Văn | Tượng Tiên Chí
Luo Fuli đăng một bài trên X, muốn đặt dấu chấm hết cho tranh cãi giảm giá của Xiaomi MiMo.
Ngày 26 tháng 5, tài khoản chính thức Xiaomi MiMo đã đăng một thông báo trên X: API dòng MiMo-V2.5 giảm giá vĩnh viễn, mức giảm cao nhất 99%. Tất cả các độ dài context đều được định giá thống nhất, gói Token nâng cấp lên 5-8 lần.
Thông báo này đã làm xôn xao cộng đồng AI trong nước suốt cả tuần. Phản ứng đầu tiên của giới công nghiệp được chia thành vài luồng. Luồng lớn nhất cho rằng đây là "một đợt chiến tranh giá cả nữa" - hai năm nay từ ZhiPu, DeepSeek, Byte DouBao đến Alibaba Tongyi, các mô hình lớn trong nước lần lượt giảm giá, ai cũng đang trong cuộc cạnh tranh.
Một luồng khác nhìn nhận theo hướng bi quan: Xiaomi vừa thông báo lợi nhuận năm nay giảm một nửa, lúc này vẫn đốt 600 tỷ cho AI, API trực tiếp cắt giảm 90% - điển hình của "lỗ vốn để chiếm thị trường". Còn có người cho rằng đây là hiệu ứng DeepSeek tiếp tục - người sau này đã kéo mức giá chuẩn của cả ngành xuống sàn, ai không theo sẽ bị loại.
Vì vậy với tư cách là người phụ trách MiMo, Luo Fuli tối qua đã công khai một bài blog kỹ thuật dài 5000 chữ, đưa bảng kế hoạch kỹ thuật giảm giá ra cho mọi người xem.
"Nhìn đây, đây là năng lực kỹ thuật thực sự, không phải là thủ đoạn marketing".
Để hiểu Luo Fuli đang nói gì, trước hết phải hiểu 99% này thực chất đang giảm cái gì.
Nó không phải giảm giá toàn bộ mô hình. Mức chiết khấu 99% đặc biệt nhắm vào một mức định giá gọi là Input (Cache Hit) - tức là phần "người dùng đọc lại lịch sử context trong cuộc hội thoại dài". Mức giảm cho input mới thông thường (No Cache Hit) nhỏ hơn nhiều, và mức giảm cho output của mô hình (Output) là nhỏ nhất.
Nếu bạn hình dung mô hình như một quán cà phê, thì sự việc này sẽ dễ hiểu hơn.
Bạn gọi một ly latte ít đường, quán cà phê có hai cách làm: mỗi lần đều xay hạt đong siro đổ sữa từ đầu, nguyên liệu nhân công đều phải trả một lần; nhưng mô hình biết tuần này bạn ngày nào cũng uống ly latte ít đường giống nhau, nên làm sẵn một ấm lớn bỏ vào tủ lạnh, lần sau múc một phần. Việc MiMo lần này làm là cách thứ hai - chuyển phần người dùng đọc lặp lại từ "tính toán lại" thành "lấy ngay", vì vậy chi phí thực tế của phần này gần bằng 0, tự nhiên có thể cho chiết khấu 99%.
Để làm được "lấy ngay", bài blog kỹ thuật đã nói đến sáu công trình, mỗi cái đều không thể thiếu. Dưới đây sẽ phân tích từng cái một.
Công trình một: Nén "ký ức" của mô hình xuống 1/7
Khi mô hình đối thoại với bạn, mỗi token đều phải tính một "trạng thái trung gian", lưu lại để bước tiếp theo sử dụng. Thứ này gọi là KVCache - có thể hiểu là "sổ tay ký ức ngắn hạn" của mô hình. Mỗi khi nói một câu, mô hình ghi chú tóm tắt câu này vào sổ tay, lần sau trực tiếp lật sổ ra xem, không cần nghe lại tất cả nội dung bạn đã nói từ đầu.
