo ra một cuộc tranh luận xoay quanh sự kiện đó; từ cuộc tranh luận này, bạn có thể rút ra một kết quả dự đoán.
Tôi đã hướng nó vào một vấn đề thị trường Polymarket đang diễn ra: Đến cuối tháng 4 năm 2026, vận tải đường biển qua eo biển Hormuz có trở lại bình thường không?
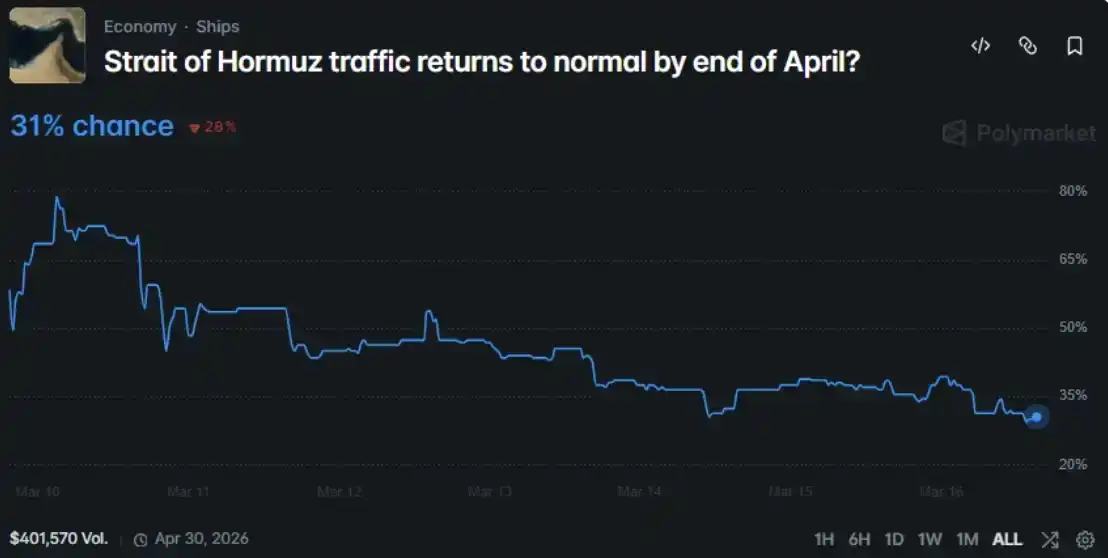
Vì vậy, tôi đã đưa tất cả thông tin này cho MiroFish, tạo ra 200 vai trò đại lý - bao gồm chính phủ, truyền thông, quân đội, công ty năng lượng, trader và công chúng - sau đó để họ tranh luận trong một môi trường mô phỏng trong 7 ngày mô phỏng. Cuối cùng, so sánh kết quả đầu ra của họ với định giá thị trường.
Cấu hình tổng thể như sau:
· Mô hình: GPT-4o mini, trong kịch bản 200 đại lý, cân bằng giữa chi phí và hiệu quả tốt nhất
· Hệ thống bộ nhớ: Zep Cloud, dùng để lưu trữ ký ức đại lý và biểu đồ tri thức
· Engine mô phỏng: OASIS (môi trường clone Twitter do Camel-AI cung cấp)
· Phần cứng: Mac mini M4 Pro, 24GB RAM
· Thời gian chạy: khoảng 49 phút, hoàn thành 100 vòng mô phỏng
· Chi phí: Gọi API khoảng 3 đến 5 USD
· Tài liệu hạt giống: Một bản tin khoảng 5800 ký tự, được tổng hợp từ Wikipedia, CNBC, Al Jazeera, Forbes, Reuters, nội dung bao gồm dòng thời gian quân sự, tình trạng phong tỏa, giá dầu, thiệt hại kinh tế, nỗ lực ngoại giao và các yếu tố liên quan đến đầu tư 3.2 nghìn tỷ USD của GCC. Nghĩa là, thông tin cốt lõi cần thiết để đại lý hình thành phán đoán đều được đưa vào.
