Tác giả | Zimu AI
Tối qua, Anthropic đã đăng một bài viết dài với tiêu đề "When AI builds itself" (Khi AI tự xây dựng chính mình), nghe giống như một cuốn tiểu thuyết khoa học viễn tưởng nào đó của Asimov, và chủ đề thực sự là một khái niệm rất viễn tưởng: recursive self-improvement (cải tiến tự quy hồi).

Nói một cách đơn giản, trước đây là các nhà nghiên cứu con người viết code, chạy thí nghiệm, huấn luyện mô hình, rồi làm cho AI mạnh hơn. Nhưng nếu chính AI bắt đầu tham gia vào việc thiết kế, huấn luyện, kiểm thử và tối ưu hóa các phiên bản kế tiếp của chính nó, thì tốc độ tiến bộ của AI sẽ không còn chỉ do con người thúc đẩy, mà có thể bắt đầu do AI "tự tiến hóa".
Vì lý do này, Anthropic đã đưa ra lời kêu gọi:
"Chúng tôi tin rằng sẽ rất có lợi cho thế giới nếu thế giới có thể lựa chọn làm chậm lại hoặc tạm thời dừng việc phát triển các AI tiên phong, để các cấu trúc xã hội và nghiên cứu alignment (đối chuẩn) theo kịp tiến bộ công nghệ."
Câu này nghe như một cảnh báo an toàn, nhưng đặt vào thời điểm Anthropic chuẩn bị IPO, nó cũng khó không bị xem như một dạng diễn ngôn dự báo khác: Claude thực sự quá tốt, thậm chí đã bắt đầu tự tạo ra thế hệ Claude tiếp theo.
Cơn bão mới đã xuất hiện
