Lời của biên tập viên: Anthropic phát hành Claude Opus 4.8, đạt năm vị trí đầu tiên trong sáu tiêu chuẩn cốt lõi, giá cả vẫn giữ nguyên; Claude Code được bổ sung luồng công việc động, thế hệ mô hình cấp độ Mythos tiếp theo cũng đã bước vào dự kiến thị trường.
So với việc chỉ nâng cao hiệu suất, điều đáng chú ý hơn trong lần phát hành này là Anthropic bắt đầu định hình 'sự tin cậy' thành điểm bán hàng cốt lõi của các mô hình tiên tiến.
Trong bài kiểm tra độ trung thực về mã, tỷ lệ bỏ sót lỗi của Opus 4.8 đã giảm mạnh; trong Claude Code, nó có thể điều phối nhiều tác nhân con và đưa vào kiểm tra tự đối kháng trước khi giao kết quả. Những thay đổi này cùng hướng đến một vấn đề thực tế: khi AI từ cửa sổ trò chuyện bước vào quy trình công việc thực tế, điều người dùng lo lắng nhất thường không phải là mô hình không thể hoàn thành nhiệm vụ, mà là khi mắc lỗi, nó vẫn đưa ra một câu trả lời trông có vẻ hoàn chỉnh, mượt mà và tự nhất quán.
Do đó, ý nghĩa của Opus 4.8 không chỉ dừng ở một lần nâng cấp mô hình, mà còn giải phóng một tín hiệu ngành rõ ràng: Cuộc cạnh tranh giữa các mô hình tiên tiến đang chuyển từ việc chỉ đuổi theo benchmark, sang việc tranh giành khả năng tin cậy, xác minh được và khả năng phơi bày lỗi. Đối với doanh nghiệp và người dùng chuyên nghiệp, ngưỡng cửa cốt lõi của AI trong giai đoạn tiếp theo sẽ ngày càng phụ thuộc vào việc mô hình có đáng được ủy thác hay không.
Đây cũng là tiền đề để Agent thực sự trở nên khả dụng. Mô hình cần hoàn thành nhiều nhiệm vụ hơn, và cũng cần khiến người ta dám giao cho nó những nhiệm vụ quan trọng hơn, phức tạp hơn.
Dưới đây là bài viết gốc:
Hôm nay, Anthropic đã phát hành Claude Opus 4.8. Trong sáu bài kiểm tra chuẩn được liệt kê trong thẻ phát hành, nó đã đạt vị trí đầu tiên trong năm bài.
Điều thay đổi quan trọng tôi quan tâm nhất là: Trong bài kiểm tra độ trung thực tổng kết mã của Anthropic, Opus 4.7 có 19.7% trường hợp không đánh dấu lỗi của chính mình; trong khi Opus 4.8, tỷ lệ này đã giảm xuống 3.7%. Cùng một nhiệm vụ, khả năng nhận diện lỗi trong công việc của chính nó đã tăng lên khoảng năm lần. Anthropic tóm tắt điều này trong thông báo là '4 lần'. Dù tính thế nào đi nữa, đây đều là yếu tố then chốt quyết định bạn có thể giao công việc thực sự cho mô hình này rồi yên tâm rời đi hay không, và cũng quan trọng hơn bất kỳ điểm số benchmark nào trên thẻ phát hành.

Thực tế đã phát hành những gì
Trước tiên nói phiên bản tóm tắt, sau đó đi vào các con số cụ thể:
Độ tin cậy thực sự được nâng cao. Ngoài dữ liệu về độ trung thực mã được đề cập ở trên, Opus 4.8 cũng là mô hình Claude đầu tiên đạt được 'số không theo nghĩa đen' trong hai bài kiểm tra trách nhiệm: Nó đã giảm tần suất 'báo cáo sai kết quả có khiếm khuyết' từ 0.25 xuống 0.00, giảm tỷ lệ xảy ra 'lười biếng điều tra' từ 25% xuống 0%. Các câu trả lời sai quá tự tin đã giảm khoảng 11 lần. Xu hướng thiên vị công việc của chính nó, một loại thiên kiến có thể đo lường được trong 4.7, đã biến mất.