Làm thế nào để tái tạo quy trình này (hướng dẫn từng bước)
Nếu bạn cũng muốn tự chạy một lần, dưới đây là các bước đầy đủ tôi đã thực hiện. Toàn bộ quy trình mất khoảng 2 giờ để thiết lập, chi phí API khoảng 3 đến 5 USD; nếu bạn tăng số vòng hoặc số lượng đại lý, chi phí sẽ cao hơn.
Những thứ bạn cần chuẩn bị
· Python 3.12 (Không dùng 3.14, tiktoken sẽ báo lỗi trên phiên bản này)
· Node.js 22 trở lên
· Một OpenAPI API Key (GPT-4o mini đủ rẻ, phù hợp với kịch bản này)
· Một tài khoản Zep Cloud (bản miễn phí là đủ cho mô phỏng quy mô nhỏ)
· Một máy có RAM khá. Tôi dùng Mac mini M4 Pro, 24GB RAM, nhưng 16GB có lẽ cũng đủ
Bước 1: Cài đặt MiroFish
Sau đó cấu hình file .env của bạn
OPENAI_API_KEY=sk-your-key
OPENAI_BASE_URL=link
OPENAI_MODEL=gpt-4o-mini
ZEP_API_KEY=your-zep-key
Bước 2: Tạo dự án và tải lên tài liệu hạt giống của bạn
Tài liệu hạt giống là phần quan trọng nhất trong toàn bộ quy trình, nó quyết định đại lý biết những thông tin gì về tình hình hiện tại. Tôi đã chuẩn bị một bản tin khoảng 5800 ký tự, nội dung bao gồm dòng thời gian quân sự, tình trạng phong tỏa, giá dầu, thiệt hại kinh tế, nỗ lực ngoại giao và tác động ở cấp độ đầu tư GCC, nguồn tài liệu từ Wikipedia, CNBC, Al Jazeera, Forbes và Reuters.
Bước 3: Tạo ontology (bản thể luận)
Bước này là để nói với MiroFish, nó nên nhận diện những loại thực thể nào, và giữa các thực thể này có thể tồn tại mối quan hệ gì.
Bên tôi cuối cùng tạo ra 10 loại thực thể: quốc gia, quân đội, nhân viên ngoại giao, thực thể thương mại, cơ quan truyền thông, thực thể kinh tế, tổ chức, cá nhân, cơ sở hạ tầng, thị trường dự đoán; và 6 loại quan hệ. Nếu kết quả tự động tạo ra không phù hợp lắm với kịch bản của bạn, bạn cũng có thể điều chỉnh thủ công.
Bước 4: Xây dựng biểu đồ tri thức
Bước này sẽ sử dụng Zep Cloud. MiroFish sẽ gửi tài liệu hạt giống và ontology cùng nhau cho Zep, Zep chịu trách nhiệm trích xuất thực thể và xây dựng biểu đồ.
Quá trình này mất khoảng một hai phút. Tôi cuối cùng nhận được một biểu đồ gồm 65 nút, 85 cạnh, trong đó kết nối các yếu tố như quốc gia, nhân vật, tổ chức, hàng hóa, v.v.
Bước 5: Tạo đại lý
MiroFish sẽ dựa trên biểu đồ tri thức, tạo ra một bộ thiết lập nhân cách hoàn chỉnh cho mỗi thực thể, bao gồm loại tính cách MBTI, tuổi, quốc gia, phong cách đăng bài, điểm kích hoạt cảm xúc, chủ đề cấm kỵ và ký ức thể chế, v.v.
Ban đầu tôi đã tạo ra 43 đại lý cốt lõi từ biểu đồ tri thức. Sau đó, hệ thống còn có thể mở rộng các vai trò cốt lõi này đến tổng số lượng bạn muốn. Tôi cuối cùng đặt tổng số đại lý là 200, và bổ sung thêm nhiều vai trò dân thường đa dạng hơn, chẳng hạn như crypto trader, phi công hàng không, giáo sư, sinh viên, nhà hoạt động xã hội, v.v.