Để minh họa cho việc AI đang ngày càng tham gia nhiều hơn vào chính quá trình R&D của AI, Anthropic đã đưa ra một lượng lớn dữ liệu nội bộ.
Ví dụ, tính đến tháng 5 năm 2026, hơn 80% mã code được hợp nhất vào kho code của Anthropic là do Claude viết. Trong khi đó, trước khi Claude Code ra mắt, con số này chỉ là một chữ số.
Đến quý 2 năm 2026, theo thống kê của Anthropic, lượng code mà các kỹ sư hợp nhất mỗi ngày đã cao hơn khoảng 8 lần so với năm 2024.
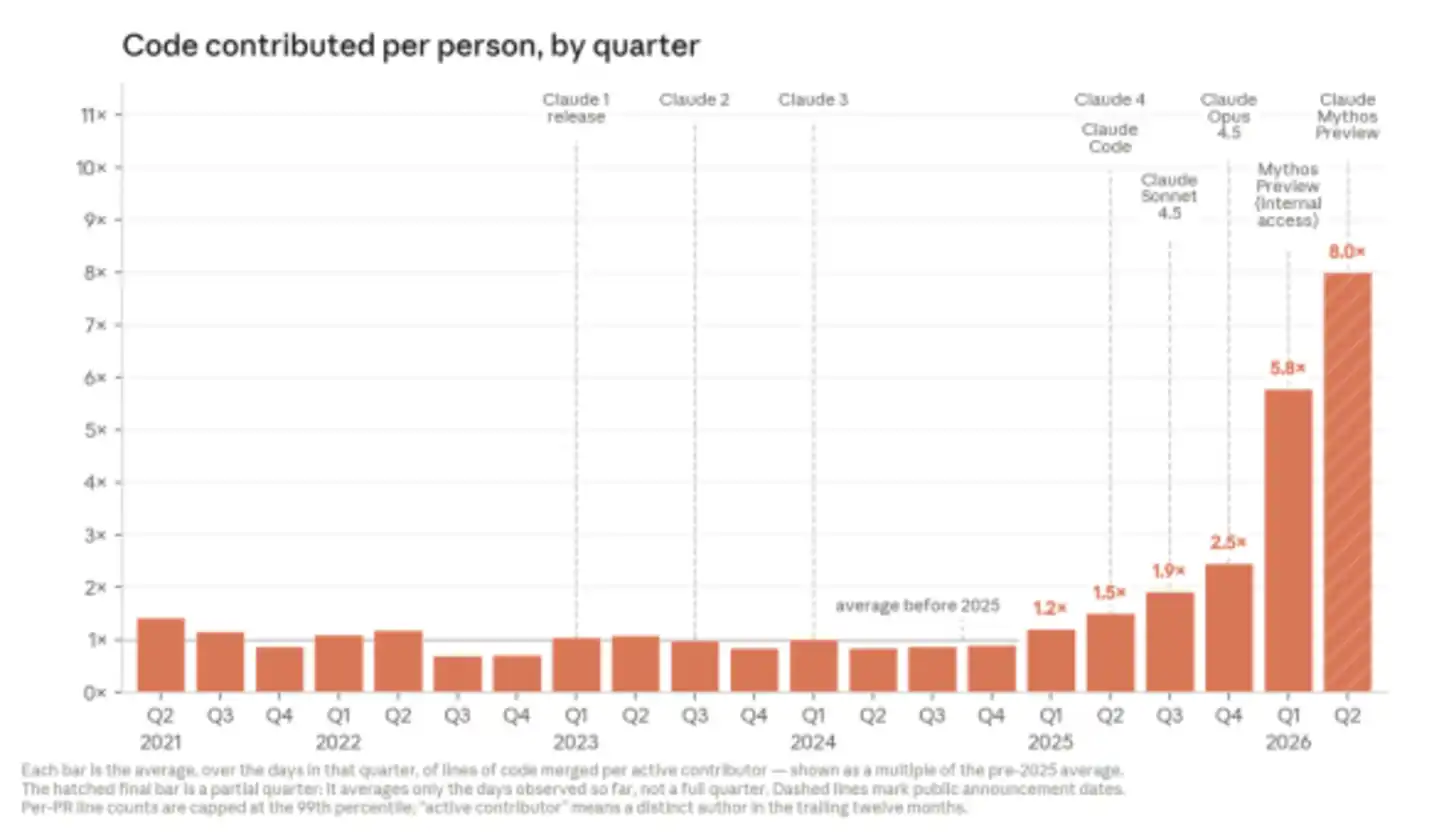
Điều đáng chú ý hơn cả lượng code là Claude đang xử lý các vấn đề kỹ thuật mang tính mở rộng hơn.
Anthropic viết trong bài rằng, trong năm qua, tần suất nhân viên phải sửa chữa Claude, kéo Claude trở lại đúng hướng, hoặc tiếp quản nhiệm vụ giữa chừng đã liên tục giảm. Sự thay đổi này không chỉ xảy ra với các nhiệm vụ đơn giản, mà còn với cả những nhiệm vụ mở phức tạp nhất.
Nhiệm vụ mở (open task) ở đây là những vấn đề không có hướng dẫn rõ ràng. Ví dụ như hệ thống sập, nhiệm vụ huấn luyện bị treo, bản thân kỹ sư lúc đầu cũng không biết đáp án trông thế nào, chỉ có thể vừa kiểm tra vừa phán đoán.
Loại nhiệm vụ này trước đây phụ thuộc nhiều nhất vào kinh nghiệm con người, và trong số những nhiệm vụ mở nhất đó, tỷ lệ thành công của Claude đến tháng 5 năm 2026 đã đạt 76%, tăng 50 điểm phần trăm trong vòng sáu tháng.