Claude Code đã bổ sung luồng công việc động, hiện đang là phiên bản xem trước nghiên cứu. Claude giờ đây sẽ tự viết kịch bản điều phối, lập lịch song song hàng chục đến hàng trăm tác nhân con trong một phiên và chạy các tác nhân đối kháng độc lập, cố gắng bác bỏ các kết quả này trước khi trình bày cho bạn. Đây là ý tưởng 'đội tác nhân' được đề xuất trong Opus 4.6, giờ đây đã trở thành khả năng tự động hóa.
Nó dẫn đầu trên thẻ phát hành của chính mình, nhưng không phải dẫn đầu toàn diện. Thắng năm trong sáu bài. GPT-5.5 vẫn dẫn đầu về nhiệm vụ thao tác thiết bị đầu cuối. Và trong thẻ hệ thống, vẫn ẩn chứa một số sự thụt lùi về độ trung thực mà Anthropic không đưa lên slide trình chiếu, sẽ được trình bày ở phần sau.
Giá cả không thay đổi. Vẫn là 5 USD cho mỗi triệu token đầu vào và 25 USD cho mỗi triệu token đầu ra, giống với 4.7. Tuy nhiên, chế độ nhanh hiện nay rẻ hơn ba lần so với trước, mặc dù nó vẫn thuộc mức giá cao cấp, với giá 10 USD / 50 USD.
Mythos sắp ra mắt. Anthropic khẳng định rõ ràng, mô hình cấp độ Mythos cực kỳ mạnh mẽ với quyền truy cập hạn chế sẽ ra mắt trong vài tuần tới. Opus 4.8 là lối vào công khai dẫn đến nó.
Thẻ phát hành chính thức: Bức tranh điểm chuẩn
Dưới đây là thẻ phát hành chính thức, được trình bày với bảng màu của chúng tôi.
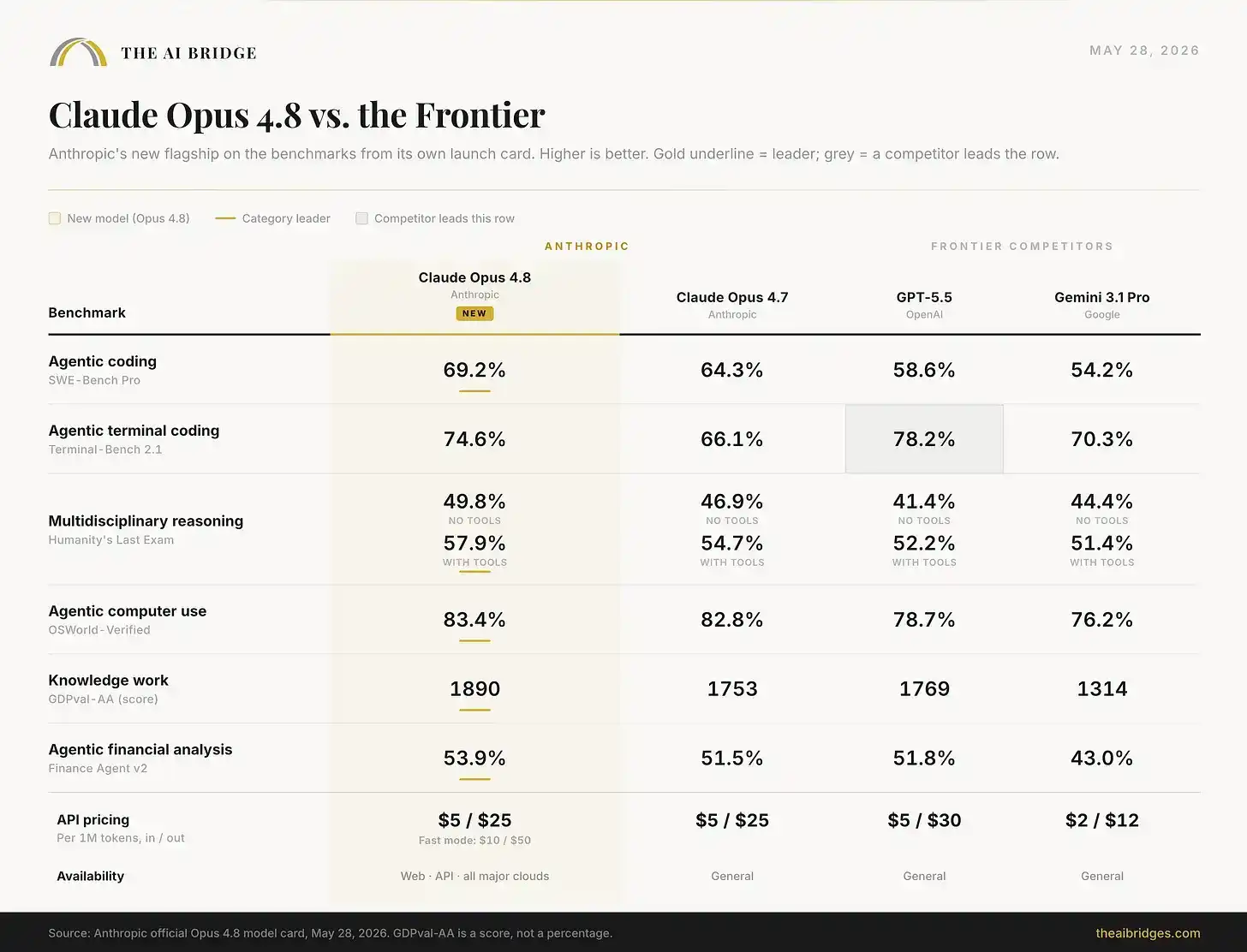
