Author: Marc Andrusko
Compiled by: Deep Tide TechFlow
Deep Tide Intro: Silicon Valley is witnessing a wave of "Palantir-ization"—AI startups are emulating Palantir, sending engineers to work on-site with clients, providing highly customized services, and signing seven-figure deals.
a16z partner Marc Andrusko pours cold water on this trend: The vast majority of companies are only copying the surface-level tactics and will ultimately become consulting firms disguised as SaaS companies. This article breaks down which parts of the Palantir model are truly replicable and which are just beautiful illusions.
Main Content:
A popular line in startup pitch decks these days is: "We're basically the Palantir for X."
Founders love to talk about deploying "Forward-Deployed Engineers" (FDEs) to client sites, building deeply customized workflows, and operating like a special forces unit rather than a traditional software company. This year, job postings for "Forward-Deployed Engineers" have surged by hundreds of percentage points. Everyone is copying the model Palantir pioneered in the early 2010s.
I understand why this approach is attractive. Enterprise clients are currently overwhelmed by the question of "what software to buy"—everything claims to be AI, and it's never been harder to separate signal from noise. Palantir's sales pitch is seductive: drop a team into a chaotic environment, stitch together various homegrown, siloed systems, and deliver a customized working platform within months. For startups trying to land their first seven-figure deal, "We'll put engineers inside your organization to get things done" is an incredibly powerful promise.
But I'm skeptical that "Palantir-ization" can be generalized as a universal methodology. Palantir is a "Category of One"—just look at how its stock trades! Most companies copying its superficial tactics will end up as expensive service firms with software valuation multiples but no compounding competitive advantages. This reminds me of the 2010s when every startup claimed to be a "platform," but true platform companies were extremely rare because they are so hard to build.
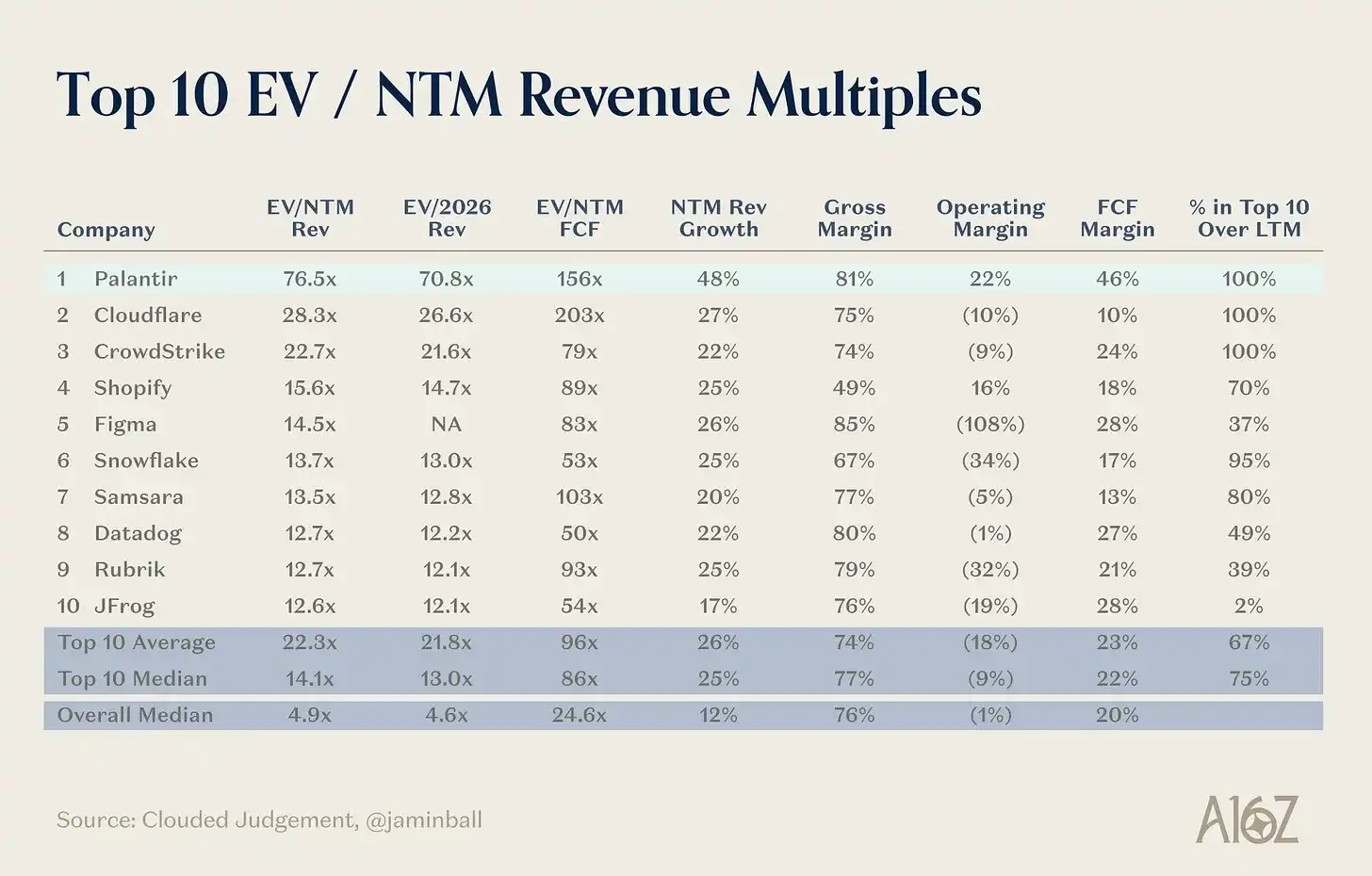
This article aims to clarify which parts of the Palantir model are truly portable and which are so unique they cannot be replicated, providing a more pragmatic roadmap for founders who want to combine enterprise software with high-touch services.
