Nghiên cứu tự động hóa, lần này thực sự bước ra khỏi hộp cát mã nguồn, tiến vào thế giới vật lý thực tế.
Gần đây, Jim Fan, người đứng đầu phòng thí nghiệm NVIDIA GEAR, đã giới thiệu một dự án mới nhất có tên ENPIRE. Đây là lần đầu tiên họ thực hiện nghiên cứu tự động hóa trên phần cứng robot.
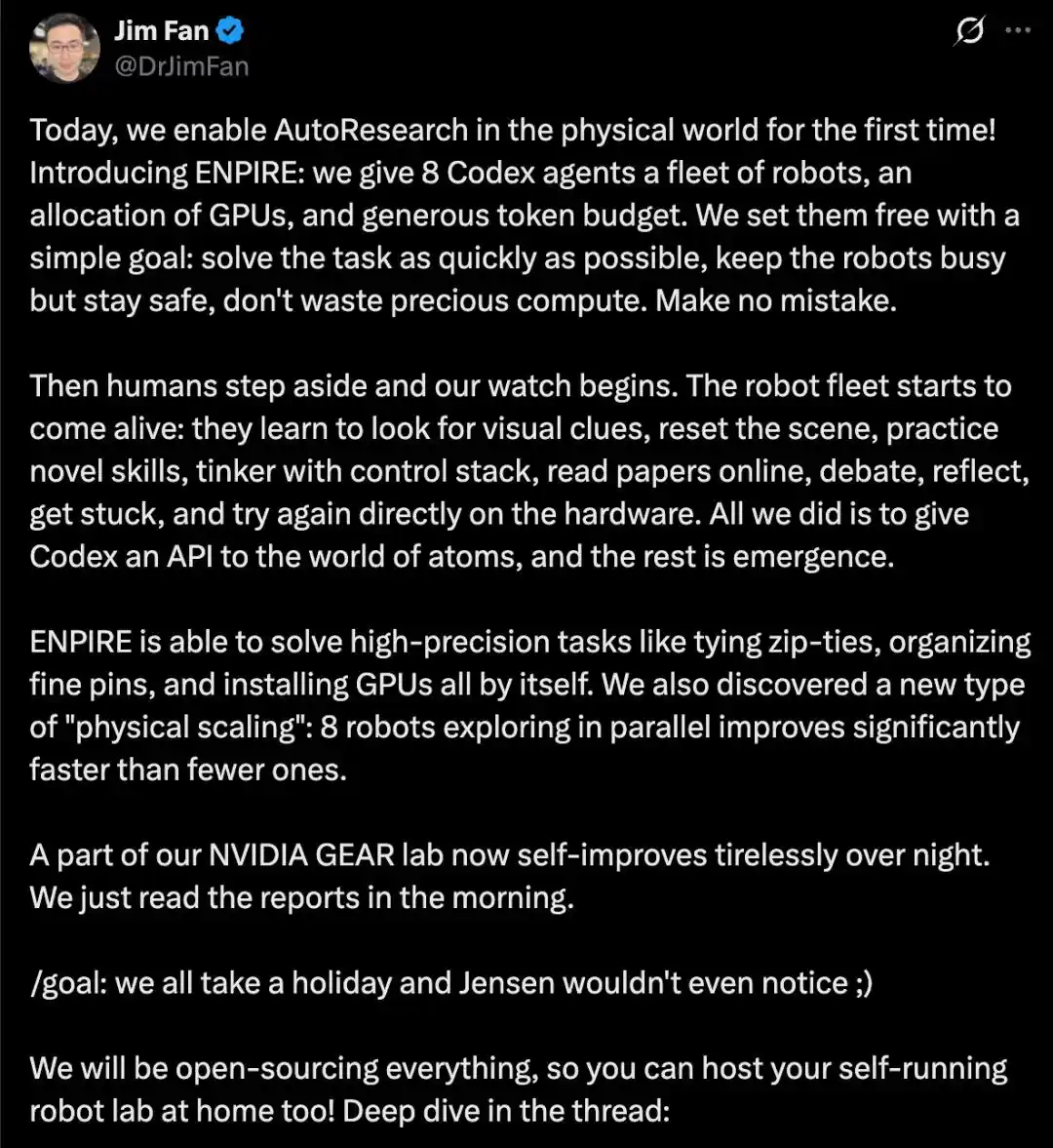
Họ đặt 8 Agent Codex vào một đội tàu robot, phân bổ sức mạnh tính toán GPU và ngân sách token dồi dào, chỉ đưa ra một mục tiêu đơn giản: giải quyết nhiệm vụ càng nhanh càng tốt, giữ cho robot luôn bận rộn nhưng đảm bảo an toàn, không lãng phí sức mạnh tính toán.
