Trong hơn mười năm qua, việc tính toán kỹ thuật số lấy GPU làm trung tâm đã thống trị lĩnh vực AI. Các cụm lớn hơn, băng thông cao hơn, GPU mạnh hơn và các trung tâm dữ liệu dày đặc hơn dường như là con đường chính dẫn đến thế hệ AI tiếp theo.
Tuy nhiên, khi quy mô tham số mô hình tiến tới nghìn tỷ, ngành công nghiệp bắt đầu thường xuyên nhắc đến từ "tiêu thụ năng lượng". Một vấn đề cơ bản hơn cũng xuất hiện: Nếu AI tiếp tục mở rộng theo cách hiện tại, điện sẽ lấy từ đâu?
Không còn nghi ngờ gì nữa, "hóa đơn tiền điện" và mức tiêu thụ năng lượng của AI đã dần dần phát triển từ chi phí vận hành thành một "nút thắt cấu trúc" hạn chế sự phát triển của toàn ngành.
Đối mặt với cuộc khủng hoảng năng lượng sắp xảy ra này, Naveen Rao, cựu Trưởng phòng AI tại Databricks và là doanh nhân khởi nghiệp huyền thoại ở Thung lũng Silicon, cùng công ty khởi nghiệp công nghệ cứng hoàn toàn mới Unconventional AI của ông đã bước vào ánh đèn sân khấu.
Hôm nay, Unconventional AI đã chính thức công bố mô hình đầu tiên của họ, Un-0, một mô hình sinh ảnh được điều khiển bởi "hệ thống dao động liên kết tương tự", có thể được coi là một mẫu của nền tảng tính toán vật lý mới nổi. Trên ImageNet 64×64, Un-0 đạt FID 6.74, chất lượng đã gần bằng mức của một số phương pháp sinh ảnh truyền thống chủ lực khi mới được công bố.
Naveen Rao gọi đây là "mô hình sinh quy mô lớn đầu tiên được xây dựng bằng cách sử dụng vật lý làm nguyên thủy tính toán".
"Điều này đánh dấu thời điểm 'Hello World' của các mô hình dựa trên vật lý. Chúng tôi sử dụng hành vi biến đổi tự nhiên theo thời gian của hệ thống vật lý để thực hiện tính toán thay cho chúng tôi. Kết quả cuối cùng là một cách xây dựng máy tính hoàn toàn mới và có triển vọng cải thiện đáng kể hiệu suất năng lượng."

Thậm chí, trong một cuộc phỏng vấn với giới truyền thông, Naveen Rao đã đưa ra một "mục tiêu nhỏ" táo bạo hơn: Trong tương lai, có thể giảm mức tiêu thụ năng lượng suy luận AI xuống còn một phần nghìn so với các hệ thống hiện có.
