Ngày 22 tháng 6 năm 2026, mô hình mới Fugu do Sakana AI phát hành đã gây chấn động cộng đồng AI. Trong các bài kiểm tra chuẩn khắt khe SWE-Bench Pro và TerminalBench, Fugu Ultra lần lượt đạt được 73.7 và 82.1 điểm, vượt qua cả GPT-5.5 và Claude Opus 4.8, thậm chí còn tuyên bố sánh ngang với Fable 5 và Mythos Preview bị kiểm soát xuất khẩu. Điều đáng ngạc nhiên là, cốt lõi của hệ thống này, đứng đầu về khả năng kỹ thuật và suy luận, không phải là một con quái vật nghìn tỷ tham số, mà là một mô hình chỉ có 7 tỷ tham số. Nó không tự làm việc, mà đóng vai trò "chủ thầu" để điều phối động các mô hình AI hàng đầu toàn cầu. Kiến trúc phản trực giác này không chỉ phá vỡ quan niệm "thông số là công lý", mà còn phản ánh con đường đột phá AI của Nhật Bản trong điều kiện bị hạn chế về năng lực tính toán.
"Chủ Thầu" 7 Tỷ Tham Số: Kiến Trúc Phản Trực Giác Của Fugu
Để hiểu được sự kỳ lạ của Fugu, trước hết phải xem xuất thân của nó. Sakana AI được đồng tác giả bài báo Transformer Llion Jones và cựu nhà nghiên cứu Google David Ha thành lập vào năm 2023 tại Tokyo. Công ty này từ khi ra đời đã mang gen "truyền cảm hứng từ tự nhiên", tập trung vào việc sử dụng thuật toán tiến hóa và trí thông minh bầy đàn trong tự nhiên để giải quyết các vấn đề AI. Năm 2025, Sakana AI nhận được đầu tư từ các ông lớn như NVIDIA, Google, định giá hơn 25 tỷ USD. Nhưng dù có sự hậu thuẫn của các ông lớn, Nhật Bản trong nước vẫn thiếu cơ sở hạ tầng tính toán khổng lồ và bể dữ liệu như ở Mỹ và Trung Quốc. Trong sự hạn chế về nguồn lực này, Sakana AI đã không chọn đối đầu trực diện với các mô hình lớn nghìn tỷ tham số, mà đi theo con đường "sắp xếp và chỉ huy".
Định vị chính thức của Fugu là "một hệ thống điều phối đa tác nhân thông minh như một mô hình cơ bản duy nhất". Trong kiến trúc AI truyền thống, mô hình lớn là một "con quái vật đơn lẻ", người dùng nhập một từ gợi ý, mô hình tính toán từ lớp mạng thần kinh đầu tiên đến lớp cuối cùng và xuất ra kết quả. Mô hình này cực kỳ hiệu quả khi xử lý các vấn đề đơn giản, nhưng khi đối mặt với các nhiệm vụ kỹ thuật phức tạp, đa bước, thường xảy ra ảo giác hoặc đứt gãy logic.
Fugu thay đổi hoàn toàn mô hình này. Cốt lõi của nó là một mô hình 7B tham số được huấn luyện bằng học tăng cường, được gọi là RL Conductor. Mô hình 7B này bản thân nó không trực tiếp tạo ra câu trả lời cuối cùng, mà đóng vai trò "chủ thầu". Khi người dùng gửi nhiệm vụ thông qua một API tương thích OpenAI duy nhất, RL Conductor sẽ phân tích động loại nhiệm vụ, sau đó phân công các nhiệm vụ con cho các mô hình hàng đầu toàn cầu trong nhóm tác nhân thông minh, chẳng hạn như GPT-5, Gemini 3.1 Pro hoặc Claude Opus 4.8. Nó chịu trách nhiệm điều phối, xác minh và tổng hợp đầu ra của các mô hình này, cuối cùng đưa ra một kết quả đã được kiểm tra nhiều lần.