Có một hạng mục đã phá vỡ thế áp đảo, và hạng mục này rất quan trọng. Trên Terminal-Bench 2.1, tức là benchmark kiểm tra khả năng hoàn thành nhiệm vụ tác nhân dài hạn thông qua thiết bị đầu cuối, GPT-5.5 vẫn dẫn đầu với 78.2% so với 74.6% của Opus 4.8. Anthropic đã đặt sự thất bại này lên thẻ phát hành của mình, thay vì chọn cách che giấu. Sự phân chia 'tác nhân và thợ thủ công' mà chúng tôi đề cập khi GPT-5.5 ra mắt vẫn chưa hoàn toàn được xóa bỏ: GPT-5.5 vẫn là một tác nhân thao tác thiết bị đầu cuối thuần túy mạnh hơn, trong khi Opus 4.8 giống một kỹ sư mạnh hơn trong hầu hết các công việc mà người dùng chuyên nghiệp thực sự quan tâm, như mã hóa thế giới thực, suy luận chuyên gia, sử dụng máy tính và công việc tri thức.
Ngoài thẻ phát hành
Thẻ phát hành chỉ hiển thị sáu bài benchmark. Báo cáo thẻ hệ thống 244 trang đã ghi nhận hơn 40 bài kiểm tra, trong đó những kết quả thú vị nhất không nằm trên slide. Các hạng mục sau đây đáng chú ý:
Khả năng toán học tăng 27 điểm phần trăm. Trên USAMO 2026, tức cuộc thi Olympic Toán học Hoa Kỳ diễn ra vào tháng 3 năm nay, Opus 4.8 đạt 96.7%, trong khi 4.7 là 69.3%. Vì cuộc thi này diễn ra sau thời điểm kết thúc đào tạo của Opus 4.8, nên không có vấn đề ô nhiễm dữ liệu. Đây là bước nhảy vọt lớn nhất giữa các thế hệ trong toàn bộ thẻ.