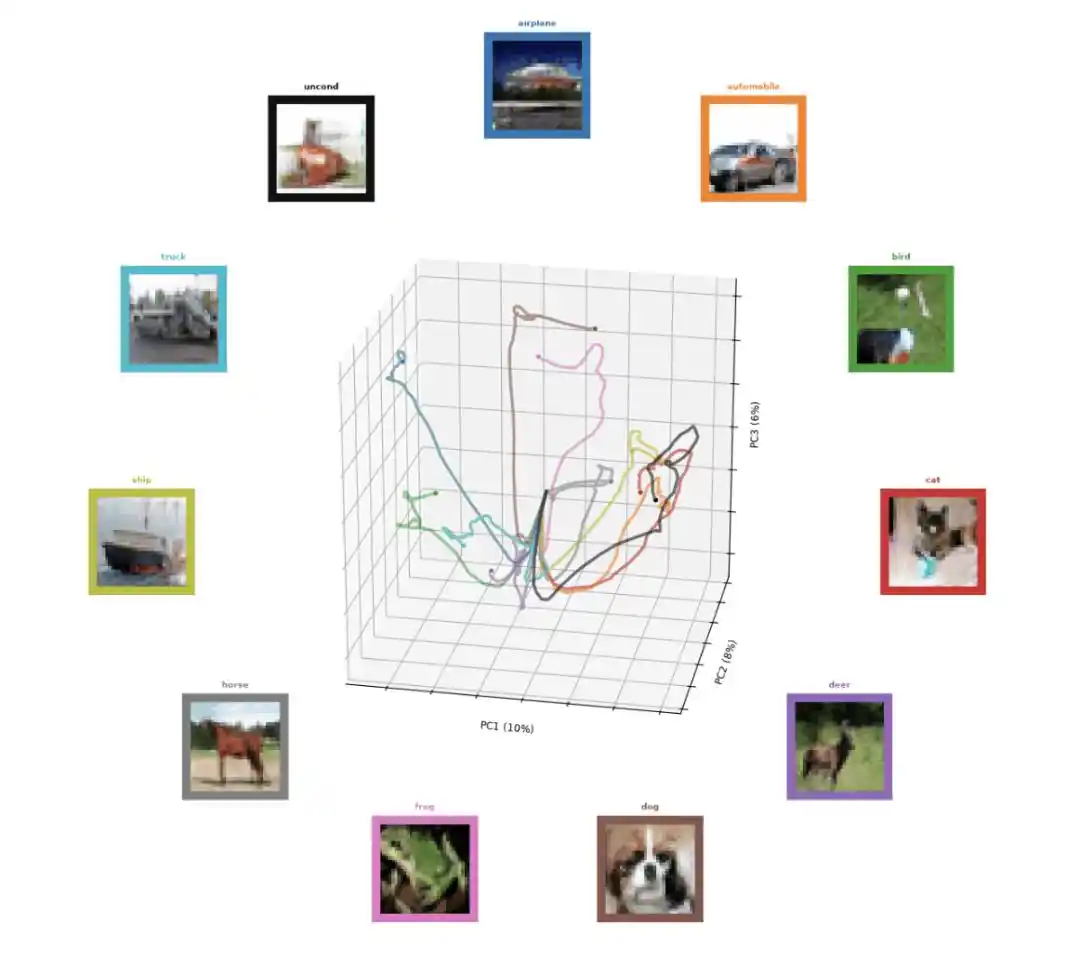
Mẫu quỹ đạo tiến hóa theo thời gian trong quá trình sinh ảnh của Un-0. Màu sắc của mỗi đường tương ứng với một ô vuông có màu sắc tương tự, trong ô vuông có gắn nhãn danh mục và thể hiện quá trình hình ảnh của danh mục đó được tạo ra dần dần theo thời gian.
Họ đã đăng một bài blog chính thức để giới thiệu về Un-0, hãy cùng tìm hiểu chi tiết.
Điểm xuất phát của Un-0: Làm lại việc tính toán AI bằng hệ thống vật lý
Unconventional AI cho biết mục tiêu của họ là xây dựng một loại máy tính mới, cho phép nó sử dụng các quy luật vật lý để hoàn thành tính toán, hy vọng rằng trong tương lai, AI hiện đại có thể chạy với mức tiêu thụ năng lượng thấp hơn rất nhiều so với ngày nay, mục tiêu là giảm khoảng 1000 lần mức tiêu thụ năng lượng.
Vì vậy, họ đặt ra một câu hỏi: Có thể huấn luyện một hệ thống động lực học vật lý để nó tạo ra hình ảnh trên các nhiệm vụ quy mô lớn hay không?
Ngày nay, các mô hình AI mạnh nhất hầu hết đều là mạng sâu truyền thống, đặc biệt là các mô hình lấy Transformer làm xương sống. Tuy nhiên, bên ngoài con đường chính, từ lâu đã có nhiều nghiên cứu cố gắng sử dụng hành vi động lực học của hệ thống vật lý để cải thiện hiệu suất năng lượng, chẳng hạn như nhiễu, biến đổi thời gian, điện áp và dòng điện trong mạch tương tự. Những phương pháp này không sử dụng các giá trị số truyền thống để tính toán, mà sử dụng chính quá trình tiến hóa của hệ thống vật lý.
Ví dụ như tính toán thần kinh dạng (neuromorphic computing), mạng Hopfield và tính toán bể chứa (Reservoir Computing), cũng như các mô hình gần đây như Mạng Hamiltonian, Mạng Lỏng (Liquid Networks), Máy Sóng Thần Kinh (Neural Wave Machines), Tính toán Nhiệt động lực học (Thermodynamic Computing) và Dao động Kuramoto (Kuramoto Oscillators).