Mô hình truyền thống mỗi tầng đều làm "Full Attention" - tức là mỗi token đều phải xem toàn bộ tất cả token của đoạn hội thoại, sổ tay càng lật càng dày. MiMo-V2.5-Pro đã thay đổi kiến trúc: Trong 70 tầng, 60 tầng chỉ xem 128 token gần nhất (SWA, Sliding Window Attention), chỉ có 10 tầng "quản lý hồ sơ" xem toàn bộ.
Kết quả là thể tích KVCache trực tiếp bị nén xuống còn 1/7 của Full Attention, lượng tính toán cũng là 1/7.
Đây là nền móng đầu tiên của việc giảm chi phí. Ví dụ, ban đầu công ty yêu cầu mỗi nhân viên phải nhớ tất cả biên bản cuộc họp, kết quả là não của mỗi người đều không đủ dùng, hiệu suất cũng thấp. Quy định mới giảm gánh nặng não bộ của 60 nhân viên xuống còn 1/7, chỉ giữ lại 10 quản lý hồ sơ quản lý toàn bộ lịch sử - khả năng ghi nhớ tổng thể của công ty không giảm, nhưng hiệu suất tăng 7 lần.
Công trình hai: Để không gian tiết kiệm được từ SWA thực sự có thể sử dụng
Về kiến trúc, nén sổ tay xuống 1/7 là bước đầu tiên, nhưng để "1/7 trên lý thuyết" thực sự trở thành "1/7 thực tế", còn một trở ngại.
Hệ thống KVCache truyền thống phân bổ bộ nhớ cho tất cả các tầng thống nhất theo "lượng dùng tối đa có thể". Ý nghĩa là: dù 60 tầng SWA chỉ cần cuốn sổ nhỏ, hệ thống cũng phân bổ cho tất cả các tầng theo "cuốn sổ lớn của quản lý hồ sơ" - không gian tiết kiệm được của SWA bị dự trữ lãng phí, bằng như không tiết kiệm.
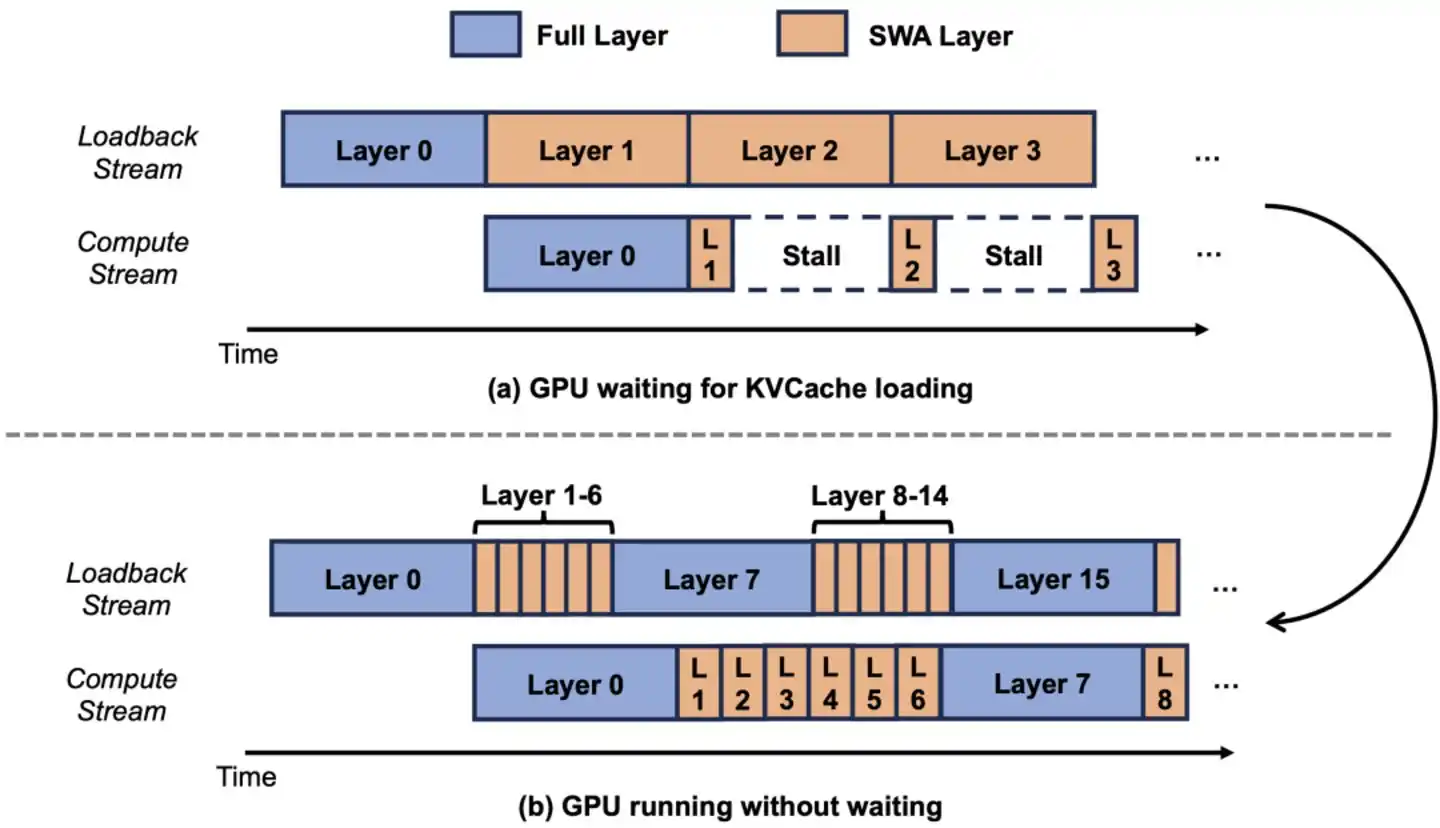
