Chia sẻ
- Chia sẻ
- Tweet
- 极
-
极
ambcryptoXuất bản vào 2026-02-18Cập nhật gần nhất vào 2026-02-18
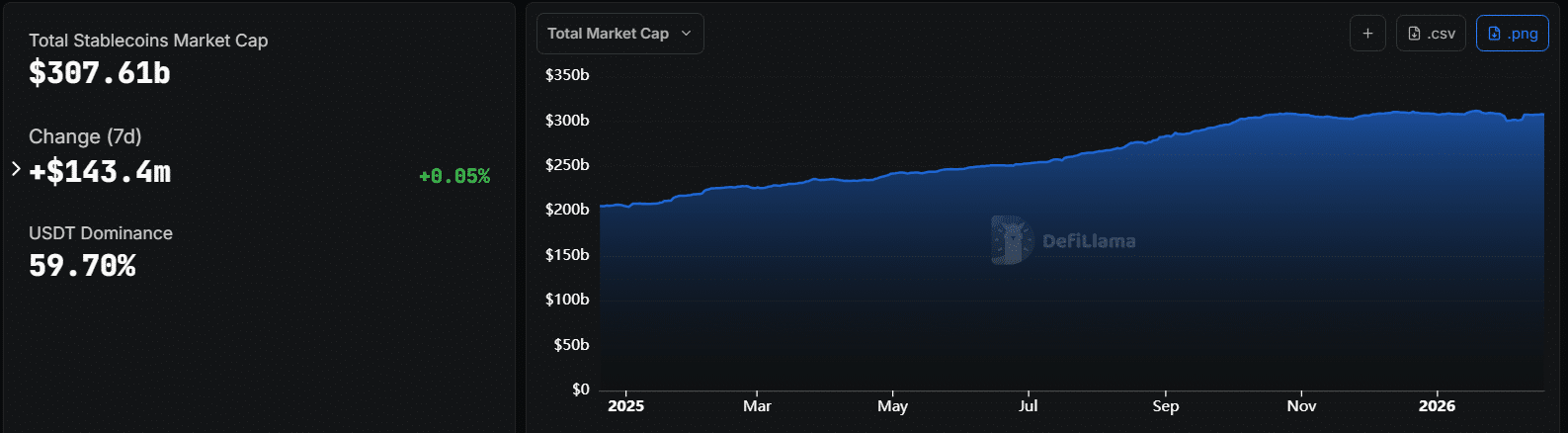
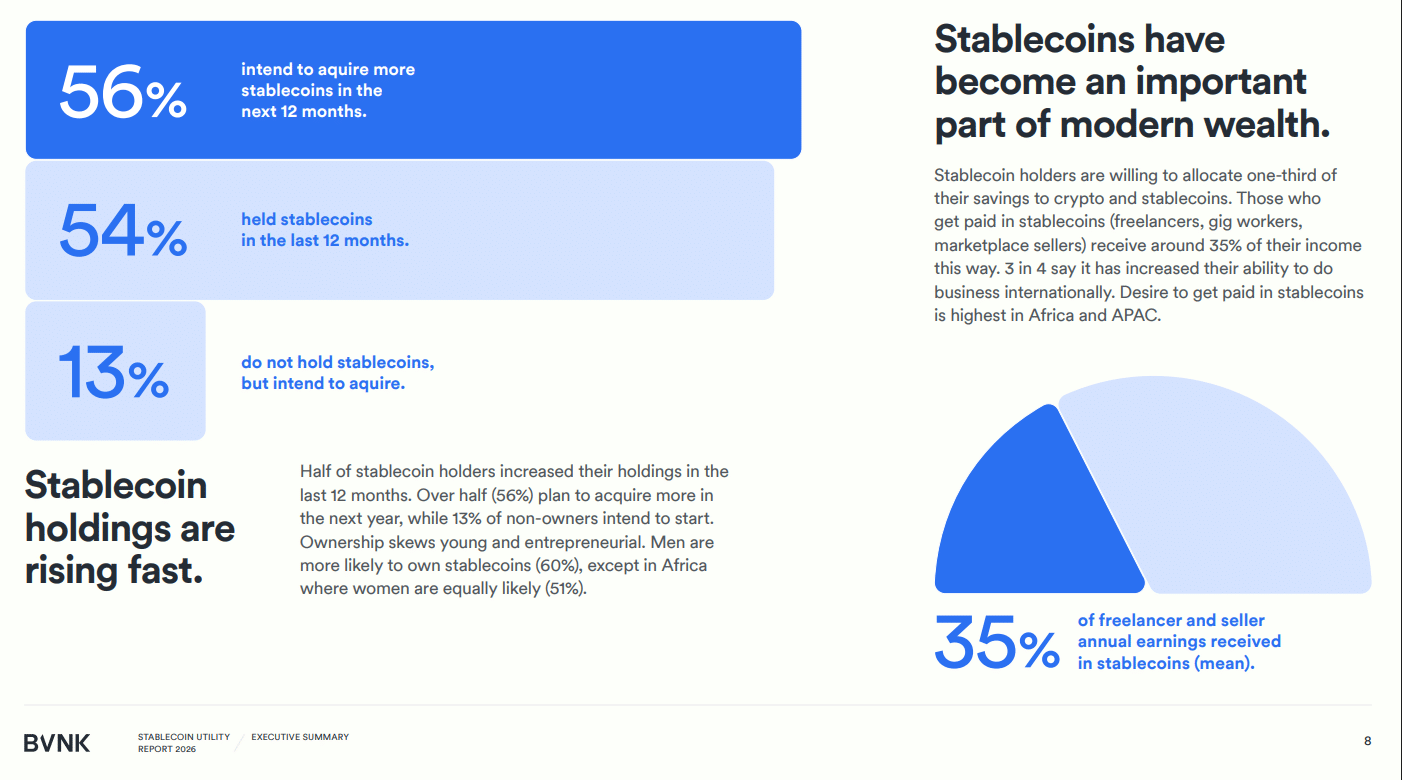
XDC Network đã hợp tác với OrbitX Pay để cho phép người dùng chi tiêu trực tiếp USD Coin (USDC) trên mạng XDC tại các điểm chấp nhận Visa, giúp giảm bớt sự phụ thuộc vào chuyển đổi fiat và các dịch vụ off-ramp truyền thống. Động thái này nằm trong xu hướng chuyển đổi từ tài sản kỹ thuật số thuần túy sang công cụ thanh toán thực tế. Tổng vốn hóa thị trường stablecoin hiện duy trì trên 307 tỷ USD, với hơn 56% người dùng dự định tăng nắm giữ trong năm tới. Khoảng 35% thu nhập của freelancer và người bán hàng đến từ stablecoin. Sự phát triển này cho thấy tiềm năng mở rộng ứng dụng blockchain ngoài lĩnh vực tài chính, hướng tới tích hợp vào các giao dịch hàng ngày. Tuy nhiên, mức độ áp dụng thực tế của giải pháp này vẫn cần được theo dõi.