Sau đó, con người về cơ bản rút khỏi can thiệp. Agent tự chủ điều khiển toàn bộ vòng lặp khép kín, bao gồm tự động thiết lập lại cảnh, tìm kiếm tài liệu, hiện thực hóa ý tưởng và xây dựng cơ sở hạ tầng, đào tạo và triển khai chiến lược, tự xác minh, phân tích nhật ký và sửa mã, lặp đi lặp lại, cho đến khi hoàn thành một cách đáng tin cậy các nhiệm vụ khéo léo độ chính xác cao trên phần cứng thực, chẳng hạn như buộc dây rút, sắp xếp hộp đựng chốt cắm, lắp đặt GPU, v.v.
Họ cũng quan sát thấy một "định luật scaling vật lý": tăng số lượng robot song song (ví dụ: từ một ít lên 8 cái) có thể tăng tốc độ giải quyết nhiệm vụ một cách đáng kể.
Hiện tại, một số hệ thống của phòng thí nghiệm này đã đạt được sự lặp lại tự chủ qua đêm mà không có sự can thiệp của con người, nhà nghiên cứu chỉ cần xem báo cáo vào buổi sáng là đủ.
Jim Fan tuyên bố, mục tiêu trong tương lai là để các thành viên trong đội ngũ yên tâm nghỉ phép, thậm chí ngay cả CEO của NVIDIA Jensen Huang cũng không nhận ra phòng thí nghiệm vẫn đang tự chủ vận hành.
