Có người reo mừng, đây là lần OpenAI "cởi mở nhất". Việc gắn ổ cắm cho Codex để có thể tùy ý thay đổi mô hình, đồng nghĩa với việc tự tay san bằng hào sâu bảo vệ của mô hình riêng họ. Họ tính toán điều gì?
Chỉ sau một đêm, Codex, tác nhân thông minh lập trình của OpenAI, không còn chỉ nhận diện GPT của riêng họ, mà đã mở cửa cho tất cả các mô hình nguồn mở.
Những người đầu tiên phát hiện ra tín hiệu này là cộng đồng nhà phát triển.
Một nhà phát triển đã tìm thấy trong cấu hình dòng lệnh (CLI) và bộ công cụ phát triển phần mềm (SDK) của Codex một chế độ nguồn mở lạ (OSS mode), mà chính thức cũng gọi là nhà cung cấp cục bộ (local providers).
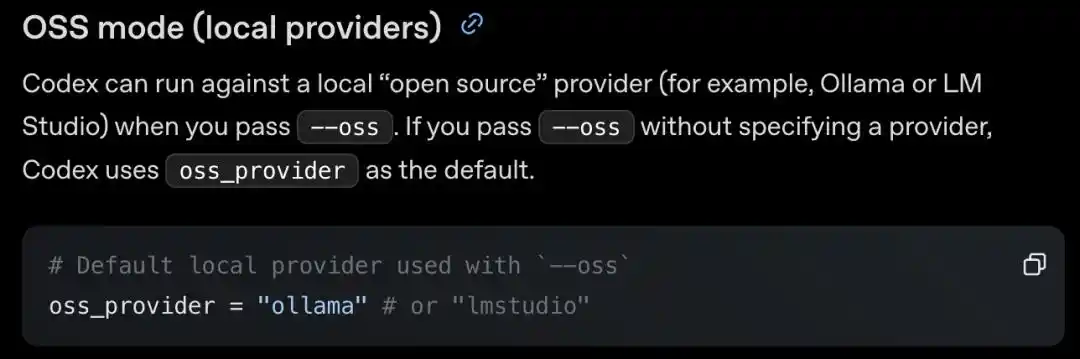
Chỉ cần thêm một --oss vào dòng lệnh, nó có thể chạy các mô hình nguồn mở ngay tại máy cục bộ; muốn kết nối mô hình khác, chỉ cần sửa một trường.
Cần biết rằng, OpenAI trong quá khứ gần như là đại diện của "mã nguồn đóng", Codex chỉ nhận diện GPT của chính OpenAI.
Nhưng bây giờ đã khác, chỉ với một dòng cấu hình, có thể chuyển sang các dịch vụ mô hình cục bộ như Ollama, LM Studio, v.v.
Sự việc này nhanh chóng gây chấn động trong giới nhà phát triển.
Trưởng nhóm Codex của OpenAI, Tibo, còn không quên nhắc nhở trực tiếp trên X:
Ứng dụng, CLI và SDK của Codex có thể kết hợp với bất kỳ mô hình nguồn mở nào để sử dụng, không phải chỉ dùng được với mô hình của riêng OpenAI.
Lời nhắc nhở này nhanh chóng được đồng sáng lập Hugging Face, Thomas Wolf, chuyển tiếp, và thêm một câu cảm thán: Hôm nay mới biết, trong Codex đã có thể dùng mô hình nguồn mở rồi.

Có cư dân mạng trực tiếp thốt lên, đây có thể là lần "cởi mở" nhất trong lịch sử của OpenAI, là một sự kiện vĩ đại.

Cộng đồng hành động còn nhanh hơn.
Tài liệu chính thức vừa ra, các nhà phát triển lập tức thử kết nối một số mô hình nguồn mở vào, còn thuận tay thảo luận về các phương án phối hợp tiết kiệm token hơn.
Nhưng cũng có người nhanh chóng vấp phải bức tường.
Nhà phát triển Filip Baturan muốn xây dựng một phương án hỗn hợp trong Codex: để GPT làm kế hoạch, sau đó để mô hình nguồn mở làm người thực thi.
Nhưng sau khi thử, anh phát hiện ra rằng Codex yêu cầu mô hình được kết nối vào cũng phải sử dụng cùng một giao thức gọi công cụ, mà mô hình nguồn mở chưa chắc đã có.
Một bên là tiếng reo hò "cởi mở nhất trong lịch sử", một bên là giao thức không thể kết nối.
