В конце 2024 года научное сообщество широко обсуждало статью под названием «Потоковое глубокое обучение с подкреплением, наконец, заработало» (arXiv:2410.14606). Авторы из команды Махмуда из Университета Альберты посвятили значительную часть описанию неловкой реальности: обучение с подкреплением, как метод, по своей сути предназначенный для «обучения на ходу», почти не может этого делать в эпоху глубоких нейронных сетей. Стоит убрать буфер воспроизведения или установить размер пакета равным 1, как обучение разваливается. Они назвали это «потоковым барьером» (stream barrier).
В той статье алгоритмы серии StreamX, благодаря тщательно подобранным гиперпараметрам, разреженной инициализации и различным методам стабилизации, едва преодолели эту стену.
Однако менее чем через полтора года член той же исследовательской группы вместе с коллабораторами из института Openmind дал совершенно другой ответ: корень потокового барьера не в «недостатке данных», а в «неправильной единице измерения шага обучения».

Название статьи: Intentional Updates for Streaming Reinforcement Learning
Адрес статьи: https://arxiv.org/pdf/2604.19033v1
Репозиторий кода: https://github.com/sharifnassab/Intentional_RL
Одна педаль газа, и большая яма
Представьте, что вы учитесь парковать машину. Инструктор говорит вам каждый раз «давить на газ 0.1 секунды». Проблема в том, что при одинаковом времени в 0.1 секунды машина проедет разное расстояние в зависимости от подъема, спуска, нагрузки и т.д. Иногда не хватит сантиметра, иногда переедет на 30 см и врежется в стену.
Шаг обучения в традиционном градиентном спуске делает именно это: он определяет, насколько параметры должны измениться, но никак не контролирует, насколько изменится выход функции. При обучении пакетами (batch) усреднение ошибок по сотням или тысячам примеров сглаживает крайние случаи, и проблема не так заметна. Но в «потоковой» среде на каждом шаге есть только один пример, усреднять нечего. Как только направление градиента становится нестабильным, величина обновления начинает сильно колебаться — сегодня сдвиг на 30 см вперед, завтра на 50 см назад — процесс обучения разрушается из-за сильных колебаний.
Это явление «перелета и недолета» (overshooting and undershooting) особенно серьезно в обучении с подкреплением, потому что градиент на каждом временном шаге различается не только по величине, но и быстро меняется по направлению.
Переопределение «какой должна быть одна итерация»
В недавней статье Арсалана Шарифнассаба из института Openmind, Мохамеда Эльсаида, А. Рупама Махмуда и Ричарда Саттона из Университета Альберты предложен подход, который меняет угол зрения: вместо того чтобы указывать, насколько должны измениться параметры, лучше прямо указать, насколько должен измениться выход функции.
Эта идея возникла не на пустом месте. В 1967 году японские ученые Нагумо и Нода в статье «A learning method for system identification» в области адаптивной фильтрации предложили алгоритм «нормализованного метода наименьших квадратов» (NLMS); по сути, он тоже использовал ожидаемое изменение выхода для обратного расчета шага, а не наоборот. Просто этот алгоритм был применим только к простым линейным сценариям.
Исследователи распространили эту идею на глубокое обучение с подкреплением. Они назвали это «целенаправленными обновлениями» (Intentional Updates): перед каждым обновлением сначала определяется «чего я хочу достичь на этом шаге», а затем обратным расчетом определяется, каким должен быть размер шага.
Для обучения оценке ценности (т.е. предсказанию будущего вознаграждения) их «цель» определяется так: после каждого обновления ошибка предсказания ценности текущего состояния должна уменьшаться на фиксированную долю — например, на 5%, не больше и не меньше. Для обучения стратегии (т.е. оптимизации принимаемых решений) их цель определяется так: вероятность выбора текущего действия на каждом шаге может измениться только на «умеренную» величину.
Возвращаясь к аналогии с вождением: это как если бы водитель перед каждым действием решал «я хочу сдвинуть машину вперед на 20 см», а затем автоматически вычислял, насколько нужно нажать на газ в зависимости от текущих условий (уклон, нагрузка), вместо того чтобы каждый раз давить на педаль с одинаковой силой и надеяться на лучшее.
Лауреат премии Тьюринга и его пазл
Одним из авторов статьи является Ричард С. Саттон — лауреат премии Тьюринга 2024 года, широко известный как «отец современного обучения с подкреплением».