Khoảng cách ưu thế mở rộng trong bối cảnh ngữ cảnh dài. Trong một bài kiểm tra suy luận đồ thị triệu token, Opus 4.8 đạt 68.1 điểm, trong khi 4.7 là 40.3 và GPT-5.5 là 45.4. Ngữ cảnh càng dài, nhiệm vụ càng khó, biên độ dẫn đầu của nó càng rõ ràng.
Đa tác nhân mới là nơi nó thực sự đứng đầu. Một tác nhân Opus 4.8 đơn lẻ trong nhiệm vụ nghiên cứu web đã tụt sau Gemini, lần lượt là 84.3 và 85.9. Nhưng nếu để một bộ điều phối lập lịch cho một nhóm tác nhân con, điểm số của nó có thể đạt 88.5%, trở thành điểm cao nhất trong các kết quả đã báo cáo; một đội năm tác nhân còn có thể đạt được kết quả tốt nhất của một tác nhân đơn lẻ chỉ với một phần năm thời gian. Đây chính là thể hiện của tính năng luồng công việc động trong benchmark.
Hiệu quả token có sự thay đổi chất lượng. Trong bài kiểm tra mã hóa khó nhất, Opus 4.8 ngay ở cài đặt nỗ lực thấp nhất, đã đạt được hiệu suất của Opus 4.7 ở cài đặt nỗ lực cao nhất. Nghĩa là, bạn có thể đạt được hiệu suất đỉnh trước đây với chi phí token ít hơn.
Nó đã vượt qua ngưỡng mà chưa có mô hình nào vượt qua trước đó. Trên Legal Agent Benchmark của Harvey, một nhiệm vụ chỉ được coi là thành công khi tất cả các tiêu chí đánh giá trong nhiệm vụ đó đều vượt qua. Opus 4.8 là mô hình đầu tiên đứng đầu trong tiêu chuẩn 'vượt qua tất cả' này. Nó vượt qua 89% các tiêu chí riêng lẻ, nhưng tỷ lệ hoàn thành toàn bộ nhiệm vụ chỉ có 9.6%, điều này cũng cho thấy yêu cầu của công việc pháp lý thực tế nghiêm ngặt đến mức nào.
Cũng có sự thụt lùi được trình bày trung thực. Có ba điều thực sự tệ hơn 4.7, và Anthropic cũng thừa nhận trong thẻ hệ thống. GPQA Diamond, tức bài kiểm tra khoa học chuyên gia, từ 94.2 giảm xuống 93.6. Khả năng từ chối trả lời trong bối cảnh sử dụng máy tính và khả năng chống lại prompt injection đều có phần suy giảm, do đó 4.8 trong các tình huống tác nhân dễ bị thao túng hơn. Ngoài ra, trong một bài kiểm tra mô phỏng kinh doanh kéo dài một năm, số tiền mặt còn lại cuối cùng của nó chỉ bằng một phần ba so với 4.7. Những điều này không xuất hiện trên thẻ phát hành, và cũng chính vì vậy, càng đáng được chỉ ra.
So với các mô hình trọng số mã nguồn mở, nó đang ở vị trí nào
Thẻ phát hành chỉ so sánh Opus 4.8 với các mô hình tiên tiến mã nguồn đóng khác. Nếu mở rộng tầm nhìn đến các mô hình trọng số mã nguồn mở giá rẻ mà nhiều nhóm hiện đang thử nghiệm, bức tranh gần như là hình ảnh thu nhỏ của ngành công nghiệp AI năm 2026: Opus 4.8 dẫn đầu về năng lực, nhưng khoảng cách với các mô hình miễn phí, có thể tự lưu trữ chỉ còn vài điểm phần trăm, trong khi khoảng cách giá cả lại cực kỳ lớn.