Dự án ENPIRE dự kiến sẽ hoàn toàn mã nguồn mở, lúc đó các nhà phát triển thông thường cũng có thể hy vọng xây dựng hệ thống nghiên cứu robot tự chủ tương tự tại nhà.

Địa chỉ dự án: https://research.nvidia.com/labs/gear/enpire/
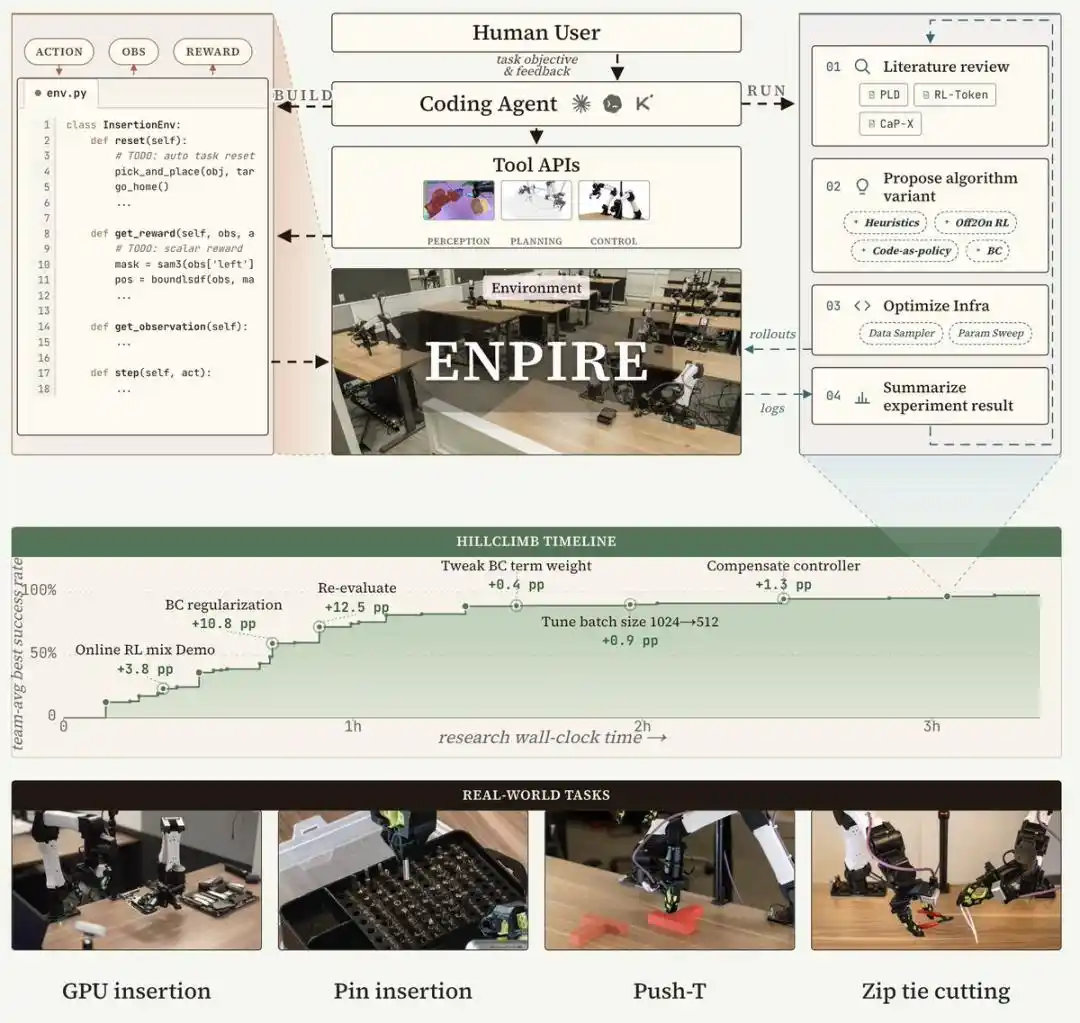
Kiến trúc hệ thống ENPIRE: Bốn mô-đun tạo thành vòng lặp khép kín
ENPIRE là một hệ thống khung được thiết kế dành riêng cho Agent mã hóa, xây dựng vòng phản hồi vật lý có thể lặp lại thông qua bốn mô-đun lõi: Mô-đun môi trường (EN) chịu trách nhiệm tự động thiết lập lại và xác minh, Mô-đun cải thiện chiến lược (PI) khởi động tối ưu hóa chiến lược, Mô-đun Rollout (R) hỗ trợ đánh giá chiến lược song song trên một hoặc nhiều robot, Mô-đun tiến hóa (E) thì để Agent mã hóa phân tích nhật ký, tra cứu tài liệu, cải thiện cơ sở hạ tầng đào tạo và mã thuật toán để giải quyết các mô hình thất bại.
Hệ thống vòng lặp khép kín này chuyển đổi việc học robot thế giới thực thành một quá trình tối ưu hóa có thể kiểm soát được, do Agent quản lý, nhằm giảm thiểu tối đa sự đầu tư thủ công, đồng thời hỗ trợ thực hiện các thí nghiệm ablation công bằng giữa các công thức đào tạo và biến thể Agent khác nhau.