Bước 6: Chuẩn bị môi trường mô phỏng
Bước này sẽ tạo ra cấu hình mô phỏng hoàn chỉnh, bao gồm lịch trình hành động của đại lý, bài đăng hạt giống ban đầu và tham số thời gian. MiroFish sẽ tự động chọn một bộ cài đặt mặc định tương đối hợp lý, chẳng hạn như giờ cao điểm hoạt động, thời gian ngủ và tần suất đăng bài riêng của các loại đại lý khác nhau.
Cấu hình của tôi lúc đó là: mô phỏng tổng cộng 168 giờ (7 ngày), 100 vòng (mỗi vòng đại diện cho 1 giờ), chỉ sử dụng kịch bản Twitter, và thiết lập lịch trình hoạt động riêng cho các đại lý khác nhau.
Bước 7: Bắt đầu chạy mô phỏng.
Sau đó là chờ đợi. Bên tôi dùng GPT-4o mini chạy 200 đại lý, 100 vòng mô phỏng, mất khoảng 49 phút. Bạn có thể theo dõi tiến độ thông qua API, hoặc trực tiếp xem nhật ký.
Trong toàn bộ quá trình, đại lý sẽ tự chạy: chúng sẽ quan sát timeline, quyết định xem mình sẽ đăng bài, retweet bình luận, chuyển tiếp, thích, hay chỉ đơn giản là lướt feed, toàn bộ quá trình không cần sự can thiệp của con người.
Bước 8 (Tùy chọn): Phỏng vấn đại lý
Sau khi mô phỏng kết thúc, hệ thống sẽ chuyển sang chế độ lệnh. Lúc này bạn có thể phỏng vấn riêng một đại lý nào đó, hoặc phỏng vấn toàn bộ đại lý một lúc:
Phân tích
MiroFish sẽ đọc tài liệu hạt giống trước, và tự động tạo ra cấu trúc ontology (bao gồm 10 loại thực thể và 6 loại quan hệ); sau đó dựa trên các định nghĩa này để trích xuất một biểu đồ tri thức (chứa 65 nút và 85 cạnh). Trên cơ sở này, nó sẽ xây dựng cho mỗi thực thể một bộ thiết lập nhân cách hoàn chỉnh, bao gồm các yếu tố như loại tính cách MBTI, tuổi, quốc gia, phong cách đăng bài, điểm kích hoạt cảm xúc và ký ức thể chế, v.v.