What Does "Palantir-ization" Actually Mean?
"Palantir-ization" has come to refer to several interrelated things:
Forward-Deployed Embedded Engineering
Forward-Deployed Engineers (called "Delta" and "Echo" internally at Palantir) embed within the client's organization (often for months), understand the business context, connect various systems, and build customized workflows on the Foundry platform (or the Gotham platform in high-security environments). Since pricing is typically a fixed fee, there's no traditional "SKU," and the engineers are responsible for building and maintaining these capabilities.
Highly Opinionated Integration Platform
Palantir's product is essentially not a loose toolkit but an opinionated platform for data integration, governance, and operational analytics—closer to an "operating system" for organizational data. The goal is to turn fragmented data into real-time, high-confidence decisions.
High-End, High-Touch Sales Model
"Palantir-ization" also describes a sales style: long, high-touch sales cycles targeting mission-critical environments (defense, law enforcement, intelligence, etc.). Regulatory complexity and the magnitude of industry "bets" are features, not bugs.
Selling Outcomes, Not Licenses
Revenue comes from multi-year, outcome-linked contracts that blend software, services, and continuous optimization. Contracts for a single client can reach tens of millions of dollars annually.
A recent analysis defined Palantir as a "Category of One" because it excels simultaneously at three things: (a) building an integrated product platform, (b) embedding elite engineers into client operations, and (c) proving itself in mission-critical government and defense environments. Most companies can do one or two of these; it's nearly impossible to do all three.
But by 2025, everyone wants to bask in the glow of this model.
Why Everyone Wants to Copy Palantir Now
Three forces are converging:
1. Enterprise AI Has an "Implementation" Problem
A large portion of AI projects get stuck before reaching production, often due to messy data, integration headaches, and a lack of internal champions. While buying intent remains fervent (there's real top-down pressure from boards and the C-suite to "must buy AI"), actual deployment and ROI often require significant hand-holding.
2. Forward-Deployed Engineers Appear to Be the Missing Bridge
Media reports and hiring data show an explosive growth in FDE roles this year—sources indicate increases between 800% and 1000%—as AI startups push to make deployments actually work by embedding engineers.
3. Growth at All Costs is the Norm (Signing Seven-Figure Deals is Easier for Quick Scale Than Five-Figure Ones)
If flying engineers out for on-site work is the price to land a $1M+ deal with a Fortune 500 company or government agency, many early-stage companies are willing to trade gross margin for momentum. Investors are also becoming more accepting of lower gross margins, as new AI experiences often require significant inference costs. The bet is: you win a seat at the table and trust with the client's management, deliver "outcomes," and price accordingly.
So the narrative becomes: "We'll do what Palantir did. We'll send an elite team, build something magical, and over time productize it into a platform."

This story *can* work in very specific circumstances. But there are hard constraints that founders often gloss over.
Where the Analogy Breaks Down
Trying to Sell "Outcomes" from Day One
Palantir's flagship product, Foundry, is a composition of hundreds of microservices that collectively serve an outcome. These microservices form productized, opinionated solutions to common enterprise problems across domains. Having met hundreds of AI application founders over the past two years, I can tell you where the analogy breaks: startups come in pitching grand outcome-based goals, whereas Palantir first consciously built microservices that formed the bedrock of its core capabilities. This is precisely what distinguishes Palantir from a regular consulting firm (and why it trades at 77x next year's revenue).
Palantir has a suite of core products:
- Palantir Gotham: A defense and intelligence platform helping military, intelligence, and law enforcement agencies integrate and analyze disparate data for mission planning and investigations.