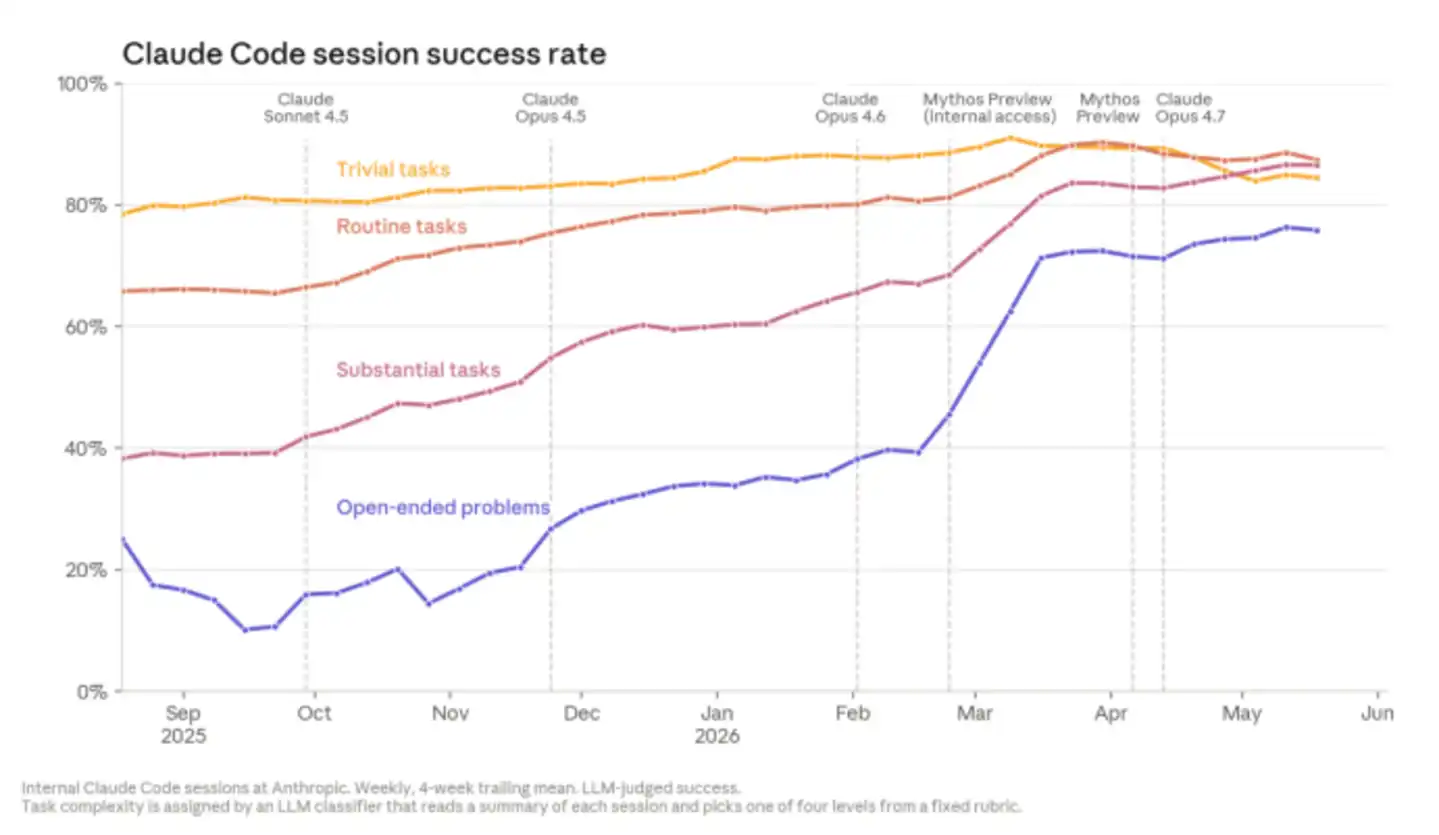
Không chỉ viết code, Anthropic còn dùng Claude để xem xét code (code review), kiểm tra lỗi bug, lỗ hổng bảo mật và các thiếu sót khác. Họ phân tích ngược lại và phát hiện ra rằng, nếu mỗi lần thay đổi code trong quá khứ đều được Claude tự động xem xét, thì khoảng một phần ba số bug dẫn đến sự cố trực tuyến trên claude.ai, lẽ ra đã có thể bị chặn lại trước khi lên sóng.
Đi xa hơn, Claude đã bắt đầu tham gia vào quy trình nghiên cứu.