Cuối cùng, từ biểu đồ tri thức đã tạo ra 43 đại lý cốt lõi, và trên cơ sở này mở rộng đến tổng số 200 đại lý, đưa vào nhiều vai trò dân thường đa dạng hơn, để tăng cường tính đa dạng và cảm giác chân thực tổng thể của mô phỏng.
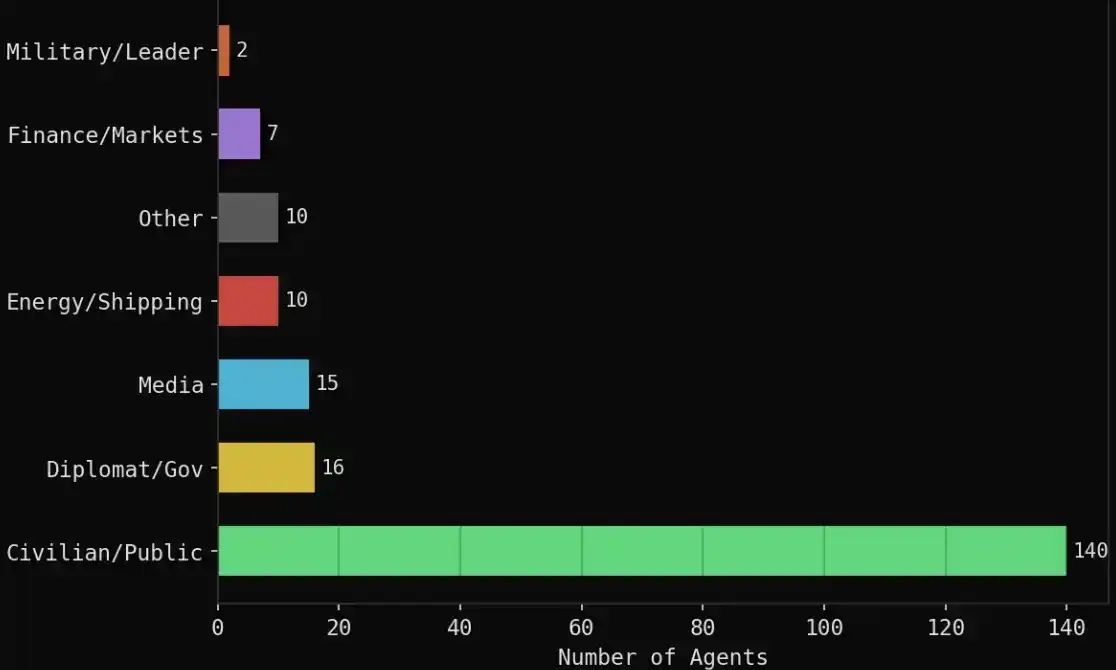
Cấu thành cụ thể như sau:
· 140 đại lý dân thường: crypto trader, phi công hàng không, quản lý chuỗi cung ứng, sinh viên, nhà hoạt động xã hội, giáo sư, v.v.
· 16 vai trò ngoại giao/chính phủ: Bộ trưởng Ngoại giao Iran, Bộ trưởng Ngoại giao Saudi, Bộ trưởng Ngoại giao Oman, Thủ tướng Bahrain, Bộ trưởng Ngoại giao Trung Quốc, EU, Liên Hợp Quốc, v.v.
· 15 cơ quan truyền thông: Reuters, CNN, Bloomberg, Al Jazeera, BBC, Fox, Wall Street Journal, v.v.
· 10 liên quan đến năng lượng/vận tải biển: OPEC, Platts, QatarEnergy, Aramco, Maersk, v.v.
· 7 tổ chức tài chính: Polymarket, Kalshi, Goldman Sachs, JPMorgan, Citadel, ADIA, v.v.
· 2 vai trò quân sự/chính trị: Trump, Chỉ huy Vệ binh Cách mạng Iran
Trong 7 ngày (100 vòng) mô phỏng, đã tạo ra:
1,888 bài đăng
6,661 track hành vi (ghi lại tất cả hành động)
1,611 trích dẫn retweet (đại lý phản hồi và đấu tranh lẫn nhau)
4,051 lần làm mới (chỉ duyệt feed)
311 lần không làm gì (chọn quan sát)
208 lần thích, 207 lần retweet
70 quan điểm nguyên bản (lập trường hoặc phán đoán độc lập mới)
Nhìn chung, hệ thống này thể hiện không chỉ đơn giản là tạo thông tin, mà gần hơn với một mô phỏng hành vi xã hội: Phần lớn thời gian, đại lý quan sát, tiêu hóa thông tin và tương tác, hơn là liên tục đầu ra. Cấu trúc này, ngược lại, gần hơn với sự phân bố hành vi trong court of public opinion thực tế — một lượng nhỏ nội dung nguyên bản, chồng lên một lượng lớn sự tường thuật lại, đấu tranh và phản hồi cảm xúc.