Cách làm của đội ngũ Luo Fuli là chia KVCache thành hai pool độc lập. 10 tầng Full Attention đi "pool lớn", phân bổ theo độ dài đầy đủ; 60 tầng SWA đi "pool nhỏ", chỉ phân bổ theo cửa sổ 128 token.
Ví dụ, ban đầu công ty phát cho mỗi nhân viên một "tủ hồ sơ có thể chứa tài liệu 100 năm" - nhưng 60 nhân viên thực ra chỉ cần "tủ nhỏ chứa tài liệu một tuần", 99% không gian trong những tủ lớn đó trống rỗng. Cách làm mới là phân tủ theo nhu cầu thực tế. Kết quả là cả văn phòng có thể chứa thêm hơn 5 lần đồng nghiệp vào làm việc - cùng một GPU có thể phục vụ số người dùng đồng thời tăng gấp 5 lần.
Bước này nhìn có vẻ đơn giản, nhưng không có nó, ưu thế thiết kế kiến trúc SWA phía trước bằng như thiết kế vô ích.
Công trình ba: Để "người dùng cũ đọc lại" thực sự có thể trúng cache
Sổ tay nén xuống 1/7 + không gian thực sự dùng được, bước tiếp theo phải giải quyết một vấn đề cũ: tỷ lệ trúng của cache tiền tố.
Nhiều cuộc hội thoại của người dùng có phần mở đầu giống nhau - cùng một đoạn system prompt, cùng một thư viện mã, cùng một tài liệu dài. Hệ thống sẽ lưu kết quả tính toán này lại, lần sau khớp được thì tái sử dụng trực tiếp. Cơ chế này gọi là cache tiền tố.
Nhưng trong chế độ SWA xuất hiện một cái hố: hai yêu cầu token giống nhau, không có nghĩa là KV vẫn còn. Có thể tiền tố đã tính toán, nhưng phần ngoài cửa sổ SWA đã sớm bị loại bỏ. Nếu hệ thống vẫn áp dụng quy tắc cũ "token giống nhau là trúng" để tái sử dụng cho bạn, sẽ đọc phải dữ liệu vô hiệu hoặc bị ghi đè, hiệu quả mô hình sẽ sụp đổ trực tiếp.