Anthropic có một bài kiểm tra cố định: đưa cho Claude một đoạn code huấn luyện mô hình nhỏ, yêu cầu nó tìm cách chạy code nhanh hơn mà không làm sai kết quả. Vào tháng 5 năm 2025, Claude Opus 4 có thể đạt tốc độ nhanh hơn khoảng 3 lần; đến tháng 4 năm 2026, Claude Mythos Preview đã đẩy con số này lên khoảng 52 lần.
Anthropic còn đề cập đến một trường hợp nghiên cứu an toàn AI mở. Họ giao một vấn đề cho agent (tác tử) được điều khiển bởi Claude: Một mô hình yếu hơn có thể giám sát một mô hình mạnh hơn một cách đáng tin cậy hay không?
Quá trình này yêu cầu đưa ra giả thuyết, kiểm tra giả thuyết, chia sẻ phát hiện với các agent song song, và lặp đi lặp lại.
Hai nhà nghiên cứu con người mất một tuần để thu hẹp khoảng 23% khoảng cách; trong khi Claude, với tổng cộng khoảng 800 giờ và tiêu thụ tài nguyên tính toán khoảng 18.000 USD, đã thu hẹp được 97%.
Kết quả này tất nhiên có giới hạn, vấn đề là do con người chọn, tiêu chí chấm điểm cũng do con người định, và kết quả cũng chưa hoàn toàn chuyển đổi sang các mô hình ở quy mô sản xuất. Nhưng nó vẫn cho thấy, Claude đã có thể tự thiết kế thí nghiệm, tự thực hiện và tự lặp lại trong một khung nghiên cứu mà con người đã định hướng sẵn.