Un-0 là một nỗ lực mới trong những con đường tính toán không truyền thống này. Nhưng khó khăn cốt lõi là: để sử dụng các phương thức tính toán thay thế này, tác vụ AI phải được ánh xạ hiệu quả vào quá trình động lực học của hệ thống vật lý. Điều Un-0 muốn kiểm chứng là liệu khối lượng công việc AI hiện đại có thể được đưa lên nền tảng vật lý để chạy hay không, và cuối cùng có hiệu quả hơn phần cứng ngày nay hay không.
Nguyên lý hoạt động của Un-0
Theo giải thích chính thức, bạn có thể hình dung hai máy đập nhịp (metronome) đặt cạnh nhau và kêu tích tắc, như hình dưới đây.
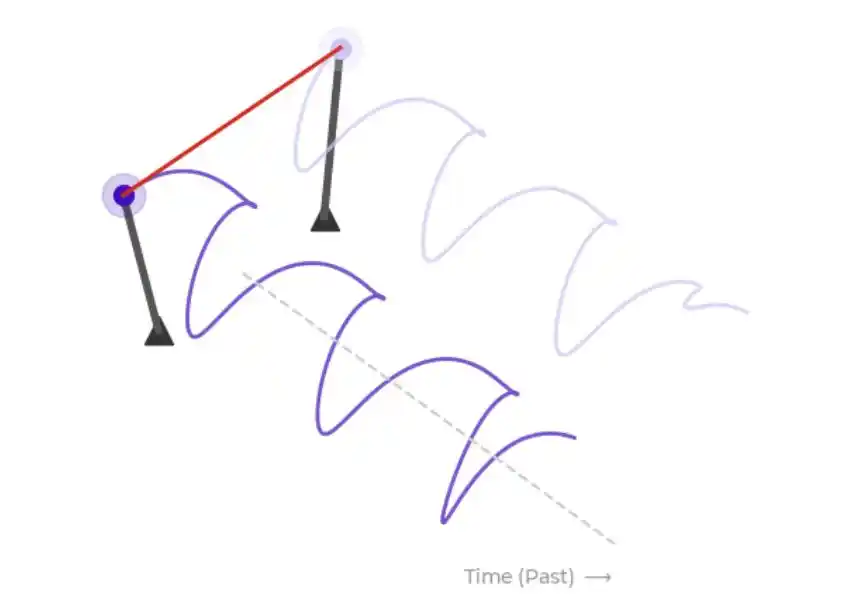
Mỗi máy đập nhịp tại bất kỳ thời điểm nào đều có một "pha", tức là vị trí hiện tại của cánh tay đòn trong chu kỳ dao động. Nếu hai máy đập nhịp được đặt trên cùng một mặt bàn, chúng sẽ ảnh hưởng lẫn nhau thông qua mặt bàn. Tùy thuộc vào độ mạnh của tương tác, tức là cường độ liên kết, chúng có thể dần đồng bộ hóa hoặc có thể rơi vào trạng thái đồng bộ ngược pha.
Đây là khái niệm cơ bản về bộ dao động: mỗi bộ dao động có pha riêng và có xu hướng quay theo tần số tự nhiên của chính nó, nhưng đồng thời cũng chịu ảnh hưởng từ các bộ dao động lân cận.
Và nếu mở rộng từ hai bộ dao động lên hàng nghìn bộ dao động, toàn bộ hệ thống sẽ trở nên thú vị hơn. Một số lượng lớn bộ dao động có các mối quan hệ liên kết với cường độ khác nhau, chúng sẽ tự tổ chức thành một kiểu mẫu nào đó thông qua tương tác lẫn nhau, như hình dưới đây.

Công cụ tính toán của Un-0 chính là một nhóm dao động quy mô lớn như vậy, trong đó cường độ liên kết giữa các bộ dao động là tham số có thể học quan trọng nhất của mô hình.
Những bộ dao động liên kết này thường được mô hình hóa là "Dao động Kuramoto".
Cụ thể, chuyển động của mỗi bộ dao động tuân theo một quy tắc đơn giản và quy tắc này có hiệu lực liên tục theo thời gian: một mặt nó quay theo tần số tự nhiên của chính nó, mặt khác nó bị lệch do sự kéo từ tất cả các bộ dao động khác.
