Lĩnh vực tạo ảnh từ văn bản từ lâu đã trở thành một thị trường cạnh tranh khốc liệt, dường như không còn gì để "cuộn" thêm.
Vậy muốn huấn luyện một mô hình tạo ảnh từ văn bản ấn tượng hiện nay, bạn cần gì?
Nếu tiếp cận từ các giải pháp chủ đạo hiện tại, cần có: Bộ mã hóa-giải mã VAE được đào tạo trước, ghép nối bộ mã hóa văn bản, cơ chế tiêm điều kiện được thiết kế tinh tế, lượng dữ liệu khổng lồ, giai đoạn căn chỉnh RL hoặc DPO...
Nhìn chung, mọi người dường như mặc định một tiền đề: việc tạo ảnh từ văn bản vốn dĩ phức tạp như vậy.
Tuy nhiên, nhóm nghiên cứu của Hà Khải Minh lại đi ngược lại hướng đó, đưa ra những suy nghĩ mới trong lĩnh vực mô hình tạo ảnh từ văn bản. Họ đã công bố MiniT2I - một mô hình tạo ảnh từ văn bản trong không gian pixel được chủ ý theo đuổi sự cực kỳ đơn giản.
Không có bộ mã hóa-giải mã VAE, không có cơ chế tiêm điều kiện AdaLN, không có hàm mất mát phụ trợ, không có dữ liệu riêng tư, không có giai đoạn căn chỉnh RL/DPO, chỉ có mục tiêu kết hợp dòng thuần túy được huấn luyện trực tiếp trên pixel. Phiên bản B/16 với 258M tham số, đạt 0.87 trên GenEval, 84.2 trên DPG-Bench, vượt trội hơn các mô hình không gian pixel cùng loại có số tham số lớn hơn nó vài lần.

Luận điểm cốt lõi của MiniT2I là: Nếu xem điều kiện văn bản như "các token ngữ cảnh mang thông tin ngữ nghĩa" để tiêm vào mô hình, về bản chất, việc tạo ảnh từ văn bản và việc tạo ảnh có điều kiện loại trên ImageNet không khác biệt nhiều đến vậy - kiến trúc có thể tương tự, khả năng tính toán có thể tương đương, thậm chí quy mô dữ liệu cũng có thể tương thích.

- Tiêu đề bài báo: A Minimalist Baseline for Text-to-Image Generation
- Blog kỹ thuật: https://peppaking8.github.io/#/post/minit2i
- Địa chỉ mã nguồn mở: https://github.com/PeppaKing8/minit2i-jax
Lộ trình kỹ thuật: Mỗi bước đều giảm thiểu
Xuất trực tiếp không gian pixel, không cần VAE
Lựa chọn thiết kế đầu tiên của MiniT2I khá triệt để: Loại bỏ VAE, trực tiếp khử nhiễu trên pixel RGB.
Mô hình khuếch tán tiềm ẩn (Latent Diffusion) là mô hình chủ đạo hiện nay, trước tiên sử dụng bộ tự mã hóa để nén hình ảnh vào không gian chiều thấp rồi mới thực hiện khuếch tán. Điều này thực sự làm cho độ phân giải cao trở nên khả thi, nhưng cái giá phải trả là giới thiệu sai số tái tạo, giai đoạn huấn luyện bổ sung, và vấn đề mục tiêu không đồng bộ giữa bộ mã hóa và bộ khử nhiễu.
Lý do MiniT2I chọn không gian pixel rất thiết thực: Với độ phân giải 512×512, sử dụng patch 16×16 để cắt hình ảnh thành 1024 token, độ dài chuỗi hoàn toàn nằm trong phạm vi thoải mái của Transformer. Sau khi loại bỏ VAE, tính toán một lượt truyền thẳng giảm từ ~1379 GFLOPs xuống ~570 GFLOPs (thiết lập B/16), và không tồn tại vấn đề giới hạn trên về độ chính xác tái tạo - khả năng của bộ khử nhiễu mạnh đến đâu, đầu ra có thể tốt đến đó.