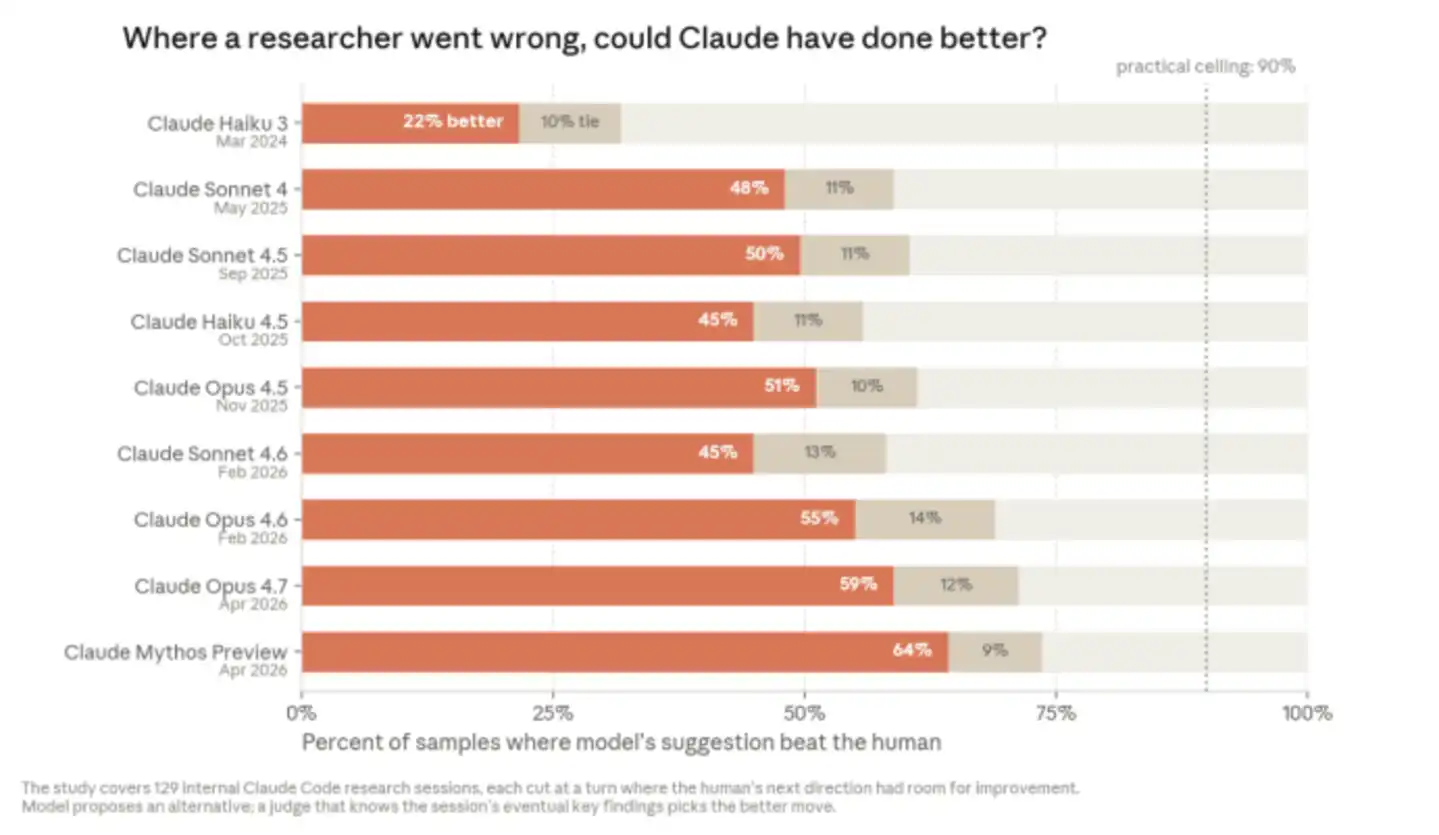
Ngoài ra, khi nhà nghiên cứu con người "đi sai đường", Claude còn có thể đưa ra phán đoán tốt hơn cho bước tiếp theo.
Anthropic đã tìm 129 phiên nghiên cứu nội bộ về Claude Code, trong những phiên này, nhà nghiên cứu con người và Claude cùng nhau giải quyết các vấn đề nghiên cứu mở. Anthropic chọn ra một số điểm nút mà "con người sau đó được chứng minh là đã đi vòng", sau đó đưa ngữ cảnh trước điểm nút đó cho các phiên bản Claude khác nhau, xem nó sẽ đề xuất bước tiếp theo thế nào. Rồi một Claude judge khác biết kết cục đầy đủ của phiên sẽ đánh giá: đề xuất của mô hình và lựa chọn của con người lúc đó, cái nào tốt hơn.
Kết quả cho thấy, ở những điểm nút mà nhà nghiên cứu con người đã được chứng minh sau sự kiện là có không gian để cải thiện, Claude ngày càng có thể đề xuất bước tiếp theo tốt hơn.
Trước đây, sự tiến bộ của mô hình AI chủ yếu do các nhà nghiên cứu và kỹ sư con người thúc đẩy. Con người quyết định làm thí nghiệm gì, viết code gì, huấn luyện mô hình và thúc đẩy lặp lại chức năng của AI.
Bây giờ, ngày càng nhiều khâu trong chuỗi này bắt đầu được Claude đảm nhận.