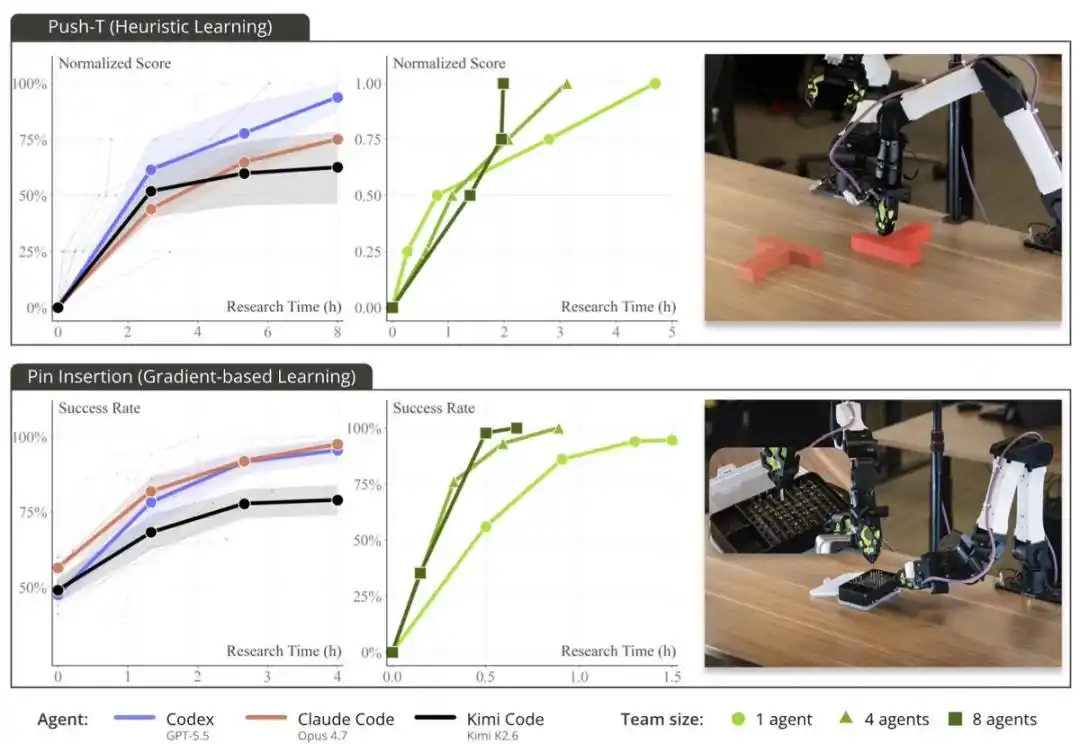
Với sự hỗ trợ của ENPIRE, các Agent lập trình tiên tiến có thể tự chủ phát triển chiến lược và đạt được tỷ lệ thành công 99% trong các nhiệm vụ thao tác khéo léo thế giới thực đầy thách thức như PushT, xếp chốt cắm vào hộp đựng chốt, sử dụng dao cắt để cắt dây rút, v.v.
Phát hiện then chốt: Thiết lập lại môi trường dễ hơn bản thân việc hoàn thành nhiệm vụ
Một trong những quan sát then chốt là: Đối với nhiều nhiệm vụ robot, việc thiết lập lại môi trường thường dễ dàng hơn chính việc hoàn thành nhiệm vụ.
Do đó, cách làm của ENPIRE là trước tiên để Agent xây dựng môi trường tự động thiết lập lại thông qua Chính-sách-như-Mã (Code-as-Policy). Trong nhiều trường hợp, cái gọi là thiết lập lại thực chất là một nhiệm vụ nhặt-và-đặt, có thể được giải quyết bởi Cap-X.
Sau đó, tác nhân thông minh sẽ viết hàm thưởng dựa trên quy tắc heuristic. Nhóm nghiên cứu sau đó đặt môi trường này vào hộp cát và khởi động Agent tiến hành nghiên cứu tự động hóa xoay quanh điểm số.
Điều này cũng tương đồng với định nghĩa của Karpathy về nghiên cứu tự động hóa: nghiên cứu tự động hóa được nói đến ở đây không phải là đơn giản điều chỉnh một siêu tham số hoặc sửa đổi một đoạn mã nhỏ. Agent sẽ khám phá các mô hình khác nhau từ internet và viết lại mọi phần có thể thúc đẩy hiệu suất, bao gồm thuật toán, mục tiêu đào tạo, thậm chí cả trình tải dữ liệu.
Trong nhiệm vụ xếp chốt cắm, một Agent thậm chí còn tự viết bộ điều khiển an toàn lực tiếp xúc, hiệu quả của nó vượt trội hơn so với việc chỉ đơn thuần điều chỉnh một số tham số học tăng cường.