Thực nghiệm cũng xác nhận điều này: Với cùng ngân sách tham số, FID của mô hình pixel ngang bằng với mô hình không gian tiềm ẩn (18.7 so với 19.0), nhưng chi phí cho một bước thấp hơn 5 lần.

Kiến trúc MM-JiT: Quay lại với Transformer thuần khiết
MM-DiT của SD3 sử dụng AdaLN (Chuẩn hóa lớp thích ứng) trong mỗi block để tiêm bước thời gian và bộ mã hóa văn bản tổng hợp vào mạng - mỗi khối con cần tính toán tham số scale, shift và gate, được tạo ra thông qua một MLP bổ sung từ vector điều kiện. Đây là một cơ chế điều chế tinh tế, nhưng MiniT2I phát hiện nó không phải là bắt buộc.
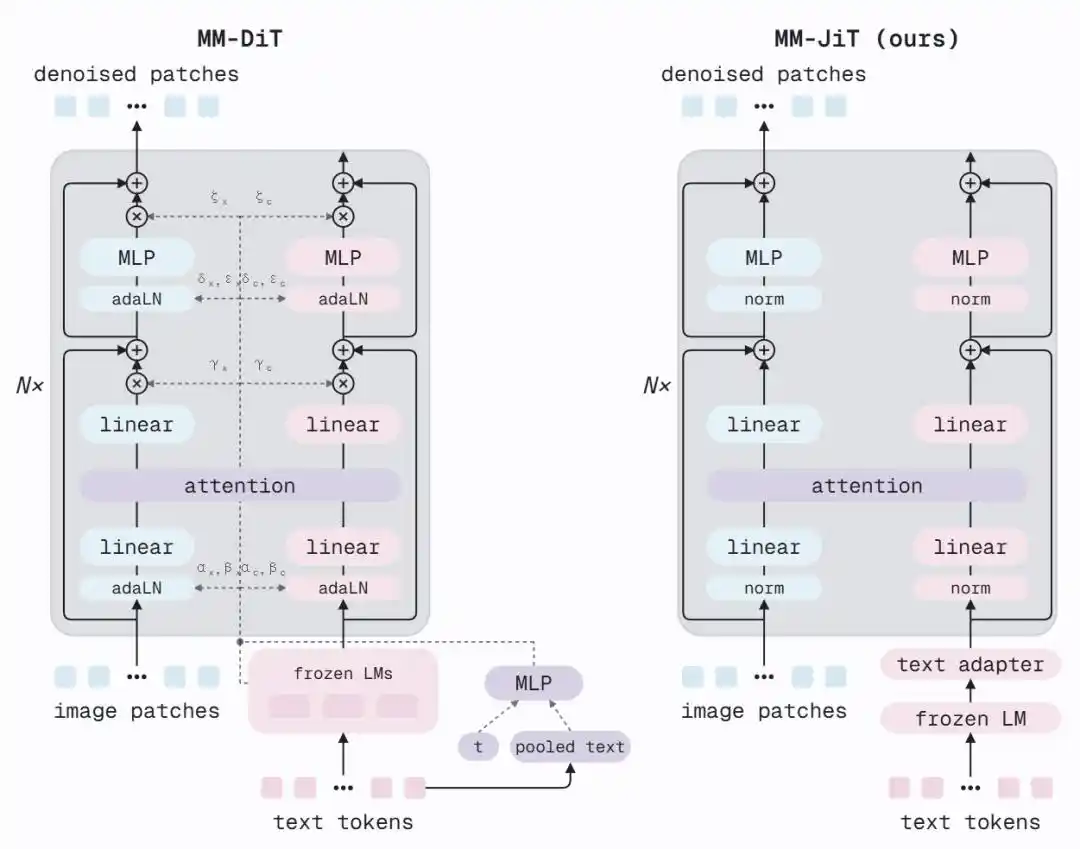
Kiến trúc MM-JiT được đề xuất bởi MiniT2I làm hai việc:
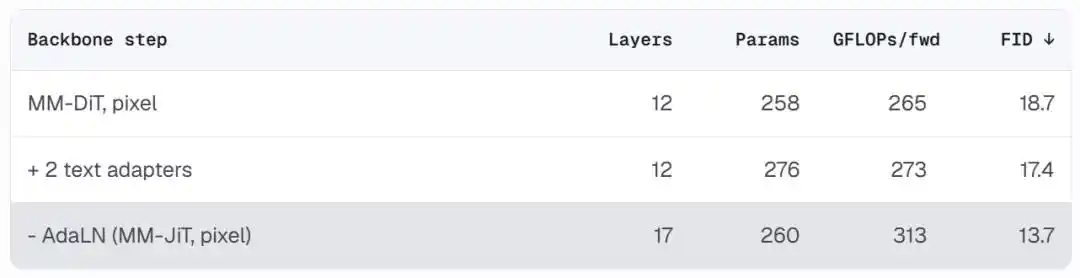
1. Thêm hai bộ điều hợp văn bản: Trước khi thực hiện chú ý kết hợp, chèn hai khối Transformer nhẹ, để đặc trưng T5 đã đóng băng trước đó "thích ứng" với nhu cầu của bộ khử nhiễu.