Anthropic đưa ra một biểu đồ giai đoạn rất trực quan:
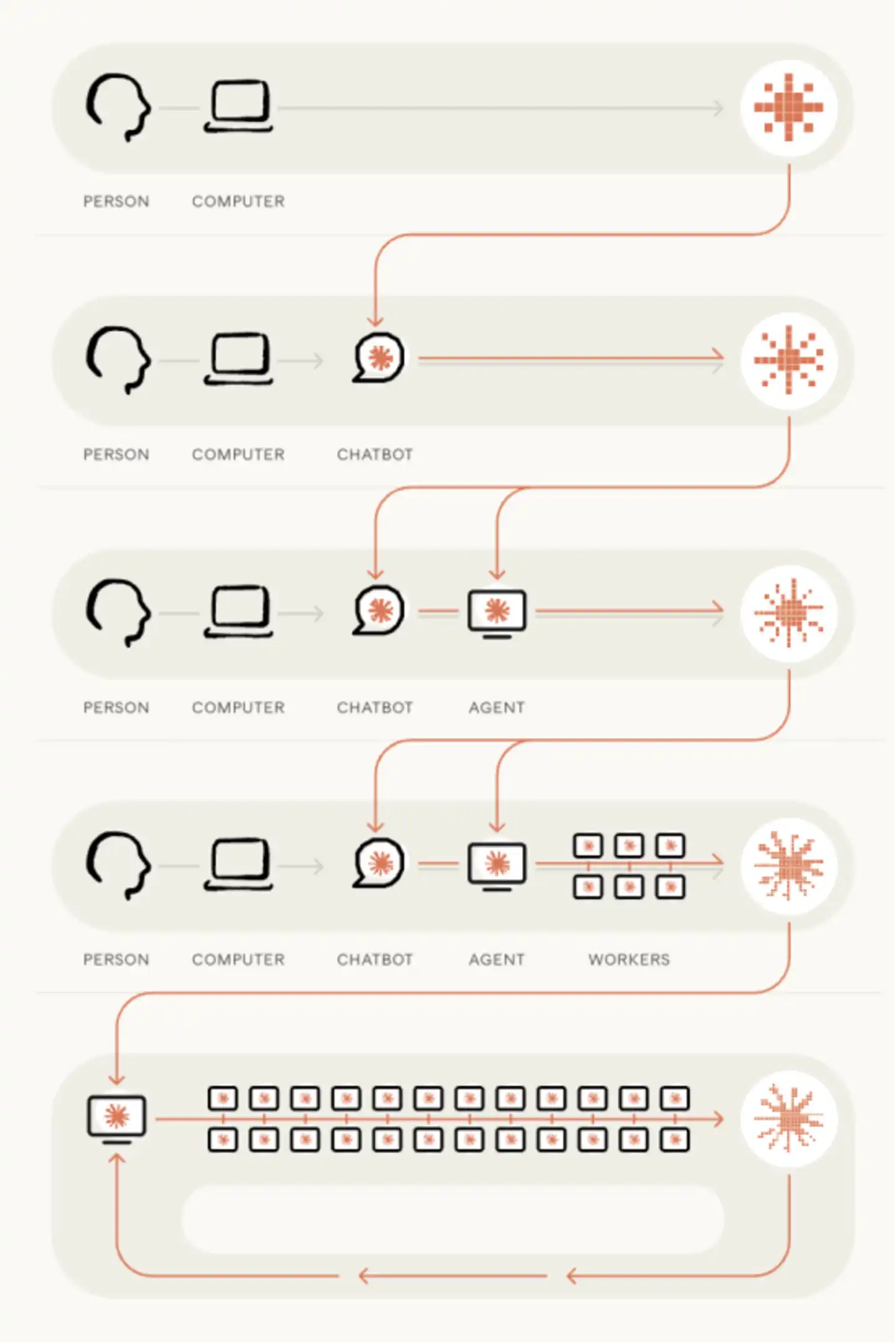
Từ năm 2021 đến 2023, Anthropic chẳng khác gì một công ty công nghệ bình thường, đều là con người viết code, viết tài liệu trên máy tính xách tay.
Từ 2023 đến 2025, chatbot bắt đầu đi vào quy trình làm việc. Kỹ sư để mô hình tạo đoạn code, sau đó sao chép vào trình soạn thảo.
Từ 2025 đến 2026, agent lập trình xuất hiện, Claude bắt đầu có thể tự viết và sửa code, đôi khi thậm chí có thể hoàn thành độc lập cả một file.
Đến nay, agent đã có thể tự chạy code, và còn có thể ủy thác công việc kéo dài hàng giờ cho các agent khác.
Tiếp theo sau đó, chính là giai đoạn mà Anthropic thực sự lo ngại: vòng lặp khép kín (closed loop).
Nếu ngày đó đến, các phiên bản kế tiếp của Claude, có thể sẽ do chính bản thân Claude liên tục cải tiến – đây chính là recursive self-improvement, cải tiến tự quy hồi.
Anthropic nói rất thận trọng trong bài: chúng tôi chưa đi đến bước đó, và cải tiến tự quy hồi cũng không phải là điều tất yếu xảy ra. Nhưng họ vẫn nhấn mạnh rằng, con đường dẫn đến bước đó, đã bắt đầu trở nên có thể nhìn thấy.