Lý thuyết hỗ trợ cho kiến trúc này đến từ hai bài báo tại ICLR 2026: "TRINITY: An Evolved LLM Coordinator" và "Learning to Orchestrate Agents in Natural Language with the Conductor". Các bài báo trình bày chi tiết cách sử dụng một mô hình tham số nhỏ thông qua học tăng cường để "chỉ huy" các mô hình lớn. Điều này thay đổi mô hình Test-time scaling (mở rộng tại thời điểm kiểm tra). Trước đây, năng lực tính toán chủ yếu được sử dụng để suy luận sâu bên trong mô hình, tức là để mô hình "cố gắng hết sức" tìm ra một câu trả lời; bây giờ, năng lực tính toán được sử dụng cho việc điều phối, xác minh và tổng hợp bên ngoài. Mô hình lớn truyền thống là một thực thể đơn lẻ toàn năng, còn Fugu là một đội ngũ chuyên gia. RL Conductor 7B đã chứng minh rằng, số lượng tham số mô hình không còn là tiêu chuẩn duy nhất quyết định năng lực, biết cách gọi công cụ và tác nhân thông minh bên ngoài cũng có thể đạt được sự nhảy vọt về hiệu suất.
Sự Thật Đằng Sau Điểm Số: Sánh Ngang Fable Và Vượt GPT-5.5
Lý do trực tiếp khiến Fugu gây chấn động là điểm số của nó trong các bài kiểm tra chuẩn khắt khe. Trong ngành công nghiệp AI, điểm số là thước đo cứng cho năng lực mô hình, nhưng các bài kiểm tra chuẩn khác nhau có trọng tâm hoàn toàn khác nhau. SWE-Bench Pro và TerminalBench 2.1 mà Sakana AI chọn đều là những "xương cứng" thiên về môi trường kỹ thuật thực tế.
SWE-Bench Pro tập trung vào năng lực kỹ thuật phần mềm, yêu cầu mô hình xác định và sửa lỗi Bug trong các kho mã nguồn thực tế. Theo dữ liệu được công bố từ bảng điều khiển của Sakana AI, Fugu Ultra đạt 73.7 điểm trên SWE-Bench Pro. Để so sánh, Claude Opus 4.8 đạt 69.2 điểm, GPT-5.5 là 58.6, Gemini 3.1 Pro là 54.2. Trong một bài kiểm tra khác về khả năng thao tác hệ thống, TerminalBench 2.1, Fugu Ultra đạt 82.1 điểm, vượt qua GPT-5.5 (78.2) và Opus 4.8 (74.6). Hai bài kiểm tra này không chỉ đánh giá khả năng tạo mã của mô hình, mà còn đánh giá tính ổn định logic và khả năng gọi công cụ trong các nhiệm vụ đa bước, chuỗi dài. Sự dẫn đầu của Fugu Ultra có nghĩa là khi xử lý các vấn đề kỹ thuật phức tạp, nó ít xảy ra tình trạng sụp đổ giữa chừng hoặc lệch mục tiêu hơn so với các mô hình đơn lẻ.