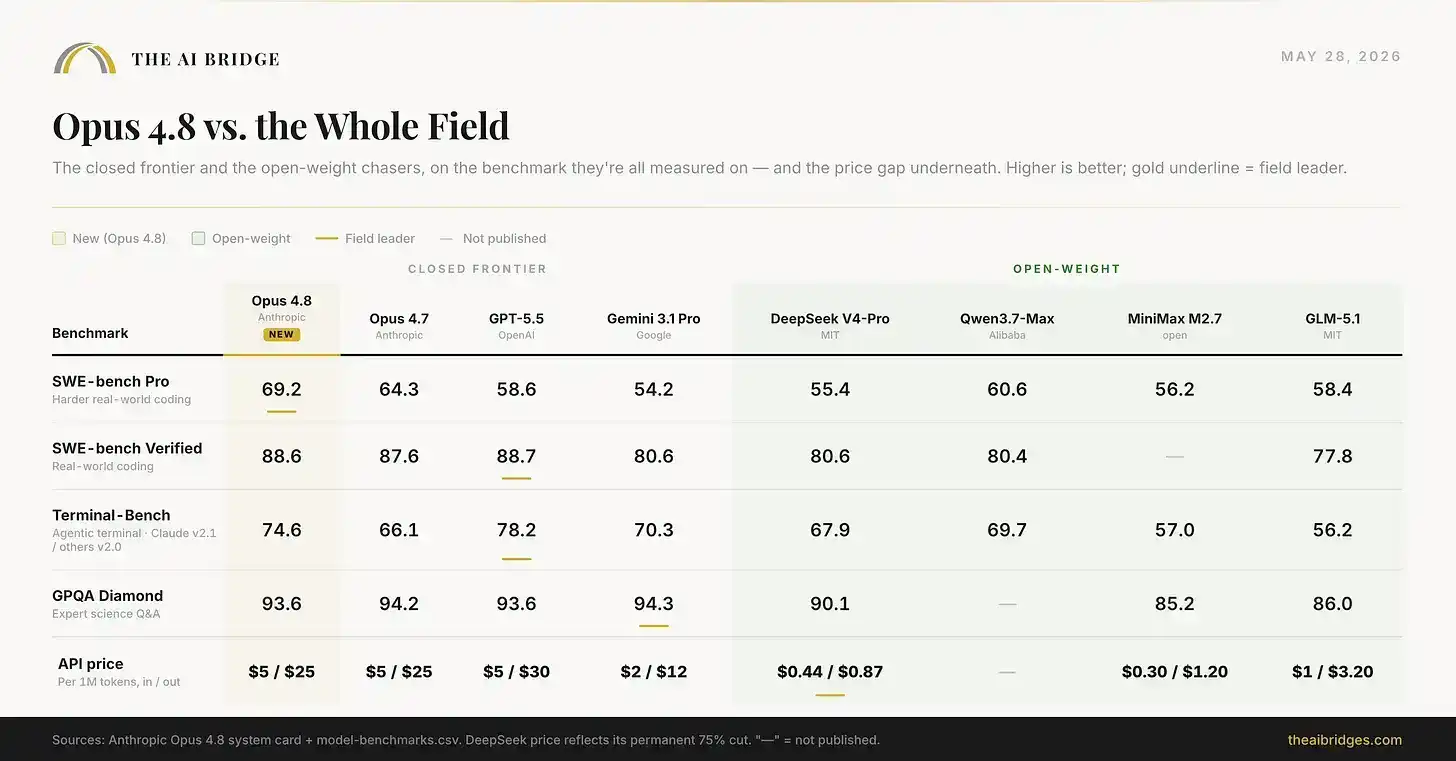
Biểu đồ trên bao gồm so sánh đầy đủ tám mô hình. Giá của DeepSeek phản ánh mức giảm giá vĩnh viễn 75%; giá của Qwen Max vẫn chưa được công bố.