Đội ngũ Luo Fuli nâng cấp quy tắc lên "độ dài an toàn cửa sổ" - chỉ cam kết phần "bạn có thể mượn đầy đủ".
Ví dụ, thư viện có 1 triệu cuốn sách, bạn muốn mượn trọn bộ "Tam Thể" gồm ba cuốn. Kiến trúc ban đầu sẽ nói với bạn "cuốn sách này có", bạn chạy đến phát hiện trên giá chỉ còn bìa và tập một, hai tập sau đều bị mượn rồi. Loại "trúng giả" này khiến bạn chạy vô ích còn phải mượn lại. Quy tắc hệ thống mới đổi thành chỉ cam kết phần bạn có thể mượn đầy đủ - trước hết đưa bạn cuốn thứ nhất, sau đó lại điều hai cuốn sau cho bạn.
Nghe có vẻ nghiêm ngặt hơn, tỷ lệ trúng sẽ giảm. Nhưng thực tế ngược lại: vì SWA khiến thể tích KVCache nén xuống 1/7, cùng một không gian lưu trữ có thể chứa nội dung nhiều hơn gấp mấy lần, tỷ lệ trúng thực tế ngược lại tăng lên đáng kể.
Luo Fuli trong blog đã đưa ra số liệu thực tế trực tuyến: Dưới khung harness chủ lưu, tỷ lệ trúng cache phía máy chủ trung bình 93%, người dùng tần suất cao chu kỳ dài có thể đạt trên 95%.
Dịch ý nghĩa của con số này: 95% yêu cầu "đọc lại" căn bản không cần GPU tính toán, lấy trực tiếp từ cache. Đây chính là cơ sở vật lý của mức chiết khấu 99%.
Công trình bốn: Đưa "cache" vào SSD đi kèm GPU
Tỷ lệ trúng tăng lên, vấn đề tiếp theo là: những cache này được lưu ở đâu.
Bộ nhớ GPU (HBM memory trên GPU) rất đắt và hạn chế - một máy H100 tám card chỉ có 640GB bộ nhớ, nhưng KVCache mà MiMo cần lưu có thể là cấp độ hàng chục TB. Vì vậy phải phân tầng: dùng gần đây đặt vào bộ nhớ (L1), hơi cũ đặt vào bộ nhớ CPU (L2), dữ liệu lạnh lưu vào cache phân tán (L3).
Giống như bạn quản lý tiền vậy. Tiền mặt trong ví là bộ nhớ - dùng ngay lấy ngay nhưng không để được nhiều. Số dư thẻ ngân hàng là bộ nhớ CPU - lấy một lần mất 30 giây nhưng để được nhiều. Tiền gửi có kỳ hạn là cache phân tán L3 - lấy một lần mất 2 phút nhưng rẻ hơn nhiều.
Cách làm thông thường của ngành là xây dựng riêng một cụm lưu trữ cho L3, máy chuyên dụng, phòng máy chuyên dụng, tháng tháng trả tiền thuê.
Cách làm của đội ngũ lưu trữ Xiaomi khác. Họ tự nghiên cứu một bộ cache phân tán gọi là GCache, triển khai trực tiếp trên SSD đi kèm máy GPU - cùng phân bố chung trong một máy với nhiệm vụ huấn luyện, nhiệm vụ suy luận.