Phương trình vi phân thường (ODE) dưới đây mô tả quá trình tiến hóa theo thời gian của những bộ dao động này:
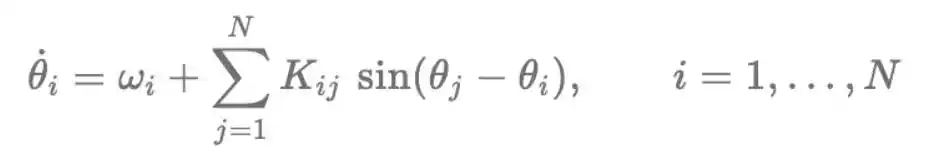
Mỗi bộ dao động i đều có một pha
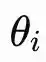
∈[0,2π), trong đó
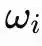
đại diện cho tần số tự nhiên của nó. Ma trận
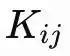
quy định cường độ liên kết, dùng để xác định lực mà bộ dao động j sẽ kéo bộ dao động i về trạng thái đồng bộ, hoặc đẩy nó ra khỏi trạng thái đồng bộ.
Những gì Un-0 cần học chính là ma trận liên kết K và tần số tự nhiên ω, những tham số này cùng nhau định nghĩa chính hệ thống vật lý.
Về lý do chọn bộ dao động, Unconventional AI đưa ra hai lý do:
- Lý do đầu tiên đến từ bộ não: Hoạt động nhịp điệu và hiện tượng đồng bộ hóa tồn tại rộng rãi trong não bộ, từ lâu người ta tin rằng những hiện tượng này có thể tham gia vào quá trình tính toán, chẳng hạn như liên kết các đặc điểm phân tán thành một kết quả nhận thức mạch lạc, kiểm soát giao tiếp thông tin giữa các vùng não, tổ chức cấu trúc thời gian của các xung thần kinh. Bộ dao động liên kết là một trong những mô hình toán học đơn giản nhất để mô tả loại hành vi này, do đó tự nhiên phù hợp để làm đơn vị cơ bản cho các mô hình tính toán lấy cảm hứng từ thần kinh.
- Lý do thứ hai mang tính kỹ thuật hơn: Bộ dao động có thể được triển khai dưới dạng một nguyên thủy mạch vật lý. Unconventional AI tin rằng có thể trực tiếp triển khai hệ thống dao động liên kết trên nền tảng CMOS hoặc các nền tảng vật lý khác, để hành vi vật lý của hệ thống tự thực hiện tính toán tiến hóa động lực học.
Cược của Un-0 là: Nếu các quy luật vật lý có thể trực tiếp tính toán khối lượng công việc AI, thì nền tảng thực thi trong tương lai có thể rất khác so với GPU ngày nay.
Kiến trúc mô hình của Un-0
Việc Un-0 tạo ra một hình ảnh, về cơ bản được chia thành năm bước:
- Khởi tạo ngẫu nhiên: Đặt pha của tất cả các bộ dao động thành các góc ngẫu nhiên (tương tự như nhiễu ngẫu nhiên trong mô hình khuếch tán);
- Hướng dẫn bằng nhãn danh mục đầu vào: Sử dụng một nhóm nhỏ hơn gồm các "bộ dao động có điều kiện" để nhập nhãn danh mục (như "núi lửa", "hoa cúc"), hướng dẫn cụm bộ dao động chính tiến hóa theo một hướng cụ thể;
- Để vật lý vận hành tự nhiên: Giải phóng hệ thống, để các bộ dao động kéo lẫn nhau và tiến hóa dưới tác động của động lực học vật lý, và cuối cùng ổn định lại;
- Chụp nhanh trạng thái: Tại một thời điểm T cụ thể, ghi lại pha của tất cả các bộ dao động, tạo thành một lưới số không gian tiềm ẩn (Latent);
- Kết xuất điểm ảnh: Thông qua một bộ giải mã truyền thống chỉ chiếm chưa đến 13% tham số của mô hình, chuyển đổi lưới pha thành các điểm ảnh hình ảnh cuối cùng.
