Tác giả: AI Sản phẩm A Dĩnh
Tôi vừa đọc một bài blog của team Anthropic có tiêu đề "Bài học từ việc xây dựng Claude Code: Cách chúng tôi sử dụng Skill". Đây có lẽ là bài tổng kết thực tiễn sâu sắc nhất về Skill mà tôi từng thấy đến nay.
Skill thực ra không phức tạp, nhưng thực sự muốn làm tốt Skill, tôi nghĩ cũng không dễ dàng.
Tôi nhớ lúc Skill mới nổi, mọi người đặc biệt thích làm các Skill về phong cách viết, Skill viết lách. Hình như chỉ cần nhét phong cách viết của mình vào, mô hình sẽ có thể xuất kết quả ổn định theo phong cách đó.
Nhưng sau đó tôi tự mình thử một vòng, phát hiện nhiều lúc hoàn toàn không khả thi.
Bởi vì một Skill về phong cách viết có thể chứa vài nghìn thậm chí hàng chục nghìn chữ. Khi Skill được tải, ngữ cảnh đã chiếm mất một phần lớn. Ngữ cảnh một khi nặng, khả năng tư duy của mô hình lại dễ bị giảm xuống.
Cuối cùng thường xuất hiện một tình huống: phong cách thì học được, nhưng nội dung trở nên hời hợt, khả năng phân tích cũng yếu đi.
Lại còn một tình huống phổ biến khác.
Nhiều người khi viết Skill, thích nhét đủ loại hướng dẫn thao tác vào. Bước đầu tiên làm gì, bước hai làm gì, bước ba làm gì. Kết quả chạy thử sẽ phát hiện, việc thực thi của mô hình không ổn định.
Sau này tôi mới dần hiểu ra, rất nhiều công việc lặp đi lặp lại như vậy, thực ra phù hợp hơn khi kết tủa thành Script, chứ không phải viết thành Instructions dài dòng.
Sau khi đọc xong bài viết này của Anthropic, cảm nhận lớn nhất của tôi là, rất nhiều người thực ra đang dùng Skill, nhưng chưa chắc đã thực sự hiểu Skill.
Về bản chất, Skill đang làm Context Engineering (Kỹ thuật Ngữ cảnh). Khi nào nên đưa kiến thức vào Skill, khi nào nên tách thành References, khi nào nên viết thành Script, khi nào nên dùng Gotchas để ràng buộc mô hình, bên trong đó thực ra có rất nhiều kinh nghiệm.
Sau khi hiểu nguyên lý vận hành của Skill, nhìn lại những Skill xuất sắc đó, sẽ phát hiện chúng giải quyết không bao giờ là vấn đề của prompt (lời nhắc), mà là đang giải quyết vấn đề về ngữ cảnh, kết tủa kinh nghiệm và tái sử dụng năng lực.
Nếu mọi người muốn nghiên cứu sâu về Skill, đặc biệt đề xuất đọc hai bài viết:
https://claude.com/blog/lessons-from-building-claude-code-how-we-use-skills
https://research.perplexity.ai/articles/designing-refining-and-maintaining-agent-skills-at-perplexity
#01 Đừng viết những câu vô nghĩa
Về bản chất, Skill đang kết tủa "kiến thức ngầm" trong tổ chức. Vì vậy, trong Skill đừng lặp lại những kiến thức thông thường mà nó đã biết. Giá trị thực sự thực ra là những thông tin mà mô hình hoàn toàn không biết.
Nội bộ Anthropic thường nhấn mạnh, thứ thực sự cần viết trong Skill là Gotchas, tức là những cái bẫy thường gặp.
Ví dụ:
1. Bảng này không thể sắp xếp theo created_at
2. Staging trả về 200 không đại diện cho thành công
3. request_id và trace_id là một thứ
Bởi vì những thông tin này thường tồn tại trong kinh nghiệm của nhân viên. Vì vậy nhất định phải nhớ bản chất của Skill là gì.
Skill = Viết ra kinh nghiệm của người thợ lành nghề.
Thông qua Skill, kết tủa những kinh nghiệm vốn nằm rải rác trong đầu óc của những người khác nhau.
#02 Skill thực ra là Context Engineering
Đây có lẽ là một trong những quan điểm sâu sắc nhất của Anthropic.
Skill không phải là một file markdown, mà là một thư mục. Với người đã dùng Skill, câu này nghe giống như chuyện thừa.
Nhưng mấy ngày nay tôi suy đi nghĩ lại, dần nhận ra: họ chính là muốn dùng hình thức thư mục này để diễn đạt quan niệm về Context Engineering.