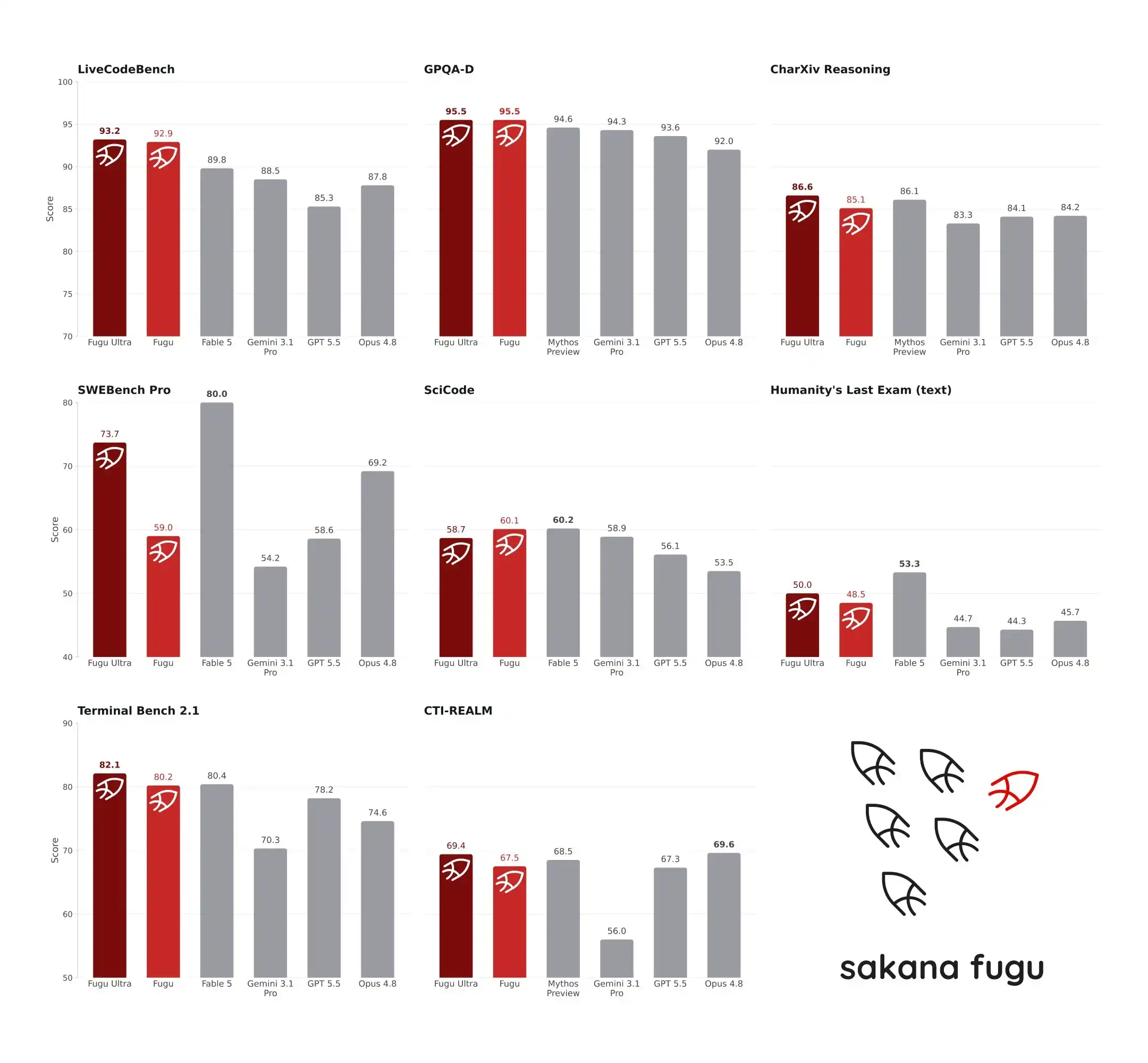
Đáng chú ý hơn là sự so sánh giữa Fugu với Fable 5 và Mythos Preview. Dòng Fable của Anthropic và dòng Mythos của một phòng thí nghiệm tiên phong khác đại diện cho trình độ đỉnh cao hiện tại về năng lực suy luận AI. Tuy nhiên, do bị kiểm soát xuất khẩu hoặc chưa được công khai hoàn toàn, hai mô hình này đã không tham gia vào nhóm tác nhân thông minh của Fugu. Sakana AI chính thức tuyên bố Fugu Ultra "sánh ngang" với Fable 5 và Mythos Preview trong các tiêu chuẩn kỹ thuật và khoa học, nhưng phải làm rõ rằng, so sánh này không phải là thử nghiệm thực tế cùng nhóm. Điểm số của Fugu dựa trên kết quả chạy thực tế của chính hệ thống nó, trong khi dữ liệu của Fable và Mythos dựa trên điểm số báo cáo công khai từ các nhà sản xuất tương ứng.
Cách so sánh này đã gây ra một số tranh cãi trong cộng đồng nhà phát triển. Có quan điểm cho rằng, điều kiện thử nghiệm của các hệ thống khác nhau trong các môi trường khác nhau khó có thể hoàn toàn đồng nhất, việc so sánh trực tiếp điểm số là không công bằng. Tuy nhiên, cũng có nhà phát triển chỉ ra rằng, trong điều kiện thiếu môi trường thử nghiệm thực tế thống nhất, việc tham khảo dữ liệu báo cáo của nhà sản xuất là thông lệ ngành. Bỏ qua tranh cãi với Fable và Mythos, việc Fugu Ultra vượt qua GPT-5.5 và Opus 4.8 trên SWE-Bench Pro và TerminalBench 2.1 là một so sánh trực tiếp trong cùng điều kiện. Sự vượt trội này không phải vì mô hình cơ bản của Fugu thông minh hơn GPT-5.5, mà vì RL Conductor thực hiện phân tích nhiệm vụ và điều phối chuyên gia chính xác hơn. Trong các thí nghiệm cần nhiều vòng suy luận và xác minh như AutoResearch, giải khối Rubik, thiết kế cơ khí, Fugu cũng liên tục thể hiện lợi thế. Điều này cho thấy khi xử lý các quy trình công việc thực tế "dài, hỗn loạn, đa bước", kiến trúc điều phối đa tác nhân thông minh thực sự linh hoạt hơn so với mô hình đơn lẻ.