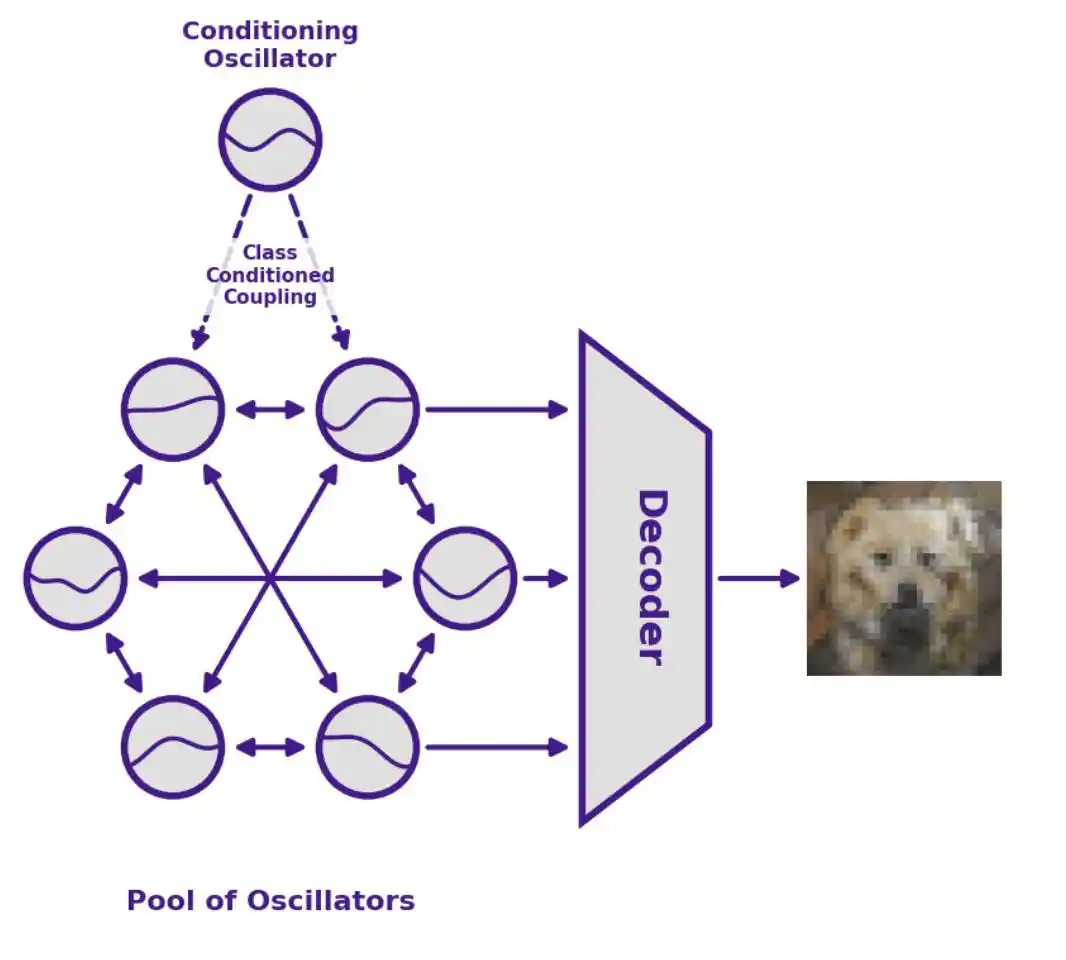
Các bộ dao động liên kết tiến hóa theo thời gian dưới tác động của mối quan hệ liên kết thu được từ quá trình huấn luyện. Trong đó, tồn tại một ma trận điều kiện hạng thấp một chiều từ các bộ dao động điều kiện đến nhóm bộ dao động chính, dùng để đưa thông tin danh mục vào. Tại thời điểm T, hệ thống đọc trạng thái bộ dao động thông qua một bộ giải mã và tạo ra hình ảnh. Bằng cách lấy mẫu nhiều lần các điều kiện ban đầu khác nhau, có thể tạo ra phân phối hình ảnh tương ứng.
Trong quá trình huấn luyện, mô hình chủ yếu học ba loại tham số: các bộ dao động liên kết với nhau như thế nào, tức là ma trận K; tần số tự nhiên của mỗi bộ dao động
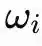
; và trọng số của bộ giải mã. Nhìn chung, hệ thống dao động đảm nhận việc tính toán vốn có thể được thực hiện bởi các lớp mạng nơ-ron truyền thống.