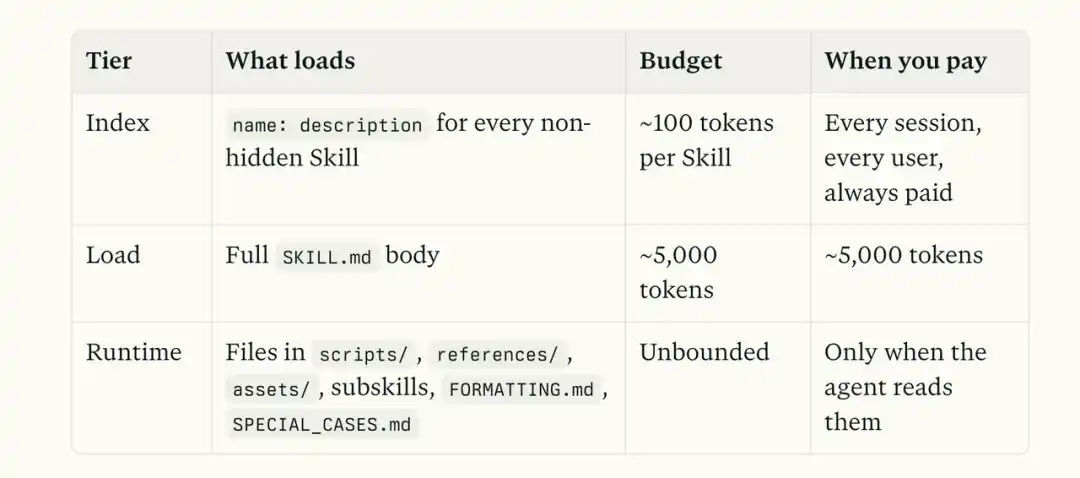
Chúng ta hãy xem lại cấu trúc Skill điển hình một lần nữa:
skill/ ├── SKILL.md ├── references/ chứa giải thích chi tiết, tham chiếu API, điều kiện biên ├── scripts/ chứa script có thể thực thi ├── examples/ chứa ví dụ ├── assets/ chứa template, hình ảnh, tài liệu cố định
Khi gọi một Skill nào đó, mô hình đầu tiên đọc là SKILL.md. Nếu chúng ta nhét tất cả thông tin vào file này, ngữ cảnh sẽ nhanh chóng bùng nổ.
Giả sử đây là một Skill xử lý sự cố thanh toán, bên trong có cả giải thích mã lỗi Stripe, cũng có các trường hợp sự cố lịch sử, còn có script kiểm tra và template báo cáo cuối cùng.
Nếu toàn bộ nội dung này chất đống vào SKILL.md, mỗi lần gọi Skill, Claude đều phải đọc lại từ đầu.
Cho dù người dùng chỉ muốn xác nhận ý nghĩa của một mã lỗi, cho dù chỉ muốn xem tại sao một trạng thái thanh toán nào đó không được cập nhật. Một lượng lớn thông tin hoàn toàn không dùng đến, cũng sẽ bị nhét chung vào ngữ cảnh.
Còn tư duy của Anthropic hoàn toàn khác.
SKILL.md giống một trang điều hướng hơn. Nhiệm vụ của nó là nói cho mô hình biết, khi gặp lỗi Stripe, hãy vào references tìm giải thích tương ứng.
Cần tham khảo trường hợp lịch sử, vào examples tra vấn đề tương tự, cần thực sự thực hiện thao tác kiểm tra, chạy script trong scripts, cuối cùng khi tạo báo cáo xử lý sự cố, lại sử dụng template trong assets.
Toàn bộ quá trình là sự tiếp xúc từ từ.
Bức hình dưới đây, mạnh mẽ đề nghị mọi người lưu lại.
#03 Cố gắng dùng script
Đừng để mô hình lãng phí ngữ cảnh và khả năng suy luận có hạn vào lao động lặp đi lặp lại. Hãy giao những việc này cho script.
Lấy ví dụ. Nhiều người khi viết Skill, sẽ viết như thế này:
1. Truy vấn dữ liệu đăng ký; 2. Truy vấn dữ liệu trả phí; 3. Tính tỷ lệ chuyển đổi; 4. Phân tích nguyên nhân bất thường.
Cách viết này tất nhiên không vấn đề gì. Mô hình cũng có thể hoàn thành. Nhưng mỗi lần thực thi, nó đều phải đi lại toàn bộ quy trình phân tích từ đầu.
Truy vấn dữ liệu, tổ chức dữ liệu, xử lý các tình huống biên giới khác nhau, những công việc này thực ra đều lặp lại.
Đã những khả năng này được kiểm chứng vô số lần. Tại sao lại để mô hình phát minh lại một lần nữa? Chi bằng cung cấp trực tiếp script cụ thể.
Hơn nữa thông qua cách thức script, việc thực thi Skill cũng sẽ chính xác hơn, cũng tiết kiệm Token hơn.
Từ góc độ này, Scripts trong Skill thực ra đang kết tủa năng lực tổ chức. Phía sau mỗi script, thường là phương pháp thực tiễn tốt nhất mà team đã tổng kết sau khi vấp vô số hố.
Sau khi cố định hóa những năng lực này lại. Mỗi lần Claude đều có thể đứng trên những kinh nghiệm này làm việc, thay vì từ con số không bắt đầu hết lần này đến lần khác.
Vì vậy tôi càng ngày càng cảm thấy, trong Skill, Instructions và Scripts giải quyết là vấn đề ở hai tầng khác nhau.