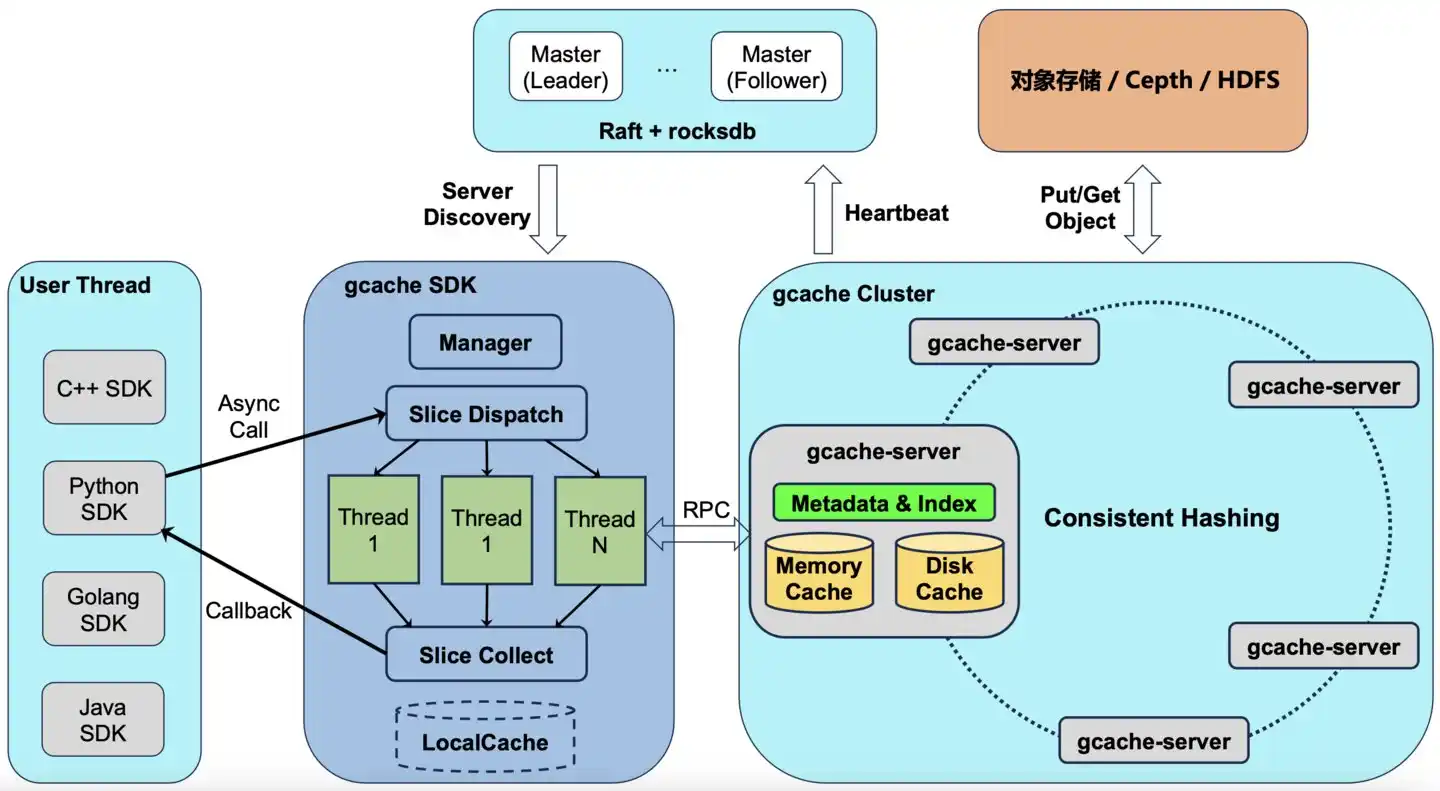
Dịch sang tiếng thông thường: người khác để lưu trữ lượng dữ liệu lớn, đã thuê riêng một nhà kho; Xiaomi phát hiện nhà để xe của máy GPU thực ra đang trống, trực tiếp lưu dữ liệu vào đó. Tiền thuê hàng tháng tiết kiệm được.
Nguyên văn trong blog kỹ thuật là: "Chi phí lưu trữ bổ sung là 0."