Vì vậy, Anthropic mới nói đến việc giảm tốc, thậm chí tạm dừng, ở cuối bài. Ý của họ không phải là tất cả các công ty AI ngay lập tức ngừng hoạt động, mà là nói rằng, nếu rủi ro tự cải tiến của AI trong tương lai tiếp tục gia tăng, các phòng thí nghiệm tiên phong cần một cơ chế phối hợp, có thể xác minh để giảm tốc.
Nói cách khác, "điểm kỳ dị (singularity)" sắp đến, con người phải kiểm soát nó.
Claude không thể ngăn cản
Nếu chỉ nhìn bề ngoài, đây là một tài liệu an toàn rất có ý thức tiên phong. Anthropic đang nói về cải tiến tự quy hồi, về việc AI có thể ngày càng nhanh chóng cải thiện chính nó, về việc xã hội loài người cần chuẩn bị trước cơ chế giảm tốc và tạm dừng.
Nhưng đặt vào thời điểm Anthropic chuẩn bị IPO, bài viết này lại có một ý nghĩa khác.
Ở một mức độ nào đó, động thái gần đây của Anthropic rất giống một học sinh ưu tú hay thể hiện trong lớp – nó thực sự có năng lực, nhưng cũng thực sự khoe khoang.
Điều nó muốn nói không chỉ là "chúng tôi có một Claude rất mạnh", mà còn tiến xa hơn một bước, nó muốn nói "Claude đang giúp chúng tôi tạo ra Claude mạnh hơn".
Nếu Anthropic chỉ bán một mô hình hoặc một công cụ, thì rất khó để thoát khỏi sự so sánh ngang hàng: Anthropic có Claude, OpenAI có GPT; Anthropic có Claude Code, OpenAI có Codex; Anthropic tranh khách hàng doanh nghiệp, OpenAI cũng tranh khách hàng doanh nghiệp. Cạnh tranh giữa hai công ty rất khốc liệt, chỉ xem ai có thể kể cho thị trường một câu chuyện lớn hơn.
Cần lưu ý rằng, chỉ 3 ngày trước, OpenAI đã viết trong một tài liệu về quản trị AI tiên phong:
"Chúng tôi cũng thấy những dấu hiệu ban đầu của cải tiến tự quy hồi trong các hệ thống ngày nay: chính sự phát triển của AI đang được AI thúc đẩy.
Điều này sẽ làm trầm trọng thêm áp lực cạnh tranh giữa các nhà phát triển và giữa các quốc gia, và mang đến những thách thức quản trị mà các thể chế hiện tại không thể đối phó."
3 ngày sau, Anthropic liền nói: con đường dẫn đến cải tiến tự quy hồi của Claude, đã bắt đầu trở nên có thể nhìn thấy.

Nếu Claude thực sự phát triển như họ kỳ vọng, thì đó không còn là câu chuyện sản phẩm thông thường nữa, nó sẽ trở thành một bánh đà (flywheel) nghiên cứu và phát triển.
Claude viết code, chạy thí nghiệm, tối ưu hóa quy trình huấn luyện, rồi ngược lại giảm sự cố trong chính sản phẩm của Anthropic… Một khi hệ thống này chạy, Claude không chỉ là một sản phẩm của Anthropic, mà còn là công cụ sản xuất quan trọng của Anthropic.
Người dùng nhìn thấy Claude là một sản phẩm, khách hàng doanh nghiệp mua khả năng của Claude, nhưng điều Anthropic thực sự muốn thị trường vốn chú ý là: Claude đã được nhúng vào quy trình cốt lõi của việc phát triển mô hình tiên phong, nó được đặt vào khoang động cơ của Anthropic.