2. Xóa nhánh AdaLN: Không còn tiêm thông tin bước thời gian và văn bản toàn cục thông qua đường dẫn bổ sung. Mô hình vẫn có thể cảm nhận được mức độ nhiễu - vì hình ảnh bị nhiễm bẩn bởi nhiễu tự nó đã mang thông tin bước thời gian.
Kết quả là một kiến trúc sạch sẽ, gần với Transformer chuẩn tắc hóa trước. Sau khi loại bỏ AdaLN, tham số giảm, nhưng có thể đổi lấy nhiều tầng hơn (12 tầng → 17 tầng) với cùng ngân sách tính toán. FID giảm từ 18.7 xuống 13.7, đồng thời bản thân kiến trúc trở nên dễ hiểu và sửa đổi hơn.
Dữ liệu huấn luyện: Hoàn toàn công khai, hai giai đoạn
Dữ liệu huấn luyện của MiniT2I cũng theo đuổi sự cực kỳ đơn giản:
- Đào tạo trước: LLaVA-recaptioned CC12M (tập dữ liệu được gán lại nhãn bởi VLM, công khai sử dụng), 250K bước
- Tinh chỉnh: ~12 vạn cặp hình ảnh-văn bản chất lượng cao (BLIP3o-60K + LAION DALL・E 3 Discord set + ShareGPT-4o-Image), 40K bước
Mô hình "đào tạo trước - tinh chỉnh" hai giai đoạn này hoàn toàn tương ứng với mô hình huấn luyện LLM: đào tạo trước mua phạm vi bao phủ, tinh chỉnh dạy mô hình thế nào là câu trả lời tốt. Phân tích loại bỏ cho thấy cả hai đều không thể thiếu - chỉ đào tạo trước, chất lượng hình ảnh có thể nhưng khả năng tuân theo gợi ý kém; chỉ tinh chỉnh, thế giới mà mô hình nhìn thấy quá hẹp, tính đa dạng của việc tạo ra bị sụp đổ.