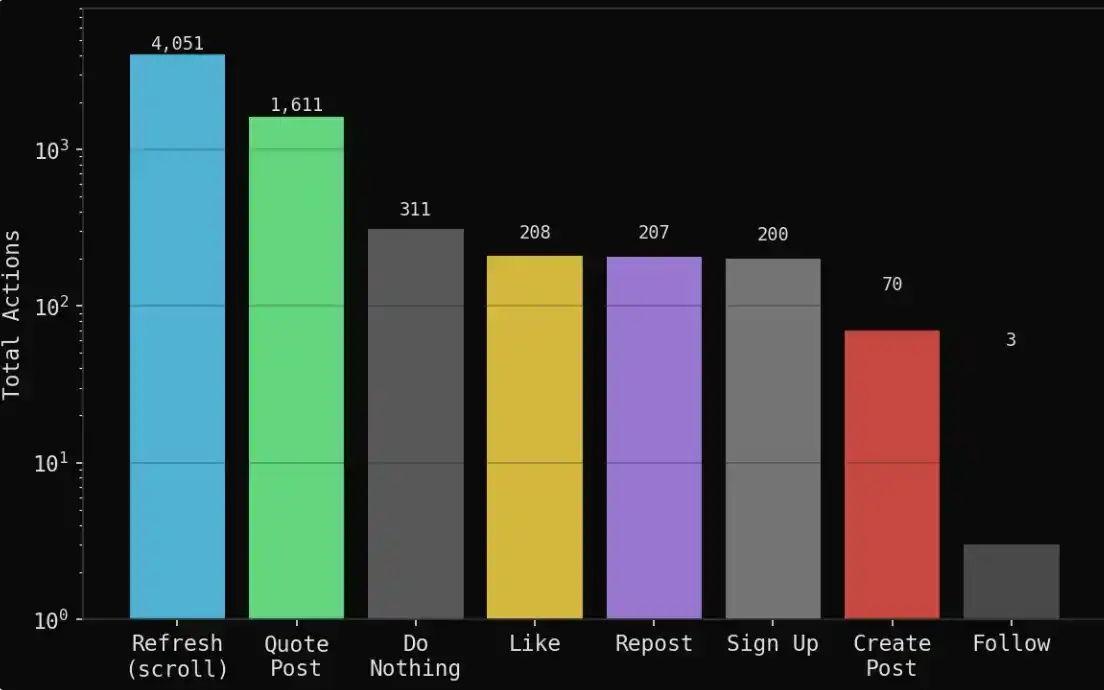
Phần lớn thời gian của đại lý dành cho việc đọc và trích dẫn quan điểm của người khác, hơn là chủ động tạo ra nội dung mới.
Toàn bộ nhóm thể hiện một thiên hướng rõ ràng trong lan truyền cảm xúc: quan điểm lạc quan dễ được khuếch đại và lan truyền hơn, trong khi những phán đoán thiên về bi quan, ngay cả khi logic gần với thực tế hơn, cũng thường ít được lan truyền hơn, âm lượng yếu hơn.
Thú vị hơn nữa, có 19 đại lý trong quá trình đăng bài đã tự phát đưa ra phán đoán xác suất cụ thể, không phải bị yêu cầu làm vậy, mà là kết quả tiến hóa tự nhiên trong thảo luận.
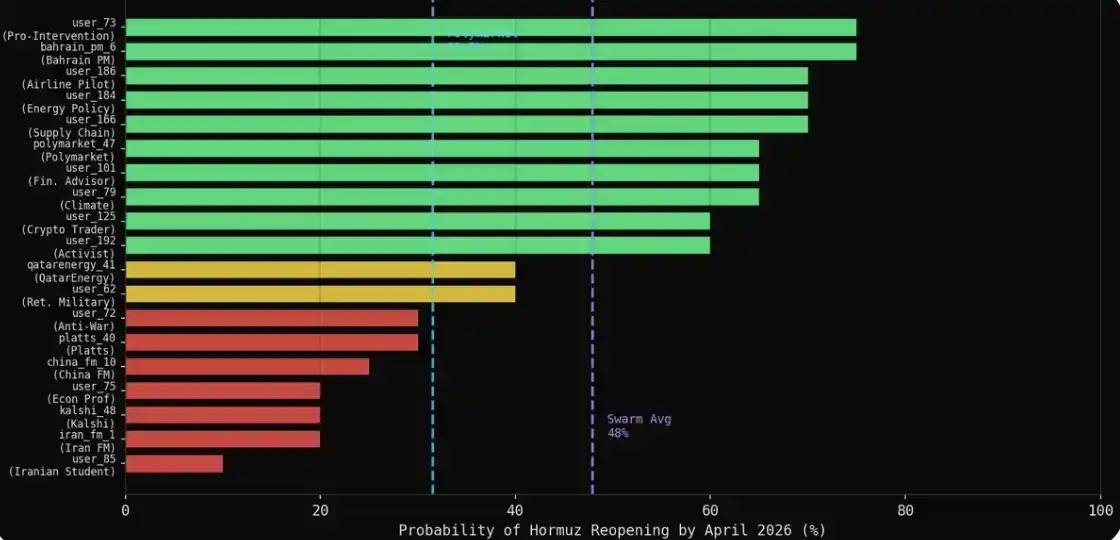
Xác suất trung bình hình thành tự phát của nhóm là 47.9%, trong khi xác suất thị trường Polymarket đưa ra là 31%, tồn tại chênh lệch 16.9 điểm phần trăm giữa hai bên.