Sức sát thương của việc này lớn hơn vẻ ngoài. Trong "sổ sách tính toán năng lực" thông thường của "công ty AI", chi phí lưu trữ là một khoản chi cố định - mô hình của bạn càng lớn, người dùng càng nhiều, hóa đơn lưu trữ càng dài. Cách làm GCache này đánh bay mục này. Kết hợp với thể tích nhỏ SWA + tỷ lệ trúng 93-95%, thời gian tồn tại (TTL) của KVCache trong L3 kéo dài từ vài phút đến vài giờ thậm chí vài ngày - TTL càng dài, cửa sổ có thể trúng của context lịch sử càng rộng, tỷ lệ trúng cache càng cao, mức chiết khấu 99% đó càng đứng vững.
Công trình năm: Để yêu cầu trúng cache đi con đường ngắn nhất
Cache có thể chứa, có thể tra cứu, còn rẻ, bước cuối cùng là: làm thế nào để yêu cầu chính xác được định tuyến đến máy chính xác.
Xiaomi đã phát triển một hệ thống điều phối của riêng mình gọi là LLM-Router, làm ba việc:
Một là điều phối thân thiết. Các yêu cầu có tiền tố giống nhau được định tuyến đến cùng một máy, để tái sử dụng cache tối đa hóa.
Hai là phân nhóm theo độ dài. Chia yêu cầu ngắn (0-64K), yêu cầu trung bình (64K-256K), yêu cầu dài (256K-1M) vào các kênh xử lý khác nhau, tránh yêu cầu ngắn bị yêu cầu dài làm chậm.
Ba là tối ưu hóa TTFT. Trong hàng đợi chờ suy luận, ưu tiên điều phối các yêu cầu có lượng tính toán thực tế nhỏ (tức là các yêu cầu trúng cache nhiều) - tránh chúng bị các yêu cầu tính toán nặng kiểu "input hoàn toàn mới" làm tắc nghẽn.
Ví dụ, trong điều phối sân bay thông thường, tất cả hành khách bay cùng một điểm đến tập trung vào cùng một phòng chờ, chia sẻ quy trình lấy hành lý - đây là điều phối thân thiết. Người mang vali xách tay và người mang 3 vali ký gửi lớn đi hai lối an ninh khác nhau, người nhanh không bị người chậm làm chậm - đây là phân nhóm theo độ dài. Khi lên máy bay ưu tiên cho người chỉ mang vali xách tay, họ lên nhanh, để máy bay có thể cất cánh sớm - đây là tối ưu hóa TTFT.
Chiến lược điều phối này qua thực tế đã nâng tỷ lệ trúng cache L2 lên 25%, thông lượng input đơn máy tăng 30%, độ trễ P90 của yêu cầu dài giảm 30%.
Dịch lại tức là: cùng một GPU có thể phục vụ nhiều người dùng hơn. Nửa logic còn lại của việc giảm giá nằm ở đây - sản lượng hiệu quả trên đơn vị năng lực tính toán cao hơn, chi phí trên đơn vị người dùng thấp hơn.
Công trình sáu: Để mô hình "gõ chữ" cũng nhanh hơn
Năm việc phía trước đều tối ưu hóa phía "đọc" - giảm chi phí người dùng đọc lại context lịch sử xuống gần bằng 0. Việc thứ sáu là tối ưu hóa phía "viết" - tức là quá trình mô hình sinh token tiếp theo.
Mô hình truyền thống một lần chỉ có thể sinh 1 token. MiMo hỗ trợ nguyên bản 3 tầng MTP (Multi-Token Prediction) - một lần dự đoán 3 token tiếp theo, nếu dự đoán giữa chừng đúng, trực tiếp bỏ qua tính toán ở giữa.
Ví dụ, gõ chữ truyền thống là gõ từng chữ một - bạn muốn gõ "hôm nay thời tiết", phải nhấn 4 lần phím. MTP giống như có tính năng tự động bổ sung đoán chữ tiếp theo 1-2 chữ của bạn là gì - nếu nó đoán đúng, bạn không cần nhấn thêm hai lần đó nữa.