Thị trường vốn thích nghe câu chuyện về bánh đà nhất, giống như chiếc bồn thần (cái gì bỏ vào cũng sinh ra tiền) vậy: Claude mạnh hơn giúp kỹ sư của Anthropic hợp nhất được nhiều code hơn, nhiều code hơn giúp sản phẩm và cơ sở hạ tầng lặp nhanh hơn, lặp nhanh hơn giúp nhà nghiên cứu chạy nhiều thí nghiệm hơn, nhiều thí nghiệm hơn lại ngược lại giúp thế hệ Claude tiếp theo mạnh hơn. Thế hệ Claude tiếp theo mạnh hơn rồi, lại tiếp tục tăng tốc R&D của Anthropic.
Tốc độ lặp của Claude cũng đang hỗ trợ bánh đà này. Nhìn từ thời điểm công bố chính thức, từ năm 2023 đến đầu năm 2025, các bản cập nhật mô hình chính của Claude chủ yếu là ba bốn tháng một lần, nhưng khi bước vào Claude 4, các bản cập nhật mô hình của Anthropic rõ ràng đã dày đặc hơn.
Claude 4 ra mắt tháng 5/2025, Opus 4.1 ra mắt tháng 8, Sonnet 4.5 ra mắt tháng 9, Haiku 4.5 ra mắt tháng 10, Opus 4.5 ra mắt tháng 11.
Đến năm 2026, Opus 4.6 ra mắt ngày 5/2, Sonnet 4.6 ra mắt ngày 17/2, Opus 4.7 ra mắt ngày 15/4, Opus 4.8 ra mắt ngày 28/5. Từ Opus 4.7 đến Opus 4.8, chỉ cách nhau 42 ngày.
Về mặt bề ngoài, Anthropic đang nói "việc này có thể rất nguy hiểm, chúng ta cần chuẩn bị phanh trước", nhưng đồng thời nó cũng ám chỉ: "chúng tôi đã nhìn thấy điều gì sẽ xảy ra sau khi đạp ga".
Sự tinh tế của câu chuyện IPO nằm ở chỗ này. Một mặt nó nói rất nặng về rủi ro, mặt khác cũng nâng cao vị trí công nghệ của mình.
Không phải tất cả các công ty AI đều có tư cách thảo luận về cải tiến tự quy hồi, bạn phải khiến bên ngoài tin rằng AI của bạn đã đi vào quy trình phát triển AI, thì mới có tư cách nói rằng việc này có thể cần sự phối hợp toàn cầu.
OpenAI: Sao có thể như vậy?
Như đã đề cập trước đó, ngay trước khi Anthropic đăng bài viết dài này, OpenAI vừa đưa cải tiến tự quy hồi lên bàn.
Nhưng cách trình bày của hai công ty rất khác nhau.
Bài "Democratic Governance of Frontier AI" của OpenAI là một bản kế hoạch chính sách gửi đến Washington, nó quan tâm không phải là "mô hình trở nên mạnh hơn thế nào", mà là khi AI tiên phong tiếp tục lao về phía trước, làm thế nào để kiềm chế nó.
Phần lớn nội dung trong báo cáo đó không phù hợp để trình bày chi tiết ở đây, chỉ có một câu then chốt: OpenAI nói rằng, trong các hệ thống ngày nay, đã có thể thấy những dấu hiệu ban đầu của cải tiến tự quy hồi.
Câu này và bài viết dài của Anthropic, thực chất đang chỉ về cùng một hướng.
Chỉ có điều OpenAI đang nói về thể chế, còn Anthropic đang nói về chính mình.
Ý của OpenAI là: AI phát triển quá nhanh, cấu trúc quản trị hiện tại có thể không theo kịp, nên cần một bộ quy tắc mới.
Còn Anthropic trực tiếp trình bày hệ thống đó ra, nói với thị trường: Claude đã đi vào quy trình R&D của chúng tôi, nên chúng tôi đã nhìn thấy con đường tự tăng tốc của AI.
Chiêu này chơi rất cao tay, cảm giác như nội bộ OpenAI chắc đang thì thầm rồi – đây rõ ràng là ăn cắp ý tưởng! Rõ ràng là chúng tôi đến trước!
Đùa thôi, nhưng OpenAI thực sự cần cố gắng hơn nữa, nhanh chóng đưa GPT 5.6 lên đi.