Thử Nghiệm Thực Tế Trong Cảnh Phát Triển: Kiểm Tra Mã Và Tính Ổn Định Phiên Làm Việc Dài
Đối với các nhà phát triển và người dùng công cụ AI, điểm số chỉ là tham khảo, điều thực sự quyết định một mô hình có tốt hay không là hiệu suất của nó trong các tình huống làm việc thực tế. Fugu đã trải qua thử nghiệm Beta với gần 500 người dùng sớm trước khi phát hành, phản hồi của những người dùng này đã tiết lộ giá trị độc đáo của Fugu trong ứng dụng thực tế.
Kiểm tra mã là một trong những tình huống sử dụng AI phổ biến nhất của nhà phát triển. Các mô hình đơn lẻ truyền thống khi kiểm tra mã thường chỉ có thể phát hiện lỗi cú pháp bề mặt hoặc các lỗ hổng logic thông thường. Trong thử nghiệm Beta, có nhà phát triển phản hồi rằng Fugu thể hiện sự tỉ mỉ bất thường trong kiểm tra mã, có thể tìm ra lỗi kiến trúc sâu, trong khi các công cụ khác thường chỉ tìm được một số ít vấn đề bề mặt. Sự khác biệt này bắt nguồn từ kiến trúc của Fugu. Khi nhận nhiệm vụ kiểm tra mã, RL Conductor có thể lần lượt gọi các mô hình giỏi phân tích tĩnh, mô hình giỏi suy luận logic và mô hình giỏi kiểm tra an ninh để xác minh chéo cùng một đoạn mã từ nhiều góc độ. Mô hình "hội chẩn chuyên gia" này tự nhiên có thể phát hiện nhiều vấn đề ẩn hơn so với "đơn thương độc mã" của một mô hình duy nhất.
Một lợi thế khác được nhắc đến nhiều là tính ổn định phiên làm việc dài. Khi xây dựng sản phẩm AI Agent, một trong những vấn đề đau đầu nhất của nhà phát triển là "trôi tính cách" của mô hình trong các phiên làm việc dài. Khi số lượng vòng đối thoại tăng lên, mô hình đơn lẻ thường quên thiết lập ban đầu hoặc có sai lệch trong việc tuân theo chỉ dẫn. Một giám đốc điều hành doanh nghiệp sau khi thử nghiệm đã phản hồi rằng Persona (tính cách) của Fugu trong phiên làm việc dài cực kỳ ổn định, hầu như không xảy ra trôi. Điều này là do bản thân RL Conductor không chịu trách nhiệm duy trì bộ nhớ văn bản dài, nó chỉ chịu trách nhiệm trong mỗi vòng đối thoại, dựa trên ngữ cảnh hiện tại, chọn chính xác mô hình cơ bản phù hợp nhất để tạo phản hồi. Kiến trúc "tách biệt điều khiển và tạo" này đã nâng cao đáng kể tính ổn định của Agent trong thời gian chạy dài.
Trong lĩnh vực an ninh mạng, Fugu cũng thể hiện năng lực thực chiến đầu cuối. Trong thử nghiệm, Fugu có thể hoàn thành độc lập toàn bộ quy trình từ trinh sát, phát hiện lỗ hổng XSS/SQLi đến kiểm tra xác thực, và tạo báo cáo kiểm tra thâm nhập hoàn chỉnh, đồng thời tuân thủ nghiêm ngặt chỉ dẫn không vượt quá giới hạn phá hủy hệ thống. Mức độ hoàn thành nhiệm vụ phức tạp này phụ thuộc vào việc RL Conductor sắp xếp chính xác chuỗi công cụ bảo mật và khả năng của các mô hình lớn khác nhau.
Ngoài ra, hiệu quả Token cũng là một điểm sáng lớn của Fugu. Các mô hình lớn truyền thống khi xử lý vấn đề phức tạp thường tạo ra chuỗi suy nghĩ dài dòng, tiêu thụ lượng lớn Token. RL Conductor của Fugu thông qua định tuyến chính xác, tránh được việc tiêu hao CoT dài vô nghĩa. Hiển thị chính thức và thử nghiệm sớm cho thấy nó có thể giảm đáng kể lãng phí Token vô hiệu. Đối với các nhà phát triển tính phí theo Token, điều này không chỉ có nghĩa là giảm chi phí, mà còn có nghĩa là cải thiện tốc độ phản hồi.