Положение Саттона в научном мире примерно соответствует положению Фейнмана в физике: он не только предложил два фундаментальных каркаса современного обучения с подкреплением — обучение с временной разницей (TD learning) и градиент стратегии (policy gradient), но и вместе с Эндрю Барто написал самый авторитетный учебник по этой области «Reinforcement Learning: An Introduction» (сейчас вышло второе издание, доступное для бесплатного чтения онлайн). Он и Барто разделили премию Тьюринга 2024 года, в формулировке которой отмечается «заложение концептуальных и алгоритмических основ обучения с подкреплением».
Получив награду, Саттон не ушел на покой, а вложил призовые деньги в созданный им институт Openmind, финансируя молодых исследователей, желающих изучать фундаментальные вопросы «в среде, свободной от коммерческого давления». Эта новая статья — продукт именно этой некоммерческой организации.
А первый автор, Шарифнассаб, недавно опубликовал на ICML 2025 фреймворк MetaOptimize, исследующий автоматическую онлайн-настройку скорости обучения. Оба проекта сосредоточены на одной задаче: как сделать сам шаг обучения более интеллектуальным.
Детали алгоритма: проще, чем кажется
Математический вывод «целенаправленных обновлений» не сложен, его основную формулу можно описать одной фразой: шаг равен «ожидаемому изменению выхода», деленному на «фактическое влияние направления градиента на выход».
При обучении оценке ценности это «фактическое влияние» — это норма вектора градиента (эквивалент измерения «крутизны» текущей области параметров): в более крутых местах шаг меньше, в более пологих — больше, что гарантирует постоянное воздействие каждого обновления на функцию ценности.
При обучении стратегии «ожидаемое изменение» определяется пропорциональным функции преимущества: насколько текущее действие лучше среднего уровня, настолько стратегия и сдвигается в этом направлении — с нормализацией величины с помощью скользящего среднего, что обеспечивает стабильность изменения стратегии в долгосрочной перспективе в объяснимых пределах.
Исследователи также объединили эту основную идею с двумя инженерными практиками: диагональным масштабированием в стиле RMSProp (для обработки различий в масштабах разных параметров) и следами пригодности (eligibility traces, помогающими распространять сигнал вознаграждения на предыдущие временные шаги).
В итоге получились три полных алгоритма: для предсказания ценности — Intentional TD (λ), для управления с дискретными действиями — Intentional Q (λ) и для непрерывного управления — Intentional Policy Gradient.



Результаты экспериментов: без GPU, наравне с SAC
Статья оценивает этот подход на нескольких стандартных бенчмарках, и результаты впечатляют.
В задачах непрерывного управления MuJoCo (включая сложных симулированных роботов, таких как Ant, Humanoid, HalfCheetah) новый метод Intentional AC в потоковой настройке (размер пакета = 1, без буфера воспроизведения) по конечной производительности многократно приближался или даже превосходил SAC — алгоритм, использующий большой буфер воспроизведения и являющийся практически золотым стандартом для текущих задач непрерывного управления. Что касается вычислительных затрат, количество операций с плавающей запятой, необходимое для одного обновления Intentional AC, составляет примерно 1/140 от одного обновления SAC.
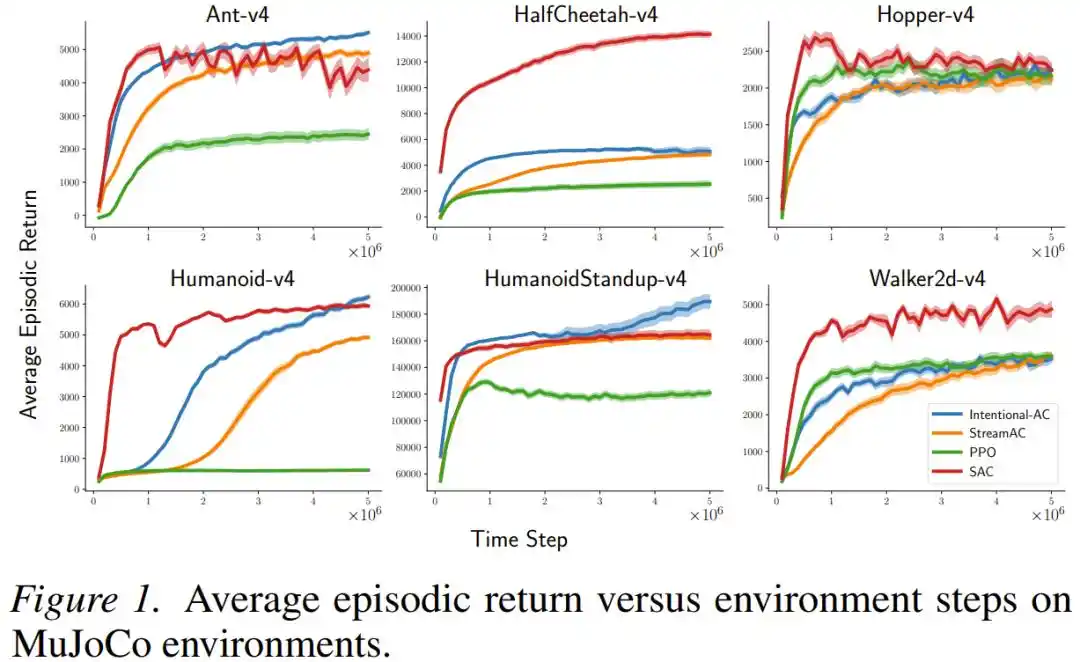
В играх с дискретными действиями Atari и MinAtar Intentional Q-learning показал результаты, сравнимые с DQN, использующим буфер воспроизведения, причем для всех задач использовались одни и те же гиперпараметры без индивидуальной настройки.