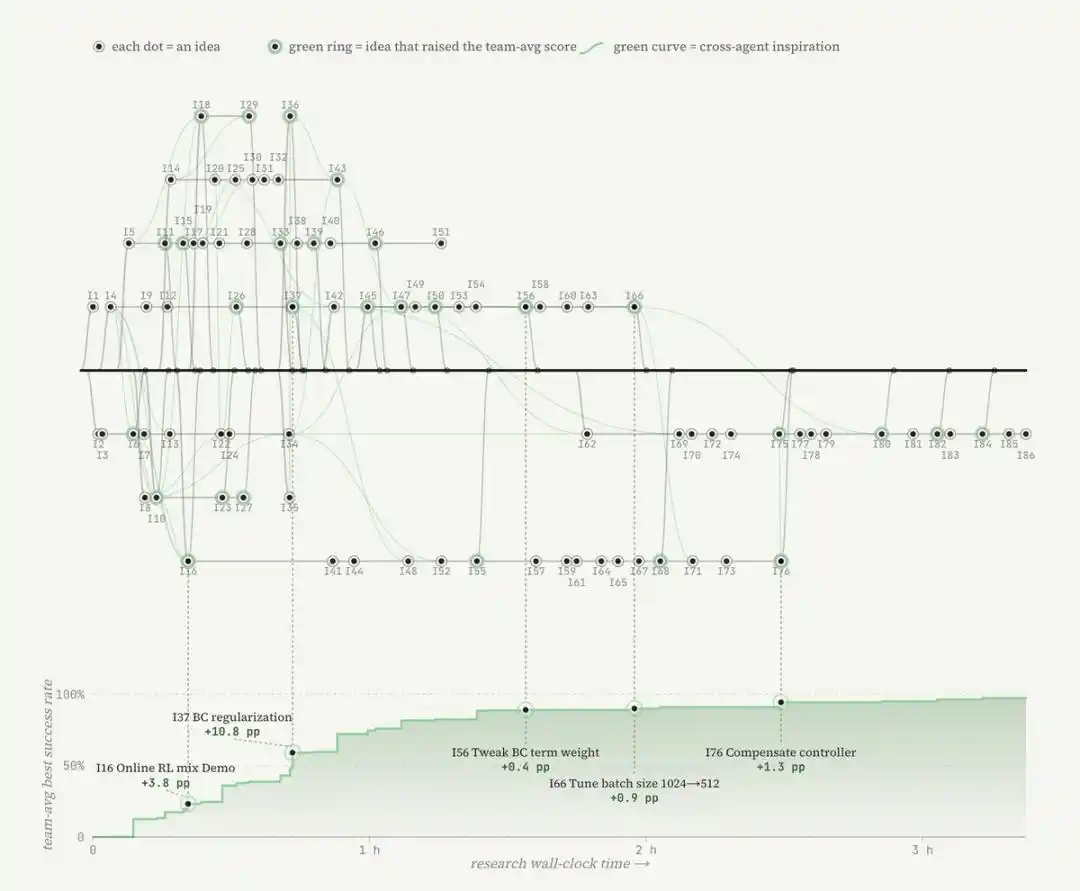
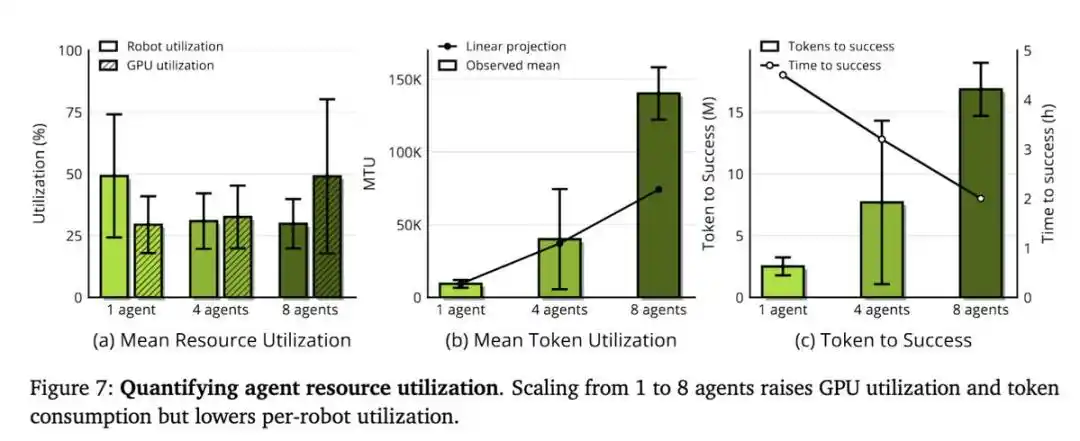
Chỉ số mới MRU và MTU
Khả năng mở rộng của ENPIRE phụ thuộc vào quy mô đội ngũ Agent và tài nguyên sức mạnh tính toán, chỉ có điều ở đây, tài nguyên thực sự khan hiếm không phải là GPU, mà là thời gian robot.