Điểm Yếu Phụ Thuộc Nền Tảng: Cái Giá Của Điều Phối Đa Tác Nhân Thông Minh
Mặc dù Fugu thể hiện xuất sắc về kiến trúc và điểm số, nhưng với tư cách là một công cụ hướng đến công việc thực tế, nó không phải không có điểm yếu. Kiến trúc điều phối đa tác nhân thông minh mang lại đột phá về hiệu suất đồng thời cũng mang lại những rủi ro và hạn chế không thể bỏ qua.
Vấn đề cốt lõi nhất là rủi ro phụ thuộc nền tảng. Nhóm tác nhân thông minh của Fugu phụ thuộc cao vào các API nền tảng của các hãng lớn Mỹ như GPT, Claude, Gemini. Mặc dù RL Conductor có khả năng định tuyến động, có thể chuyển sang các mô hình khác khi một mô hình nào đó gặp sự cố hoặc bị giới hạn lưu lượng, nhưng điều này chỉ tránh được rủi ro từ một nhà cung cấp duy nhất, và không thể cũng không thoát khỏi toàn bộ hệ sinh thái cơ sở hạ tầng AI của Mỹ. Nếu các mô hình nền tảng này đồng loạt tăng giá, giới hạn lưu lượng quy mô lớn hoặc thay đổi điều khoản API, cấu trúc chi phí và tính ổn định của Fugu sẽ bị ảnh hưởng trực tiếp. Mô hình "ký sinh" trên cơ sở hạ tầng của người khác này có sự mong manh tự nhiên về mặt thương mại hóa và ổn định lâu dài.
Thứ hai là sự đánh đổi giữa độ trễ và cấu trúc chi phí. Mặc dù RL Conductor tiết kiệm tiêu hao Token vô hiệu thông qua định tuyến chính xác, nhưng điều phối đa tác nhân thông minh chắc chắn liên quan đến nhiều lần gọi API và giao tiếp giữa các mô hình. Đối với các tình huống tương tác thời gian thực yêu cầu độ trễ cực thấp, như đối thoại giọng nói thời gian thực hoặc hỗ trợ giao dịch tần suất cao, thời gian "suy nghĩ sâu và điều phối" của Fugu Ultra có thể dài hơn so với việc gọi trực tiếp mô hình đơn lẻ. Trong những tình huống yêu cầu tốc độ phản hồi cực cao, lợi thế kiến trúc của Fugu ngược lại có thể trở thành gánh nặng cho trải nghiệm.
Ngoài ra, tranh cãi về tính công bằng so sánh vẫn luôn tồn tại. Như đã nói, Fugu tuyên bố sánh ngang Fable và Mythos, nhưng hai mô hình sau không tham gia vào nhóm tác nhân thông minh của Fugu. Trong cộng đồng nhà phát triển, có ý kiến nghi ngờ liệu so sánh dựa trên dữ liệu báo cáo của nhà sản xuất như vậy có giá trị tham khảo thực tế hay không. Rốt cuộc, hiệu suất của các mô hình khác nhau trong các phân phối nhiệm vụ khác nhau rất khác biệt, so sánh tổng điểm đơn giản có thể che giấu ưu thế và nhược điểm cụ thể. Đối với các nhà phát triển cần đánh giá chính xác năng lực mô hình, việc thiếu dữ liệu thử nghiệm thực tế cùng nhóm có nghĩa là vẫn cần thận trọng khi lựa chọn.
Không Đua Sức Tính Toán, Đua Sắp Xếp Chỉ Huy: Sự Đột Phá Bất Đối Xứng Của Mô Hình Lớn Nhật Bản
Vượt ra ngoài đánh giá sản phẩm cụ thể, sự ra đời của Fugu có ý nghĩa sâu sắc hơn đối với hệ sinh thái mô hình lớn của Nhật Bản. Trong cuộc chạy đua vũ trang AI toàn cầu, Nhật Bản ở một vị trí khó xử. Nước này vừa không có nguồn năng lực tính toán đỉnh cao liên tục và tích lũy thuật toán tiên phong như Mỹ, vừa không có bể dữ liệu khổng lồ và môi trường cạnh tranh thị trường khốc liệt như Trung Quốc. Nghiêm trọng hơn, Nhật Bản còn đối mặt với rủi ro kiểm soát xuất khẩu từ các mô hình tiên phong của Mỹ (như Fable/Mythos). Trong bối cảnh này, con đường "thuật toán tiến hóa" và "điều phối đa tác nhân thông minh" của Sakana AI thể hiện một logic "đột phá bất đối xứng" của một quốc gia bị hạn chế nguồn lực.