Unconventional AI giải thích, lý do chọn kiến trúc này là để cho bản thân hệ thống động lực học có sự tự do tối đa để hoàn thành tính toán.
Trong lượt truyền thuận (forward propagation) của quá trình huấn luyện, mô hình chỉ cần thiết lập ma trận liên kết, tần số dao động và pha ban đầu, sau đó để hệ thống động lực học tiến hóa, cuối cùng đọc biến tiềm ẩn (latent) của hình ảnh.
Điều này khác với các phương pháp sinh động lực học như mô hình khuếch tán và Flow Matching. Mô hình khuếch tán và Flow Matching thường hướng dẫn rõ ràng hệ thống động lực học tiến hóa như thế nào trong quá trình huấn luyện, trong khi phương pháp của Un-0 giống như chỉ nhìn vào mẫu được tạo ra cuối cùng, sau đó tối ưu hóa toàn bộ hệ thống động lực học thông qua hàm mất mát.
Cái giá phải trả là nó cần một hàm mất mát phức tạp hơn, vì tín hiệu huấn luyện chủ yếu đến từ chính các mẫu được tạo ra.
Làm thế nào để huấn luyện Un-0?
Unconventional AI đã huấn luyện ba mô hình với quy mô khác nhau trên CIFAR-10 và ImageNet 64×64, kết quả như sau:

Kết quả huấn luyện trên CIFAR-10

Kết quả huấn luyện trên ImageNet 64×64
Xét từ kết quả, khi số lượng bộ dao động tăng lên, điểm số FID của mô hình tiếp tục được cải thiện. Mô hình ImageNet 64×64 lớn nhất sử dụng 16384 bộ dao động, tổng số tham số khoảng 322 triệu, đạt FID 6.74.
Về phương pháp huấn luyện, họ đã sử dụng một hàm "Mất mát trôi dạt" (Drifting Loss) mới được đề xuất, kết hợp với bộ trích xuất đặc trưng DINOv2 và bộ tối ưu hóa AdamW để huấn luyện từ đầu đến cuối.
Về đánh giá, CIFAR-10 sử dụng 50.000 mẫu được tạo ra và so sánh với thống kê tham chiếu CIFAR-10 bằng gói tiêu chuẩn và quy trình đánh giá; ImageNet 64×64 cũng sử dụng 50.000 mẫu được tạo ra và tính FID thông qua ADM evaluation suite.
Về sức mạnh tính toán, tất cả các mô hình CIFAR-10 được huấn luyện trên 1 GPU B200, trong khi tất cả các mô hình ImageNet 64×64 được huấn luyện trên 8 GPU B200. Mô hình CIFAR-10 lớn nhất tiêu tốn 20 giờ B200 để huấn luyện, mô hình ImageNet 64×64 lớn nhất tiêu tốn 640 giờ B200 để huấn luyện.
Đại diện chính thức cho biết, nút thắt chính trong huấn luyện đến từ việc tính toán hàm "Mất mát trôi dạt", bởi vì nó cần sử dụng bộ trích xuất đặc trưng hình ảnh truyền thống và tính toán trên nhiều khung nhìn đặc trưng.
Un-0 đang ở vị trí nào trong lĩnh vực sinh ảnh?
Để thể hiện rõ hơn hiệu suất của Un-0, Unconventional AI đã đặt Un-0 trên đường cong "chất lượng sinh ảnh so với số lượng tham số" để so sánh với các mô hình truyền thống và không truyền thống.