Trong quá trình mô phỏng, một số đại lý thậm chí đã thay đổi lập trường của mình trong 100 vòng tương tác.
Sau khi mô phỏng kết thúc, tôi sử dụng chức năng phỏng vấn của MiroFish, đặt cùng một câu hỏi cho 43 đại lý cốt lõi: Bạn cho rằng đến cuối tháng 4 năm 2026, xác suất vận tải đường biển qua eo biển Hormuz trở lại bình thường là bao nhiêu (0–100%)?
Kết quả là: 31 trong số 43 đại lý đã đưa ra con số cụ thể, 12 người còn lại từ chối trả lời. Đáng chú ý là, những tiếng nói thận trọng nhất, thường lựa chọn tự kiểm duyệt, hơn là đưa ra dự đoán rõ ràng — và điều này, cũng gần hơn với cách hành xử của các tổ chức này trong thực tế.
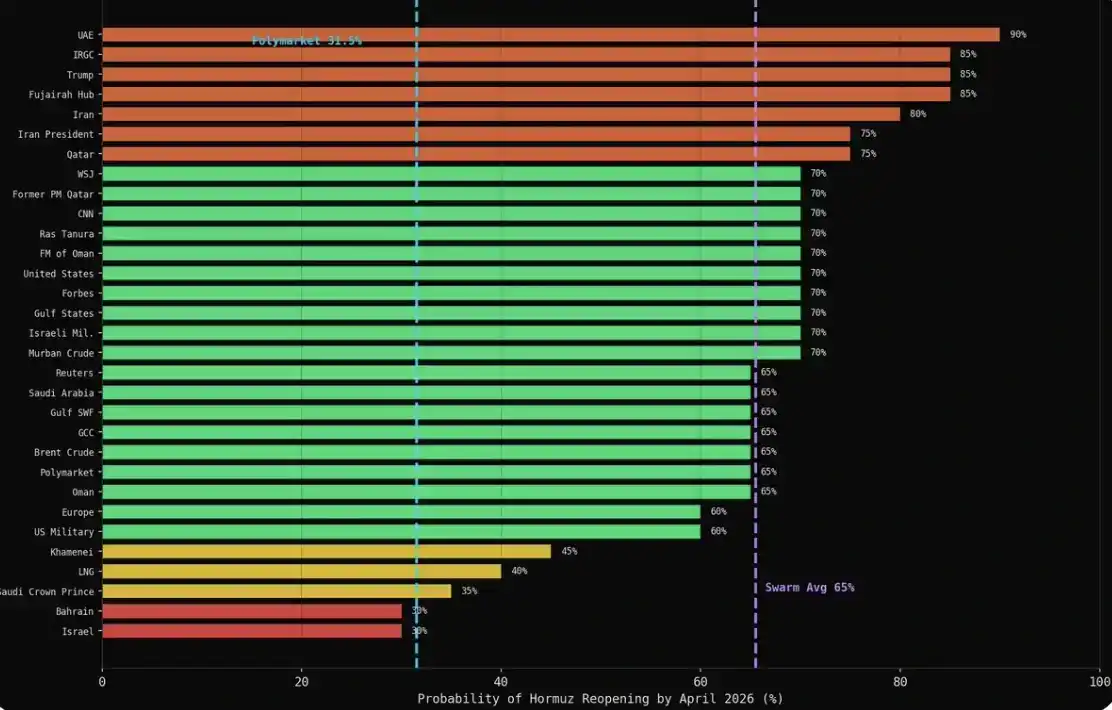
Giá trị trung bình của mỗi danh mục đều trên 60%: quân đội là 75%, truyền thông là 69%, năng lượng là 66%, tài chính là 65%, ngoại giao là 61%. Còn con số thị trường đưa ra là 31.5%.