Kết quả: Mô hình nhỏ, hiệu suất lớn
Trong so sánh về tạo ảnh từ văn bản trong không gian pixel, MiniT2I có hiệu suất chi phí cực kỳ nổi bật:
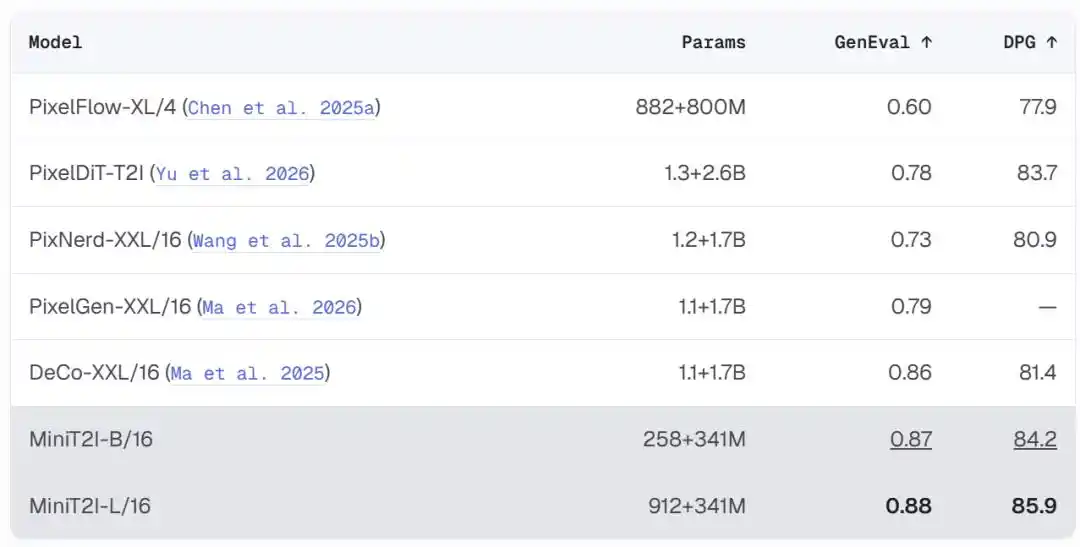
MiniT2I-B/16 chỉ sử dụng khoảng 600M tổng tham số (bao gồm bộ mã hóa văn bản), đã vượt trội hơn các mô hình có số tham số lớn hơn 3-4 lần mình trên GenEval và DPG-Bench. Hơn nữa, chi phí huấn luyện cực thấp: Mô hình loại bỏ B/32 chỉ cần khoảng 3 ngày trên 8 H100, tổng FLOPs huấn luyện tương đương với thực nghiệm ImageNet 200 epoch tiêu chuẩn.
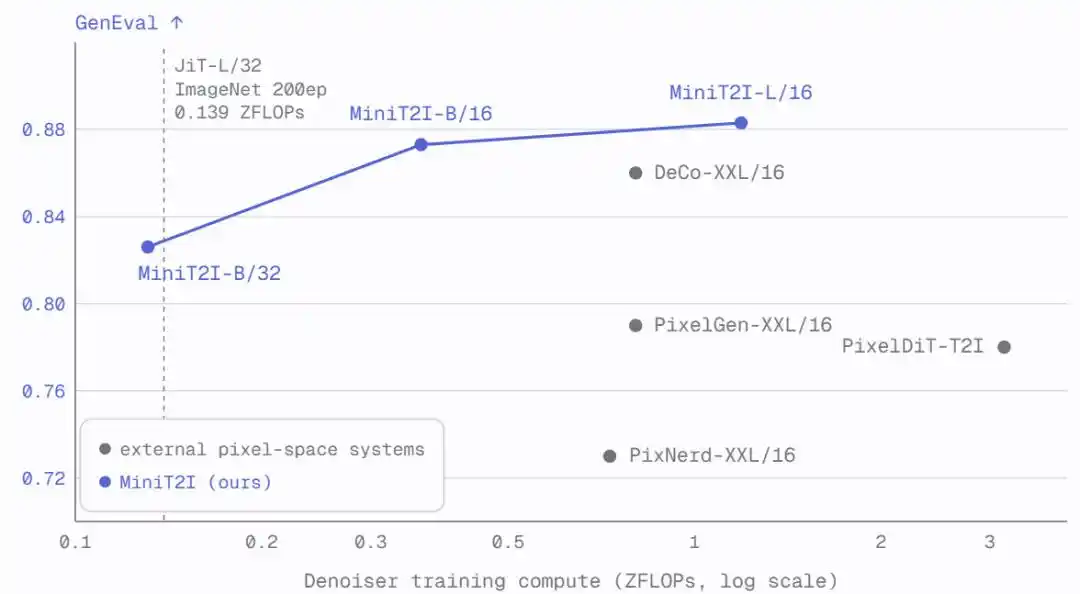
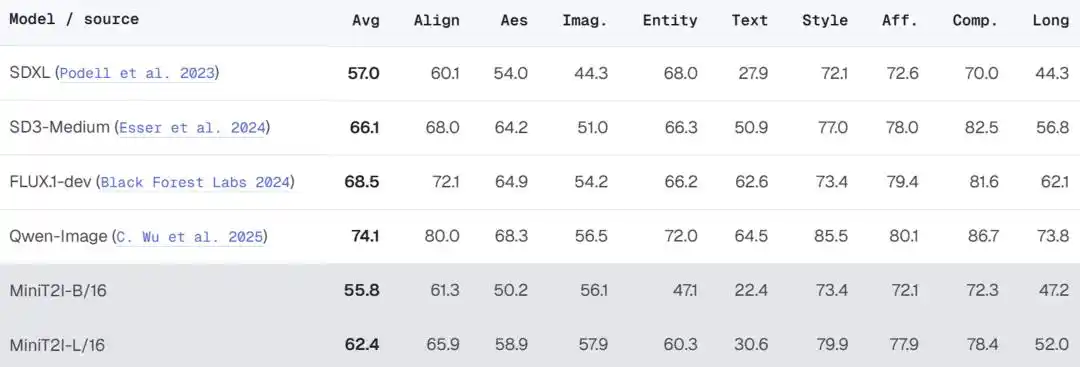
Khi mở rộng lên L/16 (912M tham số), mô hình có tiến bộ rõ ràng về tính đa dạng phong cách, quan hệ không gian và kết xuất văn bản, chất lượng tạo ra trong các cảnh tưởng tượng tương đương hoặc thậm chí tốt hơn so với SD3-Medium (~2B tham số).