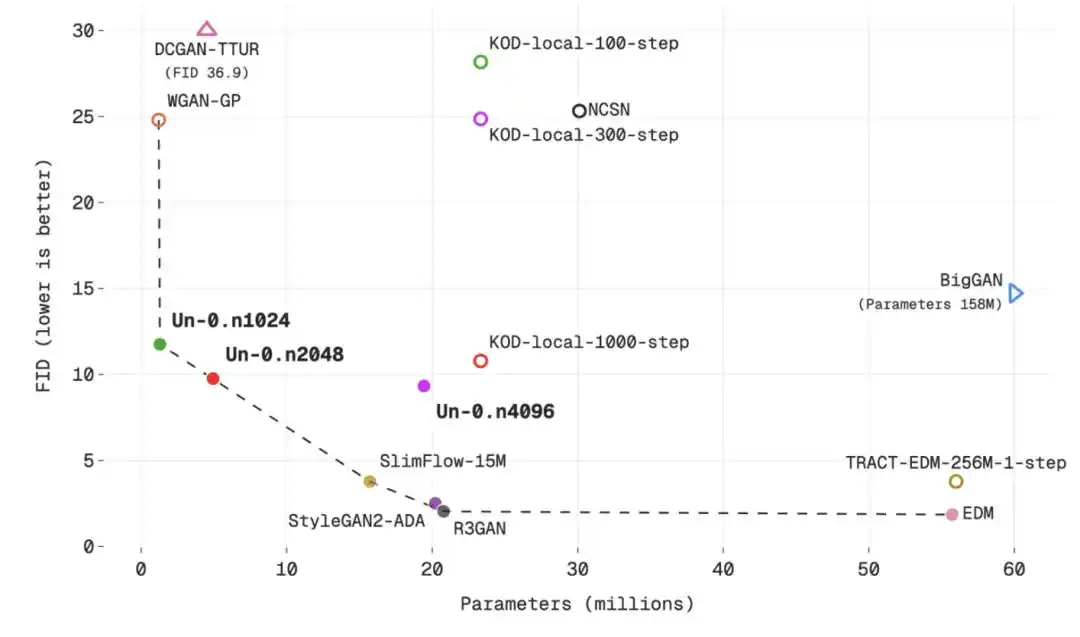
Mối quan hệ giữa số lượng tham số và giá trị FID trong tập dữ liệu CIFAR-10
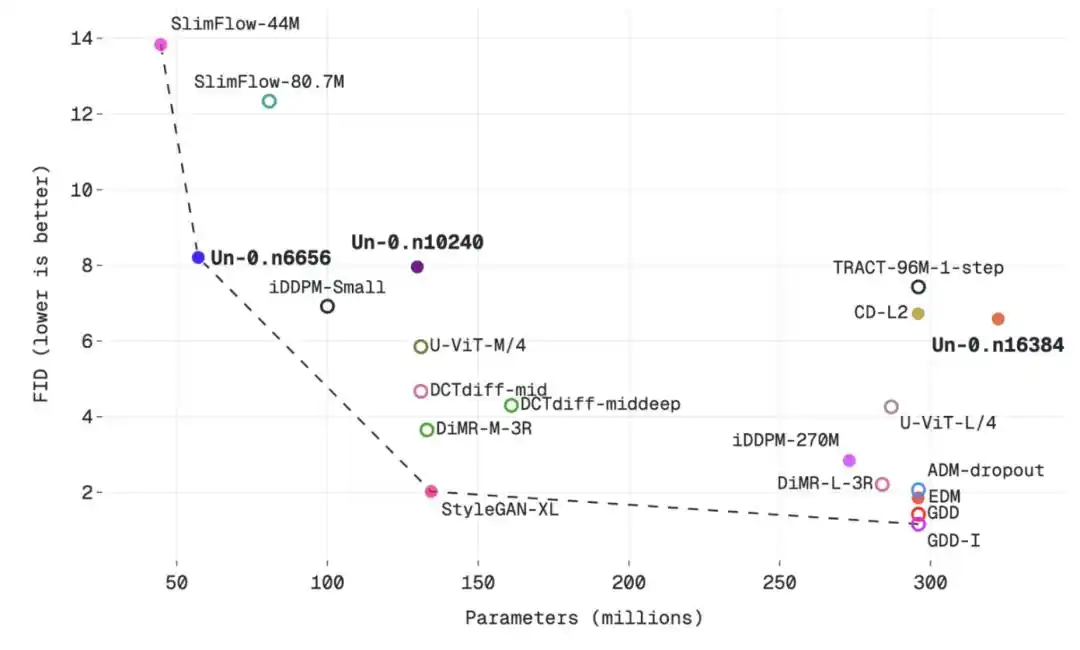
Mối quan hệ giữa số lượng tham số và giá trị FID ở kích thước hình ảnh 64×64
Kết luận là: Chất lượng của Un-0 đã có thể tương đương với một số bộ sinh ảnh truyền thống thời kỳ đầu, thậm chí tốt hơn trong một số so sánh, chẳng hạn như NCSN, DCGAN-TTUR, WGAN-GP, BigGAN, iDDPM, Consistency Models, TRACT. Nhưng nó vẫn tụt hậu so với các mô hình truyền thống hiệu suất cao xuất hiện sau này, như EDM và GDD.