Khi nhóm nghiên cứu cung cấp cho Agent 8 robot, thay vì 1 robot, thời gian cần thiết để nhiệm vụ xếp chốt đạt được hiệu suất gần hoàn hảo đã giảm từ hơn 1,5 giờ xuống còn khoảng 40 phút. Các Agent này phối hợp thông qua Git: chia sẻ mã, từ bỏ ý tưởng không lý tưởng và tự chủ lựa chọn kết quả chạy tốt nhất của nhau.
Điều này chỉ ra một sự thay đổi lớn hơn: nghiên cứu robot đang trở thành một công việc thiết kế môi trường, tức là xây dựng môi trường mà coding Agent có thể tiến hành nghiên cứu tự động hóa trong đó; công việc thuật toán thì dịch chuyển lên một tầng cao hơn, chuyển hướng sang xây dựng một loại vòng phản hồi mà Agent có thể tự khép kín.
Và vòng lặp này sẽ liên tục tích lũy theo lãi kép: Một kỹ năng mà Agent nắm vững hôm nay, ngày mai sẽ trở thành mô-đun cơ sở để xây dựng và thiết lập lại môi trường nhiệm vụ khó khăn hơn. Năng lực sẽ tự sinh ra năng lực mới.
Trong mô hình này, ràng buộc cứng thực sự là ngân sách tương tác thế giới thực.
Do đó, nhóm nghiên cứu đã đề xuất hai chỉ số:
- Tỷ lệ sử dụng robot trung bình (Mean Robot Utilization, MRU): Tỷ lệ thời gian robot thực sự chạy thí nghiệm so với tổng thời gian thực tế tiêu thụ.
- Tỷ lệ sử dụng Token trung bình (Mean Token Utilization, MTU): Đo lường hiệu quả của Agent trong việc chuyển đổi token thành tiến triển nghiên cứu.
Trong thí nghiệm của họ, MRU luôn thấp hơn 50%. Nghĩa là, robot có một nửa thời gian ở trạng thái nhàn rỗi, đang chờ Agent suy nghĩ. Do đó, harness tốt hơn và mô hình nhanh hơn sẽ trực tiếp chuyển hóa thành lợi ích thực tế.
PushT là một điểm chuẩn thao tác robot đã được sử dụng từ lâu. Thông thường, để hoàn thành nhiệm vụ này cần một lượng lớn dữ liệu minh họa của con người, cộng với vài giờ đào tạo sao chép hành vi.
Nhưng họ nhận thấy, Codex, Claude Code và Kimi Code đều sử dụng một bộ phương pháp heuristic dựa trên quy tắc để "giải quyết" nhiệm vụ này trong vòng chưa đầy 2 giờ: không sử dụng mạng nơ-ron, không tiến hành đào tạo và cũng không dựa vào bất kỳ dữ liệu con người nào.
Để nhiều người hơn có thể thử nghiệm nghiên cứu tự động hóa trong thế giới vật lý tại nhà, họ đã phát triển một hệ thống full-stack dựa trên bộ kit SO-101 của @LeRobotHF + NVIDIA Jetson Thor. Hệ thống này có thể hoàn thành nhiệm vụ PushT.
Liên kết tham khảo:
https://x.com/_wenlixiao/status/2066913334994358342
https://x.com/DrJimFan/status/2066921736369766762
Bài viết này từ tài khoản WeChat công chúng "机器之心" (ID: almosthuman2014), tác giả: Dương Văn (杨文)