Trong đánh giá toàn diện hơn trên PRISM-Bench, MiniT2I-L/16 thể hiện xuất sắc ở các chiều phong cách, kết hợp và tưởng tượng (79.9, 78.4, 57.9), đã tiệm cận mức độ của SD3-Medium. Tuy nhiên, vẫn còn khoảng cách trong kết xuất văn bản (30.6 so với 50.9 của SD3) và thực thể có tên (60.3 so với 66.3) - nhóm nghiên cứu thẳng thắn thừa nhận đây là giới hạn vốn có của công thức dữ liệu công khai, cần bổ sung dữ liệu chuyên ngành để bù đắp.
Hạn chế và triển vọng
MiniT2I là một bằng chứng khái niệm cho một lộ trình kỹ thuật, chứ không phải là sản phẩm cuối cùng. Nhóm nghiên cứu trung thực chỉ ra một số vấn đề chưa được giải quyết:
- Hiện tượng giả patch trong không gian pixel: Tồn tại sự không liên tục có thể đo lường được tại ranh giới patch (độ dốc tại ranh giới cao hơn 17-22% so với không tại ranh giới), mô hình không gian tiềm ẩn không có vấn đề này.
- Tác dụng phụ của CFG trong không gian pixel: Hệ số hướng dẫn cao (~6) sẽ đẩy các token cục bộ ra khỏi đa tạp dữ liệu, trong trường hợp không có bộ giải mã để "làm mịn", sẽ trực tiếp lộ ra như các khuyết điểm hình ảnh.
- Giới hạn trên về độ phân giải: Hiện tại hoạt động tốt ở 512×512, việc đẩy lên 4K+ cần cơ chế chú ý hiệu quả hơn hoặc chuỗi dài hơn.
- Nút thắt dữ liệu: Kết xuất văn bản và thực thể có tên vẫn yếu hơn so với hệ thống công nghiệp, cần được bổ sung mạnh mẽ bằng dữ liệu chuyên ngành.
MiniT2I đã chứng minh rằng việc tạo ảnh từ văn bản ở giai đoạn hiện tại không phải là trò chơi chỉ dành riêng cho các phòng thí nghiệm công nghiệp hàng đầu.
Khi một mô hình với 258M tham số, sử dụng dữ liệu hoàn toàn công khai, được huấn luyện trong 3 ngày với khả năng tính toán ở cấp độ học thuật, đã có thể đánh bại đối thủ lớn hơn nhiều lần về quy mô, có lẽ việc tạo ảnh từ văn bản đang trải qua sự chuyển đổi mô hình từ "chồng chất nguyên liệu" sang "tinh lọc".
"T2I không còn là bức tường cao không thể với tới. Chào mừng sử dụng và cải thiện nó, xây dựng đường cơ sở đơn giản hơn."
Bài viết này đến từ tài khoản WeChat công cộng "Cơ trí chi tâm" (机器之心)