Instructions cung cấp là kinh nghiệm và phán đoán, Scripts cung cấp là năng lực và thực thi.
Lấy ví dụ, trong Skill xử lý sự cố thanh toán có thể có câu như vậy:
Nếu Stripe trả về 200, đừng trực tiếp cho rằng thanh toán thành công, cần kiểm tra thêm bảng payment_events.
Điều này thuộc về Instructions. Bởi vì đây là kinh nghiệm, còn check_payment_events() thuộc về Script, bởi vì đây là năng lực thực thi.
Nếu chỉ có Script, mô hình biết cách tra, nhưng chưa chắc biết tại sao tra.
Nếu chỉ có Instructions, mô hình biết nên tra. Nhưng mỗi lần đều phải thực hiện lại. Hai thứ thiếu một không được.
#04 Description giống một quy tắc định tuyến hơn
Cách nhiều người viết Skill Description bẩm sinh đã sai.
Bởi vì mọi người quen viết thành giới thiệu chức năng. Ví dụ: PR Management Skill giúp người dùng giám sát trạng thái PR, xử lý vấn đề CI, tự động hoàn thành Merge.
Nhưng vấn đề ở chỗ, mô hình không phải thông qua chức năng để tìm Skill, Claude Code khi khởi động, sẽ quét trước tên và Description của tất cả Skill.
Sau đó căn cứ vào vấn đề hiện tại của người dùng, phán đoán nên tải Skill nào.
Vì vậy thông tin quan trọng nhất trong Description, không phải là Skill này có thể làm gì, mà là trong tình huống nào nên tải nó.
Description thực ra đảm nhiệm công việc định tuyến của toàn bộ Skill.
Trong thế giới thực, rất ít người nói giúp tôi gọi một công cụ quản lý PR. Mọi người có khả năng hơn nói: giúp tôi để ý PR này, CI lại sập rồi đại loại.
Vì vậy một Description tốt, nên cố gắng miêu tả ý định của người dùng, chứ không phải liệt kê chức năng.
Tôi thậm chí cảm thấy có thể dùng một phương pháp đặc biệt đơn giản để kiểm tra.
Sau khi viết xong Description, xóa toàn bộ Skill, chỉ giữ lại dòng Description này. Sau đó tự hỏi: sau khi mô hình thấy vấn đề của người dùng, có biết khi nào nên tải Skill này không.
Nếu không làm được, khả năng lớn vẫn phải tiếp tục sửa.
#05 Quản lý và phân phối Skill
Còn một điều nữa là về quản lý Skill.
Một người dùng Skill, việc này thực ra rất đơn giản. Tự viết mấy Skill, tự bảo trì, tự nâng cấp là xong. Nhưng tôi tin đa số team sau này đều sẽ gặp phải cùng một vấn đề.
Khi Skill từ vài cái biến thành mấy chục, thậm chí mấy trăm cái, những Skill này nên quản lý thế nào? Nâng cấp thế nào? Phân phối cho thành viên team thế nào?
Kinh nghiệm của Anthropic ở phương diện này, tôi cảm thấy khá đáng tham khảo.
Khi quy mô team tương đối nhỏ, Skill đi trực tiếp theo kho mã. Đặt trong thư mục .claude/skills trong dự án là được. Mọi người chia sẻ cùng một bộ Skill, cũng chia sẻ cùng một phương pháp làm việc.
Nhưng cùng với số lượng Skill ngày càng nhiều, một vấn đề mới xuất hiện.
Claude Code khi khởi động, sẽ quét tên và Description của tất cả Skill, sau đó phán đoán nhiệm vụ hiện tại nên gọi Skill nào. Skill càng nhiều, chi phí định tuyến càng cao.
Đây cũng là lý do tại sao Anthropic sau này bắt đầu làm Marketplace. Nhưng thú vị hơn là, cách thức họ quản lý Marketplace.
Nhiều công ty gặp vấn đề kiểu này, phản ứng đầu tiên thường là thiết lập một quy trình phê duyệt. Ai viết Skill, trước tiên nộp đơn; sau khi thông qua kiểm duyệt, mới vào kho Skill chính thức. Nội bộ chúng tôi trước đây cũng làm vậy, nhưng rất nặng nề. Vì quản lý mà quản lý
Tôi phát hiện cách tổ chức của Anthropic rất nhẹ nhàng.
Để Skill mới trước tiên lan truyền trong phạm vi nhỏ, để đồng nghiệp tự cài đặt, tự thử dùng.
Nếu ngày càng nhiều người bắt đầu sử dụng, chứng tỏ Skill này thực sự giải quyết một vấn đề thực tế nào đó. Đến giai đoạn này, tác giả mới nộp lên Marketplace chính thức.
Vì vậy họ không bàn trước Skill có giá trị không, mà để nó tiếp nhận kiểm nghiệm của tình huống sử dụng thực tế trước, người dùng nhiều, tự nhiên sẽ vào hệ thống chính thức. Những Skill còn lại như vậy, cơ bản đều là Skill mà team thực sự cần.