- Palantir Apollo: A software deployment and management platform that autonomously and securely pushes updates and new features to any environment (multi-cloud, on-prem, air-gapped).
- Palantir Foundry: A cross-industry data operations platform that integrates data, models, and analytics to drive enterprise operational decisions.
- Palantir Ontology: A dynamic, actionable digital model of real-world entities, relationships, and logic that powers applications and decisions within Foundry.
- Palantir AIP (Artificial Intelligence Platform): Connects AI models (like LLMs) with an organization's data and operations via the Ontology, creating production-ready AI-driven workflows and agents.
Quoting that Everest report: "Palantir's contracts start small. An initial engagement might be just a short bootcamp and limited licenses. If value is proven, more use cases, workflows, and data domains are layered on. Over time, the revenue mix shifts from services toward software subscriptions. Unlike consulting firms, services are a means to drive product adoption, not the primary revenue source. Unlike most software vendors, Palantir is willing to invest its own engineering time upfront to land meaningful clients."
On one hand, the AI application companies I see now often jump straight to seven-figure contracts. But on the other hand, this is primarily because they are in full customization mode—they are solving whatever problems their early clients throw at them, hoping to discover themes later to build core capabilities or "SKUs."
Not Every Problem is a "Palantir-Level" Problem
The domains Palantir initially deployed in had the alternative of "nothing else works": counterterrorism, fraud detection, battlefield logistics, high-stakes medical operations. The value of solving the problem is measured in billions of dollars, lives saved, or geopolitical consequences, not incremental efficiency.
If you're selling to a mid-market SaaS company to optimize its sales process by 8%, you can't afford that level of custom deployment. The ROI math simply doesn't support months of on-site engineering.
Most Clients Don't Want to Be Your R&D Lab Forever
Palantir's clients implicitly accept co-evolving the product with it; they tolerate a lot because the stakes are high and alternatives are limited.
Most enterprises, especially outside defense and regulated fields, don't want to feel like they are a long-running consulting project. They want predictable implementation, interoperability with existing software tools, and quick time-to-value.
Talent Density and Culture Don't Generalize
Palantir spent over a decade recruiting and training exceptionally strong generalist engineers who can write production-grade code, navigate bureaucracy, and sit in a room with colonels, CIOs, and regulators. Alumni from this role form an entire "Palantir Mafia" of founders and executives. Many are unicorn-level because they are both highly technical and incredibly effective with clients.
Most startups cannot assume they can hire hundreds of such people. In practice, "We'll build a Palantir-style FDE team" often devolves into:
- Pre-sales solutions engineers renamed "FDE"
- Junior generalists asked to do product, implementation, and account management simultaneously
- Leadership that has never seen a Palantir deployment up close but likes the vibe
To be clear, there is a ton of talented people out there, and tools like Cursor are enabling non-technical employees to write code. But to run the Palantir model at scale requires a fusion of commercial and technical talent that is extremely scarce, and having actually been at Palantir helps immensely because it's a very unique company. But the pool of such people is limited!
The Services Trap is Real
Palantir works because there is a real platform underneath the custom work. If you only copy the embedded engineer part, you'll end up with thousands of custom deployments that cannot be maintained or upgraded. Even in a world where AI tools allow companies to achieve software-level gross margins in this model, those over-indexing on forward deployment without a strong product backbone may fail to generate increasing returns to scale and lasting moats.
Undiscriminating investors might see hockey-stick growth from $0 to $10M in contract value and rush in. But the question I keep asking is: What happens when dozens (or even hundreds) of these $10M startups start colliding with identical pitches?
By then, you're not "the Palantir for X." You're "the Accenture for X," just with a prettier front end.
What Palantir Actually Got Right
Stripping away the mythology, a few elements are worth studying closely:
1. Platform-First, Not Project-First
Palantir's forward-deployed teams build based on a small set of reusable primitives (data models, access controls, workflow engines, visualization components), not by writing entirely custom systems for each client.
2. Strong Opinions on How Work "Should" Be Done
The company doesn't just automate existing processes; it often pushes clients toward new ways of working, and the software embodies those opinions. This is rare courage for a vendor, and it enables reuse.
3. Long Time Horizon and Capital
Becoming a Palantir-esque company requires enduring long periods of negative sentiment, political controversy, and unclear near-term monetization while the platform and sales model mature.
4. A Very Specific Market Mix
The early focus on intelligence and defense was a feature, not a bug: high willingness to pay, high switching costs, high stakes, and a very small number of超大 clients. Not to mention a set of legacy competitors that hadn't had to compete for deals in decades.
In other words, Palantir isn't just "software company + consulting." It's "software company + consulting + political project + extremely patient capital."
This is not something you can just graft onto a vertical SaaS product and generalize.