Lần này, OpenAI thực sự đã cởi mở đến bước nào?
Các mô hình nguồn mở được kết nối vào Codex như thế nào?
Việc mở cửa Codex lần này của OpenAI, về bản chất không phải là mở chính mô hình, mà là mở "lớp kết nối mô hình".
Nói cách khác, họ không mở mô hình GPT, mà là thêm cho Codex một "lớp giao diện mô hình có thể cắm rút".
Khả năng này được hoàn thành thông qua một cấu hình gọi là nhà cung cấp mô hình (model_providers).
Nhà phát triển có thể đăng ký nhiều "nhà cung cấp mô hình" trong tệp cấu hình, mỗi nhà cung cấp chứa bốn loại thông tin:
Địa chỉ truy cập (base_url), giao thức truyền thông (wire_api), phương thức xác thực (env_key), và quan hệ ánh xạ mô hình (model).
Codex khi khởi động sẽ chọn nhà cung cấp mô hình tương ứng dựa trên cấu hình, từ đó định tuyến yêu cầu đến các dịch vụ mô hình khác nhau, bao gồm mô hình tự thân của OpenAI, mô hình Ollama cục bộ hoặc API của bên thứ ba như DeepSeek.
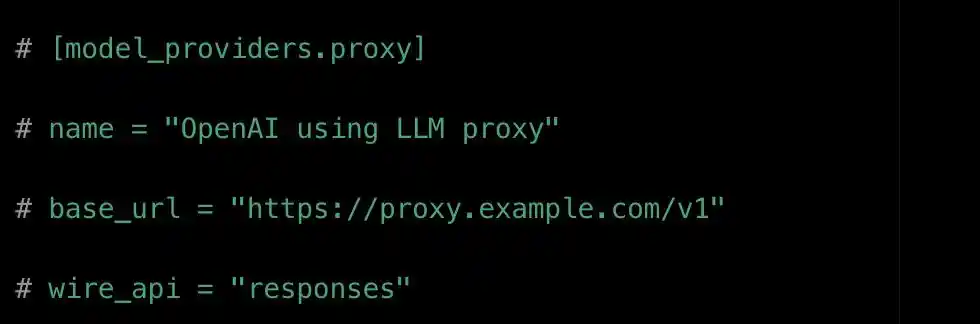
Ví dụ cấu hình model_providers của Codex. base_url là địa chỉ mô hình, còn trường giao thức wire_api chỉ nhận một giá trị là responses.
Mistral, proxy do doanh nghiệp tự xây dựng, trạm trung chuyển của bên thứ ba, đều có thể kết nối vào Codex theo cách này.
Có cư dân mạng tổng kết điểm nổi bật của khả năng này là: không bị ràng buộc bởi một nhà cung cấp, chuyển đổi theo nhu cầu, quyền riêng tư và chi phí do chính mình quyết định.
Tiện hơn nữa, bạn còn có thể lưu tất cả các thiết lập này thành "hồ sơ cấu hình", khi gỡ lỗi muốn dùng cái nào, chỉ cần nhấp vào tên của nó trong dòng lệnh là có thể chuyển đổi.
So với cấu hình thủ công ở trên, còn có một công tắc trực tiếp hơn: --oss. Thêm tham số này, Codex sẽ trực tiếp kết nối đến dịch vụ mô hình nguồn mở cục bộ.
Mặc định chỉ có hai cái này: Ollama và LM Studio. Cái trước là công cụ phổ biến nhất để chạy mô hình lớn cục bộ, cái sau là thay thế desktop với giao diện đồ họa.