QXDC Network và OrbitX Pay đã công bố hợp tác để làm gì?![]()
AXDC Network và OrbitX Pay đã hợp tác để cho phép người dùng chi tiêu trực tiếp đồng USDC được lưu trữ trên mạng lưới XDC tại các điểm chấp nhận thanh toán Visa, nhằm giảm bớt sự phụ thuộc vào chuyển đổi sang tiền pháp định và các dịch vụ off-ramp của bên thứ ba.
QLợi ích chính của việc chi tiêu USDC trực tiếp này là gì?![]()
ALợi ích chính là giảm chi phí và thời gian chờ đợi do quá trình chuyển đổi sang tiền pháp định và sử dụng các dịch vụ off-ramp truyền thống gây ra, đồng thời giữ cho người dùng toàn quyền kiểm soát tài sản của mình.
QTổng vốn hóa thị trường stablecoin hiện tại là bao nhiêu, theo bài viết?![]()
ATheo bài viết, tổng vốn hóa thị trường stablecoin đang duy trì trên mức 307 tỷ USD, với mức tăng trưởng ổn định trong năm qua.
QTỷ lệ phần trăm thu nhập của các freelancer và người bán hàng đến từ stablecoin là bao nhiêu?![]()
AKhoảng 35% thu nhập của các freelancer và người bán hàng trung bình đến từ các tài sản stablecoin.
QTheo báo cáo nghiên cứu của BVNK, bao nhiêu phần trăm người dùng stablecoin dự định mua thêm trong 12 tháng tới?![]()
ATheo báo cáo nghiên cứu gần đây của BVNK, 56% người dùng stablecoin có kế hoạch sẽ mua thêm trong 12 tháng tới.
Chào mừng bạn đến với HTX.com! Chúng tôi đã làm cho mua XDC Network (XDC) trở nên đơn giản và thuận tiện. Làm theo hướng dẫn từng bước của chúng tôi để bắt đầu hành trình tiền kỹ thuật số của bạn.Bước 1: Tạo Tài khoản HTX của BạnSử dụng email hoặc số điện thoại của bạn để đăng ký tài khoản miễn phí trên HTX. Trải nghiệm hành trình đăng ký không rắc rối và mở khóa tất cả tính năng. Nhận Tài khoản của tôiBước 2: Truy cập Mua Crypto và Chọn Phương thức Thanh toán của BạnThẻ Tín dụng/Ghi nợ: Sử dụng Visa hoặc Mastercard của bạn để mua XDC Network (XDC) ngay lập tức.Số dư: Sử dụng tiền từ số dư tài khoản HTX của bạn để giao dịch liền mạch.Bên thứ ba: Chúng tôi đã thêm những phương thức thanh toán phổ biến như Google Pay và Apple Pay để nâng cao sự tiện lợi.P2P: Giao dịch trực tiếp với người dùng khác trên HTX.Thị trường mua bán phi tập trung (OTC): Chúng tôi cung cấp những dịch vụ được thiết kế riêng và tỷ giá hối đoái cạnh tranh cho nhà giao dịch.Bước 3: Lưu trữ XDC Network (XDC) của BạnSau khi mua XDC Network (XDC), lưu trữ trong tài khoản HTX của bạn. Ngoài ra, bạn có thể gửi đi nơi khác qua chuyển khoản blockchain hoặc sử dụng để giao dịch những tiền kỹ thuật số khác.Bước 4: Giao dịch XDC Network (XDC)Giao dịch XDC Network (XDC) dễ dàng trên thị trường giao ngay của HTX. Chỉ cần truy cập vào tài khoản của bạn, chọn cặp giao dịch, thực hiện giao dịch và theo dõi trong thời gian thực. Chúng tôi cung cấp trải nghiệm thân thiện với người dùng cho cả người mới bắt đầu và người giao dịch dày dạn kinh nghiệm.
Tổng lượt xem 567Xuất bản vào 2024.12.12Cập nhật vào 2026.06.02