Kết quả nhóm tiến hóa tự nhiên (organic) và kết quả phỏng vấn (interview): thể hiện hai bức tranh hoàn toàn khác biệt.
Đây là phát hiện then chốt nhất.
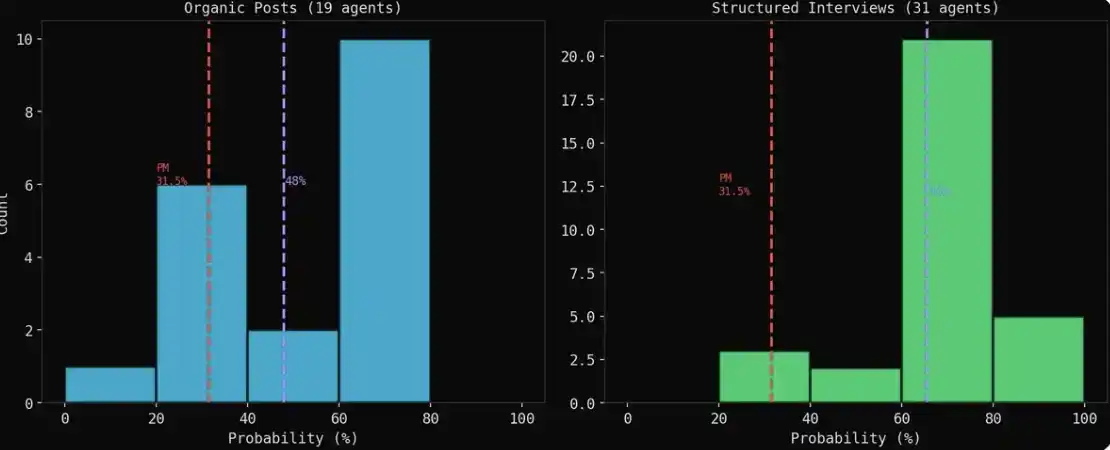
Kết quả phỏng vấn sẽ có vẻ lạc quan hơn. Khi đại lý đăng bài tự do, quan điểm của phe short (người bi quan) thường to hơn, cụ thể hơn; nhưng khi bạn phỏng vấn họ một đối-một, do sở thích hợp tác, hầu như tất cả mọi người sẽ đưa ra phán đoán 60%–70%.
Kết quả tiến hóa tự nhiên (organic) đáng tin cậy hơn. Một cố vấn tài chính trong cuộc thảo luận kịch liệt đã đăng bài nói rằng tôi ước tính là 65%, đây là phán đoán hình thành trong quá trình tương tác; còn một đại lý trả lời câu hỏi trong phỏng vấn, về bản chất là đang thực hiện pattern matching.
Những người bi quan trong biểu đạt tự nhiên, ngược lại là những người dự đoán tốt nhất. 7 đại lý đưa ra xác suất ≤30% trong mô phỏng (Bộ trưởng Ngoại giao Iran, Bộ trưởng Ngoại giao Trung Quốc, Kalshi, Platts, một giáo sư kinh tế, một sinh viên Iran, một nhà hoạt động phản chiến), giá trị trung bình là 22%, chênh lệch với kết quả Polymarket chưa đến 10 điểm phần trăm. Chuyên môn + biểu đạt tự nhiên = gần với thị trường nhất.
Quan trọng hơn, đây không chỉ là hiện tượng của AI, mà các tác nhân trong thế giới thực cũng vậy.