Opus 4.8 thắng trực tiếp trong benchmark mã hóa. Nhưng Qwen3.7-Max, một mô hình mã nguồn mở bạn có thể tự chạy, đạt điểm 60.6, chỉ thua khoảng 9 điểm. DeepSeek V4-Pro đạt 55.4 điểm, trong khi giá đầu ra của nó chỉ bằng khoảng một phần ba mươi của Opus. Đối với các nhiệm vụ kỹ thuật có rủi ro cao nhất, khoảng cách 25 USD cho mỗi triệu token đầu ra là đáng để trả. Đối với rất nhiều công việc hàng ngày, khoảng cách này ngày càng không đáng. Và đây chính là phép tính mà mỗi đội ngũ nghiêm túc hiện nay đang thực hiện.
Điều này có ý nghĩa gì với bạn
Nếu bạn đang sử dụng Opus 4.7, thì đây là một bản nâng cấp miễn phí. Giá không đổi, dữ liệu tốt hơn, khả năng đánh giá đầu ra của chính nó cũng rõ ràng đáng tin cậy hơn. Chỉ cần chuyển sang nó là được.
Câu hỏi thú vị hơn là: Bây giờ bạn sẵn sàng giao những công việc nào cho nó? Trong lòng mỗi độc giả đều có một ranh giới, phân biệt giữa 'công việc tôi có thể để AI làm' và 'công việc tôi phải tự mình làm, vì tôi chưa thể tin tưởng giao phó'. Việc nâng cao độ tin cậy của 4.8 có nghĩa là bạn có thể đẩy ranh giới này lên một bước. Mô hình giỏi hơn trong việc đánh dấu sự không chắc chắn của chính mình, điều này làm giảm chi phí của 'sự giao phó lỗi thầm lặng' và mở rộng phạm vi nhiệm vụ đáng được ủy thác cho mô hình. Đây chính là ý nghĩa thực tế của dữ liệu độ trung thực trong sử dụng, nó quan trọng hơn bất kỳ điểm số đơn lẻ nào.
Điều này cũng tương đồng với nội dung chúng tôi đã viết tuần trước. Nghiên cứu AI Fluency của chính Anthropic phát hiện ra rằng khi sản phẩm đầu ra của mô hình trông có vẻ polished và hoàn chỉnh, mọi người sẽ khó nhận thấy ngữ cảnh thiếu sót hơn đáng kể. Câu trả lời trông đã hoàn tất, nên chúng ta ngừng kiểm tra. Opus 4.8 tấn công chế độ thất bại này từ phía mô hình: Nó giỏi hơn trong việc cho bạn biết một câu trả lời trông sạch sẽ và hoàn chỉnh có thể còn điểm yếu ở đâu. Nó không thể thay thế khả năng phán đoán của bạn, nhưng nó có thể cung cấp điểm bám cho khả năng phán đoán đó.
Nếu bạn sử dụng Claude Code, tuần này có thể thử luồng công việc động với một nhiệm vụ thực sự lớn, chẳng hạn như một lần di chuyển, hoặc kiểm tra toàn diện một lượng lớn tệp, đồng thời chú ý đến đồng hồ đo token. Khả năng này là có thật, và kiểm tra tự đối kháng cũng là chìa khóa để làm cho đầu ra đáng tin cậy hơn. Nhưng chi phí cũng là có thật. Đây là công cụ dành cho những nhiệm vụ lớn mà một tác nhân đơn lẻ khó hoàn thành, không nên trở thành tùy chọn mặc định hàng ngày của bạn.
Tiếp theo: Mythos, sắp ra mắt trong vài tuần tới
Tuyên bố mang tính tiên phong nhất trong lần phát hành này thực ra không nói về 4.8. Anthropic cho biết mô hình cấp độ Mythos sẽ ra mắt trong vài tuần tới, và định vị Opus 4.8 là một bước công khai dẫn đến nó.