A More Realistic Framework: When Does "Palantir-ization" Make Sense?
Instead of asking "How do we become like Palantir?", ask a series of threshold questions:
1. Criticality of the Problem
Is this problem "mission-critical" (lives, national security, billions of dollars) or "nice-to-have" (10-20% efficiency gains)? The higher the stakes, the more justified the forward-deployed model is.
2. Customer Concentration
Are you selling to dozens of超大 clients or thousands of small ones? Embedded engineering scales better with a concentrated, high ACV (Annual Contract Value) customer base.
3. Degree of Domain Fragmentation
Are workflows similar across clients and the software tools used the same, or is every deployment fundamentally different? If every client is a snowflake, it's hard to build a consistent platform. A degree of homogeneity helps.
4. Regulation & Data Gravity
Are you operating in highly regulated domains with significant data integration pain points (defense, healthcare, financial crime, critical infrastructure)? That's where Palantir-style integration work can create real value.
If you fall mostly in the lower left of these dimensions (low criticality, fragmented customers, relatively simple integration), full "Palantir-ization" is almost certainly the wrong model. That scenario is better suited for a bottom-up PLG (Product-Led Growth) motion.
What's Worth Learning
Although I doubt every early company can successfully deploy the Palantir model, there are pieces of this playbook worth considering:
1. Use Forward Deployment as Scaffolding, Not the House
It can be perfectly correct to:
- Have engineers work closely with early design partners
- Do whatever it takes to get the first 3-5 clients into production
- Use these engagements to stress-test your primitives and abstractions
But impose clear constraints:
- Time-bound deployments (e.g., "90-day sprint to production")
- Clear ratios (e.g., "max X engineering headcount per $1M ARR on a single client")
- Quarterly goals to convert custom code into reusable configs or templates
Otherwise, "We'll productize it later" becomes "We never got around to it."
2. Build on Strong Primitives, Not Custom Workflows
The real lesson from Palantir is in the product architecture:
- Unified data model and permissions layer
- Generic workflow engines and UI primitives
- Configuration over code wherever possible
Forward-deployed teams should spend time "selecting" and "validating" which primitives to assemble, not building entirely new things for each client. Leave net-new building for engineers.
3. Make FDEs Part of the Product, Not Just Delivery
In Palantir's world, forward-deployed engineers are deeply involved in product discovery and iteration, not just implementation. A strong product org and platform team feeds off what FDEs learn on the front lines.
If your FDEs sit in a separate "professional services" department, you lose this feedback loop and slide toward a pure services firm.
4. Be Honest About Your Margin Structure
If your pitch assumes 80%+ software gross margins and 150% net revenue retention, but your sales model actually requires long-term on-site projects, be transparent about the trade-offs—at least internally.
For some categories, a structurally lower-margin, higher-ACV model is perfectly rational. The problem is pretending to be SaaS when you're actually a services company with a platform. Investors typically look for the path to the largest absolute gross profit, and one way to get there is much larger contracts with more significant COGS (Cost of Goods Sold).
How I Would Stress-Test a "Palantir-ized" Startup
When a founder tells me "We're the Palantir for X," the questions in my notebook look something like this:
- Show me the opinionated platform boundary. Where does the shared product end and client-specific code begin? How quickly is this boundary moving?
- Walk me through the deployment timeline. How many engineer-months from signed contract to first production use? What *must* be customized?
- What is the gross margin for a mature client in Year 3? Does the forward-deployed investment "meaningfully" decrease over time? If not, why?
- If you sign 50 clients next year, what breaks? Hiring? Onboarding? Product? Support? I want to see where the model cracks.
- How do you decide "no" to customization? The willingness to say "no" to custom work is often what distinguishes a product company from a "services firm with a pretty demo."
If the answers are clear, based on real deployments, and architecturally coherent, then a degree of Palantir-style forward deployment might be a real advantage.
If the answers are vague, or it's clear that every engagement is completely unique, it's hard to underwrite repeatability or true scalable potential.
Conclusion
Palantir's success has created a powerful halo effect that dominates the ethos of venture-backed startups: elite engineering squads dropping into complex environments, stitching together chaotic data, and delivering systems that change how organizations make decisions.
It's easy to believe every AI or data startup should look like this. But for most categories, full "Palantir-ization" is a dangerous fantasy:
- The problem isn't critical enough
- Customers are too fragmented
- The talent model doesn't scale
- The economics quietly collapse into a services company
For founders, a more useful question isn't "How do we become Palantir?" but:
"How much Palantir-style forward deployment do we need to bridge the AI adoption gap in our category—and how quickly can we convert it into a true platform business?"
Get this right, and you can borrow the parts of the playbook that truly matter without inheriting the parts that will crush you.