Nói cách khác, Un-0 không phải là mô hình sinh ảnh mạnh nhất hiện tại, nó giống như một điểm khởi đầu cho một hướng đi mới: Hiệu suất của nó đã gần bằng mức của nhiều mô hình sinh ảnh kinh điển khi mới được đề xuất, nhưng để đuổi kịp mặt tiên tiến mới nhất của hướng đi truyền thống, vẫn cần sự tối ưu hóa liên tục về thuật toán, kiến trúc và nguyên thủy vật lý.
Xét tổng thể, Un-0 đã chứng minh tính khả thi của việc sử dụng hệ thống động lực học vật lý để sinh ảnh quy mô lớn trong AI hiện đại. Mặc dù hiệu suất hiện tại dưới mô phỏng phần mềm chưa đạt đến đỉnh cao của AI thông thường, nhưng nó mở ra một con đường đầy hứa hẹn cho "phần cứng AI không truyền thống" đạt hiệu suất năng lượng gấp nghìn lần trong tương lai......
Và Naveen Rao cũng nhấn mạnh, sự xuất hiện của Un-0 cho thấy "tính toán không phải là phát minh độc quyền của con người." Nó tồn tại ở khắp mọi nơi trong tự nhiên và thế giới vật lý. Tất cả các quá trình vật lý của thực thể vật lý đều chứa đựng chiều thời gian, nhưng các hệ thống tính toán ngày nay lại không thực sự tận dụng điều này.
"Những gì chúng tôi đang phát triển, chính là chiều thời gian này."
Và mối quan hệ của điều này với hiệu suất năng lượng nằm ở chỗ, trong các máy có kiến trúc von Neumann hiện có, phần lớn năng lượng được tiêu thụ trong việc di chuyển thông tin giữa bộ nhớ và đơn vị tính toán, trong khi hệ thống động lực học hợp nhất tính toán và bộ nhớ vào cùng một thực thể. Quan trọng hơn, hệ thống động lực học có thể chấp nhận nhiễu, điều này mở ra thêm cơ hội mới để tiết kiệm năng lượng thông tin liên lạc.
Un-0 đại diện cho bước đầu tiên quan trọng trong sự chuyển đổi mô hình tính toán sang hệ thống động lực học. "Thông qua việc phát hành mô hình này, chúng tôi đang kết nối trí tuệ với động lực học." Đối với tính toán AI, động lực học là một khuôn khổ biểu đạt tự nhiên, về bản chất, mạng nơ-ron cũng có thể được coi là một hệ thống động lực học, do đó, việc ánh xạ giữa hai bên sẽ trực tiếp hơn.
"Trong não bộ không có sự trừu tượng như đại số tuyến tính, vì vậy theo một nghĩa nào đó, chúng tôi đang bỏ qua các khâu trung gian."
Và dưới bài đăng, nhiều cư dân mạng cũng bày tỏ sự mong đợi.
"Trên thực tế, sự cải thiện hiệu suất năng lượng này là rất lớn. Nếu công nghệ này có thể được áp dụng rộng rãi, nhiều ứng dụng chạy cục bộ có thể trở nên khả thi."

"Nếu công nghệ này có thể được thương mại hóa, thì đó thực sự là một công nghệ não bộ cực kỳ tiên tiến."

Liên kết tham khảo:
https://x.com/NaveenGRao/status/2070184079199494583
https://unconv.ai/blog/introducing-un-0-generating-images-with-coupled-oscillators/
https://techcrunch.com/2026/06/25/databricks-former-ai-chief-thinks-he-can-cut-ais-power-bill-by-1000x/
Bài viết này đến từ tài khoản công chúng WeChat "机器之心" (ID:almosthuman2014), tác giả: 关注AI的