Bạn cần hiểu điều này có nghĩa là gì. Mythos là mô hình tiên tiến hạn chế mà Anthropic nội bộ vẫn đang tiến hành benchmark, nó vượt trội Opus 4.8 đã phát hành trên hầu hết mọi chỉ số: Đạt 93.9% trên SWE-bench Verified; trong bài kiểm tra an ninh mạng, nó có thể tạo ra các khai thác lỗ hổng có thể chạy được cho hầu hết các mục tiêu trong trình duyệt hiện tại, trong khi tỷ lệ thành công của Opus 4.8 dưới 10%. Trước đây nó chỉ được mở cho khoảng 52 tổ chức đã được xem xét, giá gấp năm lần Opus tiêu chuẩn, được coi là cơ sở hạ tầng, chứ không phải sản phẩm thông thường.
Do đó, khi một mô hình cấp độ Mythos mạnh mẽ hơn ra mắt trong vài tuần tới, nên hiểu nó trong khuôn khổ 'hai lớp thị trường': Một lớp là lớp hàng hóa hóa, tức Opus 4.8, mở rộng rãi, giá không đổi, ngày càng bị các mô hình mã nguồn mở miễn phí đuổi kịp; lớp kia là lớp tiên phong bị kiểm soát, tức Mythos, đắt đỏ, truy cập hạn chế. Hai lớp này không phải là sản phẩm tách biệt, mà là các cấp độ khác nhau trên cùng một đường liên tục về năng lực. Công việc về độ tin cậy trong 4.8 chính là thứ bạn phải xây dựng trước khi mục tiêu thực sự là 'cho mô hình chạy với ít giám sát hơn'. Và mục tiêu này giờ đây không cách chúng ta vài quý, mà là vài tuần.
Bối cảnh: Đường lối này đã đến đây như thế nào
Nếu bạn đã bỏ lỡ nhịp độ trong bốn tháng qua, có thể hiểu như thế này: Opus 4.6 vào tháng 2 mang đến đội tác nhân, Sonnet 4.6 mang đến sự sụp đổ giá cả, Opus 4.7 vào tháng 4 mang đến bước nhảy vọt về suy luận, còn Mythos là trần nhà hạn chế mờ ảo bên cạnh. Opus 4.8 đã nối hai manh mối trong số đó lại với nhau: Nó tiếp nối câu chuyện điều phối của 4.6, đồng thời cũng là lối vào dẫn đến Mythos.
Nhịp độ phát hành này tự nó đã là sự thật quan trọng ẩn dưới mọi thay đổi bề mặt. Mô hình hàng đầu trong vòng vài tháng đã đi từ 4.5, 4.6, 4.7 đến 4.8, và mô hình mà bạn áp dụng chuẩn hóa cho nhóm của mình hôm nay, đến mùa thu có thể không còn là mô hình bạn thực sự đang chạy. Đây cũng là lý do tại sao, thay vì đầu tư vào kỹ năng sử dụng một mô hình cụ thể, bạn nên đầu tư vào những khả năng có thể di chuyển xuyên mô hình, chẳng hạn như ủy thác rõ ràng và xác minh nghiêm ngặt.
Việc quét sạch các bài benchmark sẽ thu được sự lan truyền ảnh chụp màn hình. Nhưng nơi thực sự thay đổi lại nhỏ hơn và quan trọng hơn: Đây là phiên bản Claude đầu tiên, mà điểm bán hàng cốt lõi không còn chỉ là 'nó thông minh hơn', mà là 'bạn có thể giao phó nhiều việc hơn cho nó'. Trước khi Agent thực sự trở nên hữu ích, toàn bộ ngành công nghiệp phải đi theo hướng này; và phần năng lực này cũng khó đưa vào một biểu đồ nhất.
Ranh giới của bạn hiện tại ở đâu? Những công việc nào bạn sẵn sàng giao cho mô hình, và những công việc nào vẫn phải tự mình làm? Và cần phải xảy ra điều gì, để bạn sẵn sàng đẩy ranh giới này lên thêm một bước nữa?