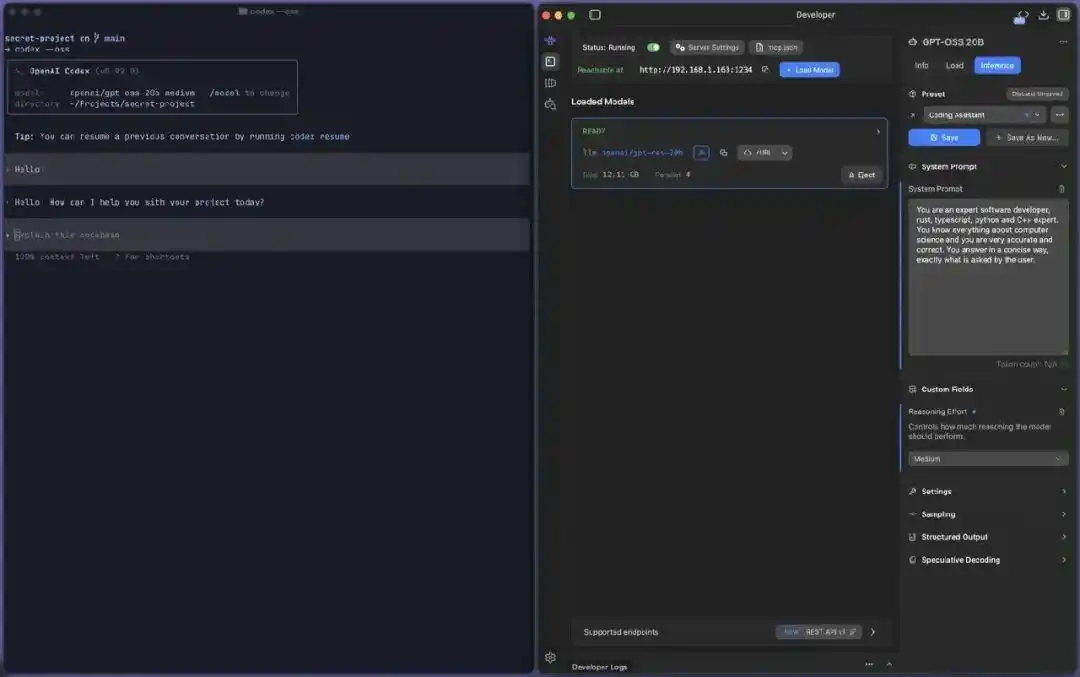
Ảnh chụp màn hình thực chiến Codex --oss kết nối mô hình cục bộ: Bên trái Codex CLI (v0.92.0) sử dụng --oss gọi mô hình cục bộ, bên phải LM Studio tải openai/gpt-oss-20b (12.11GB) trên cổng 1234 của máy này để cung cấp dịch vụ ra ngoài, toàn bộ quá trình đều cục bộ và ngoại tuyến.
Nói cách khác, thông qua dịch vụ mô hình cục bộ và cấu hình quyền mạng, bạn có thể để Codex hoàn thành việc tạo mã và suy luận ngay trên máy của mình, và ở một mức độ nhất định đạt được việc chạy ngoại tuyến và xử lý cục bộ.
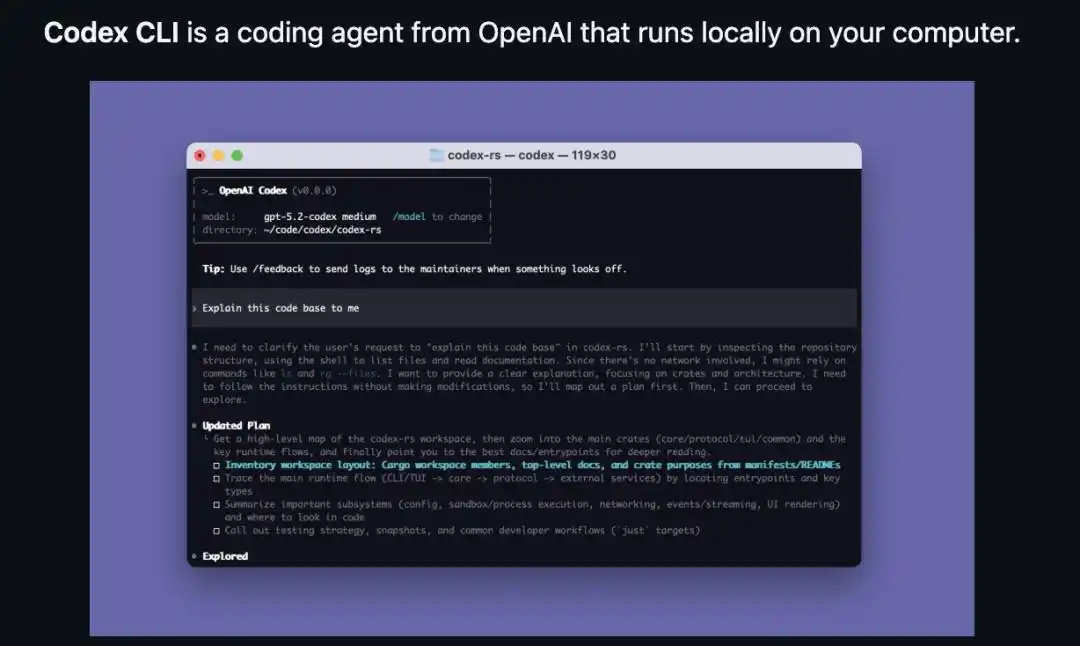
Giao diện Codex CLI: Trong thông tin khởi động, dòng model đánh dấu mô hình hiện tại (gpt-5.2-codex), phía sau theo là "/model to change", một câu lệnh có thể chuyển đổi mô hình, toàn bộ tác nhân thông minh chạy trên máy cục bộ.