MTP của MiMo trong kịch bản agentic thực tế: giải mã 128 token đầu tiên tăng tốc 2.3 lần, 128-256 token tăng tốc 1.5 lần.
Ý nghĩa của việc này là, chiết khấu 99% đặc biệt hướng đến Input (Cache Hit), nhưng khi mô hình thực tế phục vụ người dùng, input và output xảy ra trong cùng một yêu cầu - nếu output không tiết kiệm, chi phí yêu cầu tổng thể chỉ tiết kiệm được một nửa. MTP khiến nửa output đó cũng giảm xuống, mô hình lợi nhuận của toàn bộ đợt giảm giá mới khép kín.
Nối sáu việc thành một chuỗi giảm chi phí:
Kiến trúc SWA → KVCache 1/7 → Hai pool thực sự giải phóng dung lượng → Cùng một GPU có thể chứa hơn 5 lần người dùng đồng thời → Tỷ lệ trúng cache tiền tố 93-95% → 95% yêu cầu hầu như không cần tính toán → GCache khiến chi phí lưu trữ về 0 → Điều phối ưu tiên điều chuyển yêu cầu trúng → MTP khiến việc sinh cũng tiết kiệm → Thời gian GPU trên đơn vị yêu cầu giảm một bậc độ lớn → Chi phí đơn vị giảm 95%+ → Định giá giảm 99%, tỷ suất lợi nhuận gộp vẫn dương.
Thiếu bất kỳ khâu nào, chuỗi này đều đứt ở một khúc nào đó. Giảm giá 99% không phải là con số marketing, là hiệu ứng tích lũy sau khi sáu trụ cột công trình chồng lên + xác minh thực tế trực tuyến.
Nhìn lại vài cách giải thích ban đầu của giới công nghiệp, mỗi cách đều có phần lý của nó. Hai năm nay cuộc chiến tranh giá cả giữa các công ty mô hình lớn Trung Quốc là thật; lợi nhuận Xiaomi giảm một nửa vẫn phải đổ tiền vào AI là thật; DeepSeek kéo mức giá chuẩn của ngành xuống sàn cũng là thật.
Nhưng lần này Luo Fili công khai blog kỹ thuật và phân tích chi tiết công nghệ một cách chi tiết, không nghi ngờ gì là hy vọng phản kích lại cách nói về chiến tranh giá cả, để "vấn đề kỹ thuật quy về kỹ thuật, vấn đề marketing quy về marketing."
Cô ấy đã viết trong blog, hiệu suất suy luận của dòng mô hình MiMo-V2.5 không đến từ đột phá đơn điểm của một khâu nào, mà là kết quả của tối ưu hóa phối hợp đa chiều. Hybrid SWA khiến prefill và decode cùng hưởng lợi, nhưng cách triển khai KVCache chưa được tối ưu hóa đầy đủ ngược lại sẽ đẩy cao chi phí ở các khâu. Xoay quanh mục tiêu này, đội ngũ MiMo đã xây dựng lại một cách có hệ thống quản lý KVCache, cache phân cấp, cây cache tiền tố, công phá vấn đề cốt lõi của SWA KVCache, tối ưu hóa chiến lược điều phối và liên kết Prefill / Decode, và thông qua kiểm tra kịch bản thực tế trực tuyến, cuối cùng biến ưu thế hiệu suất lý thuyết của nó thành hiện thực trong môi trường sản xuất. Đến lúc này, Hybrid SWA mới phát huy được ưu thế kiến trúc vừa có cường độ vừa có hiệu suất trong suy luận văn bản dài. Kết hợp với cấu hình MoE và các tối ưu hóa suy luận đa phương thức khác nhau, đã nâng cao hiệu suất dịch vụ suy luận trực tuyến ở mức độ rất lớn.
Đây là một cách đánh có hệ thống của kỹ thuật AI, cũng là phương tiện giảm chi phí đáng để ngành cùng tham khảo học hỏi.
Chiến tranh giá cả không cần viết blog, thực hiện công trình mới cần.