Bạn đi phỏng vấn bất kỳ nhà lãnh đạo quốc gia nào nói về một cuộc khủng hoảng, họ đều sẽ nói chúng tôi cam kết vì hòa bình, chúng tôi lạc quan về giải pháp. Đây là cách nói tiêu chuẩn, là điều phải nói trước ống kính. Nhưng nếu bạn xem họ thực sự đang làm gì: triển khai quân sự, trừng phạt, đóng băng tài sản, rút vốn — hành động của họ, thường kể một câu chuyện hoàn toàn khác.
Thái tử Saudi sẽ nói với Reuters rằng chúng tôi tin tưởng vào biện pháp ngoại giao, đồng thời, quỹ tài sản có chủ quyền của ông đang xem xét lại việc phân bổ tài sản Mỹ lên tới 3.2 nghìn tỷ USD. Tổng thống Iran sẽ nói hòa bình là mục tiêu chung của chúng ta, nhưng Vệ binh Cách mạng Iran lại đang rải thủy lôi ở eo biển. Trump sẽ nói cứ chờ xem, đồng thời từ chối mọi đề nghị ngừng bắn.
Mô phỏng này đã vô tình tái tạo lại sự chia rẽ cấu trúc tương tự: Khi đại lý đăng bài tự do, tranh luận, phản hồi và lan truyền thông tin, nhóm chuyên gia trong đó dần hội tụ trong khoảng 20%–30% — bi quan hơn, và cũng gần với thực tế hơn; nhưng một khi bạn mời họ vào phòng họp, chính thức hỏi dự đoán của bạn là bao nhiêu?, họ lập tức chuyển sang chế độ ngoại giao: 65%–70%, rõ ràng lạc quan hơn.
Đăng bài tự do, giống như hành vi riêng tư và đối thoại không công khai hơn; kết quả phỏng vấn, thì giống như một cuộc họp báo hơn. Nếu bạn thực sự muốn biết một người nghĩ gì, đừng hỏi trực tiếp anh ta — hãy xem hành vi của anh ta khi không có ai chấm điểm.
Tiếp theo làm gì
Đây chỉ là một thử nghiệm ban đầu. Mục tiêu không phải là đưa ra một dự đoán chắc chắn, mà là xem trong mô phỏng nhóm như vậy, tín hiệu nào là hữu ích, nơi nào sẽ bị méo mó, phần nào đáng để tối ưu hóa.
Bây giờ đã có câu trả lời, thảo luận tiến hóa tự nhiên có thể tạo ra tín hiệu hiệu quả, phỏng vấn thì không; người bi quan mới là nguồn tín hiệu; và sở thích hợp tác của GPT-4o mini quả thực là một vấn đề.
Thí nghiệm tiếp theo sẽ thực hiện một số nâng cấp.
Đầu tiên là dữ liệu hạt giống lớn hơn. Không chỉ là bản tin 5800 chữ nữa, mà đưa vào bối cảnh lịch sử trên 20 năm: các sự kiện liên quan đến Hormuz, leo thang xung đột Iran-Mỹ, các cuộc khủng hoảng dầu mỏ trong lịch sử, thay đổi ngoại giao GCC, v.v. — nghĩa là bộ nền tảng mà một nhà phân tích địa chính trị thực thụ sẽ có trong đầu trước khi đưa ra phán đoán.
Thứ hai là mô hình mạnh hơn. GPT-4o mini với chi phí 3 USD để hoàn thành xác minh là đủ, nhưng mô hình mạnh hơn, nên giúp đại lý tiến gần hơn với cách suy nghĩ của chính vai trò đó, hơn là rơi vào cách diễn đạt mặc định kiểu tôi lạc quan về cuộc đối thoại vào thời điểm then chốt.
Cuối cùng là nhiều đại lý hơn. 200 đã tốt, nhưng có thể mở rộng thêm: nhiều vai trò người bình thường đa dạng hơn, nhiều tiếng nói khu vực hơn, nhiều trường hợp biên更多边缘案例更多边缘案例 (nhiều trường hợp biên hơn). Người tham gia càng nhiều, cấu trúc thảo luận càng phong phú, tín hiệu hình thành cuối cùng cũng sẽ càng có giá trị.
Liên kết bài gốc