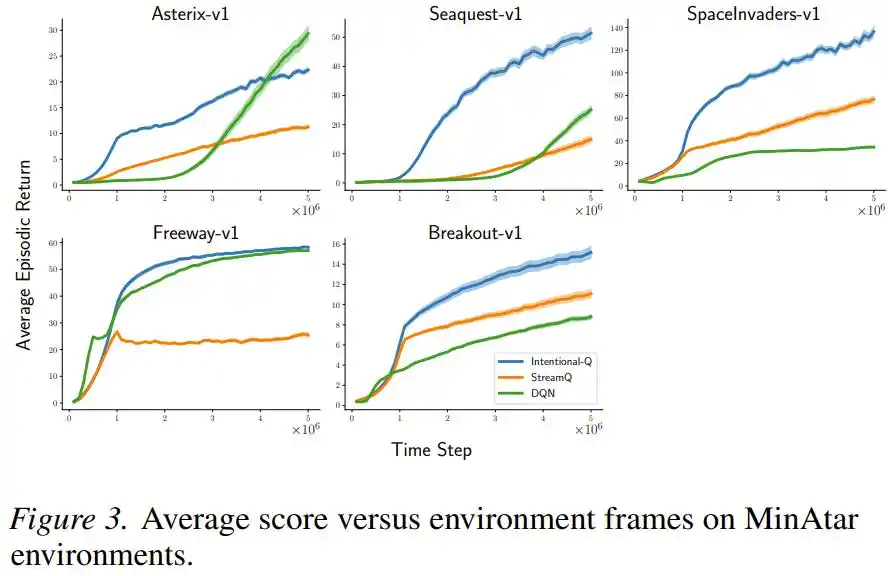
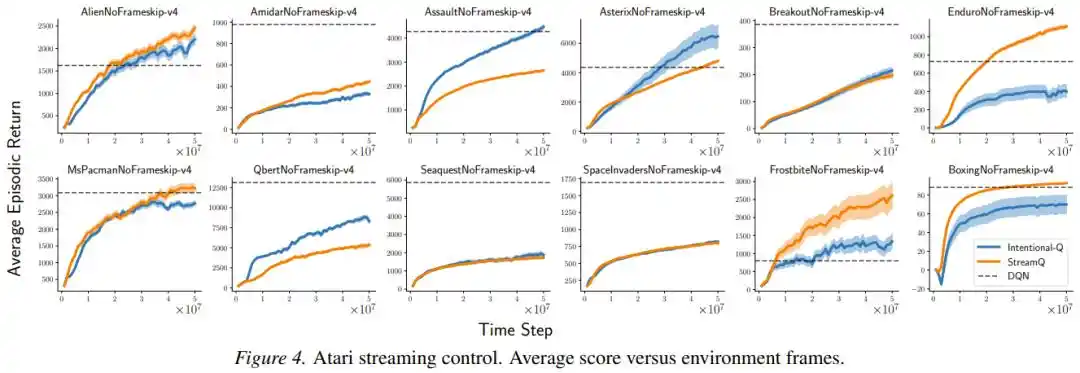
Исследователи также специально проверили, достигается ли на самом деле «цель»: они измерили отношение фактического изменения к ожидаемому. В упрощенной настройке без следов пригодности стандартное отклонение этого отношения составило всего от 0.016 до 0.029, 99-й процентиль — в пределах 1.07; это означает, что в подавляющем большинстве случаев обновление действительно делало «ровно то, что планировалось».
Кроме того, набор экспериментов по удалению компонентов показал, что если убрать нормализацию RMSProp или σ-член, производительность снижается, но остается конкурентоспособной, причем само «целенаправленное масштабирование» является основным вкладом, а другие компоненты — вспомогательными.