Tuy nhiên, ổ cắm đã được lắp đặt không có nghĩa là thiết bị điện nào cắm vào cũng chạy.
Mô hình được kết nối vào, thường phải tương thích với định dạng giao diện Chat Completions; còn đối với các khả năng phức tạp hơn như function calling có thể chạy thông suốt hay không, phía chính thức không đảm bảo, phải thử từng cái một.
Cũng chính vì giao thức thường không khớp, cộng đồng còn phải tự viết công cụ định tuyến ở giữa để phiên dịch, và những cái này đều là giải pháp mà cộng đồng đã thử nghiệm ra, phía chính thức OpenAI hiện chưa ủng hộ cho điều này.
Khi GPT và mô hình nguồn mở kết hợp
Cùng làm việc trong Codex
Phía chính thức OpenAI vừa mở một khe cửa, phía cộng đồng đã chơi náo nhiệt.
Nguyên nhân rất đơn giản: Codex dễ dùng, nhưng sử dụng mô hình của OpenAI tính phí theo token, quá đắt.
Vì vậy, nhiều nhà phát triển đều hướng ánh mắt đến các mô hình nguồn mở.
DeepSeek là một trong những mô hình nguồn mở quen thuộc nhất với nhiều nhà phát triển tiếng Trung, một câu hỏi tự nhiên là: Codex có thể trực tiếp sử dụng DeepSeek không?
Câu trả lời mà CC Switch đưa ra là: có thể, nhưng không thể kết nối trực tiếp, cần thêm một lớp "trung chuyển".
Hướng dẫn cộng đồng CC Switch: "Chạy DeepSeek với định tuyến cục bộ trong Codex"
Hướng dẫn cộng đồng của họ "Chạy DeepSeek với định tuyến cục bộ trong Codex" chỉ ra rằng, nguyên nhân là do Codex phiên bản mới chủ yếu dựa trên Responses API của OpenAI, trong khi DeepSeek và hầu hết các giao diện mô hình nguồn mở vẫn lấy Chat Completions làm chính.
Hai bộ giao diện này không hoàn toàn nhất quán về cấu trúc yêu cầu, phương thức xuất luồng, và cơ chế gọi công cụ.
Vì vậy nếu trực tiếp điền địa chỉ của DeepSeek vào Codex, sẽ không thể hoạt động trơn tru, tình huống thường gặp là tham số yêu cầu không khớp hoặc kết quả trả về không thể phân tích, dẫn đến gọi thất bại hoặc xuất ra kết quả bất thường, chứ không đơn giản là "không kết nối được".
Giải pháp của cộng đồng là thêm một lớp "lớp định tuyến" cục bộ hoặc "bộ chuyển đổi giao thức" ở giữa.
Quy trình cơ bản như sau:
1. Codex gửi yêu cầu theo Responses API;
2. Lớp định tuyến chuyển đổi nó sang định dạng Chat Completions;
3. Chuyển tiếp cho các mô hình nguồn mở như DeepSeek;
4. Lại chuyển đổi kết quả trả về về định dạng Responses mà Codex có thể nhận diện.
Khả năng tương tự không chỉ có CC Switch cung cấp.
LiteLLM, claude-code-router, và các dịch vụ proxy tự xây dựng của nhà phát triển, về bản chất đều giải quyết cùng một vấn đề: để các mô hình khác nhau tương tác thông qua quy chuẩn giao diện thống nhất.
OpenAI lần này mở một khe cửa, nhưng thực sự triển khai, vẫn cần cộng đồng tự "thêm gạch thêm ngói".
Đằng sau tất cả những điều này là một cách chơi định tuyến hỗn hợp.
Ví dụ để GPT chịu trách nhiệm lập kế hoạch: phân giải nhiệm vụ, thiết kế kiến trúc, nghĩ rõ ràng phải làm gì. Để mô hình nguồn mở chịu trách nhiệm thực thi: biến phương án thành mã có thể chạy, sửa hàng loạt tệp.