Trong nước Nhật Bản không phải không có các nhà sản xuất mô hình lớn. NTT đã ra mắt tsuzumi, các tổ chức như ELYZA, Rinna và LLM-jp cũng đang nỗ lực đào tạo mô hình ngôn ngữ nội địa. Nhưng hầu hết các nhà sản xuất này đi theo con đường truyền thống "đào tạo lại từ đầu", rất khó cạnh tranh với các mô hình đỉnh cao của Mỹ và Trung Quốc về quy mô tham số và năng lực tổng quát. Sakana AI là phòng thí nghiệm duy nhất có ảnh hưởng tiên phong toàn cầu và chủ đạo "kiến trúc bất đối xứng".
Về bản chất, khả năng định tuyến động của Fugu đang giúp các doanh nghiệp và tổ chức Nhật Bản thiết lập "chủ quyền AI" (AI Sovereignty). Trong điều kiện bị hạn chế về năng lực tính toán, thay vì tiêu tốn nhiều tiền để đào tạo một mô hình nghìn tỷ tham số mà mọi mặt đều không bằng GPT-5.5, thì hãy đào tạo một "chủ thầu" 7B thông minh. Chủ thầu này có thể linh hoạt kết nối với các mô hình tốt nhất toàn cầu dựa trên yêu cầu nhiệm vụ. Nếu một ngày nào đó một mô hình Mỹ bị kiểm soát xuất khẩu hoặc ngừng cung cấp, RL Conductor có thể nhanh chóng định tuyến nhiệm vụ đến các mô hình khả dụng khác, thậm chí kết nối với các mô hình chuyên dụng nội địa Nhật Bản. Kiến trúc này giúp Nhật Bản đạt được một mức độ tự chủ và khả năng chống chịu rủi ro nhất định trong việc sử dụng năng lực AI.
Khi quan sát hệ sinh thái công cụ AI toàn cầu, OmniTools nhận thấy rằng năng lực của các mô hình lớn đang dần được cân bằng, chiến trường cạnh tranh chính đang chuyển từ việc chất đống tham số đơn thuần sang chuỗi công cụ và cảnh ứng dụng thực tế. Sự xuất hiện của Fugu khẳng định xu hướng này. Nó không còn theo đuổi việc đạt đến cực điểm trên một mô hình duy nhất, mà theo đuổi việc tối ưu hóa ở cấp độ hệ thống. Cách suy nghĩ này có ý nghĩa tham khảo quan trọng đối với các quốc gia và khu vực không chiếm ưu thế về năng lực tính toán và dữ liệu.
Tất nhiên, "đột phá bất đối xứng" này cũng có trần của nó. Chừng nào công nghệ cốt lõi của các mô hình nền tảng vẫn nằm trong tay một số ít ông lớn, giới hạn trên về năng lực của hệ thống điều phối sẽ bị giới hạn bởi các mô hình nền tảng. Fugu đã chứng minh rằng mô hình 7B có thể trở thành chỉ huy xuất sắc, nhưng nó không thể tạo ra khả năng mà mô hình nền tảng không có. Để thực sự đột phá, mô hình lớn Nhật Bản ngoài việc đổi mới kiến trúc điều phối, vẫn cần tiếp tục đầu tư vào năng lực tính toán cốt lõi, thuật toán then chốt và dữ liệu chất lượng cao. Fugu là một đổi mới tinh tế ở cấp độ hệ thống, nhưng nó không phải là thuốc chữa bách bệnh. Đối với các nhà phát triển và người dùng doanh nghiệp, Fugu cung cấp một lựa chọn mới cực kỳ cạnh tranh trong các tình huống kỹ thuật phức tạp, nhưng khi sử dụng, cũng cần nhận thức rõ ràng về sự mong manh của sự phụ thuộc nền tảng và sự đánh đổi về chi phí độ trễ.