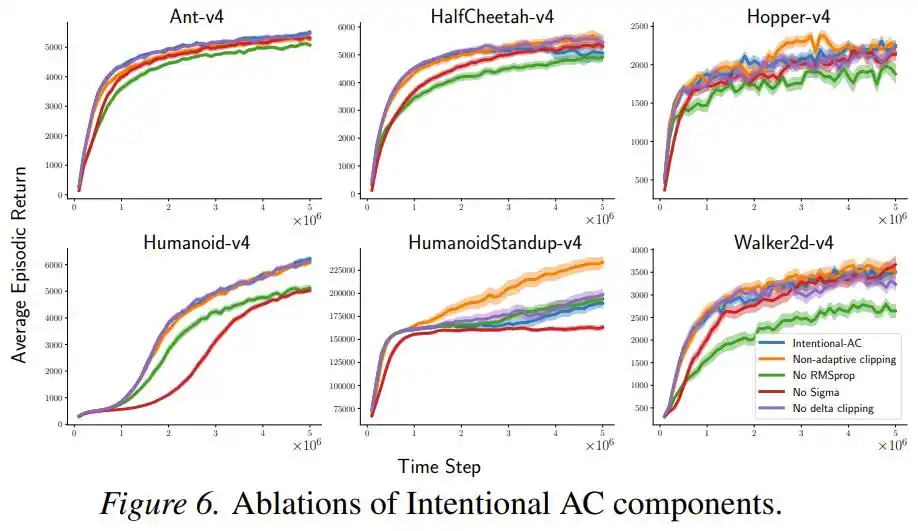
Проблемы все же есть
Фреймворк «целенаправленных обновлений» также продемонстрировал явные преимущества в устойчивости. Когда исследователи последовательно убирали различные вспомогательные методы стабилизации, от которых зависит метод StreamX (разреженная инициализация, масштабирование вознаграждения, нормализация входных данных, LayerNorm), снижение производительности Intentional AC было значительно меньше, чем у оригинального StreamAC, что указывает на то, что целенаправленное масштабирование уменьшает зависимость от внешних «костылей» на фундаментальном уровне.
Однако в статье также честно признается одна проблема, которая еще не полностью решена: при обучении стратегии шаг зависит от текущего выбранного действия, что может неявно присваивать разный «вес» разным действиям, потенциально меняя ожидаемое направление градиента стратегии. В задачах Humanoid и HumanoidStandup, измеряя косинусное сходство ожидаемого направления обновления, исследователи обнаружили, что это смещение на ключевых этапах обучения близко к 0.96 (почти не влияет); но в Ant-v4 согласованность упала до медианного значения 0.63, что указывает на то, что проблемой нельзя всегда пренебрегать.
Авторы отмечают, что будущие исследования должны искать стратегии выбора шага, независимые от действия, чтобы «цель» оставалась несмещенной и в математическом ожидании. Это четкое задание для последователей в этом направлении.
Заключение: Пусть ИИ учится на ходу, как человек
Текущая преобладающая парадигма обучения больших моделей зависит от пакетной обработки огромных объемов данных: «скормить» все тексты и код из интернета, многократно итерации, в итоге возникает удивительная способность. Этот путь доказал свою эффективность, но он принципиально является «сначала выучить, потом использовать»: после завершения обучения модель замораживается и не может непрерывно обновляться на основе каждого последующего реального взаимодействия.
Потоковое обучение с подкреплением стремится к совершенно другому режиму обучения: не зависеть от массивного воспроизведения, не зависеть от огромных кластеров GPU, каждое переживание немедленно преобразуется в обновление параметров, непрерывно, дешево, адаптивно. Это больше похоже на реальный способ обучения людей и животных.
От первоначального прорыва Эльсаида и др. в 2024 году «наконец заработало» до принципа «целенаправленных обновлений», предложенного в этой статье, потоковое глубокое обучение с подкреплением развивается с удивительной скоростью. Оно не заменит большие модели, обученные пакетным методом, но для роботов, периферийных устройств, требующих долгосрочной онлайн-адаптации, и любых сценариев, где невозможно поддерживать большие буферы воспроизведения и кластеры GPU, этот путь становится все более убедительным.
Шаг обучения — это не просто гиперпараметр, это обещание ИИ «сколько сделать» на каждом шаге. Когда это обещание наконец стало контролируемым, само обучение стабилизировалось.
Эта статья взята из официального аккаунта WeChat «机器之心» (ID: almosthuman2014), автор: 关注RL的