Thông qua sự kết hợp như vậy, cùng một nhiệm vụ, chi phí có thể cắt giảm một nửa lớn.
Ngoài tiết kiệm hơn, việc kết hợp Codex với mô hình nguồn mở cục bộ, mã nguồn một dòng cũng không ra khỏi máy tính của bạn.
Đối với những nhà phát triển cá nhân không muốn truyền dự án riêng tư lên mây, cũng không muốn liên tục trả tiền cho API, sự cám dỗ này không hề nhỏ.
Cuộc chiến mô hình kết thúc
Cuộc chiến giao diện bắt đầu
Mấy năm qua, tất cả mọi người đều nghĩ rằng hào sâu bảo vệ là mô hình. Mô hình của ai tham số lớn, điểm chạy cao, trả lời thông minh, người đó sẽ thắng.
Nhưng lần này, OpenAI đã biến lớp Codex này thành một giao diện có thể cắm rút, giá trị mà nó cung cấp cũng bắt đầu chuyển hướng sang lối vào hệ sinh thái.
Toan tính của OpenAI, rất có thể là từ một nhà sản xuất bán mô hình, chuyển mình thành một người chơi bán nền tảng và khung: mô hình tùy bạn thay đổi, công cụ phải là của tôi.
Ai chiếm giữ lối vào mà nhà phát triển mở ra mỗi ngày, người đó nắm giữ phân phối, có thể ngồi vào vị trí cốt lõi của hệ sinh thái.
Đây cũng không phải là lần đầu tiên OpenAI bố trí trong hệ sinh thái nguồn mở.
Mặc dù từ năm 2019 sau khi ra mắt GPT-2, họ lâu dài không phát hành lại mô hình ngôn ngữ lớn trọng số mở, dưới sự phát triển nhanh chóng của hệ sinh thái nguồn mở (như các mô hình Llama, DeepSeek, v.v.), họ vẫn vào tháng 8 năm 2025 ra mắt lại loạt mô hình trọng số mở gpt-oss.

Những mô hình này sau đó nhanh chóng được chuỗi công cụ cộng đồng (như Ollama, LM Studio, v.v.) tích hợp hỗ trợ, chính là những mô hình mà Codex --oss mặc định kết nối hỗ trợ hiện nay.
Ở lớp cấu hình, OpenAI thực sự mở khả năng kết nối mô hình, thông qua lớp trừu tượng nhà cung cấp mô hình cho phép mô hình của bên thứ ba kết nối vào, nhưng không phải mô hình bất kỳ đều có thể sử dụng trực tiếp, phải phù hợp với giao thức giao diện của họ hoặc thông qua lớp thích ứng để chuyển đổi.
Ở lớp giao thức, họ giữ lại một ràng buộc then chốt: lấy Responses API làm tiêu chuẩn tương tác chính, đồng thời cho phép thông qua lớp tương thích hỗ trợ các giao diện mô hình khác như Chat Completions.
Nói cách khác, bất kể kết nối loại mô hình nào, đều cần căn chỉnh theo cấu trúc yêu cầu và phản hồi do OpenAI định nghĩa, cuối cùng họ muốn làm là nắm chặt tiêu chuẩn giao diện trong tay mình.
Từ góc độ này, lớp giao thức giao diện dễ bị bỏ qua trong quá khứ này, đang trở thành tâm điểm cạnh tranh mới.
Có lẽ, lần này OpenAI muốn dùng một công tắc cấu hình không đáng chú ý, phát động một cuộc chiến lối vào lập trình AI, điều này khiến cuộc so kè giai đoạn tiếp theo của họ với Anthropic, đã không còn ở trên mô hình nữa.
Đối với các nhà phát triển mở Codex mỗi ngày, đây càng là sự tiện lợi thực tế: có thể chạy mô hình nguồn mở, có thể tiết kiệm token, còn có thể làm việc ngoại tuyến cục bộ.
Nhưng càng dùng thuận tay, càng dùng sâu, càng không rời xa lối vào này.
Tài liệu tham khảo:
https://x.com/thsottiaux/status/2067181377028538431
https://developers.openai.com/codex/config-advanced#oss-mode-local-providers
https://www.ccswitch.io/en/tutorials/codex-deepseek-routing-guide
Bài viết này đến từ tài khoản công chúng WeChat "Tân Trí Nguyên", tác giả: ASI Khải Thị Lục, biên tập: Nguyên Vũ






